
 Anton Chaynikov, pengembang Ilmu Data, Redmadrobot
Anton Chaynikov, pengembang Ilmu Data, Redmadrobot
Halo, Habr! Hari ini saya akan berbicara tentang kesulitan dalam perjalanan ke chatbot, yang memfasilitasi pekerjaan operator obrolan asuransi. Lebih tepatnya, bagaimana kami mengajarkan bot untuk membedakan permintaan dari satu sama lain menggunakan pembelajaran mesin. Model mana yang dicoba dan yang mana yang mendapatkan hasil. Bagaimana empat pendekatan untuk membersihkan dan memperkaya data dengan kualitas yang layak dan lima upaya untuk membersihkan data dengan kualitas "tidak senonoh".
Tantangan
Obrolan perusahaan asuransi menerima +100500 panggilan klien per hari. Sebagian besar pertanyaan sederhana dan berulang, tetapi operator tidak mudah, dan pelanggan masih harus menunggu lima hingga sepuluh menit. Bagaimana cara meningkatkan kualitas layanan dan mengoptimalkan biaya tenaga kerja sehingga operator memiliki lebih sedikit rutinitas dan pengguna memiliki sensasi yang lebih menyenangkan dari dengan cepat menyelesaikan masalah mereka?
Dan kami akan melakukan chatbot. Biarkan dia membaca pesan pengguna, berikan instruksi untuk kasus sederhana, dan ajukan pertanyaan standar untuk kasus rumit untuk mendapatkan informasi yang dibutuhkan operator. Operator langsung memiliki pohon skrip - skrip (atau diagram alur) yang mengatakan pertanyaan apa yang mungkin ditanyakan pengguna dan bagaimana menanggapinya. Kami akan mengambil skema ini dan menaruhnya di chatbot, tetapi itu adalah nasib buruk - chatbot tidak mengerti secara manusiawi dan tidak tahu bagaimana menghubungkan pertanyaan pengguna ke cabang skrip.
Jadi, kami akan mengajarinya dengan bantuan pembelajaran mesin tua yang baik. Tapi Anda tidak bisa hanya mengambil sepotong data yang dihasilkan oleh pengguna dan mengajarinya model kualitas yang layak. Untuk melakukan ini, Anda perlu bereksperimen dengan arsitektur model, data - untuk membersihkan, dan kadang-kadang mengumpulkan lagi.
Cara mengajar bot:
- Pertimbangkan opsi model: bagaimana ukuran dataset, rincian vektorisasi teks, pengurangan dimensi, penggolong dan akurasi akhir digabungkan.
- Mari kita bersihkan data yang layak: kita akan menemukan kelas-kelas yang dapat dibuang dengan aman; kita akan mengetahui mengapa markup enam bulan terakhir lebih baik dari tiga sebelumnya; menentukan di mana model terletak, dan di mana markup; Cari tahu bagaimana kesalahan ketik dapat bermanfaat.
- Kami akan membersihkan data "tidak senonoh": kami akan mencari tahu kapan pengelompokan berguna dan tidak berguna, karena pengguna dan operator berbicara ketika tiba saatnya untuk berhenti menderita dan pergi untuk mengumpulkan markup.
Tekstur
Kami memiliki dua klien - perusahaan asuransi dengan obrolan online - dan proyek pelatihan chatbot (kami tidak akan memanggil mereka, ini tidak penting), dengan kualitas data yang sangat berbeda. Nah, jika setengah dari masalah proyek kedua bisa diselesaikan dengan manipulasi dari yang pertama. Detailnya di bawah.
Dari sudut pandang teknis, tugas kami adalah mengklasifikasikan teks. Hal ini dilakukan dalam dua tahap: pertama teks-teks tersebut di-vektor-kan (menggunakan tf-idf, doc2vec, dll.), Kemudian model klasifikasi dilatih pada vektor (dan kelas) yang diperoleh - hutan acak, SVM, jaringan saraf, dan sebagainya. dan sebagainya.
Dari mana data berasal:
- Sql unggah riwayat obrolan. Bidang unggahan yang relevan: teks pesan; penulis (klien atau operator); mengelompokkan pesan ke dalam dialog; cap waktu; kategori kontak pelanggan (pertanyaan tentang asuransi kewajiban motor wajib, asuransi lambung, asuransi kesehatan sukarela; pertanyaan tentang situs; pertanyaan tentang program loyalitas; pertanyaan tentang perubahan kondisi asuransi, dll.).
- Rangkaian skrip, atau urutan pertanyaan dan jawaban dari operator ke pelanggan dengan permintaan berbeda.
Tanpa validasi, tentu saja, tidak ada tempat. Semua model dilatih pada 70% dari data dan dievaluasi sesuai dengan hasil pada 30% sisanya.
Metrik kualitas untuk model yang kami gunakan:
- Dalam pelatihan: logloss, untuk dapat dibedakan;
- Saat menulis laporan: akurasi klasifikasi pada sampel uji, untuk kesederhanaan dan kejelasan (termasuk untuk pelanggan);
- Ketika memilih arah untuk tindakan lebih lanjut: intuisi dari seorang ilmuwan data yang menatap dengan cermat hasil.
Eksperimen Model
Jarang ketika tugas segera memperjelas model mana yang akan memberikan hasil terbaik. Jadi di sini: tanpa eksperimen, tidak ada tempat.
Kami akan mencoba opsi vektorisasi:
- tf-idf dalam satu kata;
- tf-idf pada tiga kali lipat karakter (selanjutnya: 3 gram);
- tf-idf pada 2-, 3-, 4-, 5-gram secara terpisah;
- tf-idf pada 2-, 3-, 4-, 5 gram secara bersamaan;
- Semua pengurangan + kata di atas dalam teks sumber ke bentuk kamus;
- Semua + penurunan dimensi di atas dengan metode terpotong SVD;
- Dengan jumlah pengukuran: 10, 30, 100, 300;
- doc2vec, dilatih tentang isi teks dari tugas.
Opsi klasifikasi berdasarkan latar belakang ini terlihat agak buruk: SVM, XGBoost, LSTM, hutan acak, bayang naif, hutan acak di atas prediksi SVM dan XGB.
Dan meskipun kami memeriksa reproduktifitas hasil pada tiga set data yang dirakit secara independen dan fragmennya, kami hanya dapat menjamin penerapan yang luas.
Hasil percobaan:
- Dalam rantai “klasifikasi-penurun dimensi-preprocessing-menurunkan dimensi” efek dari pilihan pada setiap langkah hampir tidak tergantung pada langkah-langkah lain. Mana yang sangat nyaman, Anda tidak bisa melalui selusin opsi dengan setiap ide baru dan menggunakan opsi yang paling dikenal di setiap langkah.
- tf-idf dalam kata-kata kehilangan hingga 3 gram (akurasi 0,72 vs 0,78). 2-, 4-, 5 gram kalah dari 3 gram (0,75-0,76 vs 0,78). {2; 5} -gol secara bersamaan sedikit mengungguli 3-gram. Mengingat peningkatan tajam dalam memori yang diperlukan, kami memutuskan untuk lalai untuk pelatihan dalam mendapatkan akurasi 0,4%.
- Dibandingkan dengan tf-idf dari semua varietas, doc2vec tidak berdaya (akurasi 0,4 dan di bawah). Layak untuk mencoba melatihnya bukan pada korps dari tugas (~ 250.000 teks), tetapi pada yang jauh lebih besar (2,5–25 juta teks), tetapi sejauh ini, sayangnya, tangan Anda belum mencapai.
- SVD yang terpotong tidak membantu. Akurasi meningkat secara monoton dengan peningkatan pengukuran, dengan lancar mencapai akurasi tanpa TSVD.
- Di antara pengklasifikasi, XGBoost menang dengan selisih nyata (+ 5-10%). Pesaing terdekat adalah SVM dan hutan acak. Naif Bayes bukan pesaing bahkan untuk hutan acak.
- Keberhasilan LSTM sangat tergantung pada ukuran dataset: pada sampel 100.000 objek, mampu bersaing dengan XGB. Pada sampel 6000 - dalam lagging bersama dengan Bayes.
- Hutan acak di atas SVM dan XGB selalu setuju dengan XGB, atau lebih keliru. Ini sangat menyedihkan, kami berharap SVM akan menemukan dalam data setidaknya beberapa pola yang tidak tersedia untuk XGB, tetapi sayangnya.
- XGBoost rumit dengan stabilitas. Misalnya, peningkatan dari versi 0,72 menjadi 0,80 secara tidak dapat dijelaskan mengurangi keakuratan model terlatih sebesar 5-10%. Dan satu hal lagi: XGBoost mendukung perubahan parameter pelatihan selama pelatihan dan kompatibilitas dengan API scikit-learn standar, tetapi sangat terpisah. Anda tidak dapat melakukan keduanya bersama-sama. Harus memperbaikinya.
- Jika Anda membawa kata-kata ke bentuk kamus, ini meningkatkan kualitas sedikit, dalam kombinasi dengan tf-idf dalam kata-kata, tetapi tidak berguna dalam semua kasus lainnya. Pada akhirnya, kami mematikannya untuk menghemat waktu.
Pengalaman 1. Pembersihan data, atau apa yang harus dilakukan dengan markup
Operator obrolan hanya orang. Ketika mendefinisikan kategori permintaan pengguna, mereka sering keliru dan memiliki interpretasi yang berbeda tentang batas antara kategori. Oleh karena itu, data sumber harus dibersihkan secara ganas dan intensif.
Data kami tentang pelatihan model pada proyek pertama:
- Riwayat pesan obrolan online selama beberapa tahun. Ini adalah 250.000 posting dalam 60.000 percakapan. Di akhir dialog, operator memilih kategori yang menjadi milik panggilan pengguna. Ada sekitar 50 kategori dalam dataset ini.
- Pohon skrip. Dalam kasus kami, operator tidak memiliki skrip yang berfungsi.
Apa sebenarnya data itu buruk, kami dirumuskan sebagai hipotesis, kemudian diperiksa dan, jika mungkin, diperbaiki. Inilah yang terjadi:
Pendekatan pertama. Dari seluruh daftar kelas besar, Anda dapat dengan aman meninggalkan 5-10.
Kami membuang kelas kecil (<1% dari sampel): sedikit data + dampak kecil. Kami menyatukan kelas yang sulit dibedakan, dimana operator masih bereaksi dengan cara yang sama. Sebagai contoh:
'dms' + 'bagaimana cara membuat janji dengan dokter' + 'pertanyaan tentang mengisi program'
'pembatalan' + 'status pembatalan' + 'pembatalan kebijakan berbayar'
'pertanyaan perpanjangan' + 'bagaimana cara memperbarui kebijakan?'
Selanjutnya, kita membuang kelas-kelas seperti "lain", "lain" dan sejenisnya: untuk chatbot, mereka tidak berguna (tetap diarahkan ke operator), dan pada saat yang sama mereka sangat merusak akurasi, karena 20% dari permintaan (30, 50, 90) diklasifikasikan oleh operator dan disini Sekarang kita membuang kelas yang chatbot tidak dapat bekerja dengannya (belum).
Hasil: dalam satu kasus, pertumbuhan dari akurasi 0,40 menjadi 0,69, dalam kasus lain, dari 0,66 menjadi 0,77.
Pendekatan kedua. Di awal obrolan, operator sendiri kurang memahami bagaimana memilih kelas untuk dihubungi pengguna, sehingga ada banyak "noise" dan kesalahan dalam data.
Eksperimen: kami hanya mengambil dua (tiga, enam, ...) bulan terakhir dari dialog dan melatih model
mereka.
Hasil: dalam satu kasus luar biasa, akurasi meningkat dari 0,40 menjadi 0,60, dalam kasus lain - dari 0,69 menjadi 0,78.
Pendekatan ketiga. Kadang-kadang akurasi 0,70 tidak berarti "model salah dalam 30% kasus", tetapi "dalam 30% kasus markup berbohong, dan model mengoreksinya dengan sangat wajar".
Dengan metrik seperti akurasi atau logloss, hipotesis ini tidak dapat diverifikasi. Untuk keperluan percobaan, kami membatasi diri pada pandangan seorang ilmuwan data, tetapi dalam kasus yang ideal, Anda perlu mengatur ulang dataset secara kualitatif, bukan melupakan validasi silang.
Untuk bekerja dengan sampel seperti itu, kami datang dengan proses "pengayaan iteratif":
- Pisahkan dataset menjadi 3-4 fragmen.
- Latih model pada fragmen pertama.
- Prediksi kelas-kelas yang kedua dengan model yang terlatih.
- Dengan cermat melihat kelas yang diprediksi dan tingkat kepercayaan model, pilih nilai batas kepercayaan.
- Hapus teks (objek) yang diprediksi dengan keyakinan di bawah batas dari fragmen kedua, latih modelnya tentang ini.
- Ulangi sampai fragmen lelah atau habis.
Di satu sisi, hasilnya sangat baik: model iterasi pertama memiliki akurasi 70%, yang kedua - 95%, yang ketiga - 99 +%. Melihat dari dekat hasil prediksi sepenuhnya mengkonfirmasi keakuratan ini.
Di sisi lain, bagaimana seseorang dapat secara sistematis memverifikasi dalam proses ini bahwa model selanjutnya tidak mempelajari kesalahan dari yang sebelumnya? Ada ide untuk menguji proses pada dataset "berisik" secara manual dengan markup awal berkualitas tinggi, seperti MNIST. Tapi, sayangnya, tidak ada cukup waktu untuk ini. Dan tanpa verifikasi, kami tidak berani meluncurkan pengayaan berulang dan model yang dihasilkan dalam produksi.
Pendekatan keempat. Dataset dapat diperluas - dan dengan demikian meningkatkan akurasi dan mengurangi pelatihan ulang, menambahkan banyak kesalahan ketik pada teks yang ada.
Kesalahan ketik adalah kesalahan pengetikan - menggandakan surat, melompati surat, mengatur ulang surat-surat tetangga di tempat, mengganti surat dengan huruf yang berdekatan pada keyboard.
Eksperimen: Proporsi huruf p tempat terjadinya kesalahan ketik: 2%, 4%, 6%, 8%, 10%, 12%. Peningkatan set data: biasanya hingga 60.000 replika. Bergantung pada ukuran awal (setelah filter), ini berarti peningkatan 3-30 kali.
Hasil: tergantung pada dataset. Pada dataset kecil (~ 300 replika), 4–6% kesalahan pengetikan memberikan peningkatan akurasi yang stabil dan signifikan (0,40 → 0,60). Pada dataset besar, semuanya lebih buruk. Dengan proporsi kesalahan ketik 8% atau lebih, teks berubah menjadi omong kosong dan akurasinya menurun. Dengan tingkat kesalahan 2-8%, akurasi berfluktuasi dalam kisaran beberapa persen, sangat jarang melebihi akurasi tanpa kesalahan ketik, dan, sepertinya, tidak perlu menambah waktu pelatihan beberapa kali.
Hasilnya, kami mendapatkan model yang membedakan 5 kelas panggilan dengan akurasi 0,86. Kami berkoordinasi dengan klien teks pertanyaan dan jawaban untuk masing-masing dari lima garpu, kencangkan teks ke chatbot, kirim ke QA.
Pengalaman 2. Setinggi lutut dalam data, atau apa yang harus dilakukan tanpa markup
Setelah mendapatkan hasil yang baik pada proyek pertama, kami mendekati yang kedua dengan penuh percaya diri. Tapi, untungnya, kami tidak lupa bagaimana caranya terkejut.
Apa yang kami temui:
- Pohon skrip lima cabang disepakati dengan klien sekitar setahun yang lalu.
- Sampel yang ditandai dari 500 pesan dan 11 kelas dengan asal tidak diketahui.
- Ditandai oleh operator obrolan dari 220.000 pesan, 21.000 percakapan, dan 50 kelas lainnya.
- Model SVM, dilatih pada sampel pertama, dengan akurasi 0,69, yang diwarisi dari tim ilmuwan data sebelumnya. Mengapa SVM, sejarah diam.
Pertama-tama, kita melihat kelas-kelas: di pohon skrip, dalam sampel model SVM, dalam sampel utama. Dan inilah yang kita lihat:
- Kelas-kelas model SVM kira-kira sesuai dengan cabang skrip, tetapi sama sekali tidak sesuai dengan kelas-kelas dari sampel besar.
- Skrip pohon ditulis pada proses bisnis setahun yang lalu, dan sudah usang hampir tidak berguna. Model SVM sudah tidak digunakan lagi.
- Dua kelas terbesar dalam sampel besar adalah Penjualan (50%) dan Lainnya (45%).
- Dari lima kelas terbesar berikutnya, tiga adalah umum seperti Penjualan.
- 45 kelas yang tersisa masing-masing berisi kurang dari 30 dialog. Yaitu kami tidak memiliki pohon skrip, tidak ada daftar kelas dan tidak ada markup.
Apa yang harus dilakukan dalam kasus seperti itu? Kami menyingsingkan lengan baju kami dan pergi sendiri untuk mendapatkan kelas dan markup dari data.
Upaya pertama. Mari mencoba mengelompokkan pertanyaan pengguna, mis. Pesan pertama dalam dialog, kecuali salam.
Kami periksa. Kami membuat vektor replika dengan menghitung 3 gram. Kami menurunkan dimensi ke sepuluh pengukuran pertama TSVD. Kami mengelompokkan dengan pengelompokan aglomeratif dengan jarak Euclidean dan fungsi Ward target. Turunkan lagi dimensi menggunakan t-SNE (hingga dua pengukuran sehingga Anda dapat melihat hasilnya dengan mata Anda). Kami menggambar poin replika di pesawat, melukis dengan warna cluster.
Hasil: ketakutan dan kengerian. Cluster sane, kita dapat berasumsi bahwa tidak ada:
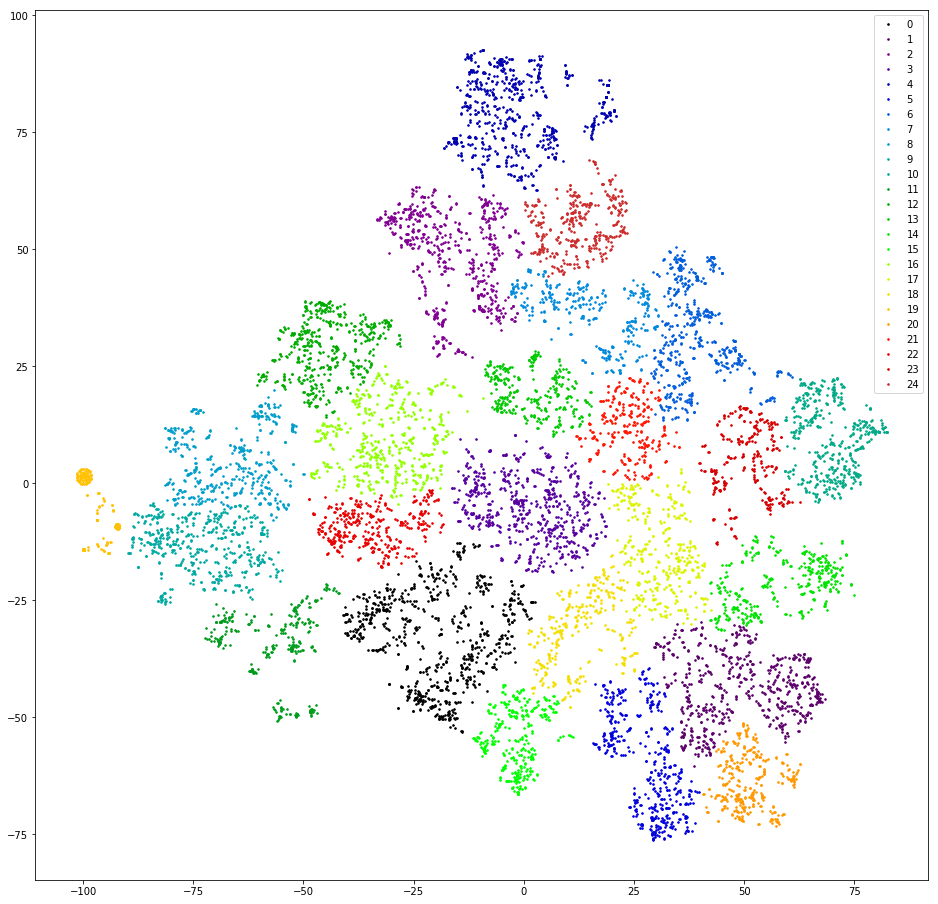
Hampir tidak - ada satu, oranye di sebelah kiri, ini karena semua pesan di dalamnya mengandung 3-gram "@". 3 gram ini adalah artefak preprocessing. Di suatu tempat dalam proses pemfilteran tanda baca, "@" tidak hanya tidak disaring, tetapi juga ditumbuhi spasi. Tapi artefak itu bermanfaat. Cluster ini termasuk pengguna yang pertama kali menulis email mereka. Sayangnya, hanya dengan ketersediaan surat saja tidak jelas apa permintaan pengguna. Kami melanjutkan.
Upaya kedua. Bagaimana jika operator sering merespons dengan kurang lebih tautan standar?
Kami periksa. Kami mengekstrak substring seperti tautan dari pesan operator, sedikit mengedit tautan, berbeda dalam pengejaan, tetapi artinya sama (http / https, / search? City =% city%), pertimbangkan frekuensi tautan.
Hasil: tidak menjanjikan. Pertama, operator hanya menanggapi sebagian kecil dari permintaan (<10%) dengan tautan. Kedua, bahkan setelah pembersihan manual dan penyaringan tautan yang terjadi sekali, ada lebih dari tiga puluh di antaranya. Ketiga, dalam perilaku pengguna yang mengakhiri dialog dengan tautan, tidak ada kesamaan tertentu.
Upaya ketiga. Mari kita mencari jawaban standar dari operator - bagaimana jika mereka akan menjadi indikator klasifikasi pesan?
Kami periksa. Dalam setiap dialog kami mengambil replika terakhir dari operator (terlepas dari selamat tinggal: "Saya bisa membantu yang lain," dll.) Dan mempertimbangkan frekuensi replika unik.
Hasil: menjanjikan, tetapi tidak nyaman. 50% respons operator unik, 10-20% lainnya ditemukan dua kali, sisanya 30-40% dicakup oleh sejumlah kecil templat populer. Relatif kecil - sekitar tiga ratus. Melihat dari dekat pada templat-templat ini menunjukkan bahwa banyak dari mereka adalah varian dari jawaban yang sama dalam hal makna - mereka berbeda di mana dengan satu huruf, di mana dengan satu kata, di mana dengan satu paragraf. Saya ingin mengelompokkan jawaban-jawaban ini yang hampir memiliki makna.
Upaya keempat. Mengelompokkan replika pernyataan terbaru. Ini dikelompokkan jauh lebih baik:
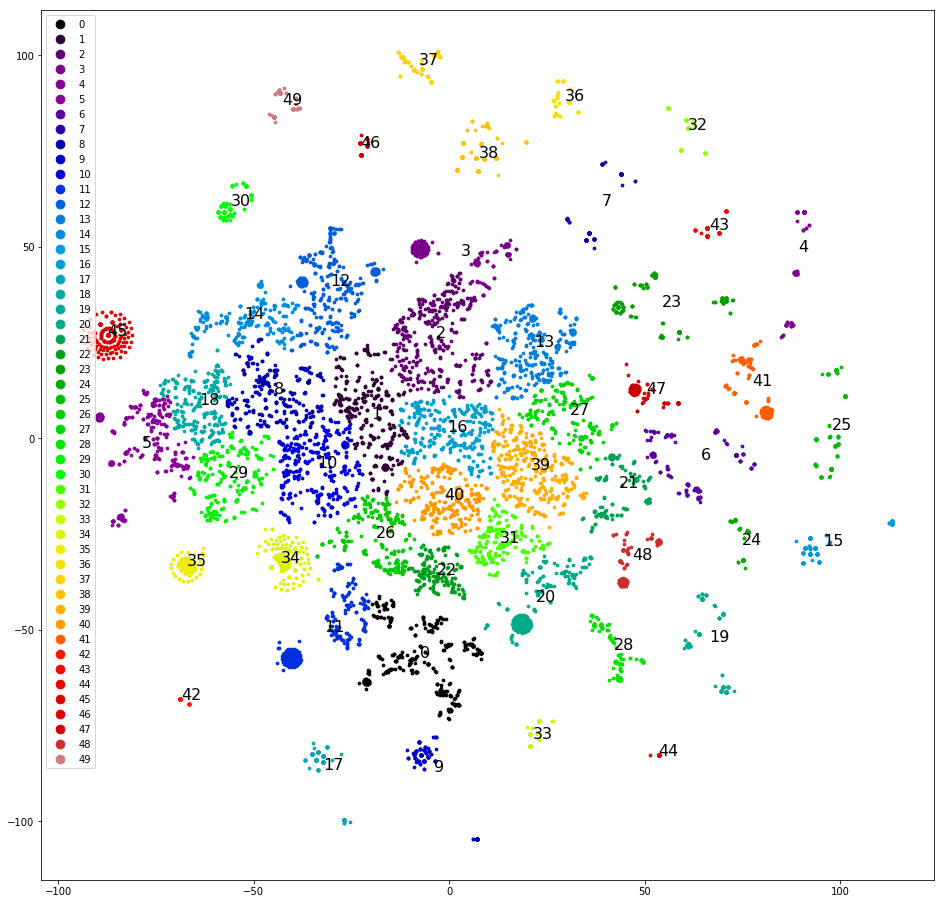
Anda sudah bisa bekerja dengan ini.
Kami mengelompokkan dan menggambar replika di pesawat, seperti pada upaya pertama, secara manual menentukan kelompok yang paling jelas terpisah, menghapusnya dari dataset dan mengelompokkan lagi. Setelah memisahkan sekitar setengah dari dataset, hapus cluster yang berakhir, dan kami mulai berpikir tentang kelas mana yang ditugaskan. Kami menyebarkan cluster menurut lima kelas asli - sampel "miring", dan tiga dari lima kelas asli tidak menerima satu cluster. Terlalu buruk Kami menyebarkan cluster ke dalam lima kelas, yang kami tetapkan secara acak, di: "panggil", "datang", "tunggu sehari untuk jawaban", "masalah dengan captcha", "lainnya". Kemiringannya kurang, tetapi akurasinya hanya 0,4-0,5. Buruk lagi Tetapkan masing-masing 30+ kelompok kelasnya sendiri. Sampel miring lagi dan keakuratannya lagi 0,5, meskipun sekitar lima kelas yang dipilih memiliki akurasi dan kelengkapan yang layak (0,8 dan lebih tinggi). Namun hasilnya masih belum mengesankan.
Upaya kelima. Kita membutuhkan semua seluk beluk pengelompokan. Kami mengambil dendrogram pengelompokan penuh alih-alih dari tiga puluh kelompok teratas. Kami menyimpannya dalam format yang dapat diakses oleh analis klien dan membantu mereka melakukan markup - kami membuat sketsa daftar kelas.
Untuk setiap pesan, kami menghitung rantai kelompok, yang mencakup setiap pesan, mulai dari root. Kami membangun tabel dengan kolom: teks, id dari cluster pertama dalam rantai, id dari cluster kedua dalam rantai, ..., id dari cluster yang sesuai dengan teks. Kami menyimpan tabel dalam csv / xls. Lebih jauh dengan itu Anda dapat bekerja dengan alat kantor.
Kami memberikan data dan sketsa daftar kelas untuk markup ke klien. Analis klien ditandai ulang ~ 10.000 pesan pengguna pertama. Kami, yang sudah diajarkan oleh pengalaman, diminta untuk menandai setiap pesan setidaknya dua kali. Dan tidak sia-sia - 4.000 dari 10.000 ini harus dibuang, karena kedua analis tersebut memiliki nilai yang berbeda. Di 6.000 yang tersisa, kami dengan cepat mengulang keberhasilan proyek pertama:
- Baseline: tidak ada penyaringan sama sekali - akurasi 0,66.
- Kami menggabungkan kelas-kelas yang sama dari sudut pandang operator. Kami mendapatkan akurasi 0,73.
- Kami menghapus kelas "Lainnya" - akurasinya meningkat menjadi 0,79.
Model sudah siap, sekarang Anda harus menggambar pohon skrip. Karena alasan yang tidak dapat kami jelaskan, kami tidak memiliki akses ke skrip untuk tanggapan operator. Kami tidak terkejut, berpura-pura menjadi pengguna dan selama beberapa jam di lapangan kami mengumpulkan template respons dan mengklarifikasi pertanyaan operator untuk semua kesempatan. Mereka mendekorasi mereka di pohon, mengemasnya dalam bot dan pergi untuk menguji. Pelanggan disetujui.
Kesimpulan, atau pengalaman apa yang telah ditunjukkan:
- Anda dapat bereksperimen dengan bagian-bagian model (preprocessing, vektorisasi, klasifikasi, dll.) Secara terpisah.
- XGBoost masih menguasai bola, meskipun jika Anda membutuhkan sesuatu yang tidak biasa darinya, Anda memiliki masalah.
- Pengguna adalah perangkat periferal dari input kacau, jadi Anda perlu membersihkan data pengguna.
- Pengayaan berulang itu keren, meski berbahaya.
- Terkadang ada baiknya mengembalikan data ke klien untuk markup. Namun jangan lupa untuk membantunya mendapatkan hasil yang berkualitas.
Disimpulkan.