Sebagian besar sistem penyimpanan yang tersedia di pasaran tidak jauh berbeda satu sama lain, karena banyak vendor memesan peralatan dari produsen ODM yang hampir sama. Kami memiliki hampir semua milik kami sendiri, dari sasis hingga pengontrol, teknologi seperti RAID 2.0+ dan perangkat lunak.

Di bawah potongan, ada beberapa detail tentang apa yang mungkin sangat tidak biasa di setiap node dari sistem penyimpanan data.
Apa yang menarik di tingkat modul
Secara struktural, semua sistem penyimpanan modern dari produsen mana pun terlihat sama: pengontrol dipasang di depan sasis kotak baja, dan modul antarmuka di belakang. Ada juga catu daya dan ventilasi. Tampaknya semuanya akrab dan standar. Namun faktanya, kami telah memperkenalkan banyak hal menarik ke dalam paradigma ini.
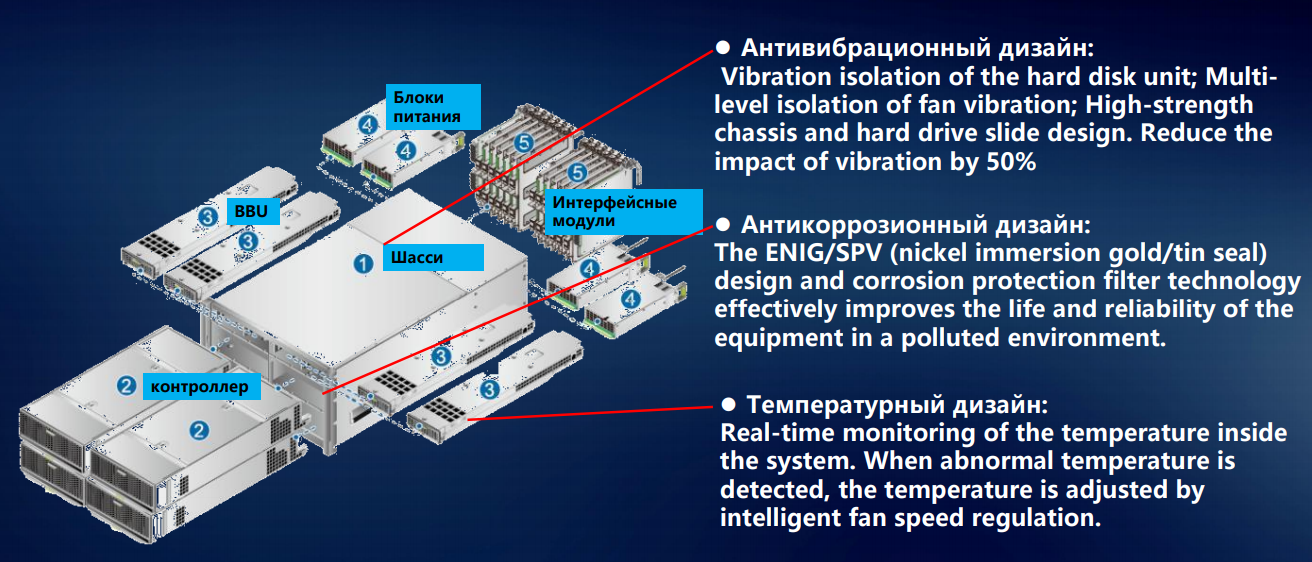
Mari kita mulai dengan memasang elemen sistem penyimpanan di sasis. Ada lebih sedikit drive 3,5 inci magnetik dalam sistem penyimpanan, sistem hibrida dan semua-flash mulai mendominasi. Tetapi bahkan beberapa disk drive dengan kecepatan spindle hingga 15 ribu putaran per menit menciptakan getaran yang tidak dapat diabaikan. Kami telah mengembangkan serangkaian rekomendasi untuk kasus ini - cara mendistribusikan drive magnetik dengan berbagai parameter di antara rak disk.
Bahkan di sebagian kecil persen, tetapi itu mempengaruhi keandalan. Dan pada skala pusat data yang besar, persentase per drive berubah menjadi indikator nyata dari kegagalan dan kegagalan fungsi. Untuk memastikan bahwa getaran masing-masing disk kurang ditransmisikan melalui struktur sasis yang kaku, kami melengkapi disk di bawah disk dengan karet atau peredam logam. Untuk menetralkan sumber getaran lain dalam sistem penyimpanan - modul ventilasi - kami memasang kipas dua arah, dan mengisolasi semua elemen yang berputar dari sasis.
Untuk drive spindle, guncangan minimal sudah menjadi masalah: kepala mulai tersesat, kinerja turun secara signifikan. SSD adalah masalah lain, mereka tidak takut terhadap getaran. Tetapi memperbaiki komponen dengan aman masih penting. Ambil proses pengiriman: kotak dapat dijatuhkan atau dilemparkan dengan santai, diletakkan miring atau terbalik. Oleh karena itu, kami memiliki semua komponen sistem penyimpanan diperbaiki secara ketat dalam tiga dimensi. Ini menghilangkan kemungkinan perpindahannya selama transportasi, melindungi konektor agar tidak keluar dari soket jika terjadi dampak yang tidak disengaja.

Sekali waktu, kami mulai dengan pengembangan teknologi komputer untuk industri telekomunikasi, di mana standar untuk pengoperasian dalam suhu dan kelembaban secara tradisional tinggi. Dan kami memindahkannya ke arah lain: bagian logam dari sistem penyimpanan tidak teroksidasi bahkan pada kelembaban tinggi - karena penggunaan pelapisan nikel dan galvanisasi.
Desain termal dari sistem penyimpanan kami dikembangkan dengan penekanan pada distribusi temperatur yang seragam di seluruh sasis - untuk mencegah panas berlebih atau pendinginan terlalu banyak pada setiap sudut rak disk. Kalau tidak, deformasi fisik tidak dapat dihindari - bahkan jika tidak signifikan, tetapi masih melanggar geometri dan mampu memperpendek umur peralatan. Dengan demikian, beberapa fraksi persen dimenangkan, tetapi ini masih memengaruhi keandalan sistem secara keseluruhan.
Seluk beluk semikonduktor
Kami menduplikasi komponen penting dari sistem penyimpanan: jika ada yang gagal, selalu ada jaring pengaman. Misalnya, modul daya untuk model yang lebih muda berfungsi sesuai dengan skema 1 + 1, untuk yang lebih solid - 2 + 1 dan bahkan 3 + 1.

Pengendali, yang setidaknya ada dua di sistem penyimpanan (kami tidak menyediakan sistem pengontrol tunggal) juga disediakan. Dalam sistem penyimpanan seri 6800 dan yang lebih lama, redundansi dilakukan sesuai dengan skema 3 + 1, dalam model yang lebih muda - 1 + 1.
Bahkan dewan manajemen dicadangkan, yang tidak secara langsung mempengaruhi operasi sistem, tetapi diperlukan hanya untuk perubahan konfigurasi dan pemantauan. Selain itu, kartu ekspansi antarmuka apa pun untuk sistem penyimpanan hanya dijual berpasangan, sehingga klien memiliki cadangan.
Semua komponen - PSU, kipas, pengontrol, modul manajemen, dll. - Dilengkapi dengan mikrokontroler yang mampu merespons situasi tertentu. Misalnya, jika kipas mulai melambat dengan sendirinya, alarm dikirim ke modul kontrol. Akibatnya, pelanggan memiliki gambaran lengkap tentang kondisi sistem penyimpanan - dan, jika perlu, dapat mengganti beberapa komponen sendiri, tanpa menunggu kedatangan insinyur layanan kami. Dan jika kebijakan keamanan pelanggan memungkinkan, kami mengonfigurasikan pengontrol sehingga mereka mengirimkan informasi tentang kondisi setrika ke dukungan teknis kami.
Chipnya lebih baik dan lebih mudah dimengerti.
Kami adalah satu-satunya perusahaan yang mengembangkan prosesor, chip, dan pengontrol solid state drive untuk sistem penyimpanannya.

Jadi, dalam beberapa model, sebagai prosesor utama sistem penyimpanan (Storage Controller Chip), kami tidak menggunakan Intel x86 klasik, tetapi prosesor ARM HiSilicon, anak perusahaan kami. Faktanya adalah bahwa arsitektur ARM dalam penyimpanan - untuk menghitung RAID dan deduplikasi yang sama - menunjukkan dirinya lebih baik daripada x86 standar.
Kebanggaan khusus kami adalah chip untuk pengontrol SSD. Dan jika server kami dapat dilengkapi dengan drive semikonduktor pihak ketiga (Intel, Samsung, Toshiba, dll.), Maka dalam sistem penyimpanan data kami hanya menginstal SSD dari desain kami sendiri.

Mikrokontroler modul input-output (chip I / O pintar) dalam sistem penyimpanan juga merupakan pengembangan HiSilicon, serta Chip Manajemen Cerdas untuk manajemen penyimpanan jarak jauh. Menggunakan microchip kami sendiri membantu kami lebih memahami apa yang terjadi pada setiap saat dengan setiap sel memori. Inilah yang memungkinkan kami untuk meminimalkan keterlambatan saat mengakses data dalam sistem penyimpanan Dorado yang sama.

Untuk cakram magnetik, pemantauan berkelanjutan sangat penting dalam hal keandalan. Sistem penyimpanan kami mendukung DHA (Disk Health Analyzer): disk itu sendiri terus mencatat apa yang terjadi padanya, seberapa baik rasanya. Berkat akumulasi statistik dan pembuatan model prediksi pintar, dimungkinkan untuk memprediksi transisi drive ke kondisi kritis dalam 2-3 bulan, dan tidak dalam 5-10 hari. Disk masih "hidup", data di dalamnya benar-benar aman - tetapi pelanggan siap untuk menggantinya pada tanda pertama dari kemungkinan kegagalan.
RAID 2.0+
Desain gagal-aman dalam sistem penyimpanan kami telah memikirkan pada tingkat sistem. Teknologi Smart Matrix kami merupakan add-on di atas PCIe - bus ini, atas dasar di mana koneksi inter-controller diterapkan, sangat cocok untuk SSD.
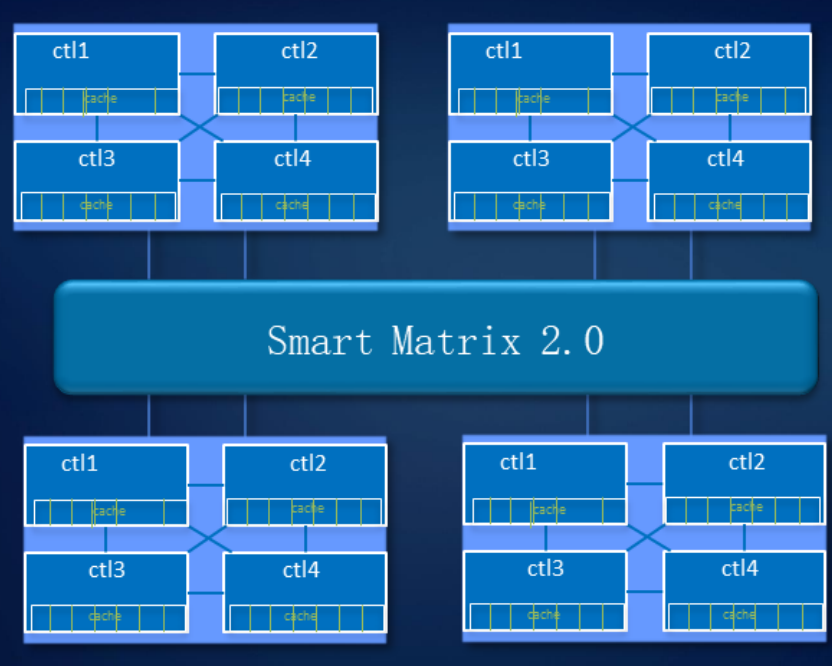
Smart Matrix menyediakan, khususnya, jala penuh 4-controller di penyimpanan Ocean Store 6800 v5 kami. Agar setiap pengontrol memiliki akses ke semua disk dalam sistem, kami mengembangkan backend SAS khusus. Cache, tentu saja, dicerminkan antara semua pengontrol yang saat ini aktif.

Ketika pengendali macet, layanan darinya dengan cepat beralih ke pengendali cermin, dan pengendali yang tersisa mengembalikan hubungan untuk saling mencerminkan. Pada saat yang sama, data yang direkam dalam cache memiliki cadangan cermin untuk memastikan keandalan sistem.

Sistem dapat menahan tiga pengontrol. Seperti yang ditunjukkan pada gambar, jika kontrol A gagal, data cache pengontrol B akan memilih pengontrol C atau D untuk mencerminkan cache. Ketika pengontrol D gagal, pengontrol B dan C mencerminkan cache.

Sistem distribusi data RAID 2.0 adalah standar untuk sistem penyimpanan kami: virtualisasi level disk telah lama menggantikan penyalinan konten blok-demi-blok dari satu media ke media lainnya. Semua disk dikelompokkan ke dalam blok, mereka digabungkan menjadi konglomerat yang lebih besar dari struktur dua tingkat, dan sudah di atas tingkat atasnya adalah volume logis yang membentuk array RAID.

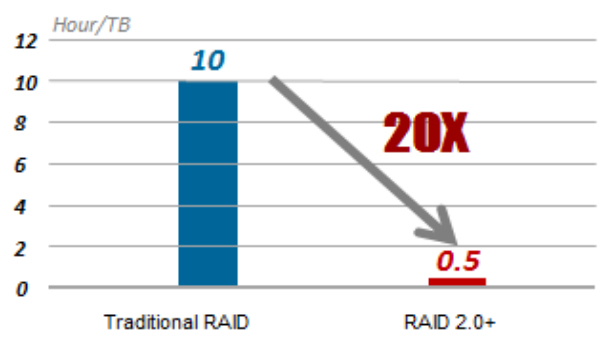
Keuntungan utama dari pendekatan ini adalah berkurangnya waktu bangun kembali array. Selain itu, dalam hal terjadi kegagalan disk, pembangunan kembali dilakukan bukan pada disk cadangan panas yang telah berdiri selama ini, tetapi pada ruang kosong di semua disk yang digunakan. Gambar di bawah ini menunjukkan sembilan hard drive RAID5 sebagai contoh. Ketika hard drive 1 crash, data CKG0 dan CKG1 rusak. Sistem memilih CK untuk rekonstruksi secara acak.

Kecepatan pemulihan RAID normal adalah 30 MB / s, sehingga dibutuhkan 10 jam untuk memulihkan 1 TB data. RAID 2.0+ mengurangi waktu ini menjadi 30 menit.
Pengembang kami berhasil mencapai distribusi beban yang seragam antara semua spindle drive dan SSD di sistem. Ini memungkinkan Anda untuk membuka kunci potensi sistem penyimpanan hybrid yang jauh lebih baik daripada penggunaan solid state drive sebagai cache.

Dalam sistem kelas Dorado, kami mengimplementasikan apa yang disebut RAID-TP, sebuah array dengan triple parity. Sistem seperti itu akan terus beroperasi sementara tiga drive gagal. Ini meningkatkan keandalan dibandingkan dengan RAID 6 dengan dua perintah desimal, dengan RAID 5 oleh tiga.
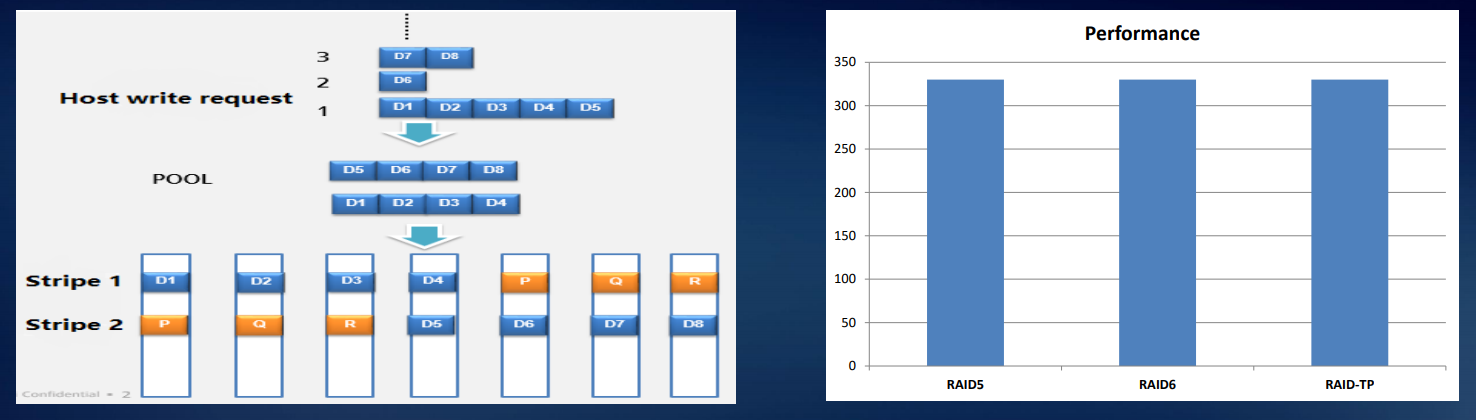
Kami merekomendasikan RAID-TP untuk data yang sangat penting, terutama karena karena RAID 2.0 dan flash drive berkecepatan tinggi, ini tidak memiliki dampak yang signifikan terhadap kinerja. Anda hanya perlu lebih banyak ruang kosong untuk dipesan.

Sebagai aturan, sistem semua-flash digunakan untuk DBMS dengan blok data kecil dan IOPS tinggi. Yang terakhir ini tidak terlalu baik untuk SSD: sel memori NAND cepat kehabisan daya. Dalam implementasi kami, sistem pertama mengumpulkan blok data yang relatif besar di cache drive, dan kemudian sepenuhnya menulisnya ke sel. Ini memungkinkan Anda untuk mengurangi beban pada disk, serta dalam mode yang lebih hemat, "pengumpulan sampah" dan membebaskan ruang pada SSD.
Enam sembilan
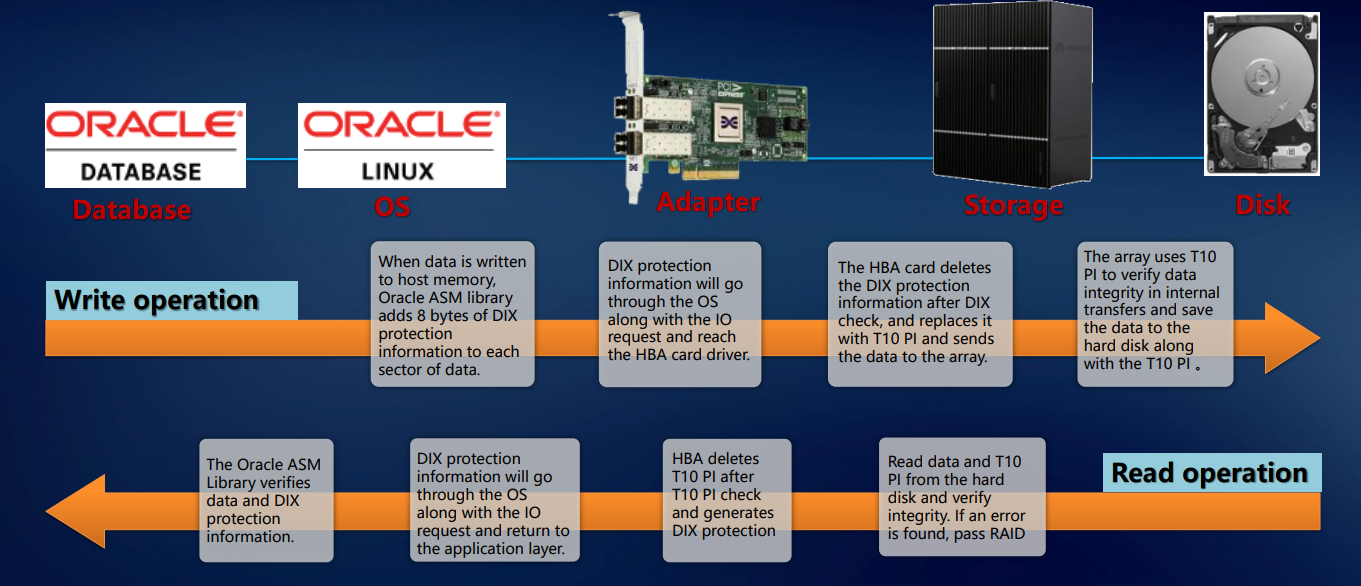
Di atas memungkinkan kita untuk berbicara tentang toleransi kesalahan sistem kita pada tingkat seluruh solusi. Validasi diimplementasikan pada level aplikasi (misalnya, Oracle DBMS), sistem operasi, adaptor, penyimpanan - dan seterusnya hingga disk. Pendekatan ini memastikan bahwa tepat blok data yang datang ke port eksternal akan ditulis ke disk internal sistem tanpa kerusakan atau kehilangan. Ini menyiratkan tingkat perusahaan.
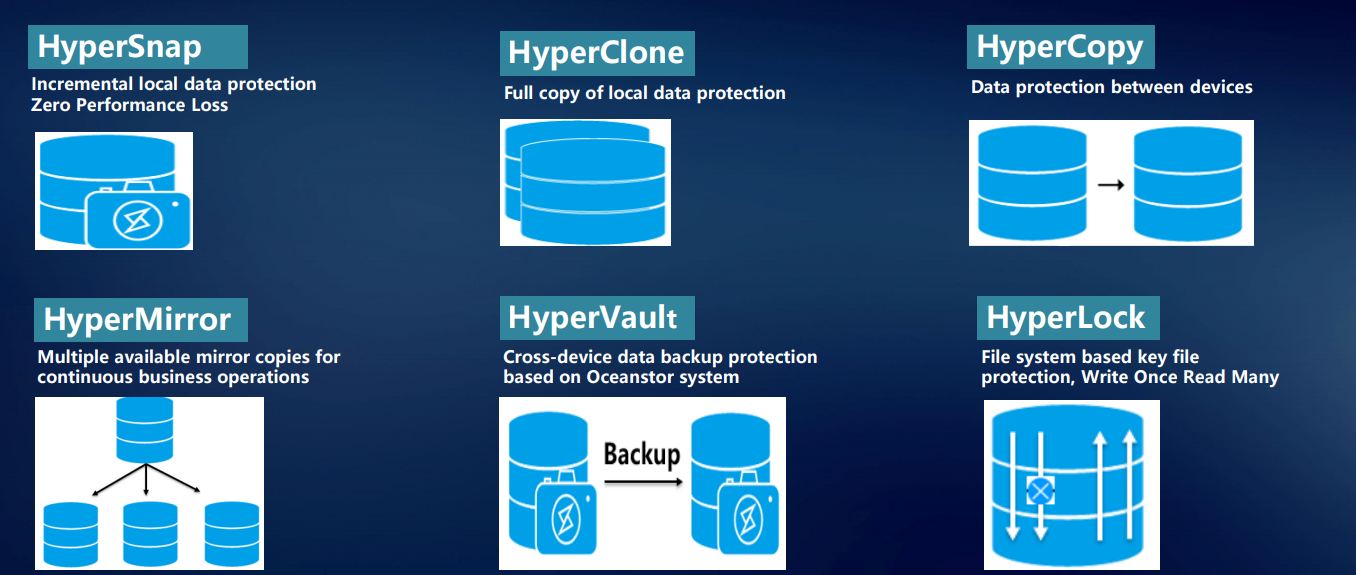
Untuk penyimpanan, perlindungan, dan pemulihan data yang andal, serta akses cepat ke sana, kami telah mengembangkan sejumlah teknologi eksklusif.

HyperMetro mungkin merupakan pengembangan paling menarik selama satu setengah tahun terakhir. Solusi turnkey yang didasarkan pada sistem penyimpanan kami untuk membangun metro cluster yang gagal-aman sedang diterapkan di tingkat pengontrol, tidak memerlukan gateway atau server tambahan, kecuali untuk arbiter. Ini diterapkan hanya dengan lisensi: dua sistem penyimpanan Huawei ditambah lisensi - dan berfungsi.

Teknologi HyperSnap menyediakan perlindungan data terus menerus tanpa kehilangan kinerja. Sistem mendukung RoW. Untuk mencegah hilangnya data pada penyimpanan pada saat tertentu, banyak teknologi digunakan: berbagai snapshot, klon, salinan.
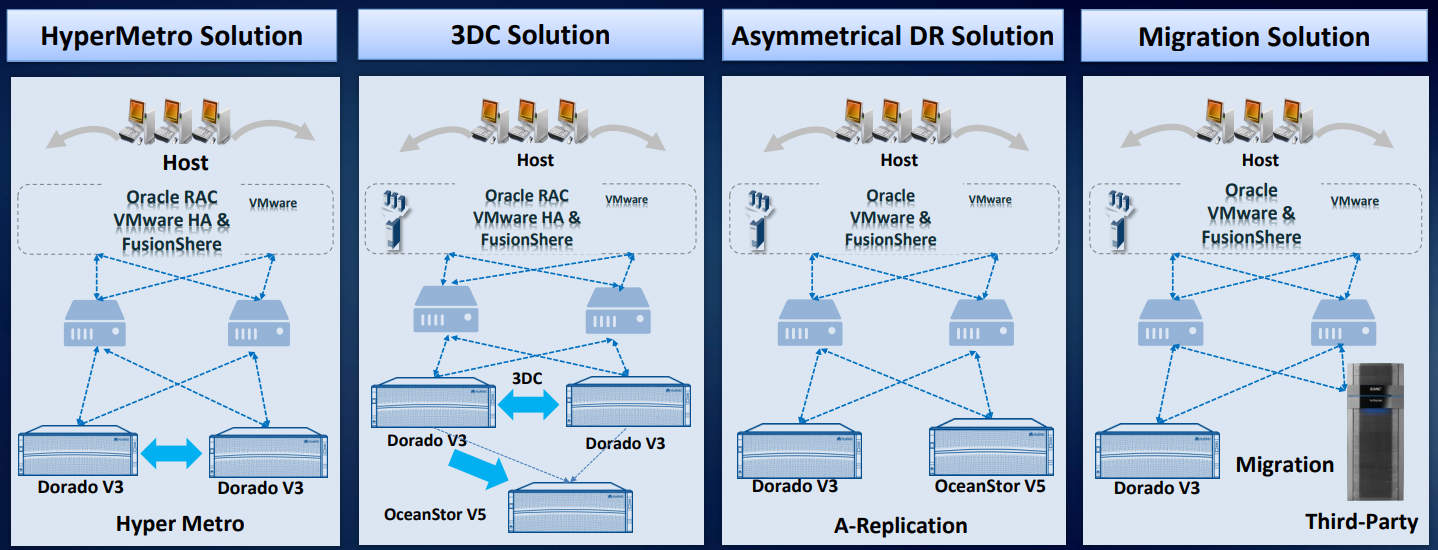
Berdasarkan sistem penyimpanan kami, setidaknya empat solusi pemulihan bencana telah dikembangkan dan diuji dalam praktik.
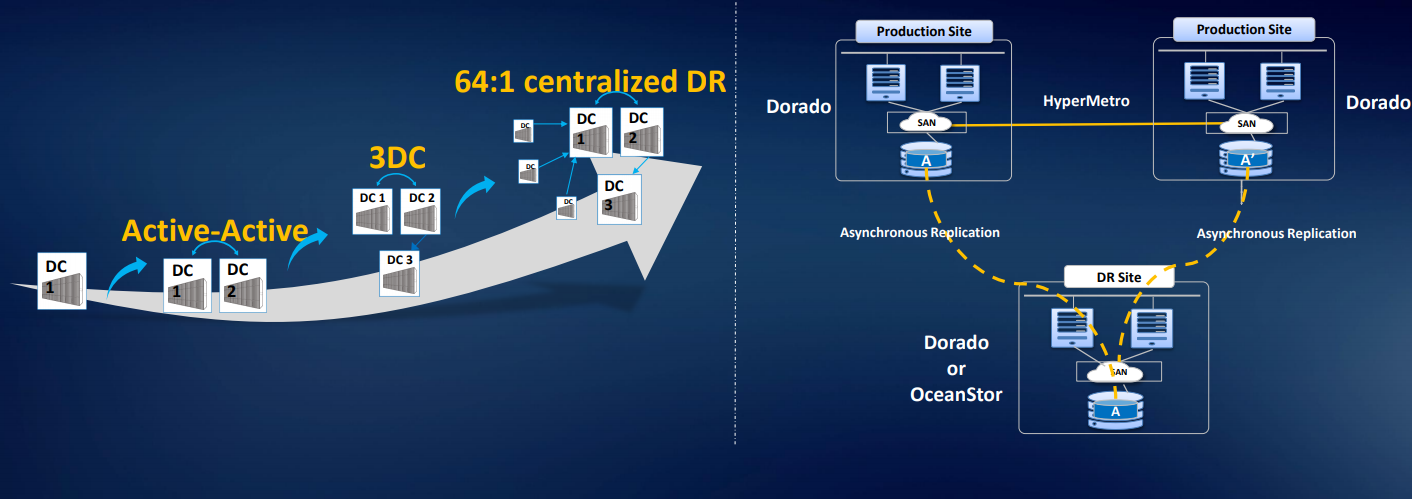
Kami juga memiliki solusi untuk tiga pusat data Solusi Ring 3DC DR: dua pusat data di cluster, dan yang ketiga adalah replikasi. Kami dapat mengatur replikasi atau migrasi asinkron dari array pihak ketiga. Ada lisensi virtualisasi pintar, sehingga Anda dapat menggunakan volume dari sebagian besar array standar dengan akses FC: Hitachi, DELL EMC, HPE, dll. Solusinya benar-benar berhasil, ada analog di pasar, tetapi harganya lebih mahal. Ada contoh penggunaan di Rusia.
Akibatnya, pada tingkat keseluruhan solusi, Anda bisa mendapatkan keandalan enam sembilan, dan pada tingkat penyimpanan lokal - lima sembilan. Secara umum, kami mencoba.
Diposting oleh Vladimir Svinarenko, Senior IT Solutions Manager, Huawei Enterprise di Rusia