
Topik artikel agak terfokus, tetapi mungkin bermanfaat bagi mereka yang mengembangkan gudang data mereka sendiri dan berpikir tentang integrasi dengan Kerangka Kerja Pegas.
Latar belakang
Pengembang biasanya tidak suka mengubah kebiasaan mereka (seringkali, kerangka kerja juga termasuk dalam daftar kebiasaan). Ketika saya mulai bekerja dengan CUBA , saya tidak perlu belajar terlalu banyak hal baru, sangat mungkin untuk terlibat aktif dalam pekerjaan di proyek ini dengan segera. Tetapi ada satu hal yang saya harus duduk lebih lama - itu bekerja dengan data.
Spring memiliki beberapa perpustakaan yang dapat digunakan untuk bekerja dengan database, salah satu yang paling populer adalah spring-data-jpa , yang dalam banyak kasus memungkinkan Anda untuk tidak menulis SQL atau JPQL. Anda hanya perlu membuat antarmuka khusus dengan metode yang dinamai dengan cara khusus dan Spring akan menghasilkan dan melakukan sisa pekerjaan untuk Anda dalam mengambil data dari database dan membuat instance objek entitas.
Di bawah ini adalah antarmuka, dengan metode untuk menghitung pelanggan dengan nama belakang yang diberikan.
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
Antarmuka ini dapat digunakan langsung di layanan Spring tanpa membuat implementasi apa pun, yang sangat mempercepat pekerjaan.
CUBA memiliki API untuk bekerja dengan data, yang mencakup berbagai fungsi seperti entitas yang dimuat sebagian atau sistem keamanan yang rumit dengan kontrol akses ke atribut entitas dan baris dalam tabel database. Tetapi API ini sedikit berbeda dari yang digunakan pengembang di Spring Data atau JPA / Hibernate.
Mengapa tidak ada repositori JPA di CUBA dan bisakah saya menambahkannya?
Bekerja dengan data di CUBA
Di CUBA, ada tiga kelas utama yang bertanggung jawab untuk bekerja dengan data: DataStore, EntityManager, dan DataManager.
DataStore adalah abstraksi tingkat tinggi untuk penyimpanan data apa pun: basis data, sistem file, atau penyimpanan cloud. API ini memungkinkan Anda untuk melakukan operasi dasar pada data. Dalam kebanyakan kasus, pengembang tidak perlu bekerja secara langsung dengan DataStore, kecuali ketika mengembangkan repositori mereka sendiri, atau jika beberapa akses yang sangat khusus ke data dalam repositori diperlukan.
EntityManager adalah salinan dari EntityManager JPA yang terkenal. Tidak seperti implementasi standar, ia memiliki metode khusus untuk bekerja dengan representasi CUBA , untuk penghapusan data "lunak" (logis), dan juga untuk bekerja dengan kueri di CUBA . Seperti dalam kasus DataStore, dalam 90% proyek, pengembang biasa tidak akan harus berurusan dengan EntityManager, kecuali jika diperlukan untuk memenuhi beberapa permintaan dengan melewati sistem pembatasan akses data.
DataManager adalah kelas utama untuk bekerja dengan data dalam CUBA. Menyediakan API untuk manipulasi data dan mendukung kontrol akses data, termasuk akses ke atribut dan batasan level baris. DataManager secara implisit memodifikasi semua kueri yang berjalan di CUBA. Misalnya, itu bisa mengecualikan bidang tabel yang pengguna saat ini tidak memiliki akses ke dari pernyataan select dan menambahkan kondisi untuk mengecualikan baris tabel dari seleksi. Dan ini membuat hidup lebih mudah bagi pengembang, karena Anda tidak perlu memikirkan cara menulis kueri dengan benar dengan mempertimbangkan hak akses akun, CUBA melakukan ini secara otomatis berdasarkan data dari tabel layanan basis data.
Di bawah ini adalah diagram interaksi komponen CUBA yang terlibat dalam pengambilan data melalui DataManager.
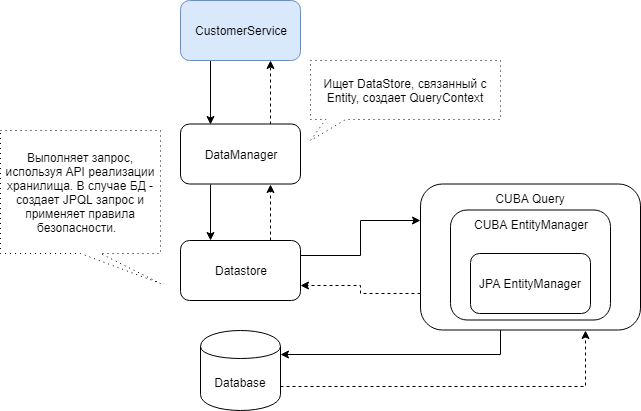
Menggunakan DataManager, Anda relatif dapat dengan mudah memuat entitas dan seluruh hierarki entitas menggunakan tampilan CUBA. Dalam bentuknya yang paling sederhana, kueri terlihat seperti ini:
dataManager.load(Customer.class).list();
Seperti yang telah disebutkan, DataManager akan memfilter catatan "dihapus secara logis", menghapus atribut terlarang dari permintaan, dan juga membuka dan menutup transaksi secara otomatis.
Tapi, ketika datang ke pertanyaan yang lebih rumit, Anda harus menulis JPQL di CUBA.
Misalnya, jika Anda perlu menghitung pelanggan dengan nama belakang yang diberikan, seperti pada contoh dari bagian sebelumnya, maka Anda perlu menulis sesuatu seperti kode ini:
public Long countByLastName(String lastName) { return dataManager .loadValue("select count(c) from sample$Customer c where c.lastName = :lastName", Long.class) .parameter("lastName", lastName) .one(); }
atau semacamnya:
public Long countByLastName(String lastName) { LoadContext<Customer> loadContext = LoadContext.create(Customer.class); loadContext .setQueryString("select c from sample$Customer c where c.lastName = :lastName") .setParameter("lastName", lastName); return dataManager.getCount(loadContext); }
Di CUBA API, Anda harus meneruskan ekspresi JPQL sebagai string (Kriteria API belum didukung), ini adalah cara yang dapat dibaca dan dimengerti untuk membuat kueri, tetapi men-debug kueri semacam itu dapat membawa banyak kesenangan. Selain itu, string JPQL tidak diverifikasi oleh kompiler atau Spring Framework selama inisialisasi wadah, yang mengarah ke kesalahan hanya di Runtime.
Bandingkan ini dengan Spring JPA:
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
Kode ini tiga kali lebih pendek, dan tidak ada baris. Selain itu, nama metode countByLastName diperiksa selama inisialisasi wadah Spring. Jika ada kesalahan ketik dan Anda menulis countByLastNsme , maka aplikasi akan macet dengan kesalahan selama penerapan:
Caused by: org.springframework.data.mapping.PropertyReferenceException: No property LastNsme found for type Customer!
CUBA dibangun di sekitar Spring Framework, jadi Anda bisa mencolokkan pegas-data-jpa di aplikasi yang ditulis menggunakan CUBA, tetapi ada masalah kecil - kontrol akses. Implementasi Spring CrudRepository menggunakan EntityManager-nya. Dengan demikian, semua kueri akan dilakukan melewati DataManager. Dengan demikian, untuk menggunakan repositori JPA di CUBA, Anda perlu mengganti semua panggilan EntityManager dengan panggilan DataManager dan menambahkan dukungan untuk tampilan CUBA.
Seseorang mungkin mengatakan bahwa pegas-data-jpa adalah kotak hitam yang tidak terkontrol dan selalu lebih baik untuk menulis JPQL murni atau bahkan SQL. Ini adalah masalah abadi keseimbangan antara kenyamanan dan tingkat abstraksi. Semua orang memilih metode yang dia sukai, tetapi untuk memiliki cara tambahan untuk bekerja dengan data di gudang tidak akan ada salahnya. Dan bagi mereka yang membutuhkan lebih banyak kontrol, Spring memiliki cara untuk mendefinisikan permintaan mereka sendiri untuk metode repositori JPA.
Implementasi
Repositori JPA diimplementasikan sebagai modul CUBA menggunakan pustaka spring-data-commons . Kami meninggalkan ide untuk memodifikasi pegas-data-jpa, karena jumlah pekerjaan akan jauh lebih banyak dibandingkan dengan menulis generator kueri kami sendiri. Terutama karena spring-data-commons melakukan sebagian besar pekerjaan. Misalnya, mem-parsing nama metode dan mengaitkan nama dengan kelas dan properti sepenuhnya dilakukan di pustaka ini. Spring-data-commons berisi semua kelas dasar yang diperlukan untuk implementasi repositori-nya sendiri dan tidak membutuhkan banyak upaya untuk mengimplementasikannya. Sebagai contoh, pustaka ini digunakan dalam spring-data-mongodb .
Hal yang paling sulit adalah mengimplementasikan generasi JPQL secara akurat berdasarkan hirarki objek - hasil parsing nama metode. Tapi, untungnya, tugas serupa sudah diterapkan di Apache Ignite, jadi kode diambil dari sana dan diadaptasi sedikit untuk menghasilkan JPQL, bukan SQL dan mendukung operator delete .
Spring-data-commons menggunakan proxy untuk secara dinamis membuat implementasi antarmuka. Ketika konteks aplikasi CUBA diinisialisasi, semua tautan ke antarmuka digantikan oleh tautan tempat proxy yang diterbitkan dalam konteks. Ketika metode antarmuka dipanggil, itu dicegat oleh objek proxy yang sesuai. Kemudian objek ini menghasilkan kueri JPQL dengan nama metode, menggantikan parameter dan mengirimkan kueri dengan parameter ke DataManager untuk dieksekusi. Diagram berikut menunjukkan proses interaksi yang disederhanakan antara komponen-komponen utama modul.

Menggunakan Gudang di CUBA
Untuk menggunakan repositori di CUBA, Anda hanya perlu menghubungkan modul di file build proyek:
appComponent("com.haulmont.addons.cuba.jpa.repositories:cuba-jpa-repositories-global:0.1-SNAPSHOT")
Anda dapat menggunakan konfigurasi XML untuk "mengaktifkan" repositori:
<?xml version="1.0" encoding="UTF-8"?> <beans:beans xmlns:beans="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:repositories="http://www.cuba-platform.org/schema/data/jpa" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.cuba-platform.org/schema/data/jpa http://www.cuba-platform.org/schema/data/jpa/cuba-repositories.xsd"> <context:component-scan base-package="com.company.sample"/> <repositories:repositories base-package="com.company.sample.core.repositories"/> </beans:beans>
Dan Anda dapat menggunakan anotasi:
@Configuration @EnableCubaRepositories public class AppConfig {
Setelah dukungan repositori diaktifkan, Anda dapat membuatnya dalam bentuk biasa, misalnya:
public interface CustomerRepository extends CubaJpaRepository<Customer, UUID> { long countByLastName(String lastName); List<Customer> findByNameIsIn(List<String> names); @CubaView("_minimal") @JpqlQuery("select c from sample$Customer c where c.name like concat(:name, '%')") List<Customer> findByNameStartingWith(String name); }
Untuk setiap metode, Anda dapat menggunakan anotasi:
@CubaView - untuk mengatur tampilan CUBA agar digunakan dalam DataManager@JpqlQuery - untuk menentukan kueri JPQL yang akan dieksekusi, terlepas dari nama metode.
Modul ini digunakan dalam modul global kerangka CUBA, oleh karena itu, repositori dapat digunakan baik dalam modul core dan di web . Satu-satunya hal yang perlu Anda ingat adalah mengaktifkan repositori di file konfigurasi kedua modul.
Contoh menggunakan repositori di layanan CUBA:
@Service(CustomerService.NAME) public class CustomerServiceBean implements PersonService { @Inject private CustomerRepository customerRepository; @Override public List<Date> getCustomersBirthDatesByLastName(String name) { return customerRepository.findByNameStartingWith(name) .stream().map(Customer::getBirthDate).collect(Collectors.toList()); } }
Kesimpulan
CUBA adalah kerangka kerja yang fleksibel. Jika Anda ingin menambahkan sesuatu ke dalamnya, maka Anda tidak perlu memperbaiki sendiri kernel atau menunggu versi baru. Saya harap modul ini membuat pengembangan CUBA lebih efisien dan lebih cepat. Versi pertama modul tersedia di GitHub , diuji pada CUBA versi 6.10