Banyak yang curiga terhadap prospek forking dan menulis sesuatu sendiri. Seringkali harganya terlalu tinggi. Sangat aneh mendengar tentang JDK Anda sendiri, yang konon ada di setiap perusahaan yang cukup besar. Apa yang mengamuk dengan lemak? Artikel ini akan menjadi cerita rinci tentang perusahaan, yang semua ini membawa manfaat komersial nyata, dan yang melakukan pekerjaan yang mengerikan, karena mereka:
- Mengembangkan mesin Java virtual multi-penyewa;
- Mereka datang dengan mekanisme untuk pengoperasian objek yang tidak membawa overhead ke pengumpulan sampah;
- Mereka melakukan sesuatu seperti mitra ReadyNow dari Azul Zing;
- Mereka mencuci coroutine mereka sendiri dengan hasil dan kelanjutan (dan bahkan siap untuk berbagi pengalaman mereka dengan Loom, yang saya tulis di musim gugur );
- Mereka mengacaukan semua keajaiban ini dengan subsistem diagnostik mereka sendiri.
Seperti biasa, video, dekripsi teks lengkap, dan slide menunggu Anda di bawah potongan. Selamat datang di neraka salah satu bidang adaptasi proyek open source yang paling sulit!

Dokter, di mana Anda mendapatkan foto-foto seperti itu? O'Reilly Covers Corner: Latar belakang KDPV disediakan oleh Joshua Newton dan menggambarkan Tari Suci Sangyang Jaran di Ubud, Indonesia. Ini adalah pertunjukan klasik Bali yang terdiri dari tarian api dan trance. Seorang laki-laki bertelanjang kaki bergerak di sekitar api unggun, dibesarkan di atas sabut kelapa, mendorong benda-benda dengan kakinya dan menari dalam kondisi trance di bawah pengaruh roh kuda. Ilustrasi sempurna untuk JDK Anda sendiri, bukan?
Slide dan deskripsi laporan (Anda tidak memerlukannya, habratopike ini memiliki semua yang Anda butuhkan).
Halo, nama saya Sanhong Lee, saya bekerja di Alibaba, dan saya ingin berbicara tentang perubahan apa yang kami buat pada OpenJDK untuk kebutuhan bisnis kami. Pos terdiri dari tiga bagian. Pada bagian pertama saya akan berbicara tentang bagaimana Java digunakan di Alibaba. Bagian kedua, menurut saya, adalah yang paling penting - di dalamnya kita akan membahas bagaimana kita mengkonfigurasi OpenJDK untuk kebutuhan bisnis kita. Bagian ketiga adalah tentang alat yang kami buat untuk diagnosis.
Tetapi sebelum pindah ke bagian pertama, saya ingin secara singkat memberi tahu Anda tentang perusahaan kami.
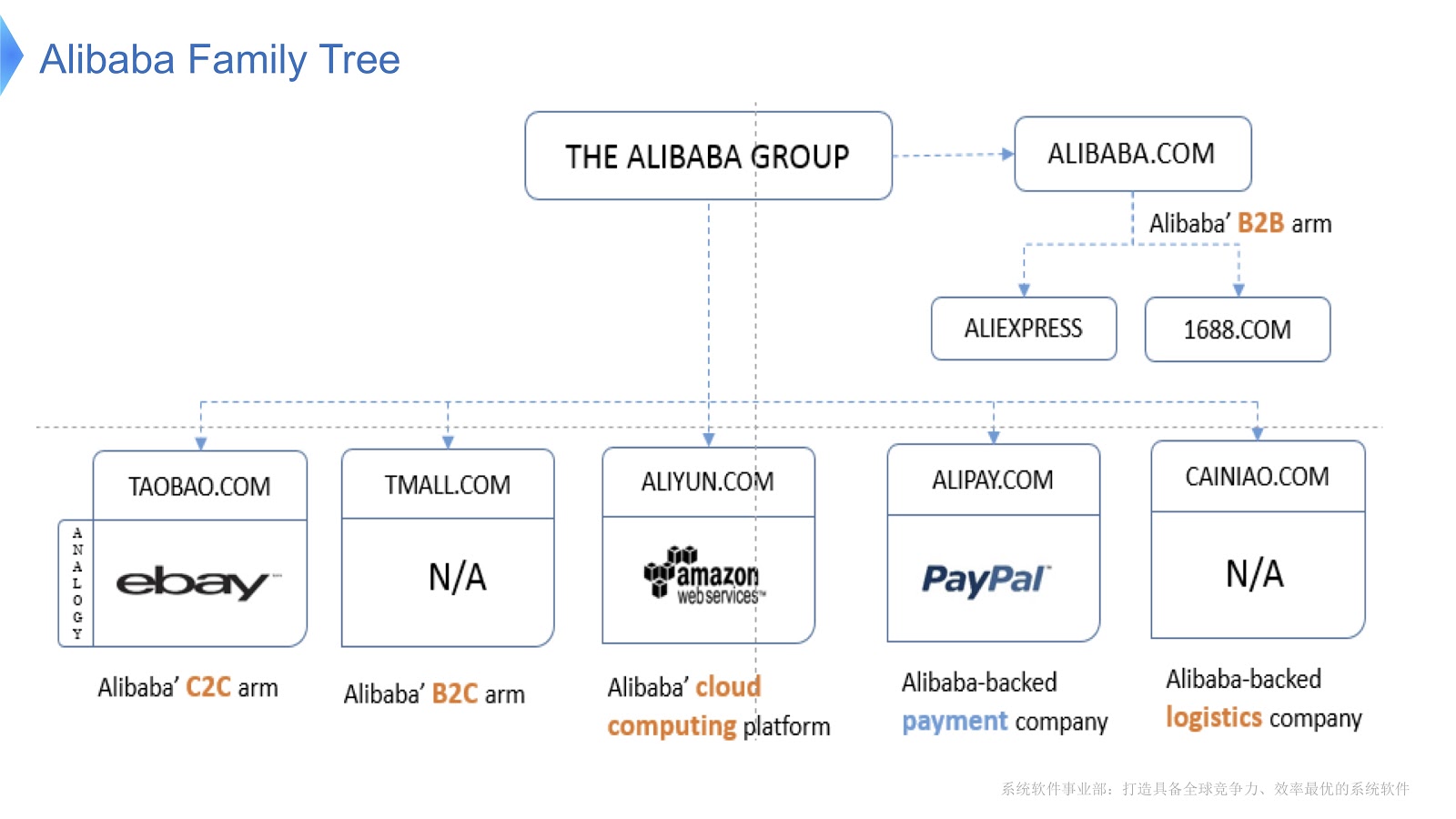
Diagram menunjukkan struktur internal Alibaba. Ini terdiri dari berbagai perusahaan yang spesialisasi utamanya adalah organisasi pasar elektronik dan penyediaan platform finansial dan logistik. Saya pikir sebagian besar orang di Rusia akrab dengan AliExpress. Alibaba memiliki tim programmer yang berdedikasi yang mengembangkan dan mendukung seluruh tumpukan yang didistribusikan, menyediakan layanan kepada pelanggan Aliexpress di seluruh dunia.
Untuk mendapatkan gambaran tentang skala pekerjaan Alibaba, mari kita lihat apa yang terjadi di China pada Hari Singles . Dirayakan setiap tahun pada 11 November, dan pada hari ini orang membeli banyak barang melalui Alibaba. Sejauh yang saya tahu, liburan di seluruh dunia ini adalah yang paling belanja.
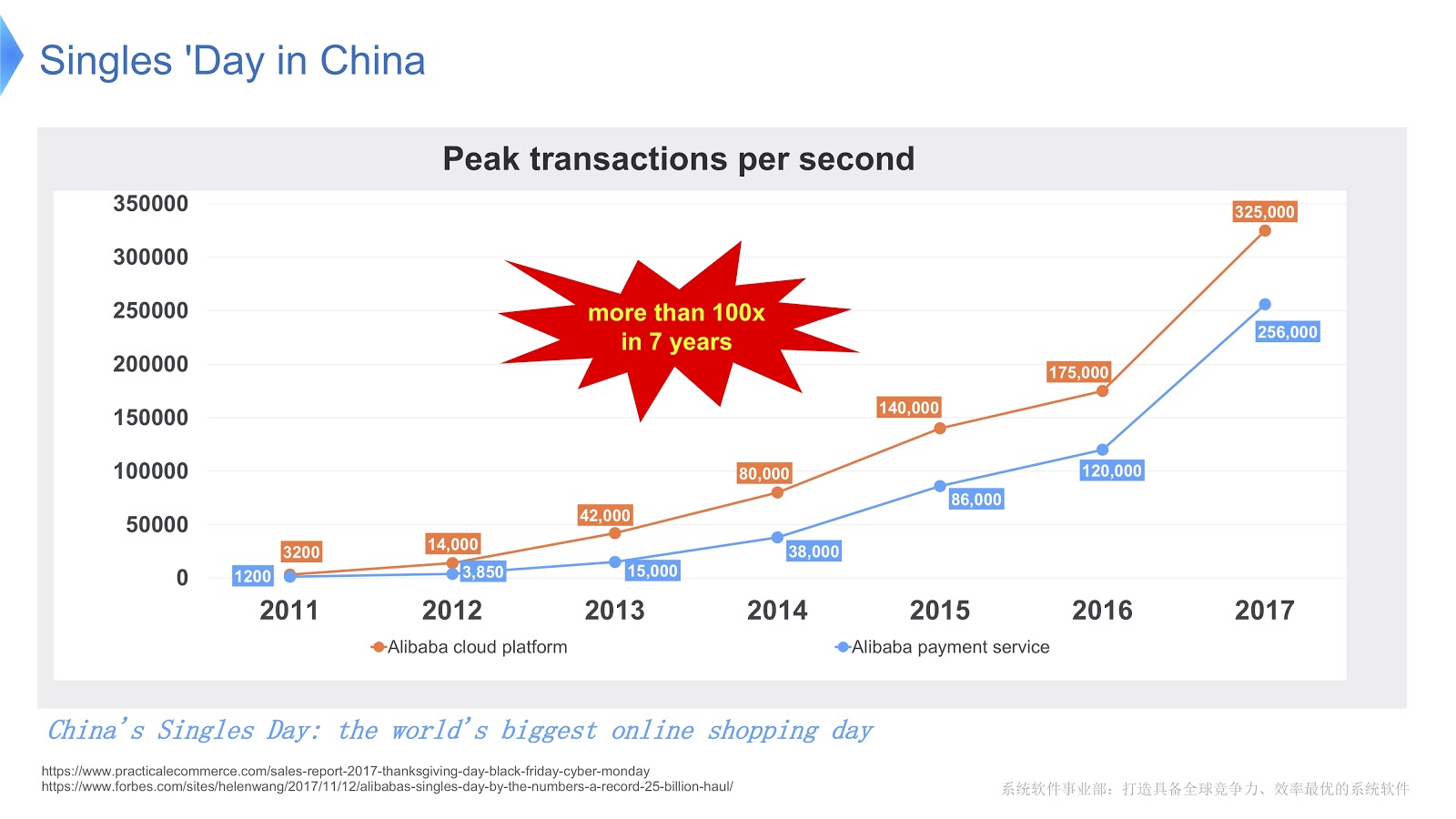
Pada gambar di atas Anda melihat diagram yang menunjukkan beban pada sistem pendukung kami. Garis merah menunjukkan pekerjaan layanan pesanan kami dan menunjukkan jumlah transaksi puncak per detik, tahun lalu berjumlah 325 ribu. Garis biru mengacu pada layanan pembayaran, dan dia memiliki angka 256 ribu. Saya ingin berbicara tentang cara mengoptimalkan tumpukan yang melayani begitu banyak transaksi.
Mari kita bahas teknologi utama yang bekerja di Alibaba dengan Java. Pertama-tama, saya harus mengatakan bahwa kami memiliki sejumlah aplikasi open source sebagai dasarnya. Untuk pemrosesan data besar kami menggunakan HBase Hadoop. Sebagai wadah kami menggunakan Tomcat dan OSGi. Java digunakan pada skala kolosal - jutaan instance JVM digunakan di pusat data kami. Harus juga dikatakan bahwa arsitektur kami berorientasi pada layanan, yaitu, kami membuat banyak layanan yang berkomunikasi satu sama lain menggunakan panggilan RPC. Akhirnya, arsitektur kami heterogen. Untuk meningkatkan kinerja, banyak algoritma ditulis menggunakan pustaka C dan C ++, sehingga mereka berkomunikasi dengan Java menggunakan panggilan JNI.

Sejarah pekerjaan kami dengan OpenJDK dimulai pada 2011, selama OpenJDK 6. Ada tiga alasan penting mengapa kami memilih OpenJDK. Pertama, kita dapat langsung mengubah kodenya sesuai dengan kebutuhan bisnis. Kedua, ketika masalah mendesak muncul, kita dapat menyelesaikannya sendiri lebih cepat daripada menunggu rilis resmi. Ini sangat penting untuk bisnis kami. Ketiga, pengembang Java kami menggunakan alat kami sendiri untuk debugging dan diagnostik yang cepat dan berkualitas tinggi.
Sebelum beralih ke masalah teknis, saya ingin membuat daftar kesulitan utama yang harus kita atasi. Pertama, kami telah meluncurkan sejumlah besar contoh JVM - dalam situasi ini, pertanyaan tentang pengurangan biaya perangkat keras adalah masalah akut. Kedua, saya sudah mengatakan bahwa kami melayani sejumlah besar transaksi. Berkat pengumpul sampah, Java menjanjikan kita "memori tak terbatas". Selain itu, ia menang dalam kinerja pada level rendah berkat kompiler JIT. Tetapi ini juga memiliki sisi lain: waktu berhenti yang lebih lama di dunia untuk pengumpulan sampah. Selain itu, Java membutuhkan siklus CPU tambahan untuk mengkompilasi metode Java. Ini berarti bahwa kompiler bersaing untuk siklus CPU. Kedua masalah memburuk karena aplikasi menjadi lebih kompleks.
Kesulitan ketiga adalah kita memiliki banyak aplikasi yang berjalan. Saya pikir semua orang di sini akrab dengan alat yang datang dengan OpenJDK, seperti JConsole atau VisualVM. Masalahnya adalah mereka tidak memberi kami informasi persis yang perlu kami konfigurasi. Selain itu, ketika kami menggunakan alat ini (misalnya, JConsole atau VisualVM) dalam produksi, overhead yang rendah bukan hanya keinginan, tetapi persyaratan yang diperlukan. Saya harus menulis alat diagnostik saya sendiri.

Gambar tersebut menguraikan perubahan yang kami lakukan pada OpenJDK. Mari kita lihat bagaimana kita mengatasi kesulitan yang saya bicarakan di atas.
JVM Multi-Tenant
Salah satu solusi yang kami sebut JVM multi-tenant. Ini memungkinkan Anda menjalankan banyak aplikasi web dengan aman dalam satu wadah. Solusi lain disebut GCIH (GC Invisible Heap). Ini adalah mekanisme yang memberi Anda objek Java lengkap, yang pada saat yang sama tidak memerlukan biaya pengumpulan sampah. Selanjutnya, untuk mengurangi biaya konteks utas, kami menerapkan coroutine pada platform Java kami. Selain itu, kami menulis mekanisme yang disebut JWarmup - fungsinya sangat mirip dengan ReadyNow. Douglas Hawkins tampaknya telah menyebutkannya dalam laporannya . Akhirnya, kami mengembangkan alat profil kami sendiri, ZProfiler.
Mari kita lihat lebih dekat bagaimana kita mengimplementasikan multi-tenancy berbasis OpenJDK.
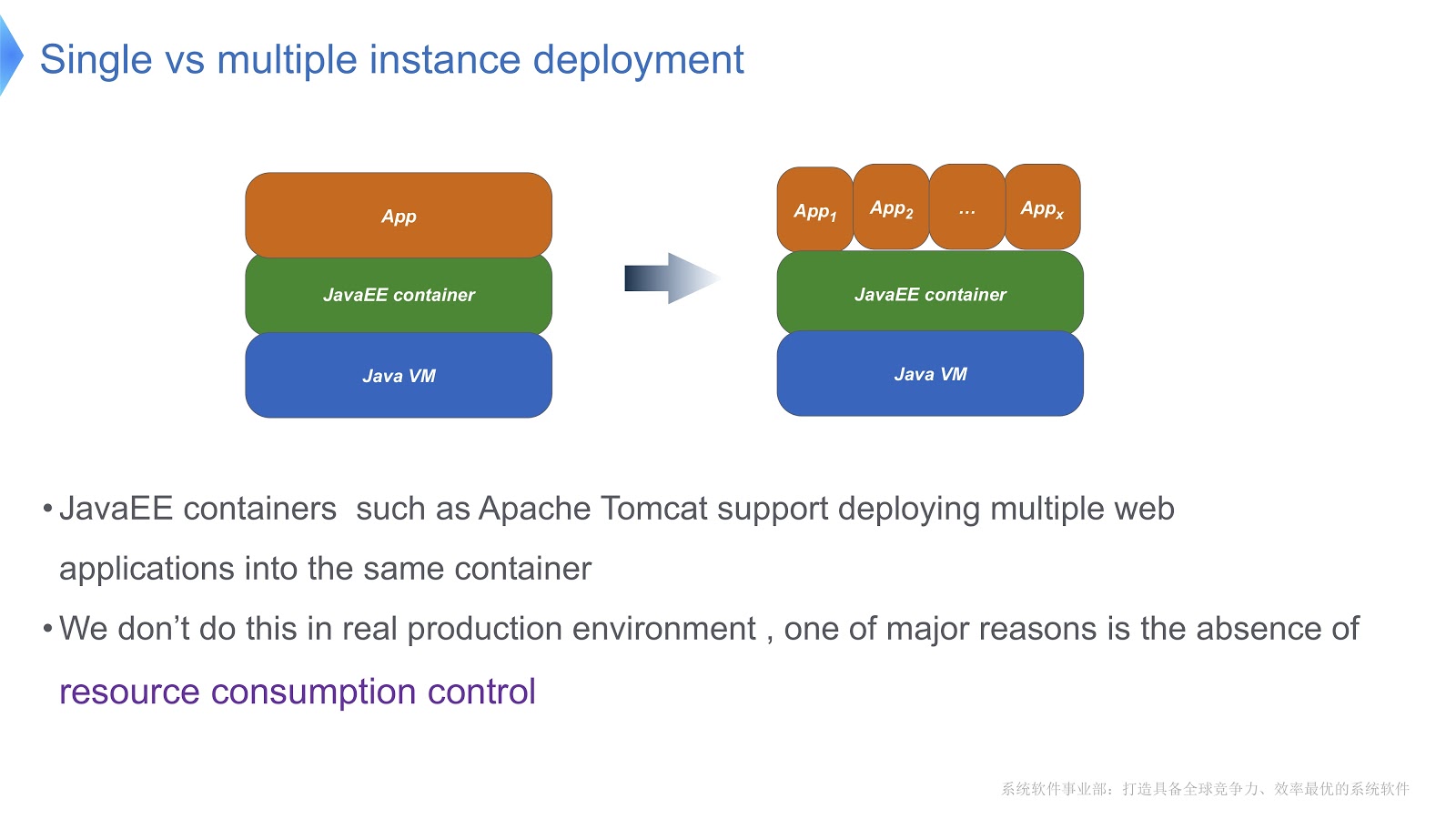
Lihatlah gambar di atas - saya pikir sebagian besar dari Anda sudah terbiasa dengan pola ini. Bandingkan pendekatan tradisional dengan multi-tenant. Jika aplikasi Anda berjalan menggunakan Apache Tomcat, Anda juga dapat menjalankan beberapa instance dalam wadah yang sama. Tetapi Tomcat tidak menyediakan konsumsi sumber daya yang stabil untuk masing-masing dari mereka. Katakanlah, jika salah satu aplikasi yang berjalan membutuhkan lebih banyak waktu CPU daripada yang lain, bagaimana Anda akan mengontrol alokasi waktu CPU? Bagaimana memastikan bahwa aplikasi ini tidak memengaruhi pekerjaan orang lain? Terutama pertanyaan inilah yang membuat kami beralih ke teknologi multitenant.
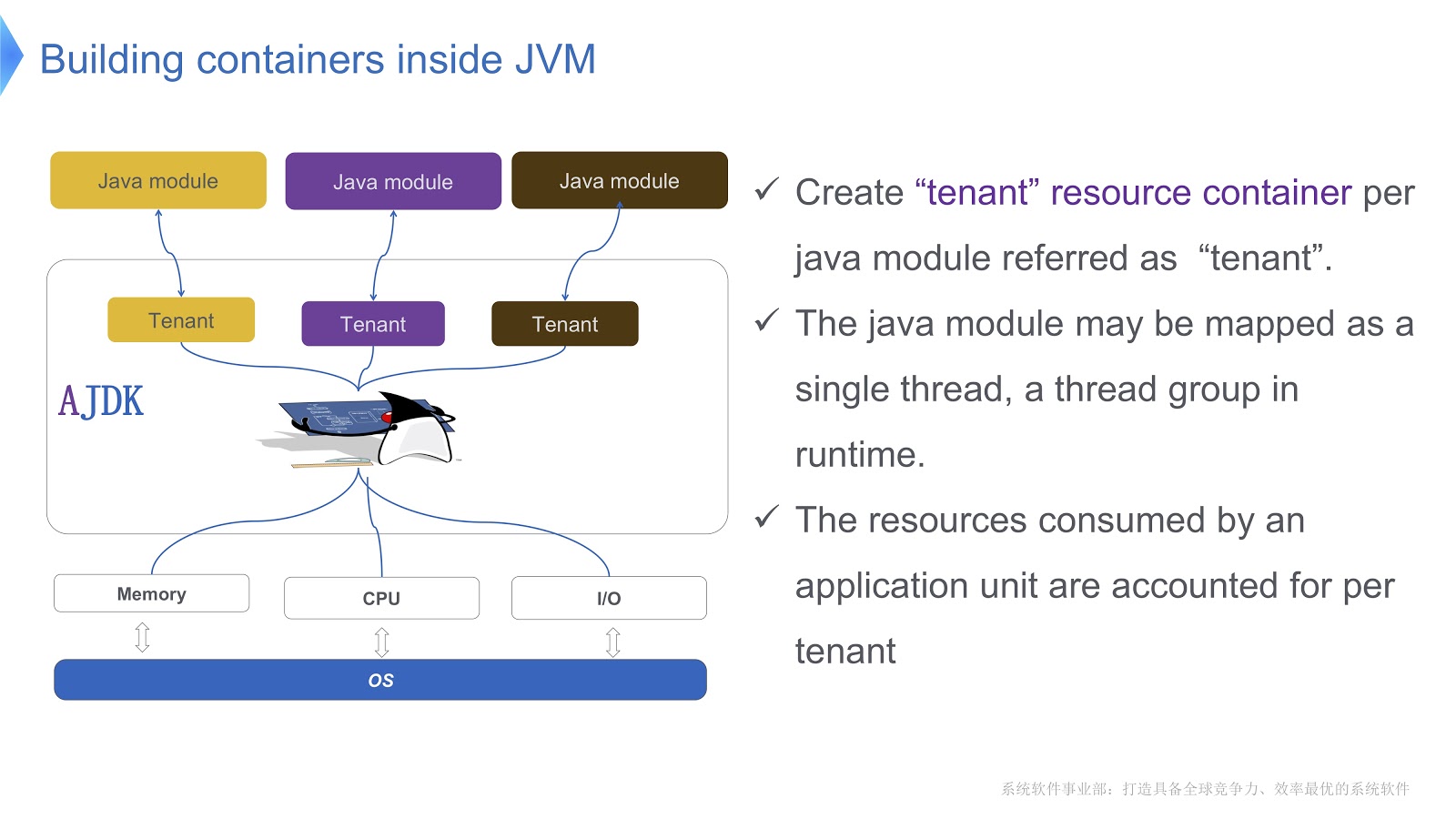
Gambar ini secara skematis menunjukkan bagaimana kami menerapkannya. Kami membuat beberapa kontainer untuk penyewa di dalam JVM. Masing-masing wadah ini menyediakan kontrol konsumsi sumber daya yang dapat diandalkan untuk setiap modul Java. Beberapa modul dapat digunakan dalam satu wadah. Setiap modul dapat dikaitkan dengan satu utas atau grup utas dalam runtime.
Mari kita lihat seperti apa bentuk wadah penyewa API. Kami memiliki kelas konfigurasi penyewa yang menyimpan informasi tentang konsumsi sumber daya. Selanjutnya, ada kelas wadah itu sendiri.
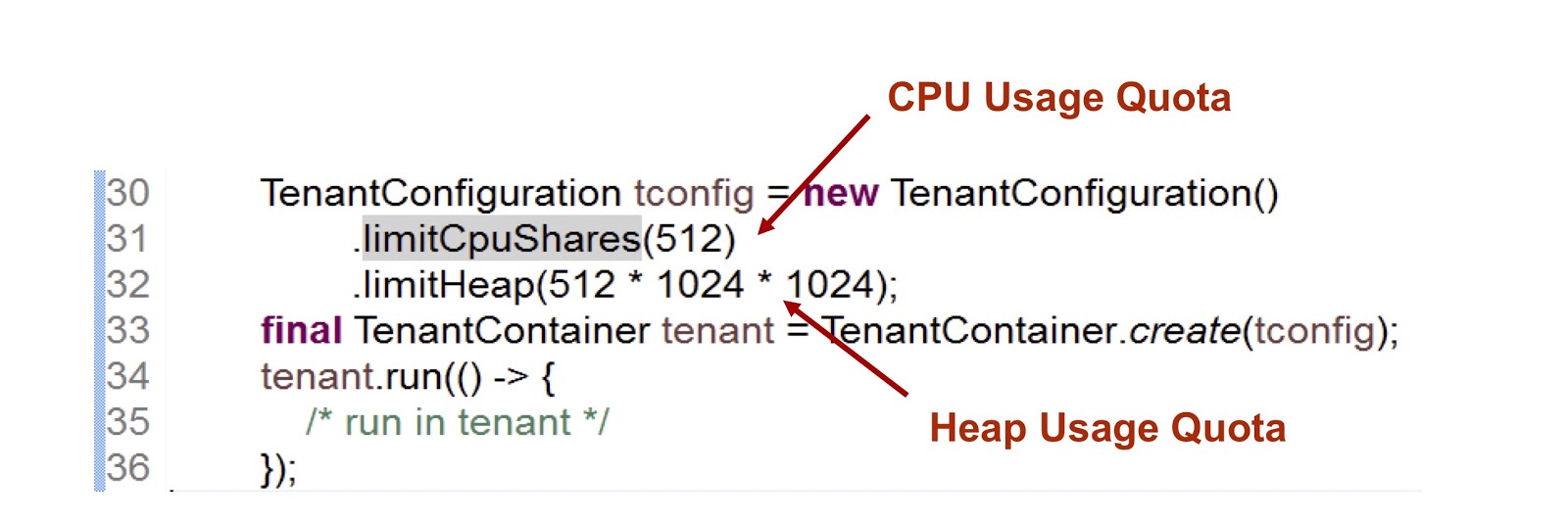
Dalam cuplikan kode yang disajikan, kami membuat satu penyewa, dan kemudian menunjukkan berapa banyak waktu yang disediakan CPU dan memori untuknya. Indikator pertama adalah bilangan bulat, yang berarti bagian dari waktu CPU tersedia untuk penyewa, dalam hal ini kami menunjukkan 512. Kami menggunakan pendekatan yang sangat mirip dalam kasus cgroup, saya akan membahas ini lebih terinci. Metrik kedua adalah ukuran tumpukan maksimum yang bisa digunakan penyewa.
Pertimbangkan bagaimana penyewa berinteraksi dengan utas. Kelas TenantContainer menyediakan metode .run() , dan ketika sebuah thread masuk, ia secara otomatis menempel ke penyewa, dan ketika meninggalkannya, prosedur sebaliknya terjadi. Jadi semua kode dieksekusi di dalam metode .run() . Selain itu, setiap utas yang dibuat di dalam metode .run() dilampirkan pada penyewa dari induk thread.
Kami sampai pada pertanyaan yang sangat penting - bagaimana CPU dikelola dalam multi-tenant JVM? Solusi kami baru saja diterapkan pada platform Linux x64. Ada mekanisme kelompok kontrol, cgroup. Ini memungkinkan Anda untuk memilih proses dalam grup terpisah, dan kemudian menunjukkan mode konsumsi sumber daya Anda untuk setiap grup. Mari kita coba transfer pendekatan ini ke konteks JVM Hotspot. Di Hotstpot, utas Java disusun sebagai utas asli.

Ini ditunjukkan dalam diagram di atas: setiap utas Java dalam korespondensi satu-ke-satu dengan utas asli. Dalam contoh kami, kami memiliki wadah TenantA , di mana ada dua utas asli. Agar dapat mengontrol distribusi waktu CPU, kami menempatkan kedua utas asli dalam satu grup kontrol. Karena ini, kita dapat mengatur konsumsi sumber daya, hanya mengandalkan fungsi dari [kelompok kontrol] ( https://en.wikipedia.org/wiki/Cgroups ).
Mari kita lihat contoh yang lebih rinci.
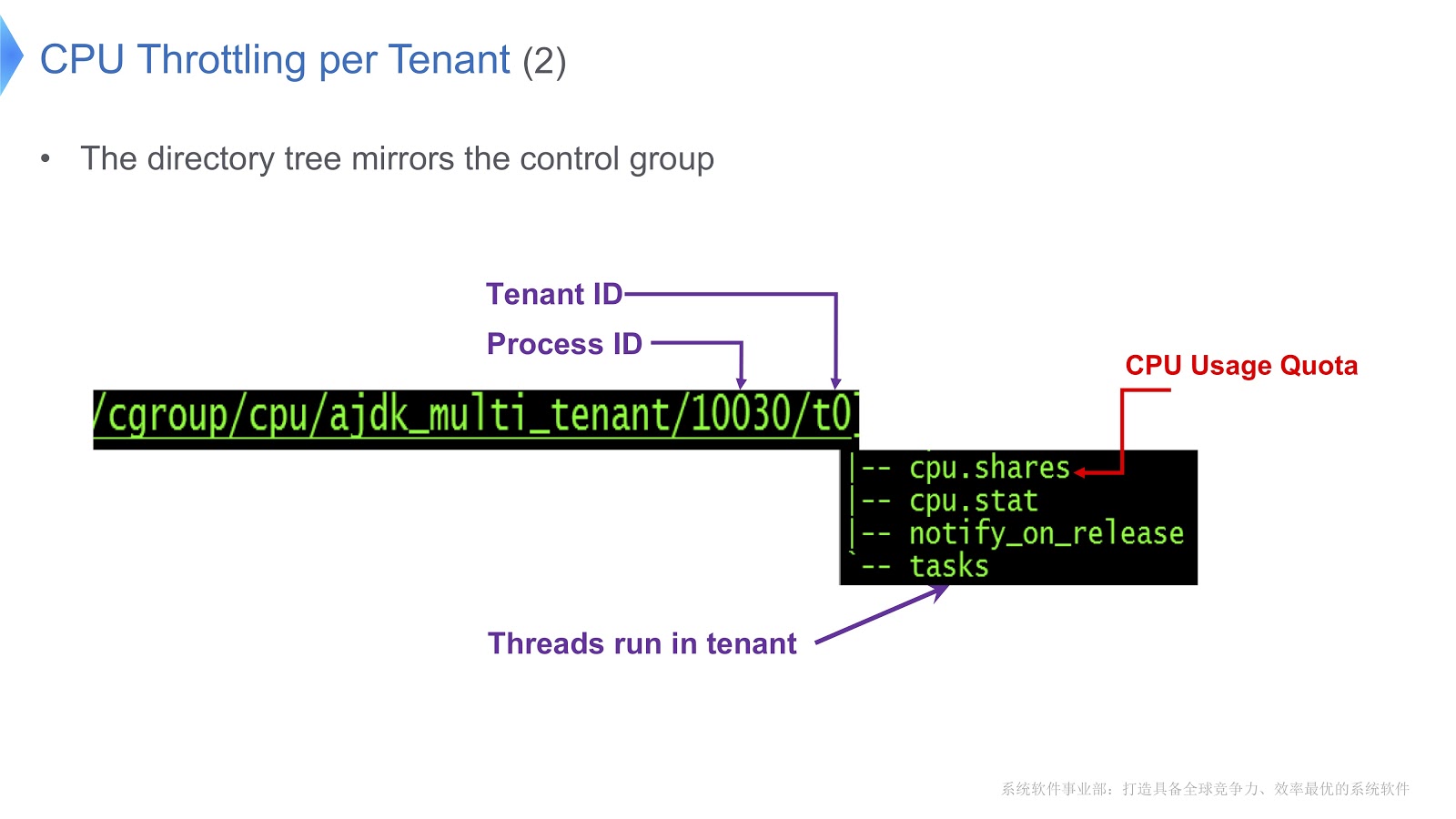
Grup kontrol di Linux dipetakan ke direktori. Dalam contoh kami, kami membuat direktori /t0 untuk tenant 0. Direktori ini berisi direktori /t0/tasks , semua utas untuk t0 akan berlokasi di sini. File penting lainnya adalah /t0/cpu.shares . Ini menunjukkan berapa banyak waktu CPU akan diberikan kepada penyewa ini. Seluruh struktur ini diwarisi dari kelompok kontrol - kami hanya memastikan korespondensi langsung antara utas Java, utas asli dan grup kontrol.
Masalah penting lainnya terkait dengan mengelola sekelompok penyewa.
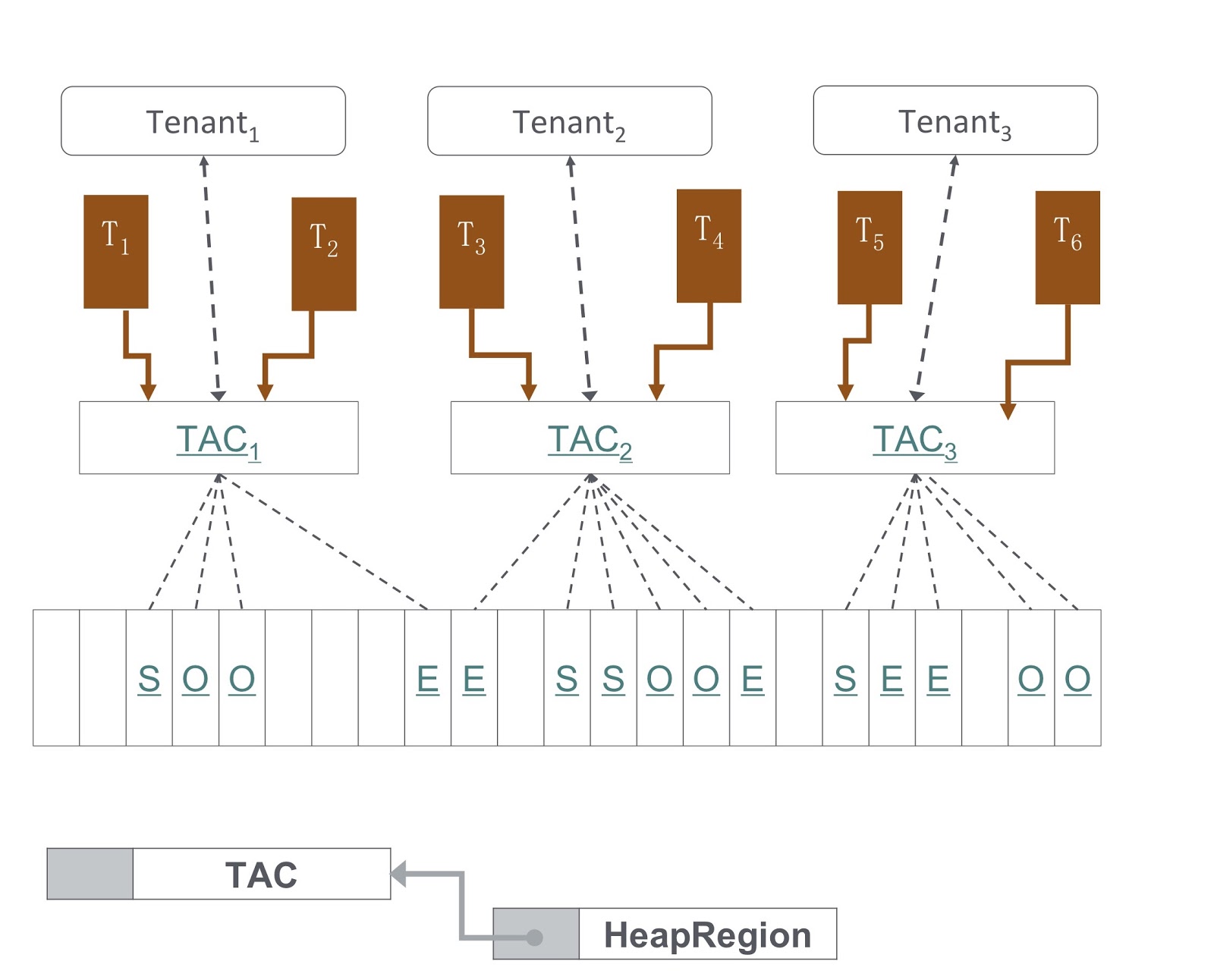
Pada gambar Anda melihat diagram bagaimana itu diterapkan. Pendekatan kami didasarkan pada G1GC. Di bagian bawah gambar, G1GC membagi tumpukan menjadi beberapa bagian dengan ukuran yang sama. Berdasarkan mereka, kami membuat Konteks Alokasi Penyewa, TAC, yang digunakan penyewa untuk mengelola bagian tumpukannya. Melalui TAC, kami membatasi ukuran bagian tumpukan yang tersedia untuk penyewa. Di sini, prinsip berlaku, yang menurutnya setiap bagian tumpukan berisi objek hanya satu penyewa. Untuk mengimplementasikannya, kami perlu membuat perubahan pada proses menyalin objek selama pengumpulan sampah - itu perlu untuk memastikan bahwa objek itu disalin ke bagian yang benar dari tumpukan.
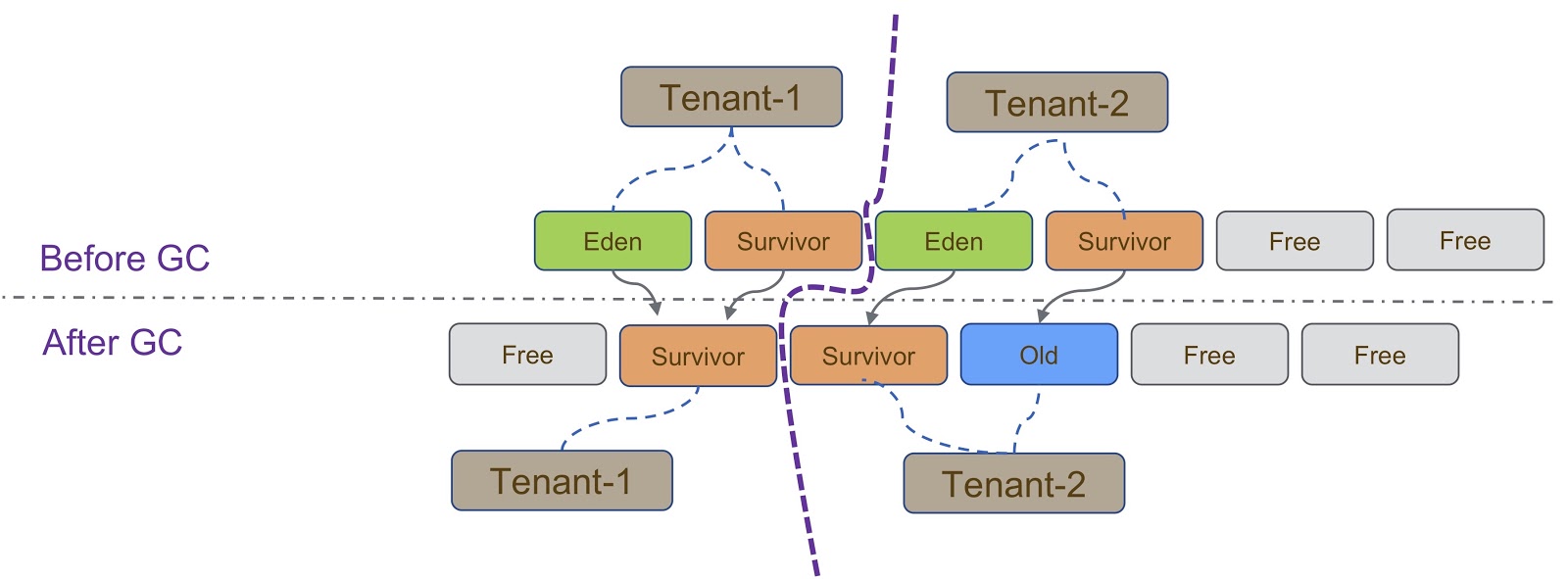
Secara skematis, proses ini digambarkan dalam diagram di atas. Seperti yang saya katakan, implementasi kami didasarkan pada G1GC. G1GC adalah pengumpul sampah penyalinan, jadi selama pengumpulan sampah kita perlu memastikan bahwa objek disalin ke bagian heap yang benar. Pada slide, semua objek yang dibuat oleh Tenant-1 harus disalin ke bagian tumpukannya, mirip dengan Tenant-2 .
Ada pertimbangan lain yang muncul ketika penyewa terisolasi satu sama lain. Di sini saya harus mengatakan tentang TLAB (Thread Local Allocation Buffer) - sebuah mekanisme untuk alokasi memori yang cepat. Ruang TLAB tergantung pada bagian heap. Seperti yang saya katakan, penyewa berbeda memiliki kelompok yang berbeda dari bagian tumpukan.

Spesifikasi bekerja dengan TLAB ditunjukkan pada slide - ketika utas beralih dari Tenant 1 ke Tenant 2 , kita perlu memastikan bahwa bagian heap yang benar digunakan untuk ruang TLAB. Ini bisa dicapai dengan dua cara. Cara pertama adalah ketika Thread A beralih dari Tenant 1 ke Tenant 2 , kita cukup singkirkan yang lama dan buat yang baru di Tenant 2 . Metode ini relatif mudah diimplementasikan, tetapi membuang-buang ruang di TLAB, yang tidak diinginkan. Cara kedua lebih rumit - untuk membuat TLAB mengetahui penyewa. Ini berarti bahwa kami akan memiliki beberapa buffer TLAB untuk satu utas. Ketika Thread A beralih dari Tenant 1 ke Tenant 2 , kita perlu mengubah buffer dan menggunakan buffer yang dibuat di Tenant 2 .
Mekanisme lain yang perlu dikatakan sehubungan dengan pembatasan penyewa adalah IHOP (Initiating Thread Occupancy Perscent). Awalnya, IHOP dihitung berdasarkan seluruh heap, tetapi dalam kasus mekanisme multitenant, harus dihitung berdasarkan hanya satu bagian heap.
Mari kita lihat lebih dekat apa itu GCIH (GC Invisible Heap). Mekanisme ini menciptakan bagian pada heap, disembunyikan dari pengumpul sampah, dan, karenanya, tidak terpengaruh oleh pengumpulan sampah. Situs ini dikelola oleh penyewa GCIH.

Penting untuk mengatakan di sini bahwa kami menyediakan API publik untuk pengembang Java kami. Contoh bekerja dengannya dapat dilihat di layar. Itu memungkinkan menggunakan metode moveIn() untuk memindahkan objek dari heap biasa ke bagian heap GCIH. Keuntungannya adalah Anda masih dapat berinteraksi dengan objek-objek ini seperti objek Java biasa, strukturnya sangat mirip. Tetapi pada saat yang sama mereka tidak memerlukan biaya pengumpulan sampah. Kesimpulannya, menurut saya, adalah jika Anda ingin mempercepat pengumpulan sampah, Anda perlu menyesuaikan perilaku pengumpul sampah sesuai dengan kebutuhan aplikasi Anda.
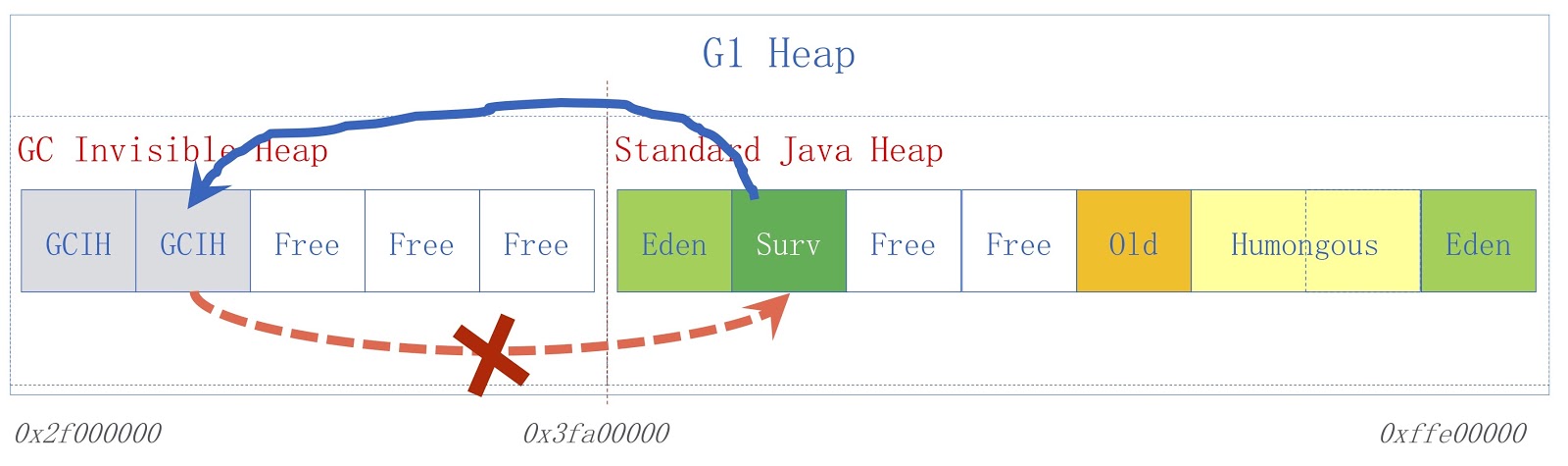
Gambar menunjukkan skema GCIH tingkat tinggi. Di sebelah kanan adalah tumpukan Java biasa, di sebelah kiri adalah ruang yang dialokasikan untuk GCIH. Tautan dari tumpukan reguler ke objek di GCIH valid, tetapi tautan dari GCIH ke tumpukan biasa tidak. Untuk memahami mengapa demikian, pertimbangkan sebuah contoh. Kami memiliki objek "A" di GCIH, yang berisi referensi ke objek "B" di tumpukan reguler. Masalahnya adalah bahwa objek B dapat dipindahkan oleh pengumpul sampah. Seperti yang sudah saya katakan, kami tidak melakukan pembaruan di GCIH, jadi setelah pengumpul sampah bekerja, objek "A" mungkin berisi referensi yang tidak valid ke objek "B". Masalah ini dapat diselesaikan dengan menggunakan penghalang pra-tulis - mereka telah dibahas dalam laporan sebelumnya. Sebagai contoh, misalkan seseorang perlu menyimpan tautan dari tumpukan Java reguler ke GCIH sebelum penyimpanan yang kami asumsikan akan menghasilkan pengecualian prediktor dengan tanda indikator bahwa aturan tersebut dilanggar.
Untuk aplikasi tertentu, JVM multi-tenant digunakan di Platform Personalisasi Taobao kami, disingkat TPP. Ini adalah sistem rekomendasi untuk aplikasi e-shopping kami. TPP dapat menggunakan beberapa layanan microser dalam satu wadah, dan dengan bantuan multi-tenant JVM kami mengontrol memori dan waktu CPU yang disediakan untuk setiap layanan microser.
Adapun GCIH, digunakan di sistem kami yang lain, Platform UM. Ini adalah aplikasi diskon online. Pemilik aplikasi ini menggunakan GCIH untuk melakukan pra-cache data GCIH pada mesin lokal, agar tidak mengakses objek pada server cache jarak jauh atau basis data jauh. Sebagai hasilnya, kami mengurangi beban pada jaringan dan melakukan lebih sedikit serialisasi dan deserialisasi.
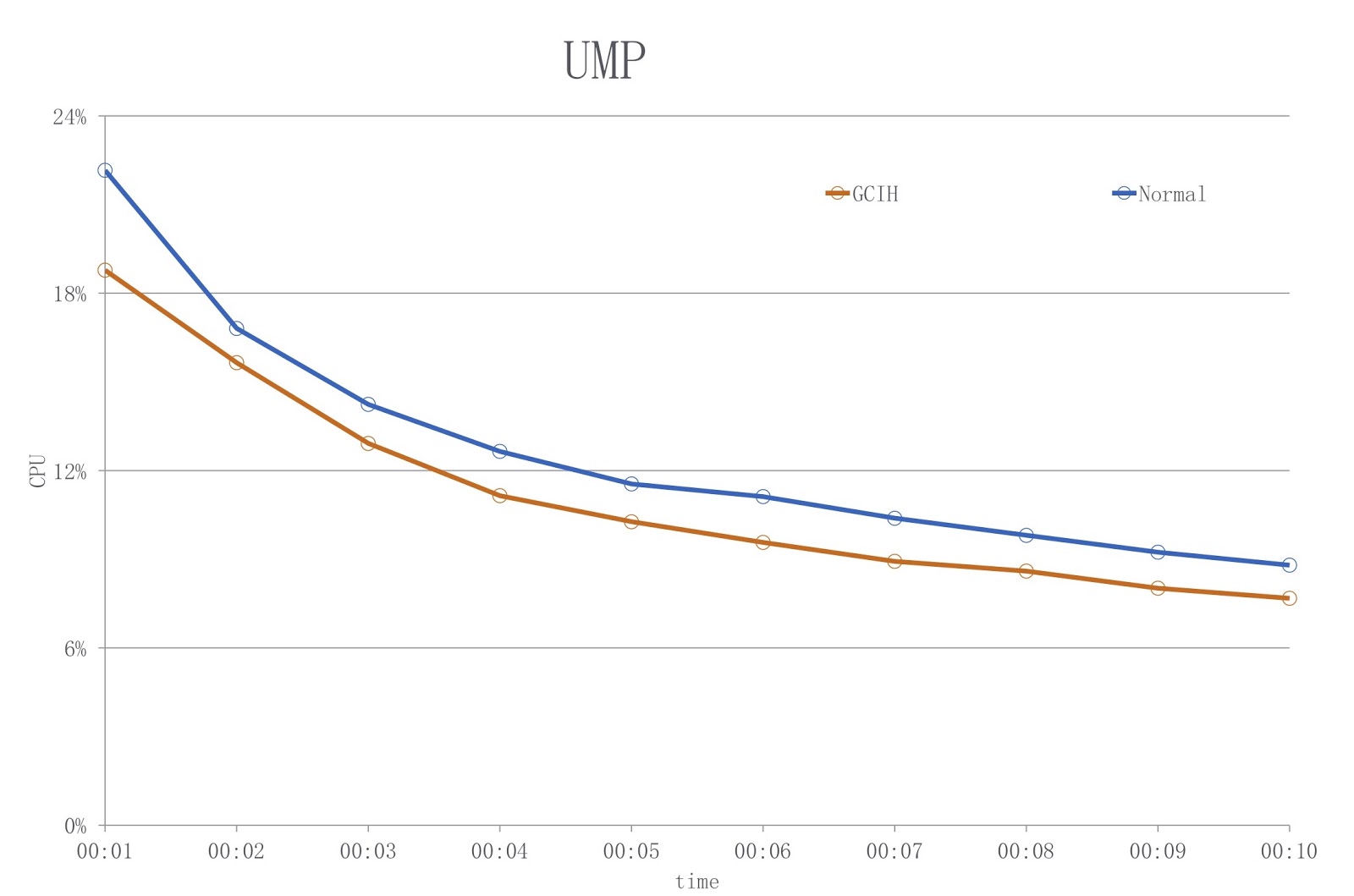
Gambar menunjukkan diagram di mana warna biru menunjukkan beban saat menggunakan JDK konvensional, dan merah - GCIH. Seperti yang Anda lihat, kami mengurangi penggunaan CPU lebih dari 18%.
Sejauh yang saya tahu, masalah serupa diselesaikan oleh BellSoft , dan solusi mereka mirip dengan GCIH, tetapi mereka menggunakan pendekatan yang berbeda untuk mengurangi biaya serialisasi dan deserialisasi.
Coroutine di Jawa
Mari kita kembali ke Alibaba dan melihat bagaimana coroutine dapat diimplementasikan di Jawa. Tapi pertama-tama, mari kita bicara tentang asal-usulnya, mengapa kita perlu melakukan ini. Di Jawa, selalu sangat mudah untuk menulis aplikasi multithreading. Tetapi masalah dengan membuat aplikasi seperti itu adalah, seperti yang saya katakan, di Hotspot Java utas sudah diimplementasikan sebagai utas asli. Karena itu, ketika ada banyak utas dalam aplikasi Anda, biaya untuk mengubah konteks utas menjadi sangat tinggi.

Pertimbangkan contoh di mana kita akan memiliki 4 utas / 200 utas dan 200 utas dengan logika aplikasi Anda. Tabel di layar menunjukkan hasil memulai demo sederhana ini - Anda dapat melihat berapa banyak waktu yang diperlukan CPU untuk mengubah konteks. Solusi untuk masalah ini mungkin implementasi corutin di Jawa.
Untuk menyediakannya, kami membutuhkan dua hal. Pertama, Alibaba JDK perlu menambahkan dukungan lanjutan. Pekerjaan ini didasarkan pada tambalan JKU, kami akan membahasnya lebih terinci. Kedua, kami menambahkan sheduler mode pengguna yang akan bertanggung jawab untuk kelanjutan di utas. Ketiga, ada banyak aplikasi di Alibaba. Oleh karena itu, solusi kami sangat penting bagi pengembang Java kami, dan itu perlu untuk membuatnya benar-benar transparan bagi mereka. Dan ini berarti bahwa dalam aplikasi bisnis kita seharusnya praktis tidak ada perubahan dalam kode. Kami menyebut solusi kami Wisp. Implementasi coroutine kami di Jawa banyak digunakan di Alibaba, sehingga dapat dibuktikan terbukti bekerja di Jawa. Kenali dia lebih detail.

Mari kita mulai dengan contoh, kode yang disajikan di atas - ini adalah aplikasi Java yang benar-benar biasa. Pertama, kumpulan thread dibuat. Kemudian tugas Runnable lain dibuat yang menerima soket. Setelah itu, pembacaan dari aliran dilakukan. Selanjutnya, kita membuat tugas Runnable lain, yang dengannya kita terhubung ke server dan, akhirnya, menulis data ke aliran. Seperti yang Anda lihat, semuanya terlihat cukup standar. Jika Anda menjalankan kode pada JDK biasa, masing-masing tugas Runnable ini akan dieksekusi di utas terpisah. Tetapi dalam keputusan kami, mekanisme akan sangat berbeda.
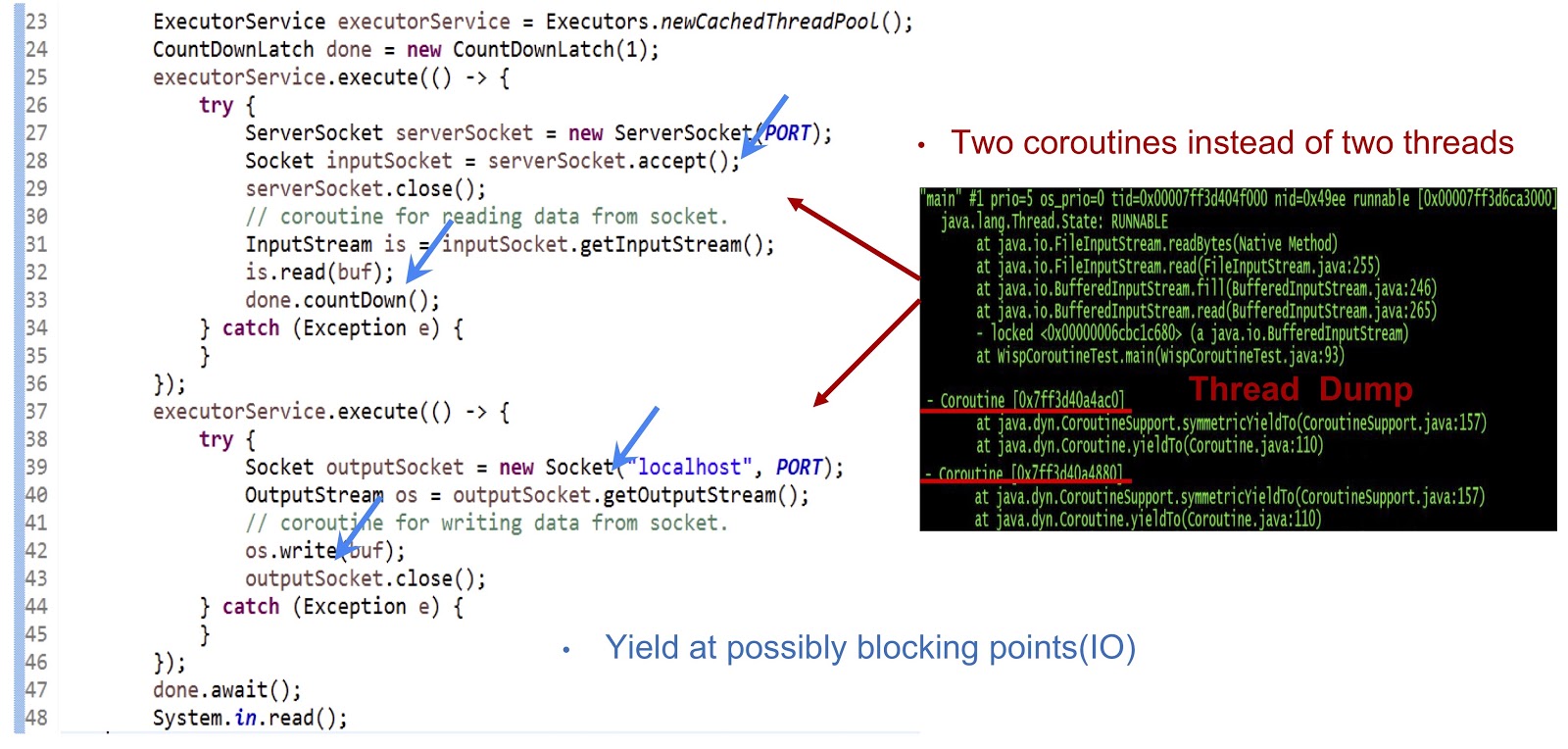
Seperti yang dapat Anda lihat dari tumpukan utas yang ditampilkan pada slide, kami membuat dua coroutine dalam satu utas, dan bukan dua utas. Sekarang Anda perlu membuat solusi ini berfungsi. Hal utama di sini adalah membuat yieldTo menghasilkan acara di semua titik pemblokiran yang memungkinkan. Dalam contoh kita, titik-titik ini akan menjadi serverSocket.accept() , is.read(buf) , koneksi socket, dan os.write(buf) . Berkat menghasilkan acara pada titik-titik ini, kami akan dapat mentransfer kontrol dari satu coroutine ke yang lain dalam utas yang sama. Sebagai rangkuman, pendekatan kami adalah kami mencapai kinerja asinkron menggunakan coroutine, tetapi programmer kami dapat menulis kode dengan gaya sinkron, karena kode tersebut jauh lebih sederhana dan lebih mudah untuk dirawat dan didebug.
Mari kita lihat persis bagaimana kami memberikan dukungan lanjutan di Alibaba JDK. Seperti yang saya katakan, pekerjaan ini didasarkan pada proyek mesin virtual multibahasa yang dibuat oleh komunitas - ini berada dalam domain publik. Kami menggunakan patch ini di Alibaba JDK dan memperbaiki beberapa bug yang terjadi di lingkungan produksi kami.
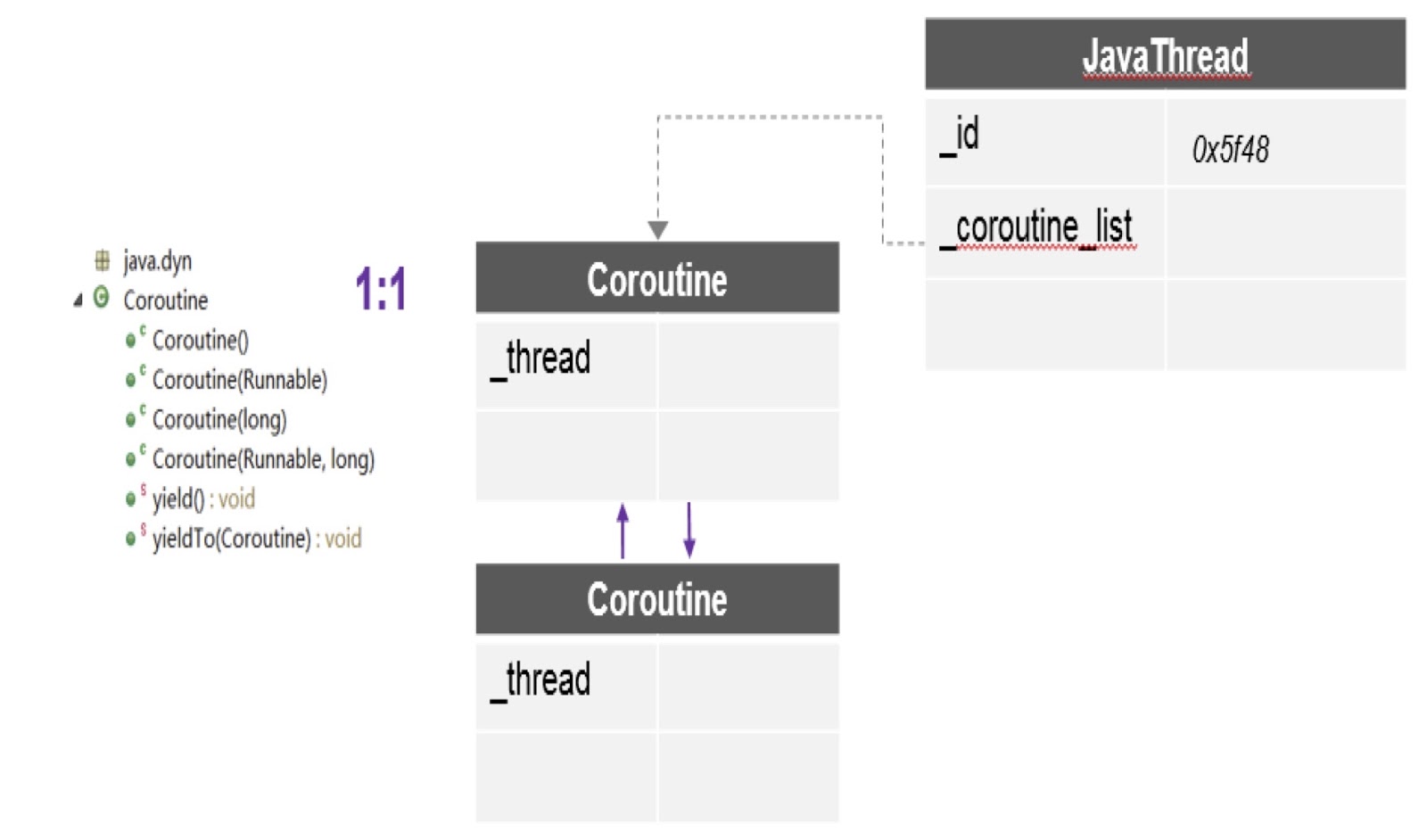
Seperti yang dapat Anda lihat pada diagram, di sini dalam satu utas terdapat beberapa coroutine, dan untuk masing-masing tumpukan dibuat. Selain itu, tambalan yang saya bicarakan memberi kami API paling penting di sini - yieldTo, dengan bantuan kontrol yang ditransfer dari satu coroutine ke yang lain.
Mari kita beralih ke bagaimana kita menerapkan sheduler mode pengguna untuk coroutine. Kami menggunakan pemilih, dan dengan itu kami mendaftarkan beberapa saluran. Ketika ada peristiwa I / O (soket baca, soket tulis, soket terhubung atau soket terima) terjadi, itu ditulis sebagai kunci untuk pemilih. Karena itu, di akhir acara ini, kami menerima peringatan dari pemilih. Dengan demikian, kami menggunakan pemilih untuk merencanakan coroutine jika terjadi kunci I / O. Pertimbangkan contoh bagaimana ini akan bekerja.
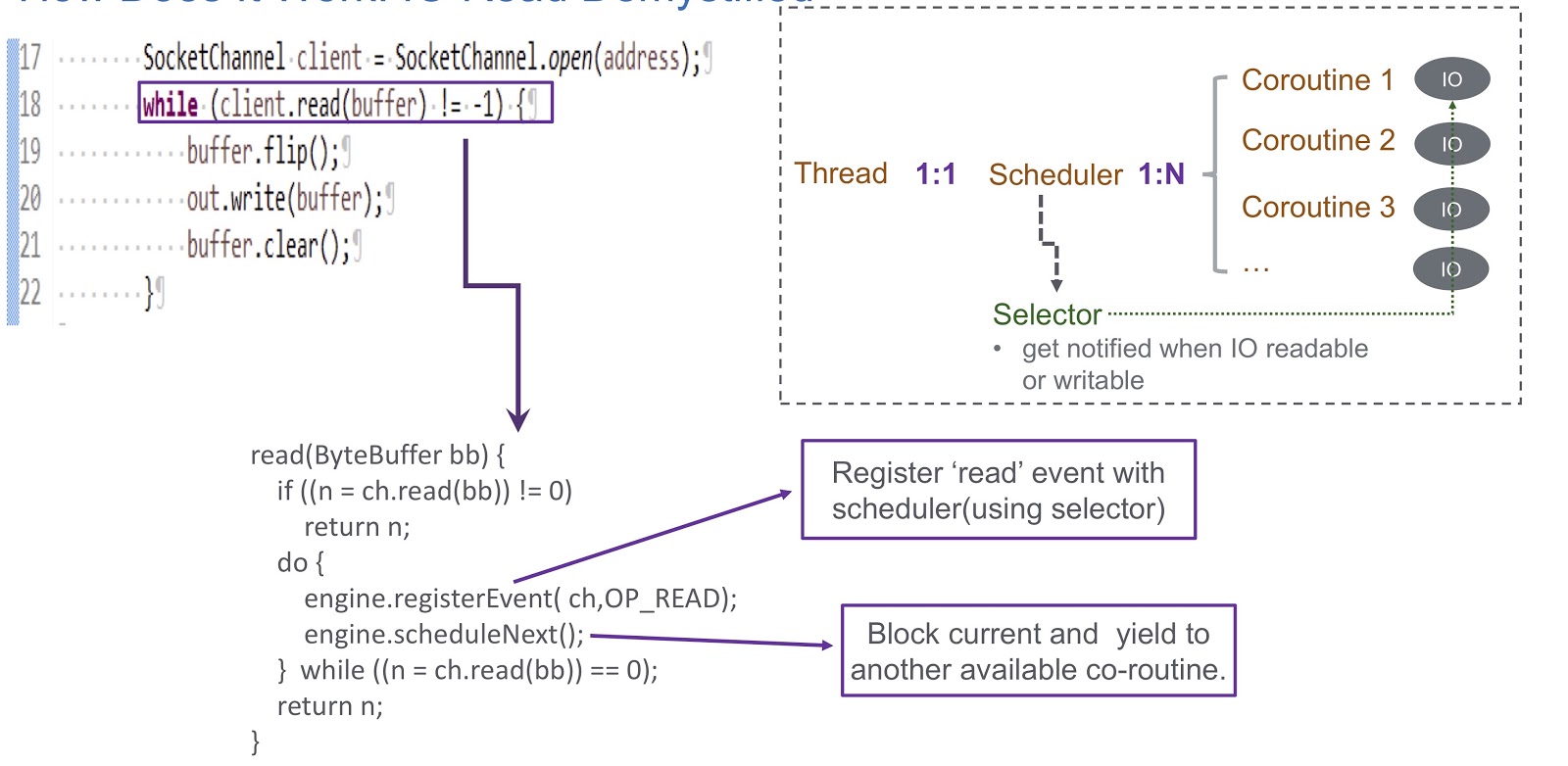
Dalam gambar kita melihat soket dan panggilan client.read(buffer) sinkron. client.read(buffer) . Di bagian bawah slide, tertulis kode yang akan dieksekusi di dalam panggilan ini. Pertama, memeriksa apakah mungkin untuk membaca dari saluran atau tidak. Jika demikian, maka kami mengembalikan hasilnya. Hal yang paling menarik terjadi jika membaca tidak dapat dilakukan. Kemudian kami mendaftarkan acara baca di penjadwal kami dengan pemilih. Ini memungkinkan untuk merencanakan eksekusi coroutine lainnya. Lihatlah bagaimana ini terjadi. Kami memiliki utas tempat penjadwal dibuat. Utas dan coroutine kami saling berhubungan satu sama lain. Sheduler memungkinkan kita untuk mengelola coroutine dari utas ini. Apa yang terjadi jika I / O diblokir? Ketika peristiwa I / O terjadi, sheduler menerima peringatan, dan dalam situasi ini ia sepenuhnya bergantung pada pemilih. Setelah kejadian seperti itu, sheduler mendapat kesempatan untuk merencanakan coroutine berikutnya yang tersedia.
Mari meringkas ikhtisar sheduler kami, yang kami sebut WispEngine. Untuk setiap utas kami, kami mengalokasikan WispEngine terpisah. Ketika kunci coroutine terjadi, kami mencatat peristiwa tertentu (soket baca / tulis dan sebagainya) menggunakan WispEngine. Beberapa acara terkait dengan parkir ulir, misalnya, jika Anda menelepon thread.sleep() dengan penundaan 100 milidetik. Dalam hal ini, acara parkir ulir akan dibuat untuk Anda, yang kemudian akan terdaftar di pemilih. Masalah penting lainnya adalah ketika sheduler menunjuk coroutine berikutnya yang tersedia. Ada dua syarat utama. Yang pertama adalah ketika peristiwa tertentu dihasilkan, seperti acara I / O atau peristiwa batas waktu. Semuanya sangat sederhana di sini: misalkan Anda melakukan panggilan ke thread.sleep() dengan penundaan 200 milidetik. Ketika mereka kedaluwarsa, sheduler memiliki kesempatan untuk mengeksekusi coroutine berikutnya yang tersedia. Atau di sini kita dapat berbicara tentang beberapa peristiwa membongkar yang dihasilkan, katakanlah, dengan memanggil object.notify() atau object.notifyAll() Kondisi kedua adalah ketika pengguna mengirimkan permintaan baru, dan kami membuat coroutine untuk melayani permintaan ini, dan kemudian sheduler menugaskan implementasinya.
Di sini Anda juga perlu mengatakan tentang layanan yang kami buat, WispThreadExecutor.

Contoh kode disajikan di layar, dan kami melihat bahwa ini adalah ExecutorService biasa, dibuat dengan cara yang sama. Metode .execute() dan submit() tersedia untuk tugas Runnable, tetapi masalahnya adalah bahwa semua tugas Runnable yang melewati metode submit() akan dieksekusi di corutin, dan bukan di utas. Solusi ini sangat transparan bagi mereka yang akan menerapkan aplikasi kami, mereka akan dapat menggunakan API kami untuk coroutine.

Saya sampai pada bagian paling sulit dari postingan ini - bagaimana menyelesaikan masalah sinkronisasi di coroutine. Ini adalah pertanyaan yang kompleks, jadi mari kita lihat dengan contoh sederhana. Di sini kita memiliki coroutine A ( test::foo ) dan corutin test::bar ). Pertama, kami menetapkan pelaksanaan test:foo to coroutine wait() . Jika tidak ada yang dilakukan, maka utas saat ini akan diblokir oleh panggilan untuk wait() . Seperti yang dapat dilihat dari dump thread ini, kebuntuan akan terjadi, dan kita tidak akan dapat menjadwalkan coroutine berikutnya untuk dieksekusi.
Bagaimana cara mengatasi masalah ini? Hotspot menyediakan tiga jenis kunci. Yang pertama adalah kunci cepat. Di sini, pemilik kunci ditentukan oleh alamat pada tumpukan. Seperti yang saya katakan, masing-masing coroutine kami memiliki tumpukan yang terpisah. Karena itu, dalam hal penguncian cepat, kita tidak perlu melakukan pekerjaan tambahan. Tidak ada dukungan serupa untuk kunci bias di sistem kami. Kami mencobanya pada produksi kami dan ternyata dengan tidak adanya kunci bias, kinerja tidak menurun. Bagi kami itu sangat cocok.
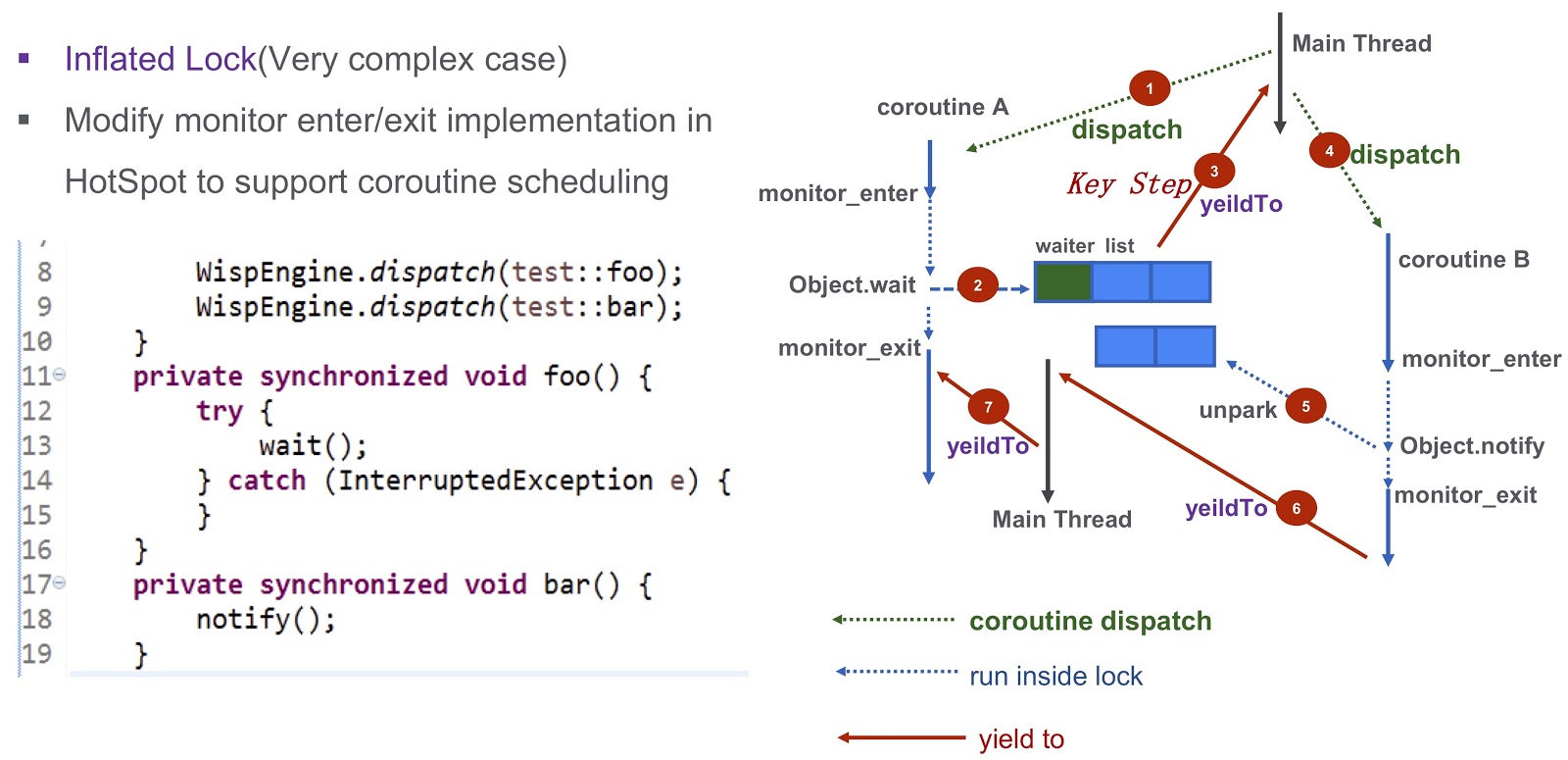
Mari kita bicara tentang kasus yang lebih rumit - kunci meningkat. Mari kita lihat kembali contoh yang saya kutip di atas. Kami memiliki Corutin .foo() ) dan Corutin B ( .bar() ). Pertama, kami menetapkan eksekusi coroutine Object.wait , setelah itu masuk ke daftar tunggu. Setelah itu, kami mengambil langkah yang sangat penting: kami menghasilkan acara yieldTo , yang mentransfer kontrol ke utas utama. Selanjutnya, kita mulai Corutin B Itu panggilan Object.notify , dan acara unpark sesuai unpark . Mereka akhirnya akan membangunkan coroutine bar() , akan ada kemungkinan untuk mentransfer kontrol ke coroutine
Mari kita bahas kinerja sekarang. Kami menggunakan coroutine di salah satu aplikasi online Carts kami. Berdasarkan itu, kita dapat membandingkan pekerjaan corutin dengan pekerjaan JDK biasa.
Seperti yang Anda lihat, mereka memungkinkan kami untuk mengurangi konsumsi waktu prosesor hampir 10%. Saya mengerti bahwa sebagian besar dari Anda kemungkinan besar tidak memiliki kemampuan untuk secara langsung membuat perubahan kompleks pada kode JDK. Tetapi kesimpulan utama di sini, menurut pendapat saya, adalah jika kerugian kinerja membutuhkan biaya dan jumlah yang dihasilkan cukup besar, Anda dapat mencoba meningkatkan kinerja menggunakan perpustakaan coroutine.
Jarmarm
Mari kita beralih ke alat kami yang lain - JWarmup. Ini sangat mirip dengan alat lain, ReadyNow. Seperti yang kita ketahui, di Jawa ada masalah pemanasan - kompiler pada tahap ini membutuhkan siklus CPU tambahan. Ini menyebabkan masalah pada kami - misalnya, TimeOut Error terjadi. Ketika penskalaan, masalah ini hanya memburuk, dan dalam kasus kami, kami berbicara tentang aplikasi yang sangat kompleks - lebih dari 20 ribu kelas dan lebih dari 50 ribu metode.
Sebelum kami mulai menggunakan JWarmup, pemilik aplikasi kami menggunakan data simulasi untuk pemanasan. Pada data ini, kompiler JIT telah dikompilasi sebelum permintaan diterima. Tetapi data simulasi berbeda dari yang asli, oleh karena itu, tidak mewakili untuk kompiler. Dalam beberapa kasus, deoptimisasi yang tidak terduga terjadi, kinerja menderita. Solusi untuk masalah ini adalah JWarmup. Dia memiliki dua tahap utama pekerjaan - perekaman dan kompilasi. Alibaba memiliki dua jenis lingkungan, beta dan produksi. Keduanya menerima permintaan nyata dari pengguna, setelah itu versi aplikasi yang sama digunakan di kedua lingkungan ini. Dalam lingkungan beta, hanya data profil yang dikumpulkan, yang kemudian dilakukan kompilasi awal dalam produksi.

Mari kita lihat lebih detail informasi apa yang kami kumpulkan. Kita perlu menuliskan kelas mana yang diinisialisasi, metode mana yang dikompilasi, kemudian data ini dimasukkan ke log pada hard drive, yang dapat diakses oleh kompiler. Momen paling sulit adalah inisialisasi kelas. . — Bar Foo.test() , foo.count . , .
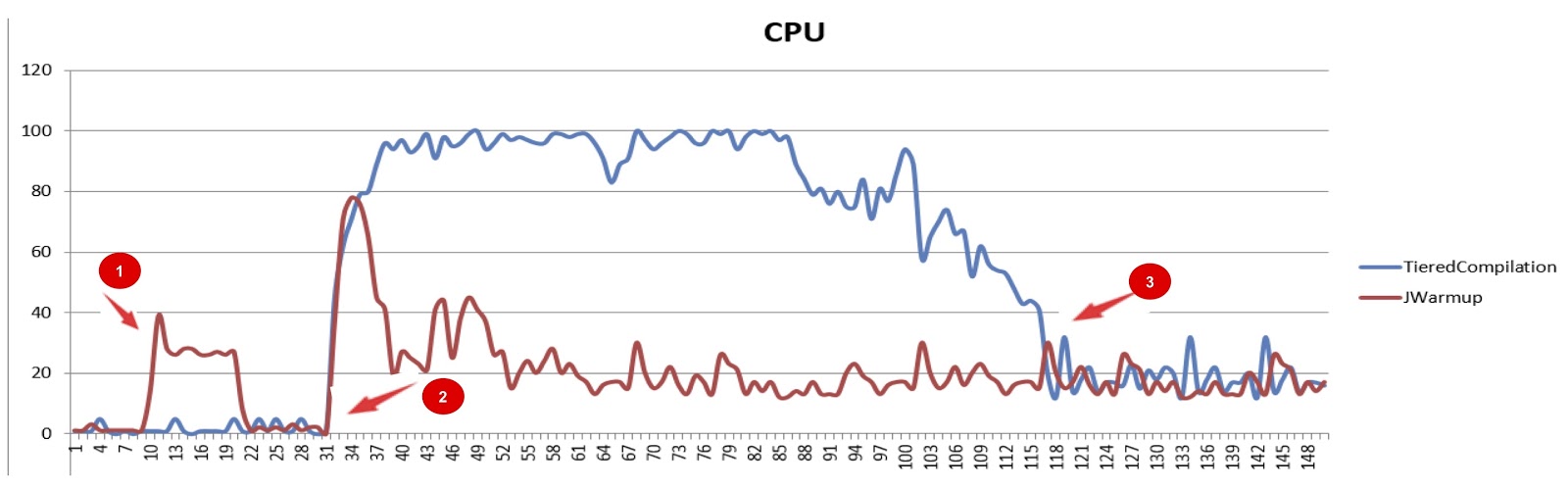
JWarmup (tiered compilation), . , — CPU. JWarmup , CPU, JDK. , , JDK. , , .
JWarmup. , , , groovy-, Java-, . . , , «null check elimination». . , JWarmup , JWarmup, .
, Alibaba.
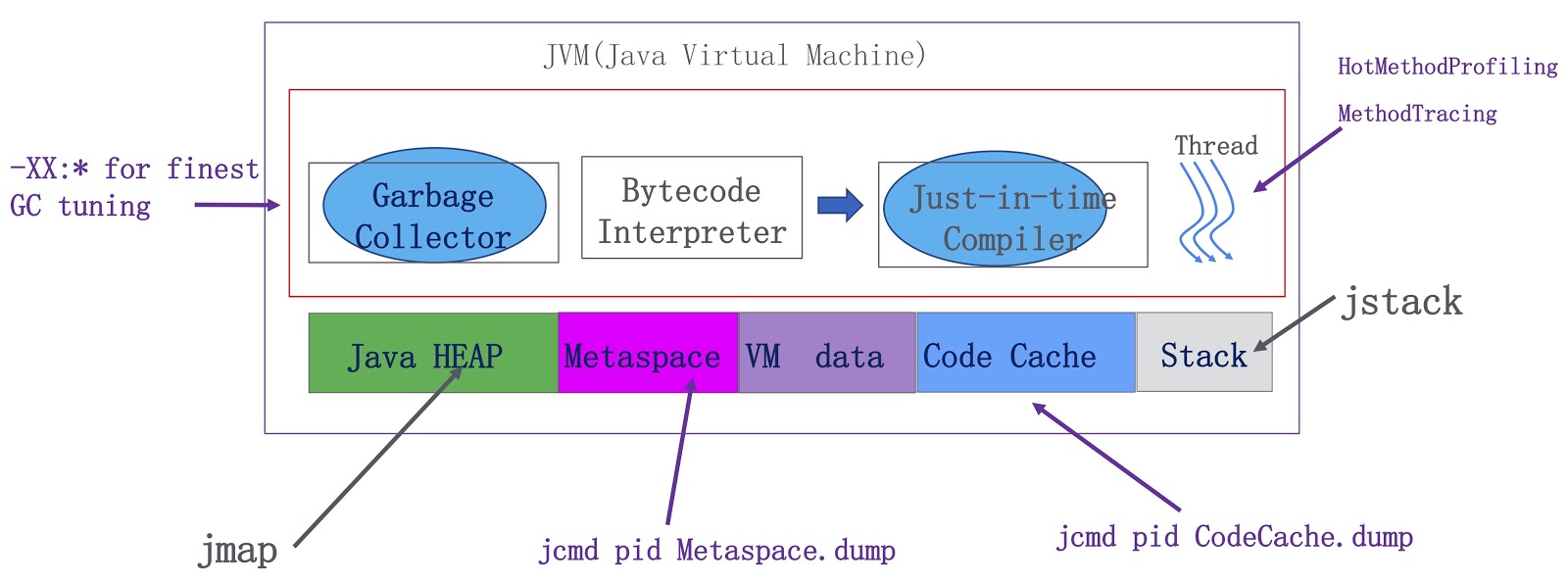
. JVM — , , . Java-, metaspace, VM ( VM) JIT-. OpenJDK. -, , . -, . HotMethodProfiling, , CPU. , , Honest Profiler , , , HotMethodProfiling. MethodTracing. , , . , metaspace . Java-, . metaspace , . Java.
, , ZProfiler.
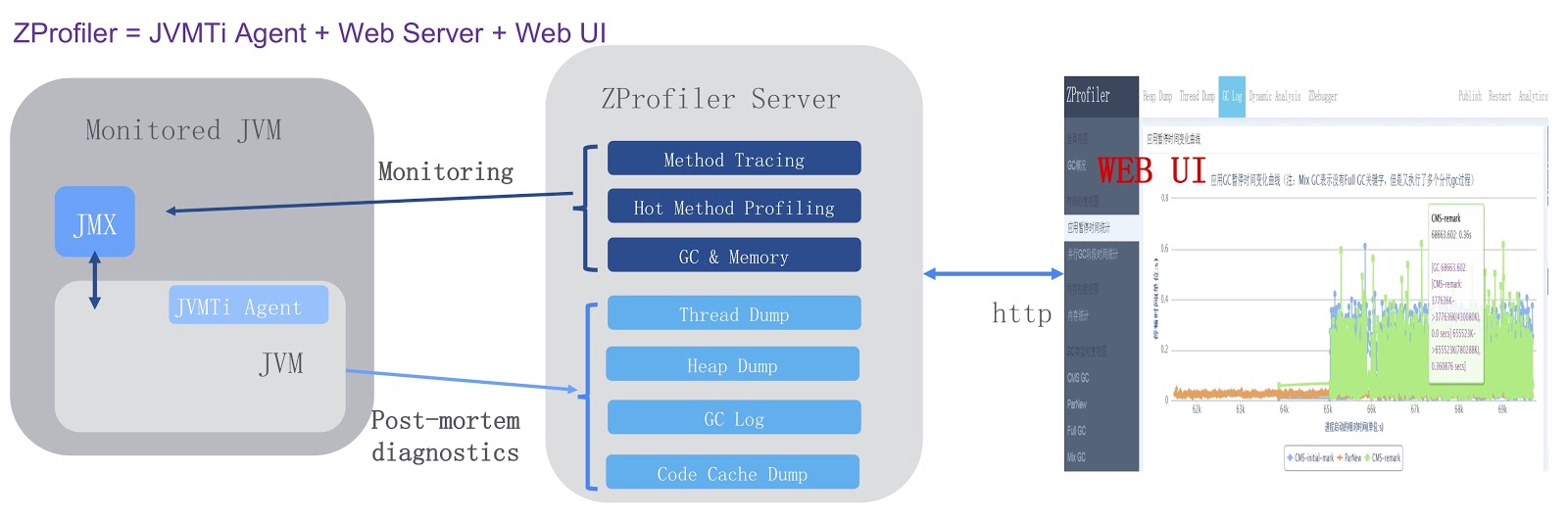
. JVMTi, JVM ( ). , ZProfiler Apache Tomcat. -. ZProfiler JVM. , ZProfiler -UI, . ZProfiler . -, UI JVM. -, ZProfiler post-mortem . , OutOfMemoryError, , JVM ZProfiler, . , , , Eclipse MAT.
. . JVM, GCIH, Alibaba JDK, JWarmup — , ReadyNow Zing JVM. , ZProfiler. , , OpenJDK. , , JWarmup OpenJDK. , OpenJDK Loom, Java. , .
. , , JPoint 2018 . 2019 , JPoint , 5-6 . , Rafael Winterhalter Sebastian Daschner. . , YouTube . JPoint!