
The Guardian adalah salah satu surat kabar Inggris terbesar, didirikan pada tahun 1821. Selama hampir 200 tahun keberadaannya, arsip telah mengakumulasi jumlah yang wajar. Untungnya, tidak semuanya disimpan di situs - hanya dalam beberapa dekade terakhir. Basis data, yang oleh orang Inggris sendiri disebut sebagai "sumber kebenaran" untuk semua konten online, mengandung sekitar 2,3 juta elemen. Dan pada satu titik, mereka menyadari kebutuhan untuk bermigrasi dari Mongo ke Postgres SQL - setelah satu hari yang panas di bulan Juli 2015, prosedur failover diuji dengan berat. Migrasi memakan waktu hampir 3 tahun! ..
Kami telah menerjemahkan
sebuah artikel yang menjelaskan bagaimana proses migrasi berjalan dan kesulitan apa yang dihadapi administrator. Prosesnya panjang, tetapi ringkasannya sederhana: sampai ke tugas besar, rujuk bahwa kesalahan akan diperlukan. Namun pada akhirnya, 3 tahun kemudian, rekan-rekan Inggris berhasil merayakan berakhirnya migrasi. Dan tidur.
Bagian Satu: Awal
Di Guardian, sebagian besar konten, termasuk artikel, blog, galeri foto, dan video, diproduksi dalam CMS, Komposer kami sendiri. Sampai saat ini, Composer bekerja dengan Mongo DB AWS. Basis data ini pada dasarnya adalah "sumber kebenaran" untuk semua konten online Guardian - sekitar 2,3 juta elemen. Dan kami baru saja menyelesaikan migrasi dari Mongo ke Postgres SQL.
Komposer dan basis datanya semula di-host di Guardian Cloud, pusat data di ruang bawah tanah kantor kami dekat Kings Cross, dengan failover di tempat lain di London. Suatu
hari di bulan Juli yang panas pada tahun 2015, prosedur kegagalan kami mengalami ujian yang agak berat.
 Panas: bagus untuk menari di air mancur, bencana bagi pusat data. Foto: Sarah Lee / Wali
Panas: bagus untuk menari di air mancur, bencana bagi pusat data. Foto: Sarah Lee / WaliSejak itu, migrasi Guardian ke AWS menjadi masalah hidup dan mati. Untuk bermigrasi ke cloud, kami memutuskan untuk membeli
OpsManager , perangkat lunak manajemen Mongo DB, dan menandatangani kontrak dukungan teknis Mongo. Kami menggunakan OpsManager untuk mengelola cadangan, mengatur dan memantau kelompok basis data kami.
Karena persyaratan editorial, kami perlu memulai cluster database dan OpsManager pada infrastruktur kami sendiri di AWS, dan tidak menggunakan solusi yang dikelola Mongo. Kami harus berkeringat, karena Mongo tidak menyediakan alat apa pun untuk konfigurasi yang mudah pada AWS: kami secara manual merancang seluruh infrastruktur dan menulis
ratusan skrip Ruby untuk menginstal agen pemantauan / otomatisasi dan mengatur instance database baru. Akibatnya, kami harus mengatur tim program pendidikan tentang manajemen basis data dalam tim - apa yang kami harapkan akan dilakukan oleh OpsManager.
Sejak transisi ke AWS, kami mengalami dua kerusakan signifikan karena masalah basis data, yang masing-masing tidak memungkinkan publikasi di theguardian.com selama setidaknya satu jam. Dalam kedua kasus tersebut, OpsManager maupun staf dukungan teknis Mongo tidak dapat memberikan bantuan yang memadai kepada kami, dan kami menyelesaikan sendiri masalahnya - dalam satu kasus, terima kasih kepada anggota
tim kami yang berhasil menangani situasi tersebut melalui telepon dari gurun di pinggiran Abu Dhabi.
Masing-masing masalah bermasalah layak mendapat pos terpisah, tetapi berikut adalah poin-poin umumnya:
- Perhatikan waktu - jangan menghalangi akses ke VPC Anda sedemikian rupa sehingga NTP berhenti berfungsi.
- Membuat indeks basis data secara otomatis saat startup aplikasi adalah ide yang buruk.
- Manajemen basis data sangat penting dan sulit - dan kami tidak ingin melakukannya sendiri.
OpsManager tidak menepati janjinya tentang manajemen basis data yang sederhana. Sebagai contoh, manajemen aktual OpsManager itu sendiri - khususnya, peningkatan dari OpsManager versi 1 ke versi 2 - membutuhkan banyak waktu dan pengetahuan khusus tentang pengaturan OpsManager kami. Dia juga gagal memenuhi janjinya tentang "pembaruan satu klik" karena perubahan dalam skema otentikasi antara berbagai versi Mongo DB. Kami kehilangan setidaknya dua bulan insinyur per tahun mengelola database.
Semua masalah ini, dikombinasikan dengan biaya tahunan yang signifikan yang kami bayarkan untuk kontrak dukungan dan OpsManager, memaksa kami untuk mencari opsi basis data alternatif dengan karakteristik berikut:
- Upaya minimal untuk mengelola database.
- Enkripsi saat istirahat.
- Jalur migrasi yang dapat diterima dengan Mongo.
Karena semua layanan kami yang lain menjalankan AWS, pilihan yang jelas adalah Dynamo, basis data NoSQL Amazon. Sayangnya, pada saat itu, Dynamo tidak mendukung enkripsi saat istirahat. Setelah menunggu sekitar sembilan bulan untuk fitur ini ditambahkan, kami akhirnya meninggalkan ide ini dengan memutuskan untuk menggunakan Postgres pada AWS RDS.
"Tapi Postgres bukan repositori dokumen!" - Anda marah ... Ya, ini bukan repositori dok, tetapi memiliki tabel yang mirip dengan kolom JSONB, dengan dukungan untuk indeks di bidang alat JSON Blob. Kami berharap bahwa menggunakan JSONB kami akan dapat bermigrasi dari Mongo ke Postgres dengan sedikit perubahan pada model data kami. Selain itu, jika kita ingin pindah ke model yang lebih relasional di masa depan, kita akan memiliki kesempatan seperti itu. Hal hebat lainnya tentang Postgres adalah seberapa baik kerjanya: untuk setiap pertanyaan yang kami miliki, dalam kebanyakan kasus jawabannya sudah diberikan di Stack Overflow.
Dalam hal kinerja, kami yakin bahwa Postgres dapat melakukannya: Komposer adalah alat khusus untuk merekam konten (ia menulis ke basis data setiap kali seorang jurnalis berhenti mencetak), dan biasanya jumlah pengguna secara bersamaan tidak melebihi beberapa ratus - yang tidak memerlukan sistem kekuatan super tinggi!
Bagian dua: migrasi konten selama dua dekade berjalan tanpa downtime
RencanakanSebagian besar migrasi basis data menyiratkan tindakan yang sama, dan kami tidak terkecuali. Inilah yang kami lakukan:
- Membuat database baru.
- Mereka menciptakan cara untuk menulis ke database baru (API baru).
- Kami membuat server proxy yang mengirimkan lalu lintas ke database lama dan baru, menggunakan yang lama sebagai yang utama.
- Memindahkan catatan dari database lama ke yang baru.
- Mereka menjadikan database baru sebagai yang utama.
- Menghapus basis data lama.
Mengingat bahwa basis data tempat kami bermigrasi menyediakan fungsi CMS kami, sangat penting bahwa migrasi menyebabkan masalah sesedikit mungkin bagi jurnalis kami. Pada akhirnya, berita itu tidak pernah berakhir.
API baruPekerjaan pada API berbasis Postgres baru dimulai pada akhir Juli 2017. Ini adalah awal dari perjalanan kami. Tetapi untuk memahami bagaimana itu, pertama-tama kita harus mengklarifikasi dari mana kita mulai.
Arsitektur CMS kami yang disederhanakan adalah sesuatu seperti ini: database, API, dan beberapa aplikasi yang terkait dengannya (seperti antarmuka pengguna). Tumpukan dibangun dan selama 4 tahun sekarang beroperasi berdasarkan
Scala ,
Scalatra Framework dan
Angular.js .
Setelah beberapa analisis, kami sampai pada kesimpulan bahwa sebelum kami dapat memigrasikan konten yang ada, kami membutuhkan cara untuk menghubungi basis data PostgreSQL yang baru, menjaga operasional API yang lama. Lagipula, Mongo DB adalah "sumber kebenaran" kita. Dia melayani kami sebagai penyelamat saat kami bereksperimen dengan API baru.
Ini adalah salah satu alasan mengapa membangun di atas API lama bukan bagian dari rencana kami. Pemisahan fungsi dalam API asli minimal, dan metode spesifik yang diperlukan untuk bekerja secara spesifik dengan Mongo DB dapat ditemukan bahkan pada tingkat pengontrol. Akibatnya, tugas menambahkan jenis database lain ke API yang ada terlalu berisiko.
Kami pergi ke arah lain dan menduplikasi API lama. Maka lahirlah APIV2. Itu adalah salinan yang kurang lebih persis dari API lama yang berhubungan dengan Mongo, dan termasuk titik akhir dan fungsi yang sama. Kami menggunakan
doobie , lapisan fitur JDBC murni untuk Scala, menambahkan
Docker untuk menjalankan dan menguji secara lokal, dan meningkatkan pencatatan operasi dan pembagian tanggung jawab. APIV2 seharusnya menjadi versi cepat dan modern dari API.
Pada akhir Agustus 2017, kami memiliki API baru yang digunakan yang menggunakan PostgreSQL sebagai databasenya. Tapi itu baru permulaan. Ada artikel di Mongo DB yang pertama kali dibuat lebih dari dua dekade lalu, dan mereka semua harus bermigrasi ke database Postgres.
MigrasiKami harus dapat mengedit artikel apa pun di situs, terlepas dari kapan artikel itu diterbitkan, oleh karena itu semua artikel ada di basis data kami sebagai satu "sumber kebenaran".
Meskipun semua artikel hidup dalam
API Konten Guardian (CAPI) , yang melayani aplikasi dan situs, sangat penting bagi kami untuk bermigrasi tanpa gangguan, karena basis data kami adalah "sumber kebenaran" kami. Jika sesuatu terjadi pada cluster CAPI Elasticsearch, kami akan mengindeksnya kembali dari database Komposer.
Karena itu, sebelum menonaktifkan Mongo, kami harus memastikan bahwa permintaan yang sama untuk API yang berjalan di Postgres dan API yang berjalan di Mongo akan mengembalikan jawaban yang sama.
Untuk melakukan ini, kami perlu menyalin semua konten ke dalam database Postgres baru. Ini dilakukan menggunakan skrip yang berinteraksi langsung dengan API lama dan baru. Keuntungan dari metode ini adalah bahwa kedua API sudah menyediakan antarmuka yang telah teruji untuk membaca dan menulis artikel masuk dan keluar dari database, sebagai lawan dari menulis sesuatu yang secara langsung mengakses database masing-masing.
Urutan migrasi dasar adalah sebagai berikut:
- Dapatkan konten dari Mongo.
- Posting konten ke Postgres.
- Dapatkan konten dari Postgres.
- Pastikan jawaban mereka identik.
Migrasi basis data dapat dianggap berhasil hanya jika pengguna akhir tidak memperhatikan bahwa ini telah terjadi, dan skrip migrasi yang baik akan selalu menjadi kunci keberhasilan tersebut. Kami membutuhkan skrip yang dapat:
- Jalankan permintaan HTTP.
- Pastikan bahwa setelah memigrasi sebagian konten, respons kedua API adalah sama.
- Berhenti ketika terjadi kesalahan.
- Buat log operasi terperinci untuk mendiagnosis masalah.
- Mulai ulang setelah kesalahan dari titik yang benar.
Kami mulai dengan menggunakan
Ammon . Ini memungkinkan Anda untuk menulis skrip dalam bahasa Scala, yang merupakan inti dari tim kami. Itu adalah kesempatan yang baik untuk bereksperimen dengan sesuatu yang belum pernah kami gunakan sebelumnya untuk melihat apakah itu akan berguna bagi kami. Meskipun Amon mengizinkan kami untuk menggunakan bahasa yang akrab, kami menemukan beberapa kekurangan dalam mengerjakannya. Intellij saat ini
mendukung Ammonite, tetapi tidak melakukannya selama migrasi kami, dan kami kehilangan penyelesaian otomatis dan impor otomatis. Selain itu, untuk jangka waktu yang lama, skrip Amon gagal dijalankan.
Pada akhirnya, Ammon bukan alat yang tepat untuk pekerjaan ini, dan sebagai gantinya kami menggunakan proyek sbt untuk melakukan migrasi. Ini memungkinkan kami untuk bekerja dalam bahasa yang kami yakini, serta melakukan beberapa 'tes migrasi' sebelum diluncurkan di lingkungan kerja utama.
Tidak terduga adalah betapa bergunanya memeriksa versi API yang berjalan di Postgres. Kami menemukan beberapa kesalahan yang sulit ditemukan dan membatasi kasus yang tidak kami temukan sebelumnya.
Maju cepat ke Januari 2018 ketika tiba waktunya untuk menguji migrasi penuh di lingkungan KODE pra-prod kami.
Seperti kebanyakan sistem kami, satu-satunya kesamaan antara CODE dan PROD adalah versi aplikasi yang diluncurkan. Infrastruktur AWS yang mendukung CODE jauh lebih lemah daripada PROD, hanya karena mendapat beban kerja yang jauh lebih sedikit.
Kami berharap bahwa uji migrasi di lingkungan CODE akan membantu kami:
- Perkirakan berapa lama migrasi akan berlangsung di lingkungan PROD.
- Menilai bagaimana (jika sama sekali) migrasi mempengaruhi produktivitas.
Untuk mendapatkan pengukuran yang akurat dari indikator-indikator ini, kami harus membawa kedua lingkungan ke dalam korespondensi yang saling melengkapi. Ini termasuk memulihkan cadangan Mongo DB dari PROD ke CODE dan memutakhirkan infrastruktur yang didukung oleh AWS.
Migrasi lebih dari 2 juta item data seharusnya memakan waktu lebih lama daripada yang diizinkan oleh hari kerja standar. Karena itu, kami menjalankan skrip di
layar untuk malam itu.
Untuk mengukur kemajuan migrasi, kami mengirim kueri terstruktur (menggunakan token) ke tumpukan ELK kami (Elasticsearch, Logstash, dan Kibana). Dari sana, kami dapat membuat dasbor terperinci dengan melacak jumlah artikel yang berhasil ditransfer, jumlah macet, dan keseluruhan kemajuan. Selain itu, semua indikator ditampilkan di layar lebar sehingga seluruh tim dapat melihat detailnya.
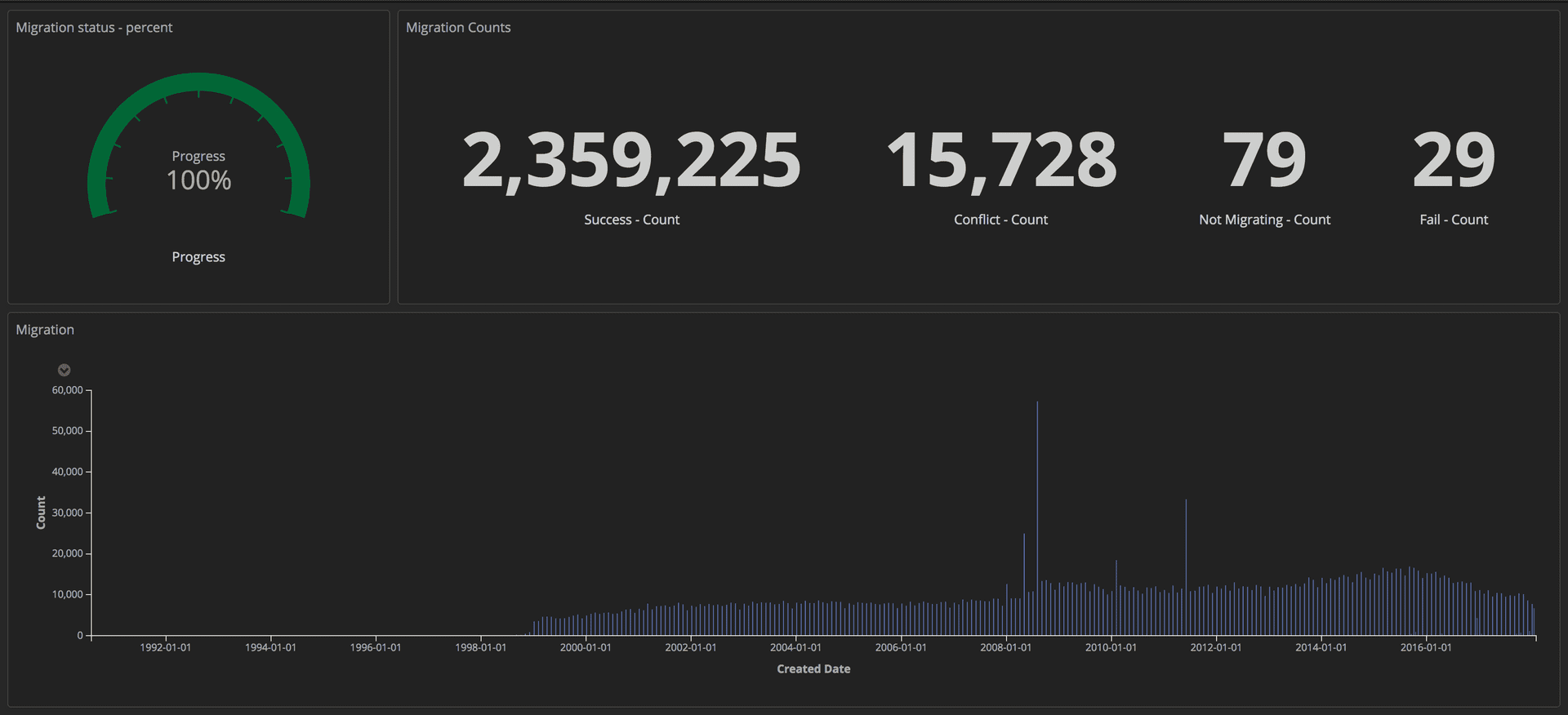 Dasbor menunjukkan kemajuan migrasi: Alat Editorial / Wali
Dasbor menunjukkan kemajuan migrasi: Alat Editorial / WaliSetelah migrasi selesai, kami memeriksa kecocokan untuk setiap dokumen di Postgres dan di Mongo.
Bagian Tiga: Proxy dan Peluncuran di Prod
ProksiSekarang setelah API baru yang berjalan di Postgres diluncurkan, kami perlu mengujinya dengan lalu lintas nyata dan pola akses data untuk memastikan keandalan dan stabilitasnya. Ada dua cara yang mungkin untuk melakukan ini: perbarui setiap klien yang mengakses API Mongo sehingga mengakses kedua API; atau jalankan proxy yang akan melakukannya untuk kita. Kami menulis proksi di Scala menggunakan
Akka Streams .
Proxynya cukup sederhana:
- Terima lalu lintas dari penyeimbang beban.
- Alihkan lalu lintas ke API utama dan sebaliknya.
- Teruskan lalu lintas yang sama secara tidak sinkron ke API tambahan.
- Hitung perbedaan antara dua jawaban dan catat dalam log.
Pada awalnya, proksi mencatat banyak perbedaan, termasuk beberapa perbedaan perilaku yang sulit ditemukan tetapi penting dalam dua API yang perlu diperbaiki.
Logging TerstrukturDi Guardian, kami mencatat menggunakan tumpukan
ELK (Elasticsearch, Logstash, dan Kibana). Menggunakan Kibana memberi kami kesempatan untuk memvisualisasikan majalah dengan cara yang paling nyaman bagi kami. Kibana menggunakan
sintaks query Lucene , yang cukup mudah dipelajari. Tetapi kami segera menyadari bahwa mustahil untuk memfilter atau mengelompokkan entri jurnal dalam pengaturan saat ini. Misalnya, kami tidak dapat memfilter yang dikirim karena permintaan GET.
Kami memutuskan untuk mengirim lebih banyak data terstruktur ke Kibana, bukan hanya pesan. Satu entri log berisi beberapa bidang, misalnya cap waktu dan nama tumpukan atau aplikasi yang mengirim permintaan. Menambahkan bidang baru sangat mudah. Bidang terstruktur ini disebut penanda dan dapat diimplementasikan menggunakan
perpustakaan logstash-logback-encoder . Untuk setiap permintaan, kami mengekstraksi informasi berguna (misalnya, rute, metode, kode status) dan membuat peta dengan informasi tambahan yang diperlukan untuk log. Berikut ini sebuah contoh:
import akka.http.scaladsl.model.HttpRequest import ch.qos.logback.classic.{Logger => LogbackLogger} import net.logstash.logback.marker.Markers import org.slf4j.{LoggerFactory, Logger => SLFLogger} import scala.collection.JavaConverters._ object Logging { val rootLogger: LogbackLogger = LoggerFactory.getLogger(SLFLogger.ROOT_LOGGER_NAME).asInstanceOf[LogbackLogger] private def setMarkers(request: HttpRequest) = { val markers = Map( "path" -> request.uri.path.toString(), "method" -> request.method.value ) Markers.appendEntries(markers.asJava) } def infoWithMarkers(message: String, akkaRequest: HttpRequest) = rootLogger.info(setMarkers(akkaRequest), message) }
Bidang tambahan dalam log kami memungkinkan kami membuat dasbor informatif dan menambahkan lebih banyak konteks ke perbedaan, yang membantu kami mengidentifikasi beberapa ketidakkonsistenan kecil antara kedua API.
Replikasi lalu lintas dan refactoring proxySetelah mentransfer konten ke basis data CODE, kami mendapat salinan yang hampir persis dari basis data PROD. Perbedaan utama adalah bahwa KODE tidak memiliki lalu lintas. Untuk mereplikasi traffic nyata ke lingkungan CODE, kami menggunakan alat open source
GoReplay (selanjutnya
disebut sebagai gor). Sangat mudah untuk menginstal dan fleksibel untuk menyesuaikan dengan kebutuhan Anda.
Karena semua lalu lintas yang datang ke API kami pertama kali pergi ke proksi, masuk akal untuk menginstal gor pada wadah proxy. Lihat di bawah ini cara memuat gor ke dalam wadah Anda dan bagaimana mulai memantau lalu lintas di port 80 dan mengirimkannya ke server lain.
wget https://github.com/buger/goreplay/releases/download/v0.16.0.2/gor_0.16.0_x64.tar.gz tar -xzf gor_0.16.0_x64.tar.gz gor sudo gor --input-raw :80 --output-http http://apiv2.code.co.uk
Untuk sementara semuanya bekerja dengan baik, tetapi segera ada kerusakan ketika proxy menjadi tidak tersedia selama beberapa menit. Dalam analisis, kami menemukan bahwa ketiga wadah proxy secara berkala digantung pada waktu yang sama. Pada awalnya kami pikir proksi mogok karena gor menggunakan terlalu banyak sumber daya. Setelah menganalisis konsol AWS lebih lanjut, kami menemukan bahwa wadah proxy tergantung secara teratur, tetapi tidak pada saat yang bersamaan.
Sebelum menggali lebih dalam masalah lebih lanjut, kami mencoba menemukan cara untuk menjalankan gor, tetapi kali ini tanpa beban tambahan pada proxy. Solusinya datang dari tumpukan sekunder kami untuk Komposer. Tumpukan ini hanya digunakan dalam keadaan darurat, dan
alat pemantauan kami yang
bekerja terus mengujinya. Kali ini, pemutaran lalu lintas dari tumpukan ini ke CODE dengan kecepatan ganda berfungsi tanpa masalah.
Temuan baru telah menimbulkan banyak pertanyaan. Proxy dibangun sebagai alat sementara, sehingga mungkin tidak dirancang dengan hati-hati seperti aplikasi lain. Selain itu, itu dibangun menggunakan
Akka Http , yang tidak diketahui oleh tim kami. Kode itu berantakan dan penuh dengan perbaikan cepat. Kami memutuskan untuk memulai banyak refactoring untuk meningkatkan keterbacaan. Kali ini kami menggunakan generator bukan logika bertingkat yang kami gunakan sebelumnya. Dan menambahkan lebih banyak penanda logging.
Kami berharap bahwa kami dapat mencegah pembekuan proxy dari pembekuan jika kami merinci apa yang sedang terjadi di dalam sistem dan menyederhanakan logika operasinya. Tetapi itu tidak berhasil. Setelah dua minggu mencoba membuat proxy lebih dapat diandalkan, kami merasa terjebak. Itu perlu untuk membuat keputusan. Kami memutuskan untuk mengambil risiko dan membiarkan proxy seperti itu, karena lebih baik menghabiskan waktu pada migrasi itu sendiri daripada mencoba memperbaiki perangkat lunak yang akan menjadi tidak perlu dalam sebulan. Kami membayar solusi ini dengan dua kegagalan lagi - masing-masing hampir dua menit - tetapi itu harus dilakukan.
Maju cepat hingga Maret 2018, ketika kami telah menyelesaikan migrasi ke CODE tanpa mengorbankan kinerja API atau pengalaman klien dalam CMS. Sekarang kita bisa mulai berpikir tentang menghapus proksi dari CODE.
Langkah pertama adalah mengubah prioritas API sehingga proxy pertama berinteraksi dengan Postgres. Seperti yang kami katakan di atas, ini diputuskan oleh perubahan dalam pengaturan. Namun, ada satu kesulitan.
Komposer mengirim pesan ke aliran Kinesis setelah memperbarui dokumen. Hanya satu API yang diperlukan untuk mengirim pesan untuk mencegah duplikasi. Untuk ini, API memiliki flag dalam konfigurasi: true untuk API yang didukung oleh Mongo, dan false untuk Postgres yang didukung. Cukup mengubah proxy untuk berinteraksi dengan Postgres pertama tidak cukup, karena pesan tidak akan dikirim ke aliran Kinesis sampai permintaan mencapai Mongo. Sudah terlalu lama.
Untuk mengatasi masalah ini, kami membuat titik akhir HTTP untuk secara instan mengubah konfigurasi semua contoh penyeimbang beban dengan cepat. Ini memungkinkan kami untuk menghubungkan API utama dengan sangat cepat tanpa perlu mengedit file konfigurasi dan memindahkan kembali. Selain itu, ini bisa otomatis, sehingga mengurangi interaksi manusia dan kemungkinan kesalahan.
Sekarang semua permintaan dikirim ke Postgres terlebih dahulu, dan API2 berinteraksi dengan Kinesis. Penggantian bisa dibuat permanen dengan perubahan konfigurasi dan pemindahan.
Langkah selanjutnya adalah menghapus sepenuhnya proxy dan memaksa klien untuk mengakses API Postgres secara eksklusif. Karena kami memiliki banyak klien, memperbarui setiap klien secara individual tidak dimungkinkan. Oleh karena itu, kami mengangkat tugas ini ke tingkat DNS. Yaitu, kami membuat CNAME dalam DNS yang pertama kali menunjuk ke proxy ELB dan akan berubah untuk menunjuk ke API ELB. Ini memungkinkan satu perubahan dilakukan alih-alih memperbarui setiap klien API individual.
Sudah waktunya untuk memindahkan PROD. Meski agak menakutkan, yah, karena ini adalah lingkungan kerja utama. Prosesnya relatif sederhana, karena semuanya diputuskan dengan mengubah pengaturan. Selain itu, ketika penanda panggung ditambahkan ke log, menjadi mungkin untuk membuat ulang profil dasbor yang dibuat sebelumnya hanya dengan memperbarui filter Kibana.
Menonaktifkan proxy dan Mongo DBSetelah 10 bulan dan 2,4 juta artikel yang dimigrasi, kami akhirnya dapat menonaktifkan semua infrastruktur yang terkait dengan Mongo. Tapi pertama-tama, kita harus melakukan apa yang kita semua tunggu: bunuh proxy.
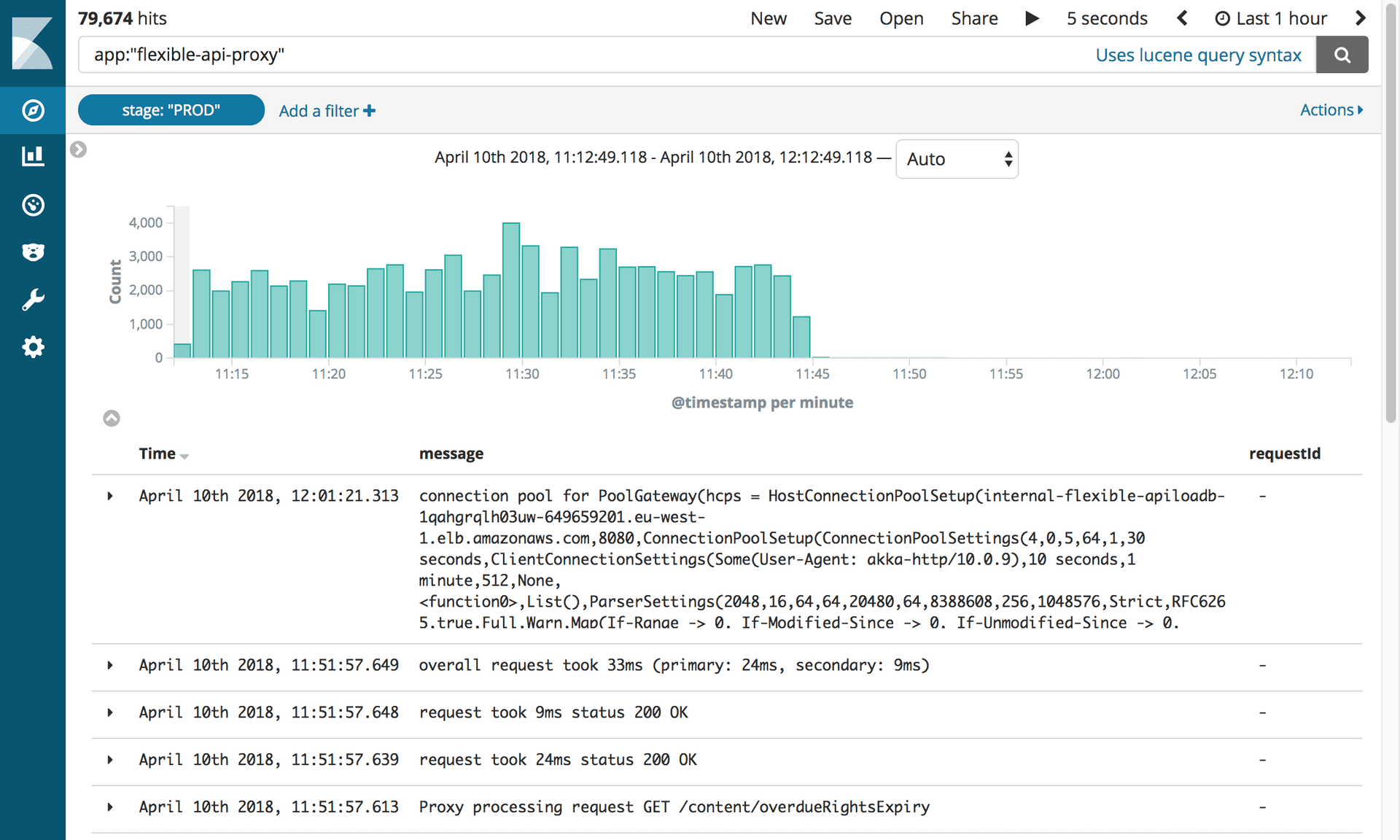 Log yang menunjukkan penonaktifan Proxy API Fleksibel. Foto: Alat Editorial / Wali
Log yang menunjukkan penonaktifan Proxy API Fleksibel. Foto: Alat Editorial / WaliSepotong kecil perangkat lunak ini menyebabkan banyak masalah sehingga kami ingin segera memutusnya! Yang harus kami lakukan adalah memperbarui catatan CNAME untuk menunjuk langsung ke penyeimbang beban APIV2.
Seluruh tim berkumpul di sekitar satu komputer. Itu perlu untuk membuat hanya satu keystroke. Semua orang menahan napas! Diam sepenuhnya ... Klik! Pekerjaan sudah selesai. Dan tidak ada yang terbang! Kami semua menghembuskannya dengan gembira.
Namun, menghapus Mongo DB API sudah penuh dengan tes lain. Putus asa untuk menghapus kode lama, kami menemukan bahwa tes integrasi kami tidak pernah disesuaikan untuk menggunakan API baru. Semuanya dengan cepat berubah merah. Untungnya, sebagian besar masalah terkait dengan konfigurasi dan kami dengan mudah memperbaikinya. Ada beberapa masalah dengan pertanyaan PostgreSQL yang ditangkap oleh tes. Berpikir tentang apa yang bisa dilakukan untuk menghindari kesalahan ini, kami belajar satu pelajaran: ketika memulai tugas besar, rujuk bahwa akan ada kesalahan.
Setelah itu, semuanya berjalan lancar. Kami memutus semua contoh Mongo dari OpsManager, dan kemudian memutusnya. Satu-satunya yang tersisa untuk dilakukan adalah merayakan. Dan tidur.