Saya seorang Lead DevOps Engineer di Miro (ex-RealtimeBoard). Saya akan membagikan bagaimana tim DevOps kami memecahkan masalah rilis server harian dari aplikasi stateful monolitik dan membuatnya otomatis, tidak terlihat oleh pengguna dan nyaman bagi pengembang mereka sendiri.
Infrastruktur kami
Tim pengembangan kami adalah 60 orang yang dibagi menjadi tim Scrum, di antaranya ada juga tim DevOps. Sebagian besar perintah Scrum mendukung fungsionalitas produk saat ini dan menghadirkan fitur baru. Tugas DevOps adalah membuat dan memelihara infrastruktur yang membantu aplikasi bekerja dengan cepat dan andal serta memungkinkan tim untuk dengan cepat memberikan fungsionalitas baru kepada pengguna.

Aplikasi kami adalah papan online tanpa akhir. Ini terdiri dari tiga lapisan: situs, klien, dan server di Jawa, yang merupakan aplikasi stateful monolitik. Aplikasi ini membuat koneksi web-socket yang konstan dengan klien, dan setiap server menyimpan dalam cache cache yang terbuka.
Seluruh infrastruktur - lebih dari 70 server - terletak di Amazon: lebih dari 30 server dengan aplikasi Java, server web, server database kami, broker, dan banyak lagi. Dengan pertumbuhan fungsionalitas, semua ini harus diperbarui secara teratur, tanpa mengganggu pekerjaan pengguna.
Memperbarui situs dan klien itu sederhana: kami mengganti versi yang lama dengan yang baru, dan saat berikutnya pengguna mengakses situs baru dan klien baru. Tetapi jika kita melakukan ini ketika server dilepaskan, kita mengalami downtime. Bagi kami, ini tidak dapat diterima, karena nilai utama dari produk kami adalah kerja bersama pengguna secara real time.
Bagaimana proses CI / CD kami terlihat
Proses CI / CD bersama kami adalah git commit, git push, kemudian perakitan otomatis, pengujian otomatis, penyebaran, rilis dan pemantauan.
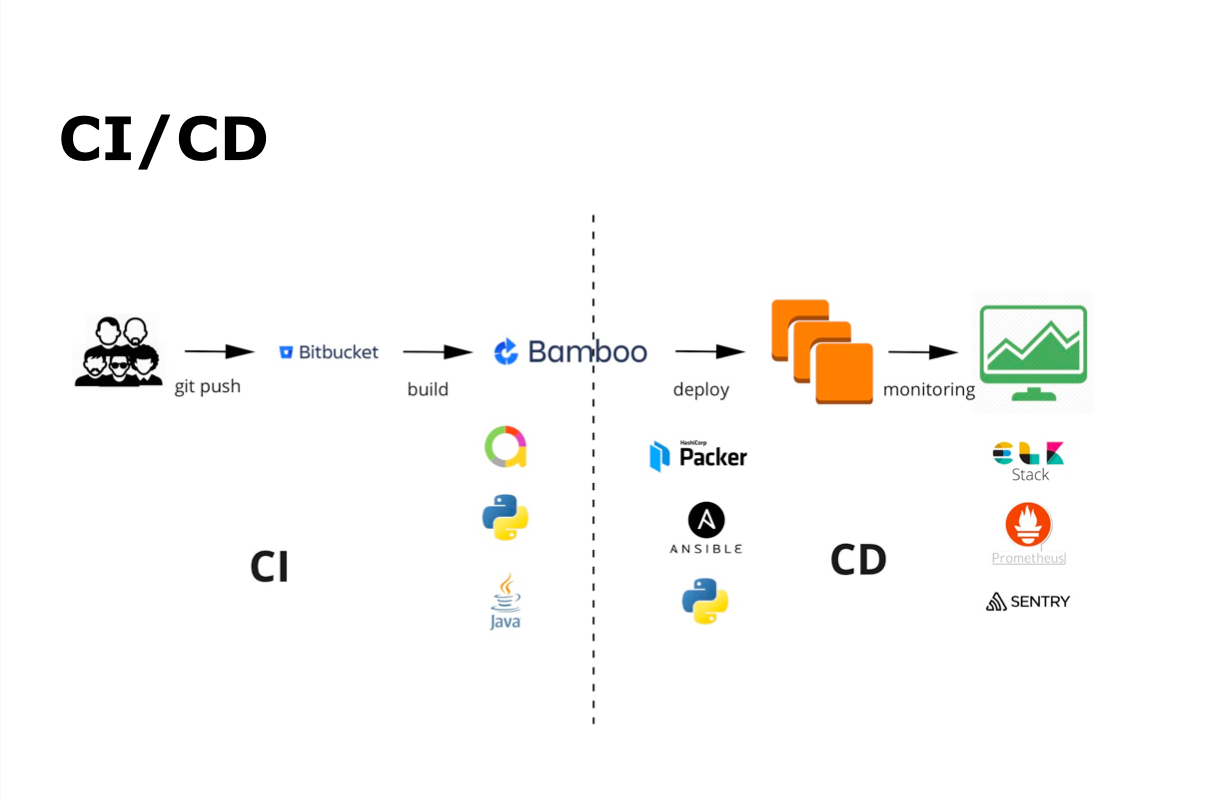
Untuk integrasi berkelanjutan, kami menggunakan Bamboo dan Bitbucket. Untuk pengujian otomatis - Java dan Python, dan Allure - untuk menampilkan hasil pengujian otomatis. Untuk pengiriman kontinu - Packer, Ansible, dan Python. Semua pemantauan dilakukan menggunakan ELK Stack, Prometheus dan Sentry.
Pengembang menulis kode, menambahkannya ke repositori, setelah itu perakitan otomatis dan pengujian otomatis diluncurkan. Pada saat yang sama di dalam tim mengumpulkan dari pengembang lain dan melakukan Peninjauan Kode. Ketika semua proses yang diperlukan, termasuk autotest, telah selesai, tim memegang bangunan di cabang utama, dan membangun cabang utama dimulai dan dikirim untuk pengujian otomatis. Seluruh proses debugged dan dilakukan oleh tim sendiri.
Gambar AMI
Sejalan dengan build build dan testing, build image AMI untuk Amazon dimulai. Untuk melakukan ini, kami menggunakan Packer dari HashiCorp, alat opensource yang hebat yang memungkinkan Anda membuat gambar mesin virtual. Semua parameter diteruskan ke JSON dengan satu set kunci konfigurasi. Parameter utama adalah pembangun, yang menunjukkan untuk penyedia mana kami membuat gambar (dalam kasus kami, untuk Amazon).
"builders": [{ "type": "amazon-ebs", "access_key": "{{user `aws_access_key`}}", "secret_key": "{{user `aws_secret_key`}}", "region": "{{user `aws_region`}}", "vpc_id": "{{user `aws_vpc`}}", "subnet_id": "{{user `aws_subnet`}}", "tags": { "releaseVersion": "{{user `release_version`}}" }, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ami_name": "packer-board-ami_{{isotime \"2006-01-02_15-04\"}}" }],
Adalah penting bahwa kita tidak hanya membuat gambar dari mesin virtual, tetapi mengkonfigurasinya terlebih dahulu menggunakan Ansible: menginstal paket yang diperlukan dan membuat pengaturan konfigurasi untuk menjalankan aplikasi Java.
"provisioners": [{ "type": "ansible", "playbook_file": "./playbook.yml", "user": "ubuntu", "host_alias": "default", "extra_arguments": ["--extra_vars=vars"], "ansible_env_vars": ["ANSIBLE_HOST_KEY_CHECKING=False", "ANSIBLE_NOCOLOR=True"] }]
Peran yang dimungkinkan
Kami dulu menggunakan buku pedoman Ansible biasa, tetapi ini menyebabkan banyak kode berulang, yang menjadi sulit untuk tetap up to date. Kami mengubah sesuatu di satu buku pedoman, lupa melakukannya di yang lain, dan akibatnya kami mengalami masalah. Jadi kami mulai menggunakan Ansible-role. Kami menjadikannya serbaguna mungkin sehingga kami dapat menggunakannya kembali di berbagai bagian proyek dan tidak membebani kode dalam potongan berulang besar. Misalnya, kami menggunakan peran Pemantauan untuk semua jenis server.
- name: Install all board dependencies hosts: all user: ubuntu become: yes roles: - java - nginx - board-application - ssl-certificates - monitoring
Dari sisi Scrum-tim proses ini terlihat sesederhana mungkin: tim menerima notifikasi di Slack bahwa build dan AMI-image telah dirakit.
Pra-rilis
Kami memperkenalkan pra-rilis untuk mengirimkan perubahan produk kepada pengguna secepat mungkin. Sebenarnya, ini adalah rilis kenari yang memungkinkan Anda untuk menguji fungsionalitas baru dengan aman pada sebagian kecil pengguna.
Mengapa rilis disebut kenari? Sebelumnya, para penambang, ketika mereka turun ke tambang, membawa kenari. Jika ada gas di tambang, kenari mati, dan para penambang dengan cepat naik ke permukaan. Begitu pula dengan kami: jika ada masalah dengan server, maka rilisnya tidak siap dan kami dapat dengan cepat memutar kembali dan sebagian besar pengguna tidak akan melihat apa-apa.
Bagaimana rilis kenari dimulai:- Tim pengembang di Bamboo mengklik tombol -> aplikasi Python disebut yang meluncurkan pra-rilis.
- Itu menciptakan contoh baru di Amazon dari gambar AMI yang sudah disiapkan sebelumnya dengan versi baru aplikasi.
- Mesin virtual ditambahkan ke grup target yang diperlukan dan load balancers.
- Dengan Ansible, konfigurasi individual dikonfigurasikan untuk setiap instance.
- Pengguna bekerja dengan versi baru aplikasi Java.
Di samping perintah Scrum, proses peluncuran pra-rilis sekali lagi terlihat sesederhana mungkin: tim menerima pemberitahuan di Slack bahwa proses telah dimulai, dan setelah 7 menit server baru sudah beroperasi. Selain itu, aplikasi mengirim ke Slack seluruh changelog perubahan dalam rilis.
Agar penghalang perlindungan dan keandalan ini berfungsi, tim Scrum memantau kesalahan baru di Sentry. Ini adalah aplikasi pelacakan bug sumber terbuka secara real time. Sentry terintegrasi dengan Java dan memiliki konektor dengan logback dan log2j. Ketika aplikasi dimulai, kami mentransfer ke Sentry versi yang menjalankannya, dan ketika kesalahan terjadi, kami melihat di versi mana aplikasi itu terjadi. Ini membantu tim Scrum merespons kesalahan dengan cepat dan memperbaikinya dengan cepat.
Pra-rilis harus bekerja setidaknya selama 4 jam. Selama waktu ini, tim memantau pekerjaannya dan memutuskan apakah akan merilis rilis ke semua pengguna.
Beberapa tim dapat secara bersamaan merilis rilis mereka . Untuk melakukan ini, mereka sepakat di antara mereka sendiri apa yang masuk ke dalam pra-rilis dan siapa yang bertanggung jawab untuk rilis final. Setelah itu, tim menggabungkan semua perubahan menjadi satu pra-rilis, atau meluncurkan beberapa pra-rilis pada saat yang sama. Jika semua pra-rilis sudah benar, mereka akan dirilis sebagai satu rilis di hari berikutnya.
Rilis
Kami melakukan rilis harian:
- Kami memperkenalkan server baru agar berfungsi.
- Kami memantau aktivitas pengguna di server baru menggunakan Prometheus.
- Tutup akses untuk pengguna baru ke server lama.
- Kami mentransfer pengguna dari server lama ke yang baru.
- Matikan server lama.
Semuanya dibangun menggunakan aplikasi Bamboo dan Python. Aplikasi memeriksa jumlah server yang berjalan dan bersiap untuk meluncurkan jumlah yang sama dengan yang baru. Jika tidak ada cukup server, mereka dibuat dari gambar AMI. Versi baru dikerahkan pada mereka, aplikasi Java diluncurkan, dan server dioperasikan.
Saat memantau, aplikasi Python menggunakan API Prometheus memeriksa jumlah papan terbuka di server baru. Ketika mengerti bahwa semuanya berfungsi dengan baik, ia menutup akses ke server lama dan mentransfer pengguna ke yang baru.
import requests PROMETHEUS_URL = 'https://prometheus' def get_spaces_count(): boards = {} try: params = { 'query': 'rtb_spaces_count{instance=~"board.*"}' } response = requests.get(PROMETHEUS_URL, params=params) for metric in response.json()['data']['result']: boards[metric['metric']['instance']] = metric['value'][1] except requests.exceptions.RequestException as e: print('requests.exceptions.RequestException: {}'.format(e)) finally: return boards
Proses mentransfer pengguna antar server ditampilkan di Grafana. Di bagian kiri grafik, server yang menjalankan versi lama ditampilkan, di sebelah kanan - yang baru. Persimpangan grafik adalah momen transfer pengguna.

Tim mengawasi pelepasan Slack. Setelah rilis, seluruh changelog perubahan dipublikasikan di saluran terpisah di Slack, dan di Jira semua tugas yang terkait dengan rilis ini ditutup secara otomatis.
Apa itu migrasi pengguna
Kami menyimpan status papan tulis tempat pengguna bekerja, dalam memori aplikasi dan terus-menerus menyimpan semua perubahan ke database. Untuk mentransfer papan di tingkat interaksi cluster, kami memuatnya ke dalam memori di server baru dan mengirimkan klien perintah untuk menyambung kembali. Pada titik ini, klien terputus dari server lama dan terhubung ke yang baru. Setelah beberapa detik, pengguna melihat tulisan - Koneksi dipulihkan. Namun, mereka terus bekerja dan tidak melihat ketidaknyamanan.
Apa yang kami pelajari saat membuat penyebaran tidak terlihat
Apa yang kita dapatkan setelah selusin iterasi:
- Tim scrum memeriksa kodenya sendiri.
- Tim scrum memutuskan kapan untuk meluncurkan pra-rilis dan membawa beberapa perubahan kepada pengguna baru.
- Scrum-team memutuskan apakah rilisnya siap untuk digunakan oleh semua pengguna.
- Pengguna terus bekerja dan tidak memperhatikan apa pun.
Ini tidak mungkin segera, kami menginjak menyapu yang sama berkali-kali dan mengisi banyak kerucut. Saya ingin membagikan pelajaran yang telah kami terima.
Pertama, proses manual, dan baru setelah itu otomatisasi. Langkah-langkah pertama tidak perlu masuk lebih jauh ke dalam otomatisasi, karena Anda dapat mengotomatisasi apa yang pada akhirnya tidak berguna.
Kemungkinan adalah baik, tetapi peran yang mungkin lebih baik. Kami membuat peran kami seuniversal mungkin: kami menyingkirkan kode berulang, jadi mereka hanya membawa fungsionalitas yang harus mereka bawa. Ini memungkinkan Anda menghemat waktu secara signifikan dengan menggunakan kembali peran, yang sudah kami miliki lebih dari 50.
Gunakan kembali kode dengan Python dan pecah menjadi perpustakaan dan modul yang terpisah. Ini membantu Anda menavigasi proyek yang kompleks dan dengan cepat membenamkan orang-orang baru di dalamnya.
Langkah selanjutnya
Proses penyebaran yang tak terlihat belum berakhir. Berikut ini beberapa langkah berikut:
- Izinkan tim untuk menyelesaikan tidak hanya pra-rilis, tetapi semua rilis.
- Buat rollback otomatis jika terjadi kesalahan. Misalnya, pra-rilis harus secara otomatis memutar kembali jika kesalahan kritis terdeteksi di Sentry.
- Mengotomatisasi sepenuhnya rilis tanpa adanya kesalahan. Jika tidak ada kesalahan pada pra-rilis, itu berarti dapat secara otomatis diluncurkan lebih lanjut.
- Tambahkan pemindaian kode otomatis untuk kemungkinan kesalahan keamanan.