Halo, Habr! Setelah cukup istirahat setelah liburan panjang, kami siap melakukan kebaikan Anda dengan semua cara yang tersedia. Kolega dari departemen TI selalu memiliki sesuatu untuk diceritakan, dan hari ini kami berbagi dengan Anda laporan oleh Alexander Prizov, administrator sistem Yandex.Money, dari pertemuan JavaJam.
Bagaimana kami membangun aliran umpan balik untuk mendeteksi rilis masalah menggunakan Graphite dan Moira. Kami akan memberi tahu Anda cara mengumpulkan dan menganalisis metrik tentang jumlah kesalahan dalam aplikasi.
- Halo semuanya, nama saya Alexander Prizov, saya bekerja di departemen otomatisasi operasi di Yandex.Money, dan hari ini saya akan memberi tahu Anda tentang bagaimana kami mengumpulkan, memproses, menganalisis informasi tentang sistem kami.
Anda mungkin bertanya-tanya mengapa laporan itu disebut The Second Way (nama laporan pada pertemuan itu ed.). Semuanya cukup sederhana. Di jantung DevOps adalah sejumlah prinsip yang secara kondisional dibagi menjadi tiga kelompok.
Cara pertama adalah prinsip flow. Cara kedua melibatkan prinsip umpan balik. Cara ketiga adalah pembelajaran dan eksperimen yang berkelanjutan.
Sebagai aturan, dalam hal pengembangan dan pengoperasian produk perangkat lunak, umpan balik berarti telemetri, yang kami kumpulkan tentang sistem kami, dan kasus yang paling umum adalah pengumpulan dan pemrosesan metrik.
Mengapa kita membutuhkan metrik ini? Dengan bantuan metrik, kami mendapatkan umpan balik dari sistem dan kami dapat mengetahui status sistem kami, apakah semuanya berjalan dengan baik, bagaimana perubahan kami memengaruhi operasinya, dan apakah diperlukan intervensi untuk menyelesaikan masalah tertentu.
Metrik apa yang kami kumpulkan?
Kami mengumpulkan metrik dari tiga level.
Tingkat bisnis mencakup indikator yang menarik dari sudut pandang tugas bisnis apa pun. Misalnya, kita bisa mendapatkan jawaban atas pertanyaan seperti berapa banyak pengguna yang telah kita daftarkan, seberapa sering pengguna masuk ke sistem kita, berapa banyak pengguna aktif yang dimiliki aplikasi seluler kita.
Level selanjutnya adalah level aplikasi . Metrik tingkat ini paling sering dilihat oleh pengembang, karena indikator ini memberikan jawaban untuk pertanyaan seberapa baik aplikasi kita bekerja, seberapa cepat aplikasi memproses permintaan, apakah ada kekurangan dalam kinerja. Ini termasuk waktu respons, jumlah permintaan, panjang antrian, dan banyak lagi.
Dan akhirnya, tingkat infrastruktur . Semuanya sangat jelas di sini. Dengan menggunakan metrik ini, kami dapat memperkirakan jumlah sumber daya yang dikonsumsi, cara memperkirakannya, dan mengidentifikasi masalah terkait infrastruktur.
Singkatnya, saya akan menjelaskan bagaimana kami mengirim, memproses, dan di mana kami menyimpan metrik ini. Di sebelah aplikasi, kami memiliki pengumpul metrik. Dalam kasus kami, ini adalah layanan Heka, yang mendengarkan port UDP dan mengharapkan metrik dalam format StatsD sebagai input.
Format StatsD adalah sebagai berikut:

Yaitu, kami menentukan nama metrik, menunjukkan nilai metrik ini, yaitu 1, 26, dan seterusnya, dan menunjukkan jenisnya. Secara total, StatsD memiliki sekitar empat atau lima jenis. Jika Anda tiba-tiba tertarik, Anda dapat melihat secara detail deskripsi jenis ini .
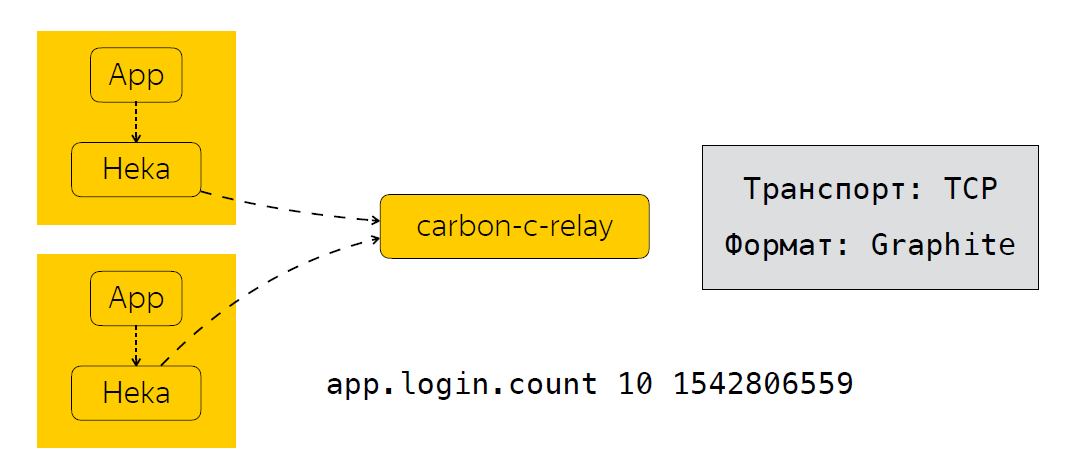
Setelah aplikasi mengirim data Heka, metrik dikumpulkan untuk waktu tertentu. Dalam kasus kami, ini adalah 30 detik, setelah itu Heka mengirimkan data ke carbon-c-relay, yang melakukan fungsi penyaringan, perutean, memperbarui metrik, yang, pada gilirannya, mengirimkan metrik ke penyimpanan kami, kami menggunakan clickhouse (ya, itu tidak memperlambat) ), serta di Moira. Jika ada yang tidak tahu, ini adalah layanan yang memungkinkan Anda mengonfigurasi pemicu tertentu untuk metrik. Saya akan berbicara tentang Moira sedikit kemudian. Jadi, kami melihat metrik apa yang kami kumpulkan, bagaimana kami mengirim dan memprosesnya. Dan langkah logis berikutnya adalah analisis metrik ini.
Bagaimana kami menganalisis metrik?
Saya akan memberikan situasi nyata di mana analisis metrik memberi kami hasil nyata. Ambil proses rilis sebagai contoh. Secara umum, ini termasuk langkah-langkah berikut.
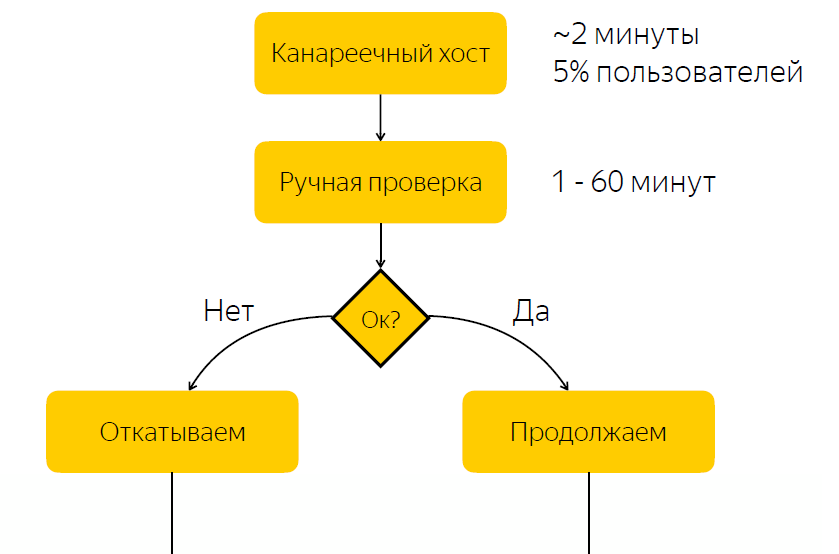
Rilis ini dikerahkan ke host kenari. Ini menyumbang sekitar lima persen dari lalu lintas pengguna. Setelah rilis ke host kenari selesai, kami memberi tahu orang yang bertanggung jawab untuk rilis bahwa ia harus memeriksa apakah semuanya baik-baik saja dengan rilis. Dan dia harus memberikan reaksi, bereaksi terhadap rilis ini dan mengklik tombol dengan keputusan apakah rilis ini harus diputar, atau harus diputar kembali.
Tidak sulit untuk menebak bahwa ada kelemahan yang signifikan dalam skema ini, yaitu, bahwa kita mengharapkan reaksi yang bertanggung jawab. Jika orang yang bertanggung jawab saat ini karena suatu alasan tidak dapat merespons dengan cepat, maka jika kami memiliki rilis bug, maka untuk beberapa waktu lima persen dari lalu lintas datang ke simpul masalah. Jika semuanya sesuai dengan rilis, maka kami hanya menghabiskan waktu menunggu, dan dengan demikian memperlambat proses rilis.
Tanpa bug - kami memperlambat proses rilis
Dengan bug - kasih sayang pengguna
Dengan memahami masalah ini, kami memutuskan untuk mencari tahu apakah mungkin untuk mengotomatiskan proses pengambilan keputusan pada apakah rilis itu bermasalah atau tidak.
Tentu saja, kami berpaling kepada pengembang kami untuk memahami bagaimana pemeriksaan rilis dilakukan. Ternyata, dan tampaknya cukup logis, bahwa indikator utama bahwa rilis itu bermasalah adalah peningkatan jumlah kesalahan dalam log aplikasi ini.
Apa yang dilakukan pengembang? Mereka membuka Kibana, membuat pilihan sesuai dengan tingkat KESALAHAN dari blok aplikasi, dan jika mereka melihat daftar, mereka berpikir ada sesuatu yang salah dengan aplikasi tersebut. Perlu disebutkan bahwa log aplikasi kita disimpan dalam Elastis, dan tampaknya semuanya terlihat cukup sederhana. Kami memiliki log di Elastis, kami hanya harus membuat permintaan di Elastis, membuat pilihan dan memahami berdasarkan data ini apakah rilis itu bermasalah atau tidak. Namun keputusan ini bagi kami tampaknya tidak terlalu baik.
Kenapa tidak elastis?
Pertama-tama, kami khawatir bahwa kami mungkin tidak dapat dengan cepat menerima data dari Elastic. Ada kasus-kasus seperti itu, misalnya, selama pengujian stres, ketika kita memiliki aliran data yang besar, dan cluster mungkin tidak mengatasinya, dan, pada akhirnya, ada keterlambatan pengiriman log selama sekitar 10-15 menit.
Ada juga alasan sekunder, misalnya, kurangnya nama seragam untuk indeks. Ini harus diperhitungkan dalam alat otomatisasi. Dan juga aplikasi pada platform yang berbeda dapat memiliki format log yang berbeda.
Kami pikir, mengapa tidak mencoba membuat semacam metrik berdasarkan mana kita dapat memutuskan apakah rilis itu bermasalah atau tidak. Pada saat yang sama, kami tidak ingin membebani pengembang kami untuk membuat perubahan pada basis kode. Dan, sepertinya bagi kami, kami menemukan solusi yang agak elegan dengan menambahkan append tambahan ke log4j.
Seperti apa bentuknya
<?xml version="1.0" encoding="UTF-8" ?> <Configuration status="warn" name="${sys:application.name}" > <Properties> <Property name="logsCountStatsDFormat">app_name.logs.%level:1|c</Property> </Properties> ... <Appenders> <Socket name="STATSD" host="127.0.0.1" port="8125" protocol="UDP"> <PatternLayout pattern="${logsCountStatsDFormat}"/> </Socket> </Appenders> <Loggers> <Root level="INFO"> <AppenderRef ref="STATSD"/> </Root> </Loggers> </Configuration>
Pertama, kami menentukan format metrik yang kami kirim. Berikut ini adalah lampiran tambahan yang mengirimkan catatan dalam format yang kami miliki di atas ke port 8125 melalui UDP, yaitu ke Heka. Apa yang ini berikan pada kita? Log4j mengirimkan metrik tipe Penghitung ke setiap entri log dengan tingkat catatan yang ditentukan ERROR, INFO, PERINGATAN, dan sebagainya.
Namun, kami segera menyadari bahwa mengirim metrik ke setiap entri log dapat membuat beban yang cukup signifikan, dan kami menulis pustaka yang mengagregasi metrik untuk waktu tertentu dan mengirimkan metrik yang sudah teragregasi ke layanan Heka. Sebenarnya, kami menambahkan aplikasi ini ke logger, dan dengan pendekatan ini kami sekarang tahu berapa banyak aplikasi kami menulis log untuk leveling, kami memiliki nama terpadu untuk metrik, terlepas dari platform mana yang digunakan. Kita dapat dengan mudah memahami berapa banyak kesalahan dalam log aplikasi. Dan akhirnya, kami dapat mengotomatiskan proses pengambilan keputusan untuk rilis yang bermasalah.
Otomasi
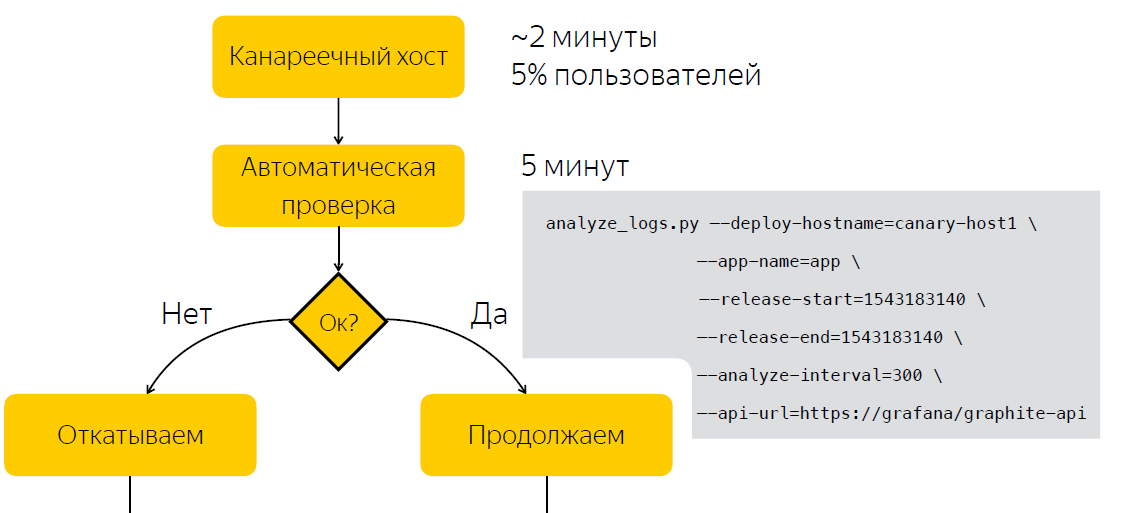
Alih-alih memeriksa secara manual setelah rilis, kami menunggu lima menit, setelah itu kami mengumpulkan data pada jumlah entri dalam log aplikasi. Setelah kami menjalankan skrip, yang, berdasarkan dua sampel, sebelum rilis dan setelah, memutuskan apakah rilis itu bermasalah. Dengan demikian, kami mengurangi jumlah waktu yang kami habiskan untuk membuat keputusan menjadi lima menit.
Selain fakta bahwa informasi tentang jumlah kesalahan dalam log berguna selama rilis, ternyata bonus yang bagus juga berguna selama operasi. Jadi, misalnya, kita dapat memvisualisasikan jumlah kesalahan dalam log di Grafana dan mencatat lonjakan anomali di log aplikasi.
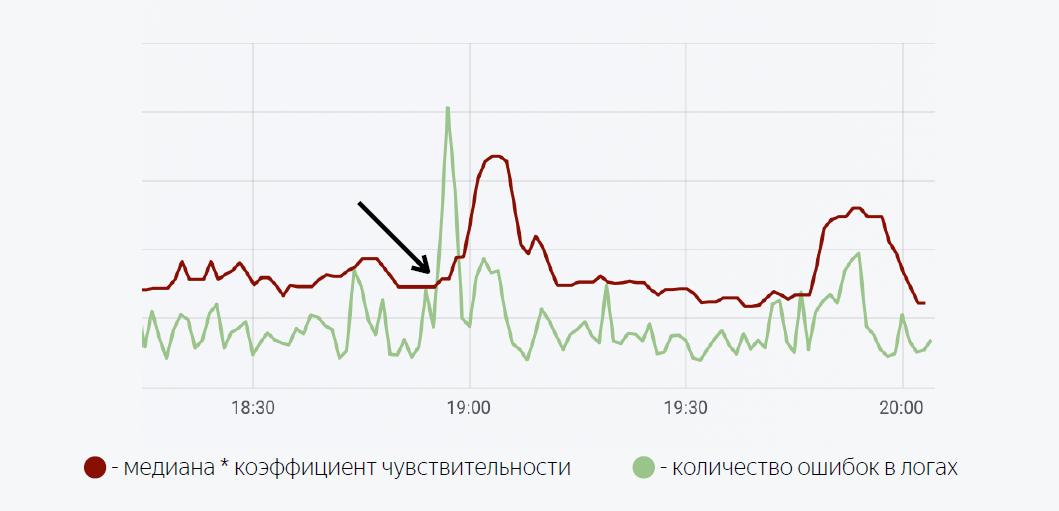
Model matematika yang cukup sederhana digunakan di sini. Garis hijau adalah jumlah kesalahan dalam log aplikasi. Merah tua adalah median kali faktor sensitivitas. Dalam kasus ketika jumlah kesalahan dalam log melewati median, pemicu dipicu, ketika dipicu, pemberitahuan dikirim melalui Moira.
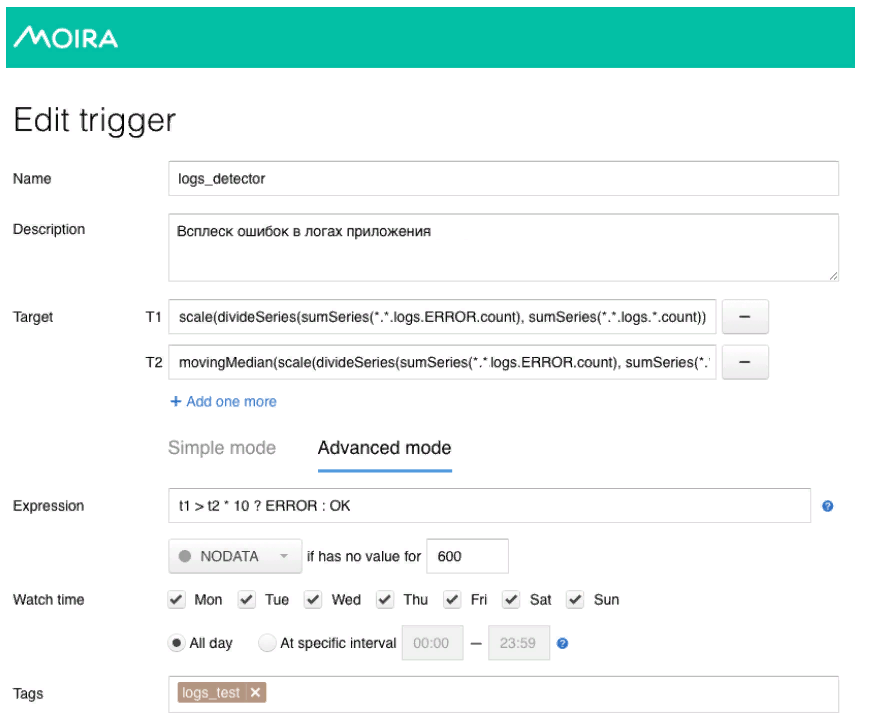
Seperti yang saya janjikan, saya akan bercerita sedikit tentang Moira, bagaimana cara kerjanya. Kami menetapkan metrik target yang ingin kami amati. Ini adalah jumlah kesalahan dan median bergerak, serta kondisi di mana pemicu ini akan bekerja, yaitu, ketika jumlah kesalahan dalam log melebihi median kali koefisien sensitivitas. Ketika pemicu dipicu, pengembang menerima pemberitahuan bahwa ledakan kesalahan yang abnormal telah dicatat dalam aplikasi, dan beberapa tindakan harus diambil.

Apa yang kita miliki pada akhirnya? Kami telah mengembangkan mekanisme umum untuk semua aplikasi backend kami, yang memungkinkan kami untuk mendapatkan informasi tentang jumlah entri dalam log pada level tertentu. Selain itu, dengan menggunakan metrik tentang jumlah kesalahan dalam log aplikasi, kami dapat mengotomatiskan proses pengambilan keputusan apakah rilisnya bermasalah atau tidak. Mereka juga menulis perpustakaan untuk log4j, yang dapat Anda gunakan jika Anda ingin mencoba pendekatan yang saya jelaskan. Tautan ke perpustakaan di bawah ini.
Mungkin itu semua untuk saya. Terima kasih
Tautan yang bermanfaat
Log4j-count-appender
Moira