Pengingat
Halo, Habr! Saya memberi perhatian Anda terjemahan lain dari artikel baru saya dari
media .
Terakhir kali (
artikel pertama ) (
Habr ), kami menciptakan agen menggunakan teknologi Q-Learning, yang melakukan transaksi pada rangkaian waktu simulasi dan pertukaran riil dan mencoba memeriksa apakah bidang tugas ini cocok untuk pembelajaran yang diperkuat.
Kali ini kami akan menambahkan layer LSTM untuk memperhitungkan dependensi waktu akun dalam lintasan dan melakukan teknik pembentukan hadiah berdasarkan presentasi.
Biarkan saya mengingatkan Anda bahwa untuk memverifikasi konsep, kami menggunakan data sintetis berikut:
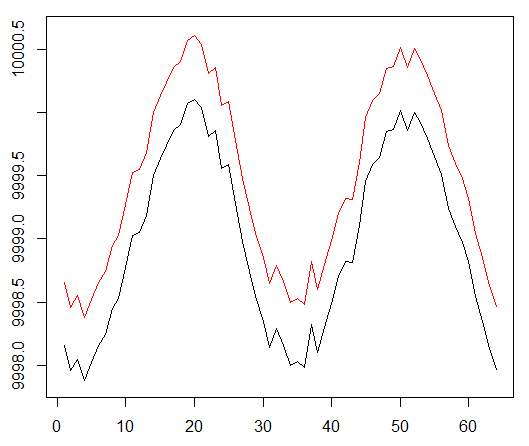
Data sintetis: sinus dengan noise putih.
Fungsi sinus adalah titik awal pertama. Dua kurva mensimulasikan harga pembelian dan penjualan suatu aset, di mana spread adalah biaya transaksi minimum.
Namun, kali ini kami ingin menyulitkan tugas sederhana ini dengan memperluas jalur penugasan kredit:
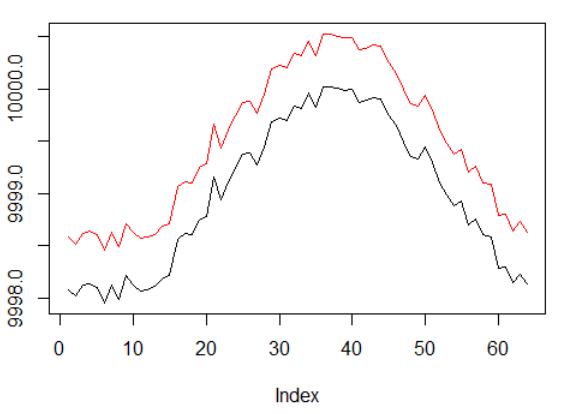
Data sintetis: sinus dengan noise putih.
Fase sinus digandakan.
Ini berarti bahwa hadiah jarang yang kami gunakan harus tersebar di lintasan yang lebih panjang. Selain itu, kami secara signifikan mengurangi kemungkinan menerima hadiah positif, karena agen harus melakukan serangkaian tindakan yang benar 2 kali lebih lama untuk mengatasi biaya transaksi. Kedua faktor tersebut sangat menyulitkan tugas RL bahkan dalam kondisi sederhana seperti gelombang sinus.
Selain itu, kami ingat bahwa kami menggunakan arsitektur jaringan saraf ini:
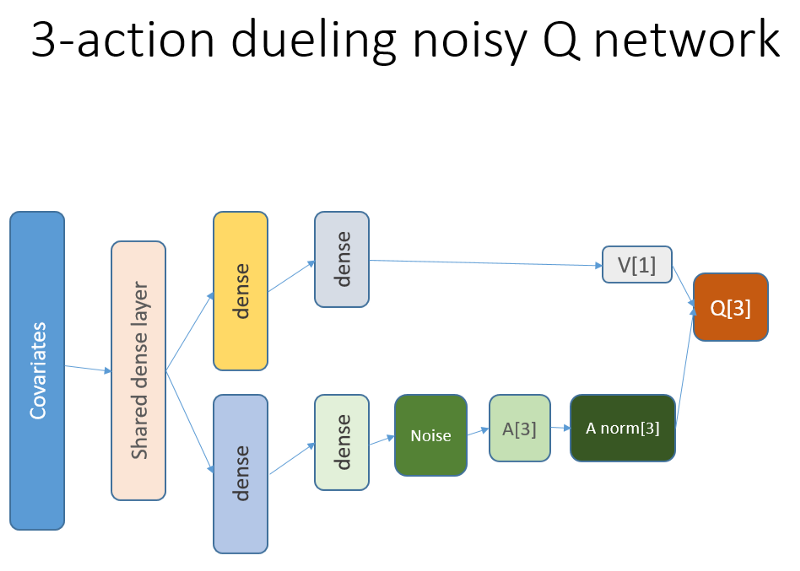
Apa yang ditambahkan dan mengapa
Lstm
Pertama-tama, kami ingin memberi agen lebih banyak pemahaman tentang dinamika perubahan dalam lintasan. Sederhananya, agen harus lebih memahami perilakunya sendiri: apa yang dia lakukan sekarang dan untuk beberapa waktu di masa lalu, dan bagaimana distribusi tindakan negara, serta imbalan yang diterima, dikembangkan. Menggunakan layer perulangan dapat memecahkan masalah ini dengan tepat. Selamat datang di arsitektur baru yang digunakan untuk meluncurkan serangkaian eksperimen baru:

Harap perhatikan bahwa deskripsi saya sedikit ditingkatkan. Satu-satunya perbedaan dari NN lama adalah lapisan LSTM pertama yang tersembunyi dan bukan yang sepenuhnya terikat.
Harap dicatat bahwa dengan LSTM dalam pekerjaan, kita harus mengubah pemilihan contoh reproduksi pengalaman untuk pelatihan: sekarang kita membutuhkan urutan transisi daripada contoh yang terpisah. Begini cara kerjanya (ini adalah salah satu algoritma). Kami menggunakan point sampling sebelum:

Skema fiktif dari buffer pemutaran.
Kami menggunakan skema ini dengan LSTM:

Sekarang urutan dipilih (yang panjangnya kita tentukan secara empiris).
Seperti sebelumnya, dan sekarang sampel diatur oleh algoritma prioritas berdasarkan kesalahan pembelajaran temporal-temporal.
Level rekurensi LSTM memungkinkan penyebaran informasi secara langsung dari deret waktu untuk mencegat sinyal tambahan yang tersembunyi di jeda waktu lalu. Rangkaian waktu bersama kami adalah tensor dua dimensi dengan ukuran: panjang urutan pada representasi tindakan negara kami.
Presentasi
Rekayasa pemenang penghargaan, Potential Based Reward Shaping (PBRS), berdasarkan potensi, adalah alat yang ampuh yang memungkinkan Anda untuk meningkatkan kecepatan, stabilitas dan tidak melanggar optimalitas proses pencarian kebijakan untuk menyelesaikan masalah lingkungan kita. Saya sarankan membaca setidaknya dokumen asli ini dengan topik:
people.eecs.berkeley.edu/~russell/papers/ml99-shaping.psPotensi menentukan seberapa baik keadaan kita saat ini relatif terhadap keadaan target yang ingin kita masukkan. Pandangan skematis tentang cara kerjanya:

Ada beberapa opsi dan kesulitan yang bisa Anda pahami setelah coba-coba, dan kami menghilangkan detail ini, meninggalkan Anda dengan pekerjaan rumah Anda.
Perlu disebutkan satu hal lagi, yaitu PBRS dapat dibenarkan menggunakan presentasi, yang merupakan bentuk pengetahuan ahli (atau simulasi) tentang perilaku agen yang
hampir optimal di lingkungan. Ada cara untuk menemukan presentasi seperti itu untuk tugas kami menggunakan skema optimisasi. Kami menghilangkan detail pencarian.
Potensi hadiah berupa: (persamaan 1):
r '= r + gamma * F (s') - F (s)
di mana F adalah potensi negara, dan r adalah hadiah awal, gamma adalah faktor diskon (0: 1).
Dengan pemikiran ini, kami beralih ke pengkodean.Implementasi dalam R
Berikut adalah kode jaringan saraf berdasarkan API Keras:
Men-debug keputusan Anda berdasarkan hati nurani Anda ...
Hasil dan Perbandingan
Mari selami hasil akhirnya.
Catatan: semua hasil adalah estimasi titik dan mungkin berbeda pada beberapa kali berjalan dengan berbagai sids seed acak.Perbandingan meliputi:
- versi sebelumnya tanpa LSTM dan presentasi
- LSTM 2-elemen sederhana
- LSTM 4-elemen
- LSTM 4 sel dengan imbalan PBRS yang dihasilkan
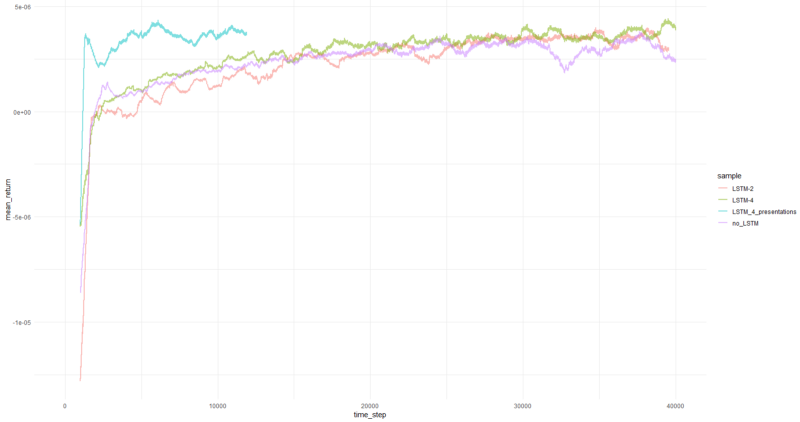
Pengembalian rata-rata per episode rata-rata lebih dari 1000 episode.
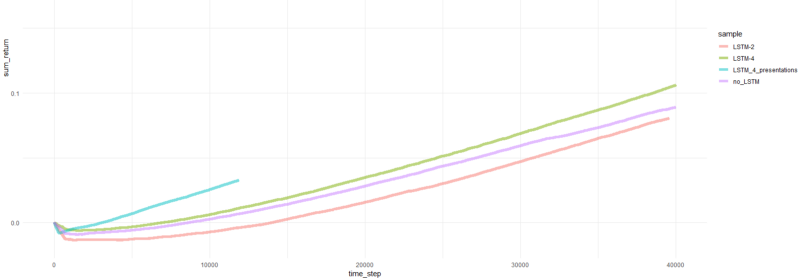
Total episode kembali.
Bagan untuk agen paling sukses:

Kinerja agen.
Yah, cukup jelas bahwa agen dalam bentuk PBRS bertemu begitu cepat dan stabil dibandingkan dengan upaya sebelumnya sehingga dapat diterima sebagai hasil yang signifikan. Kecepatannya sekitar 4-5 kali lebih tinggi daripada tanpa presentasi. Stabilitas luar biasa.
Ketika menggunakan LSTM, 4 sel memiliki kinerja lebih baik dari 2 sel. LSTM 2 sel tampil lebih baik daripada versi non-LSTM (namun, mungkin ini adalah ilusi dari satu percobaan).
Kata-kata terakhir
Kita telah melihat bahwa penghargaan yang berulang dan pembangunan kapasitas membantu. Saya terutama menyukai kinerja PBRS yang sangat tinggi.
Jangan percaya siapa pun yang membuat saya mengatakan bahwa mudah untuk membuat agen RL yang menyatu dengan baik, karena itu bohong. Setiap komponen baru yang ditambahkan ke sistem membuatnya berpotensi kurang stabil dan membutuhkan banyak konfigurasi dan debugging.
Namun demikian, ada bukti jelas bahwa solusi untuk masalah tersebut dapat diperbaiki hanya dengan meningkatkan metode yang digunakan (data tetap utuh). Adalah fakta bahwa untuk tugas apa pun sejumlah parameter tertentu berfungsi lebih baik daripada yang lain. Dengan pemikiran ini, Anda memulai jalur pembelajaran yang sukses.
Terima kasih