Pada awal 2018, kami secara aktif memulai proses digitalisasi produksi dan proses di perusahaan. Di sektor petrokimia, ini bukan hanya tren mode, tetapi langkah evolusi baru menuju peningkatan efisiensi dan daya saing. Mempertimbangkan kekhasan bisnis, yang, tanpa digitalisasi, menunjukkan hasil ekonomi yang baik, digitalisers menghadapi tugas yang sulit: mengubah proses yang telah mapan di perusahaan adalah tugas yang cukup melelahkan.
Digitalisasi kami dimulai dengan penciptaan dua pusat dan blok fungsional yang sesuai.
Ini adalah "Fungsi Teknologi Digital", yang mencakup semua area produk: digitalisasi proses, IIoT, dan analitik lanjutan, serta pusat manajemen data yang telah menjadi area independen.

Dan hanya tugas utama dari kantor data adalah untuk sepenuhnya menerapkan budaya pengambilan keputusan berdasarkan data (ya, ya, keputusan yang didorong data), serta, pada prinsipnya, merampingkan segala sesuatu yang terkait dengan bekerja dengan data: analisis, pemrosesan , penyimpanan dan pelaporan. Keunikannya adalah bahwa semua alat digital kita tidak hanya harus secara aktif menggunakan data mereka sendiri, yaitu, yang mereka hasilkan sendiri (misalnya, jalan memutar, atau sensor IIoT), tetapi juga data eksternal, dengan pemahaman yang jelas tentang di mana dan mengapa mereka dibutuhkan untuk digunakan.
Nama saya Artyom Danilov, saya adalah kepala departemen Infrastruktur dan Teknologi di SIBUR, dalam posting ini saya akan memberi tahu Anda bagaimana dan pada apa kami membangun sistem pemrosesan dan penyimpanan data yang besar untuk seluruh SIBUR. Untuk mulai dengan, kami hanya akan berbicara tentang arsitektur tingkat atas dan bagaimana Anda bisa menjadi bagian dari tim kami.
Berikut adalah area yang termasuk pekerjaan di kantor data:
1. Bekerja dengan dataOrang-orang yang secara aktif terlibat dalam inventarisasi dan katalogisasi data kami bekerja di sini. Mereka memahami kebutuhan apa yang dimiliki fungsi tertentu, dapat menentukan analitik seperti apa yang mungkin dibutuhkan, metrik apa yang harus dipantau untuk membuat keputusan, dan bagaimana data digunakan dalam area bisnis tertentu.
2. BI dan visualisasi dataArahnya terkait erat dengan yang pertama dan memungkinkan Anda untuk memvisualisasikan hasil kerja orang-orang dari tim utama.
3. Arah kontrol kualitas dataDi sini alat kontrol kualitas data diperkenalkan dan seluruh metodologi kontrol tersebut diimplementasikan. Dengan kata lain, orang-orang dari sini menerapkan perangkat lunak, menulis berbagai pemeriksaan dan pengujian, memahami bagaimana pemeriksaan silang antara sistem yang berbeda terjadi, mencatat fungsi karyawan yang bertanggung jawab atas kualitas data, dan juga membangun metodologi umum.
4. Manajemen NSIKami adalah perusahaan besar. Kami memiliki banyak jenis direktori - dan kontraktor, dan material, dan direktori perusahaan ... Secara umum, percayalah, ada lebih dari cukup direktori.
Ketika sebuah perusahaan secara aktif membeli sesuatu untuk kegiatannya, biasanya memiliki proses khusus untuk mengisi direktori ini. Kalau tidak, kekacauan akan mencapai tingkat sedemikian rupa sehingga tidak mungkin untuk bekerja dari kata "sepenuhnya". Kami juga memiliki sistem seperti itu (MDM).
Inilah masalahnya. Misalkan, di salah satu divisi regional, di mana kami memiliki banyak, karyawan duduk dan memasukkan data ke dalam sistem. Berkontribusi dengan tangan, dengan semua konsekuensi yang timbul dari metode ini. Artinya, mereka perlu memasukkan data, memverifikasi bahwa semuanya tiba di sistem dalam bentuk yang benar, tanpa duplikat. Pada saat yang sama, beberapa hal, dalam hal mengisi beberapa detail dan bidang yang diperlukan, Anda harus mencari dan google secara mandiri. Misalnya, Anda memiliki TIN perusahaan, dan Anda memerlukan informasi lain - Anda memeriksa melalui layanan khusus dan register.
Semua data ini, tentu saja, sudah ada di suatu tempat, jadi cukup tepat untuk menariknya secara otomatis.
Sebelumnya, perusahaan, pada prinsipnya, tidak memiliki posisi tunggal, tim yang jelas yang akan melakukan ini. Ada banyak divisi yang tersebar yang secara manual memasukkan data. Tetapi biasanya sulit untuk struktur seperti itu untuk merumuskan apa yang sebenarnya dan di mana tepatnya dalam proses bekerja dengan data harus diubah sehingga semuanya sempurna. Oleh karena itu, kami meninjau format dan struktur manajemen NSI.
5. Implementasi data warehouse (data node)Inilah yang mulai kami lakukan di bidang ini.
Mari kita segera mendefinisikan istilah-istilahnya, jika tidak, frase yang saya gunakan dapat bersinggungan dengan beberapa konsep lain. Secara kasar, data node = data lake + data warehouse. Lebih jauh saya akan mengungkapkan ini secara lebih rinci.
Arsitektur
Pertama-tama, kami mencoba mencari tahu data seperti apa yang bekerja - sistem apa yang ada, sensor mana. Kami memahami seperti apa streaming data (inilah yang dihasilkan oleh perusahaan sendiri dari semua peralatan mereka, ini adalah IIoT dan sebagainya) dan sistem klasik, CRM berbeda, ERP, dan sejenisnya.
Kami menyadari bahwa data dalam sistem saat ini tidak akan cukup langsung menjadi volume yang sangat besar, tetapi dengan diperkenalkannya alat-alat digital dan IIoT akan ada banyak dari mereka. Dan juga akan ada data yang sangat heterogen dari sistem akuntansi klasik. Karena itu, mereka datang dengan arsitektur rencana seperti itu.

Rincian lebih lanjut tentang blok.
Penyimpanan
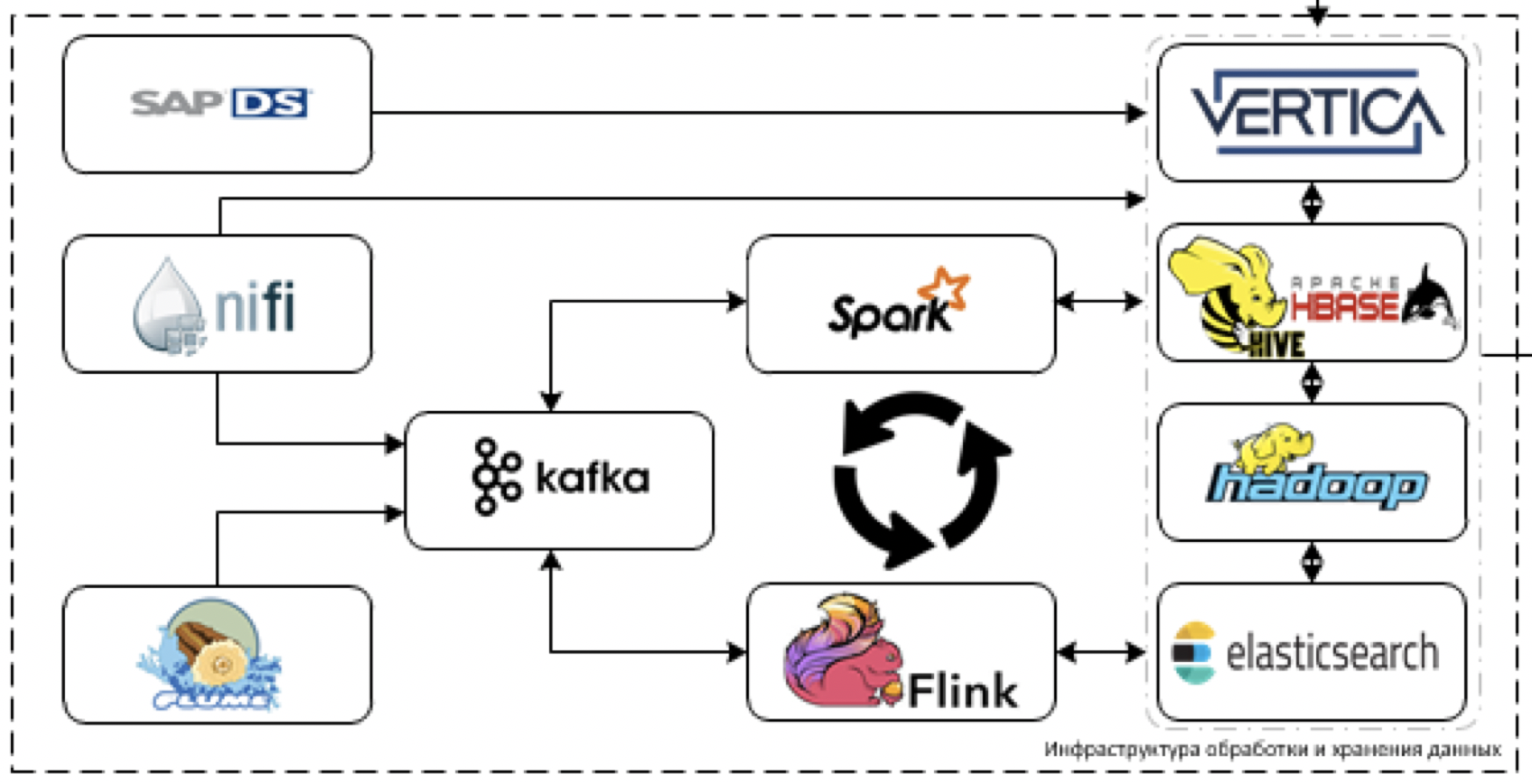
Ini adalah inti dari platform kami. Apa yang digunakan untuk memproses dan menyimpan data. Tantangannya adalah untuk mengunduh data dari lebih dari 60 sistem yang berbeda ketika mereka mulai mengirimkannya. Artinya, umumnya ada semua data yang mungkin berguna untuk membuat beberapa keputusan.
Mari kita mulai dengan ekstraksi dan pemrosesan data. Untuk tujuan ini, kami berencana untuk menggunakan alat ETL NiFi untuk streaming dan paket data, serta alat pemrosesan streaming: Flume untuk penerimaan data awal dan decoding, Kafka untuk buffering, Flink dan Spark Streaming sebagai alat pemrosesan aliran data utama.
Paling sulit untuk bekerja dengan sistem SAP stack. Anda harus mengambil data dari SAP menggunakan alat ETL terpisah - Layanan Data SAP.
Sebagai alat penyimpanan, kami berencana untuk menggunakan platform Cloudera Hadoop (HDFS, HBASE, Hive, Impala sendiri), DBMS analitik Vertica dan, untuk kasus individual, elasticsearch.
Pada dasarnya, kami menggunakan tumpukan paling canggih. Ya, Anda dapat mencoba melempar tomat ke arah kami dan mengejek apa yang kami sebut tumpukan paling modern, tetapi kenyataannya - memang begitu.
Kami tidak terbatas pada pengembangan warisan, tetapi kami tidak dapat menggunakan tepi pendarahan dalam solusi industri karena orientasi perusahaan yang eksplisit dari platform kami. Karena itu, mungkin kita tidak menyeret Horton, tetapi membatasi diri pada Clouder, sedapat mungkin, kita pasti berusaha menyeret alat yang lebih baru.

SAS Data Quality digunakan untuk mengontrol kualitas data, dan Airflow digunakan untuk mengelola semua kebaikan ini. Kami memantau seluruh platform melalui tumpukan ELK. Kami berencana untuk melakukan visualisasi untuk sebagian besar di Tableau, beberapa laporan yang sepenuhnya statis pada SAP BO.
Kami sudah memahami bahwa sebagian tugas tidak dapat diwujudkan melalui solusi BI standar, karena diperlukan visualisasi waktu nyata yang sangat canggih dengan banyak kontrol kardus. Oleh karena itu, kami akan menulis kerangka visualisasi kami sendiri, yang dapat tertanam dalam produk digital yang sedang dikembangkan.
Tentang platform digital
Jika Anda melihat sedikit lebih luas, sekarang kolega kami dari fungsi teknologi digital membangun platform digital tunggal, yang tugasnya adalah mengembangkan aplikasi kita sendiri dengan cepat.
Danau data adalah salah satu elemen dari platform ini.
Sebagai bagian dari kegiatan ini, kami memahami bahwa kami perlu mengimplementasikan antarmuka yang nyaman untuk mengakses data analitik. Oleh karena itu, kami berencana untuk mengimplementasikan API Data dan model objek produksi untuk akses yang lebih mudah ke data produksi.
Apa lagi yang kita lakukan dan siapa yang kita butuhkan
Selain menyimpan dan memproses data, semua pembelajaran mesin, serta kerangka kerja IIoT, akan bekerja pada platform kami. Danau akan bertindak sebagai sumber data untuk model pelatihan dan kerja, dan sebagai kapasitas untuk model kerja. Kerangka kerja ML yang akan bekerja di atas platform sudah siap.

Saat ini saya memiliki tim, beberapa arsitek dan 6 pengembang, jadi kami secara aktif mencari orang-orang baru (saya membutuhkan
arsitek data dan
insinyur data ) yang akan membantu kami dalam pengembangan platform. Anda tidak perlu melihat-lihat warisan (warisan ada di sini hanya di pintu masuk dari sistem), tumpukan masih segar.
Di situlah kehalusan akan berada - itu dalam integrasi. Untuk menghubungkan yang lama dengan yang baru, sehingga berfungsi dengan baik dan memecahkan masalah, adalah sebuah tantangan. Selain itu, penting untuk menemukan, berolahraga, dan menggantung banyak metrik yang berbeda.
Pengumpulan data dilakukan dari semua sistem utama - 1C, SAP, dan banyak lainnya. Berdasarkan data yang dikumpulkan di sini, semua analitik, semua prediksi, semua pelaporan digital akan dibangun.
Singkatnya, kami ingin membuat data bekerja sangat keren. Misalnya, pemasaran dan penjualan - mereka memiliki orang yang mengumpulkan semua statistik dengan tangan. Yaitu, mereka duduk dan dari 5 sistem yang berbeda memompa data yang berbeda dalam format yang berbeda, mengunduhnya dari 5 program yang berbeda, kemudian membongkar semua ini ke dalam Excel. Kemudian mereka meringkas informasi ke dalam tabel Excel terpadu, entah bagaimana mereka mencoba membuat visualisasi.
Secara umum, kereta membutuhkan waktu selama ini. Kami ingin menyelesaikan masalah tersebut dengan platform kami. Dan dalam posting berikut kami akan memberi tahu Anda secara rinci tentang bagaimana kami menghubungkan elemen bersama dan mengatur operasi sistem yang benar.
Ngomong-ngomong, selain
arsitek dan
insinyur data di tim ini, kami akan senang melihat: