Dengan penyebaran dan pengembangan jaringan saraf, ada kebutuhan yang meningkat untuk menggunakannya pada perangkat dan robot berdaya rendah dan berdaya rendah. Perangkat Neural Compute Stick bersama dengan kerangka kerja Intel OpenVINO memungkinkan kami untuk menyelesaikan masalah ini dengan mengambil perhitungan berat jaringan saraf. Berkat ini, Anda dapat dengan mudah meluncurkan pengklasifikasi jaringan saraf atau detektor pada perangkat berdaya rendah seperti Raspberry Pi dalam waktu yang hampir bersamaan, tanpa konsumsi energi yang sangat meningkat. Dalam posting ini, saya akan menunjukkan kepada Anda bagaimana menggunakan kerangka kerja OpenVINO (dalam C ++) dan Neural Compute Stick untuk meluncurkan sistem deteksi wajah sederhana pada Raspberry Pi.
Seperti biasa, semua kode tersedia di
GitHub .

Sedikit tentang Neural Compute Stick dan OpenVINO
Pada musim panas 2017, Intel merilis perangkat
Neural Compute Stick (NCS), yang dirancang untuk menjalankan jaringan saraf pada perangkat berdaya rendah, dan setelah beberapa bulan dapat dibeli dan diuji, yang saya lakukan. NCS adalah modul komputasi kecil dengan casing warna biru (juga bertindak sebagai radiator), yang terhubung ke perangkat utama melalui USB. Di dalam, antara lain, adalah Intel Myriad
VPU , yang pada dasarnya adalah prosesor paralel 12-core, dipertajam untuk operasi yang sering terjadi dalam jaringan saraf. NCS tidak cocok untuk pelatihan jaringan saraf, tetapi kesimpulan dalam jaringan saraf yang sudah terlatih sebanding dengan kecepatan pada GPU. Semua perhitungan dalam NCS dilakukan pada angka float 16-bit, yang memungkinkan Anda untuk meningkatkan kecepatan. NCS hanya membutuhkan daya 1 Watt untuk beroperasi, yaitu, pada 5 V, arus hingga 200 mA dikonsumsi pada konektor USB - ini bahkan kurang dari kamera untuk Raspberry Pi (250 mA).

Untuk bekerja dengan NCS pertama,
Neural Compute SDK (NCSDK) digunakan: termasuk alat untuk menyusun jaringan saraf dalam format
Caffe dan
TensorFlow ke format NCS, alat untuk mengukur kinerja mereka, serta API Python dan C ++ untuk inferensi.
Kemudian versi baru kerangka kerja NCS dirilis:
NCSDK2 . API telah banyak berubah di dalamnya, dan meskipun beberapa perubahan tampak aneh bagi saya, ada beberapa inovasi yang bermanfaat. Secara khusus, konversi otomatis dari float 32 bit ke float 16 bit ke C ++ ditambahkan (sebelumnya, kruk harus dimasukkan dalam bentuk kode dari Numpy). Juga muncul antrian gambar dan hasil pemrosesan mereka.
Pada Mei 2018, Intel merilis
OpenVINO (sebelumnya disebut Intel Computer Vision SDK). Kerangka kerja ini dirancang untuk secara efisien meluncurkan jaringan saraf pada berbagai perangkat: prosesor Intel dan kartu grafis,
FPGA , serta Neural Compute Stick.
Pada November 2018, versi baru akselerator dirilis:
Neural Compute Stick 2 . Kekuatan komputasi perangkat telah meningkat: dalam deskripsi di situs mereka menjanjikan akselerasi hingga 8x, namun, saya tidak dapat menguji versi perangkat yang baru. Akselerasi dicapai dengan meningkatkan jumlah core dari 12 menjadi 16, serta menambahkan perangkat komputasi baru yang dioptimalkan untuk jaringan saraf. Benar, saya tidak menemukan informasi tentang konsumsi daya informasi.
Versi kedua NCS sudah tidak kompatibel dengan NCSDK atau NCSDK2: OpenVINO, yang mampu bekerja dengan banyak perangkat lain selain kedua versi NCS, melewati otoritas mereka. OpenVINO sendiri memiliki fungsionalitas hebat dan mencakup komponen-komponen berikut:
- Pengoptimal Model: Skrip Python yang memungkinkan Anda untuk mengubah jaringan saraf dari kerangka pembelajaran mendalam populer ke dalam format OpenVINO universal. Daftar kerangka kerja yang didukung: Caffe , TensorFlow , MXNET , Kaldi (kerangka pengenalan suara), ONNX (format terbuka untuk mewakili jaringan saraf).
- Mesin Inferensi: C ++ dan Python API untuk inferensi jaringan saraf, disarikan dari perangkat inferensi tertentu. Kode API akan terlihat hampir identik untuk CPU, GPU, FPGA dan NCS.
- Satu set plugin untuk perangkat yang berbeda. Plugin adalah perpustakaan dinamis yang dimuat secara eksplisit dalam kode program utama. Kami paling tertarik dengan plugin untuk NCS.
- Serangkaian model pra-terlatih dalam format OpenVINO universal (daftar lengkapnya ada di sini ). Kumpulan jaringan saraf berkualitas tinggi yang mengesankan: detektor wajah, pejalan kaki, objek; pengakuan akan orientasi wajah, titik wajah khusus, postur manusia; resolusi super; dan lainnya. Perlu dicatat bahwa tidak semuanya didukung oleh NCS / FPGA / GPU.
- Pengunduh Model: skrip lain yang menyederhanakan pengunduhan model dalam format OpenVINO melalui jaringan (meskipun Anda dapat dengan mudah melakukannya tanpa itu).
- Pustaka visi komputer OpenCV dioptimalkan untuk perangkat keras Intel.
- Perpustakaan visi komputer OpenVX .
- Intel Compute Library untuk Deep Neural Networks .
- Perpustakaan Intel Math Kernel untuk Deep Neural Networks .
- Alat untuk mengoptimalkan jaringan saraf untuk FPGA (opsional).
- Program dokumentasi dan sampel.
Dalam artikel saya sebelumnya, saya berbicara tentang cara menjalankan detektor wajah YOLO pada NCS
(artikel pertama) , serta cara melatih detektor wajah SSD Anda dan menjalankannya pada Raspberry Pi dan NCS
(artikel kedua) . Dalam artikel ini, saya menggunakan NCSDK dan NCSDK2. Pada artikel ini saya akan memberi tahu Anda bagaimana melakukan sesuatu yang serupa, tetapi menggunakan OpenVINO, saya akan membuat perbandingan kecil dari kedua pendeteksi wajah dan dua kerangka kerja untuk meluncurkannya, dan saya akan menunjukkan beberapa jebakan. Saya menulis dalam C ++, karena saya percaya bahwa dengan cara ini Anda dapat mencapai kinerja yang lebih baik, yang akan menjadi penting dalam kasus Raspberry Pi.
Instal OpenVINO
Bukan tugas yang paling sulit, meskipun ada kehalusan. Pada saat penulisan, OpenVINO hanya mendukung Ubuntu 16.04 LTS, CentOS 7.4, dan Windows 10. Saya telah menginstal Ubuntu 18 dan memerlukan
kruk kecil untuk menginstalnya. Saya juga ingin membandingkan OpenVINO dengan NCSDK2, instalasi yang juga memiliki masalah: khususnya, memperketat versi Caffe dan TensorFlow dan sedikit dapat merusak pengaturan lingkungan. Pada akhirnya, saya memutuskan untuk mengikuti jalur sederhana dan menginstal kedua kerangka kerja ke mesin virtual dengan Ubuntu 16 (saya menggunakan
VirtualBox ).
Perlu dicatat bahwa agar berhasil menghubungkan NCS ke mesin virtual, Anda perlu menginstal add-on guest VirtualBox dan mengaktifkan dukungan USB 3.0. Saya juga menambahkan filter universal untuk perangkat USB, akibatnya NCS terhubung tanpa masalah (meskipun webcam masih harus terhubung dalam pengaturan mesin virtual). Untuk menginstal dan mengkompilasi OpenVINO Anda harus memiliki akun Intel, pilih opsi kerangka kerja (dengan atau tanpa dukungan FPGA) dan ikuti
instruksi . NCSDK bahkan lebih sederhana: mem-boot
dari GitHub (jangan lupa untuk memilih cabang ncsdk2 untuk versi baru framework), setelah itu Anda perlu
make install .
Satu-satunya masalah yang saya temui saat menjalankan NCSDK2 di mesin virtual adalah kesalahan dari bentuk berikut:
E: [ 0] dispatcherEventReceive:236 dispatcherEventReceive() Read failed -1 E: [ 0] eventReader:254 Failed to receive event, the device may have reset
Itu terjadi pada akhir pelaksanaan program yang benar dan (tampaknya) tidak mempengaruhi apa pun. Rupanya, ini adalah
bug kecil yang terkait dengan VM (ini tidak boleh di Raspberry).
Instalasi pada Raspberry Pi sangat berbeda. Pertama, pastikan Anda telah menginstal Raspbian Stretch: kedua kerangka kerja hanya berfungsi pada OS ini. NCSDK2 perlu
dikompilasi dalam mode API-only , jika tidak maka akan mencoba untuk menginstal Caffe dan TensorFlow, yang sepertinya tidak akan menyenangkan Raspberry Anda. Dalam hal OpenVINO, ada versi yang sudah
dirakit untuk Raspberry , yang Anda hanya perlu membongkar dan mengonfigurasi variabel lingkungan. Dalam versi ini hanya ada C ++ dan Python API, serta pustaka OpenCV, semua alat lain tidak tersedia. Ini berarti bahwa untuk kedua kerangka kerja, model harus dikonversi terlebih dahulu pada mesin dengan Ubuntu.
Demo deteksi wajah saya berfungsi pada Raspberry dan desktop, jadi saya baru saja menambahkan file jaringan saraf yang dikonversi ke repositori GitHub saya untuk membuatnya lebih mudah untuk disinkronkan dengan Raspberry. Saya memiliki Raspberry Pi 2 model B, tetapi harus lepas landas dengan model lain.
Ada kehalusan lain mengenai interaksi Raspberry Pi dan Neural Compute Stick: jika dalam kasus laptop, cukup dengan memasukkan NCS ke port USB 3.0 terdekat, maka untuk Raspberry Anda harus menemukan kabel USB, jika tidak NSC akan memblokir tiga konektor USB yang tersisa dengan tubuhnya. Perlu juga diingat bahwa Raspberry memiliki semua versi USB 2.0, sehingga tingkat inferensi akan lebih rendah karena keterlambatan komunikasi (perbandingan detail akan dilakukan nanti). Tetapi jika Anda ingin menghubungkan dua atau lebih NCS ke Raspberry, kemungkinan besar Anda harus mencari hub USB dengan daya tambahan.
Seperti apa bentuk kode OpenVINO
Cukup besar. Ada banyak tindakan berbeda yang harus dilakukan, mulai dengan memuat plug-in dan diakhiri dengan inferensi itu sendiri - itu sebabnya saya menulis kelas pembungkus untuk detektor. Kode lengkap dapat dilihat di GitHub, tetapi di sini saya hanya mendaftar poin utama. Mari kita mulai dengan urutan:
Definisi semua fungsi yang kita butuhkan ada di file
inference_engine.hpp di namespace
InferenceEngine .
#include <inference_engine.hpp> using namespace InferenceEngine;
Variabel berikut akan dibutuhkan setiap saat. kita membutuhkan
inputName dan
outputName untuk mengatasi input dan output dari jaringan saraf. Secara umum, jaringan saraf dapat memiliki banyak input dan output, tetapi dalam detektor kami akan ada satu per satu.
net variabel adalah jaringan itu sendiri,
request adalah pointer ke permintaan inferensi terakhir,
inputBlob adalah pointer ke array data input dari jaringan saraf. Variabel yang tersisa berbicara sendiri.
string inputName; string outputName; ExecutableNetwork net; InferRequest::Ptr request; Blob::Ptr inputBlob;
Sekarang unduh plugin yang diperlukan - kita membutuhkan plugin yang bertanggung jawab untuk NCS dan NCS2, ini dapat diperoleh dengan nama "MYRIAD". Biarkan saya mengingatkan Anda bahwa dalam konteks OpenVINO, sebuah plugin hanyalah pustaka dinamis yang terhubung dengan permintaan eksplisit. Parameter fungsi
PluginDispatcher adalah daftar direktori tempat mencari plugin. Jika Anda mengatur variabel lingkungan sesuai dengan instruksi, baris kosong akan cukup. Sebagai referensi, plugin terletak di
[OpenVINO_install_dir]/deployment_tools/inference_engine/lib/ubuntu_16.04/intel64/ InferencePlugin plugin = PluginDispatcher({""}).getPluginByDevice("MYRIAD");
Sekarang buat objek untuk memuat jaringan saraf, pertimbangkan deskripsinya dan atur ukuran bets (jumlah gambar yang diproses secara bersamaan). Jaringan saraf dalam format OpenVINO didefinisikan oleh dua file: .xml dengan deskripsi struktur dan .bin dengan bobot. Sementara kita akan menggunakan detektor yang sudah jadi dari OpenVINO, nanti kita akan membuatnya sendiri. Di sini
std::string filename adalah nama file tanpa ekstensi. Anda juga perlu diingat bahwa NCS hanya mendukung ukuran batch 1.
CNNNetReader netReader; netReader.ReadNetwork(filename+".xml"); netReader.ReadWeights(filename+".bin"); netReader.getNetwork().setBatchSize(1);
Kemudian terjadi hal berikut:
- Untuk memasuki jaringan saraf, atur tipe data ke unsigned char 8 bit. Ini berarti bahwa kita dapat memasukkan gambar dalam format yang berasal dari kamera, dan InferenceEngine akan menangani konversi (NCS melakukan perhitungan dalam format float 16 bit). Ini akan mempercepat sedikit pada Raspberry Pi - seperti yang saya mengerti, konversi dilakukan pada NCS, sehingga ada sedikit penundaan dalam mentransfer data melalui USB.
- Kami mendapatkan nama input dan output, sehingga nanti kami bisa mengaksesnya.
- Kami mendapatkan deskripsi output (ini adalah peta dari nama output ke pointer ke blok data). Kami mendapatkan pointer ke blok data dari output (tunggal) pertama.
- Kami mendapatkan ukurannya: 1 x 1 x jumlah maksimum deteksi x panjang deskripsi deteksi (7). Tentang format deskripsi deteksi - nanti.
- Atur format output ke float 32 bit. Sekali lagi, konversi dari float 16 bit menangani InferenceEngine.
Sekarang poin yang paling penting: kita memuat jaringan saraf ke dalam plugin (yaitu, di NCS). Rupanya, mengkompilasi ke format yang diinginkan adalah on the fly. Jika program macet pada fungsi ini, jaringan saraf mungkin tidak cocok untuk perangkat ini.
net = plugin.LoadNetwork(netReader.getNetwork(), {});
Dan akhirnya - kita akan membuat inferensi percobaan dan mendapatkan ukuran input (mungkin ini bisa dilakukan dengan lebih elegan). Pertama, kami membuka permintaan untuk inferensi, lalu dari sana kami mendapatkan tautan ke blok data input, dan kami sudah meminta ukuran dari itu.
Mari kita coba unggah gambar ke NCS. Dengan cara yang sama, kita membuat permintaan untuk inferensi, mendapatkan pointer ke blok data darinya, dan dari sana kita mendapatkan pointer ke array itu sendiri. Selanjutnya, cukup salin data dari gambar kami (ini sudah dikurangi ke ukuran yang diinginkan). Perlu dicatat bahwa dalam
cv::Mat dan
inputBlob pengukuran disimpan dalam urutan yang berbeda (di OpenCV, indeks saluran berubah lebih cepat dari semua, di OpenVINO lebih lambat dari semua), sehingga memcpy sangat diperlukan. Kemudian kita mulai inferensi asinkron.
Mengapa tidak sinkron? Ini akan mengoptimalkan alokasi sumber daya. Sementara NCS mempertimbangkan jaringan saraf, Anda dapat memproses frame berikutnya - ini akan mengarah pada akselerasi yang terlihat pada Raspberry Pi.
cv::Mat data; ...
Jika Anda terbiasa dengan jaringan saraf, Anda mungkin memiliki pertanyaan tentang pada titik mana kami skala nilai-nilai piksel input dari jaringan saraf (misalnya, kami membawa ke kisaran
[ 0 , 1 ] ) Faktanya adalah bahwa dalam model OpenVINO transformasi ini sudah termasuk dalam deskripsi jaringan saraf, dan ketika menggunakan detektor kami, kami akan melakukan sesuatu yang serupa. Dan karena konversi ke float dan penskalaan input dilakukan oleh OpenVINO, kita hanya perlu mengubah ukuran gambar.
Sekarang (setelah melakukan beberapa pekerjaan yang bermanfaat) kami akan menyelesaikan permintaan inferensi. Program diblokir hingga hasil eksekusi datang. Kami mendapatkan pointer ke hasilnya.
float * output; ncsCode = request->Wait(IInferRequest::WaitMode::RESULT_READY); output = request->GetBlob(outputName)->buffer().as<float*>();
Sekarang saatnya untuk memikirkan dalam format apa NCS mengembalikan hasil detektor. Perlu dicatat bahwa formatnya sedikit berbeda dari apa ketika menggunakan NCSDK. Secara umum, output detektor adalah empat dimensi dan memiliki dimensi (1 x 1 x jumlah maksimum deteksi x 7), kita dapat mengasumsikan bahwa ini adalah array ukuran (
maxNumDetectedFaces x 7).
Parameter
maxNumDetectedFaces diatur dalam deskripsi jaringan saraf, dan mudah untuk mengubahnya, misalnya, dalam deskripsi .prototxt dari jaringan dalam format Caffe. Sebelumnya kami mendapatkannya dari objek yang mewakili detektor. Parameter ini terkait dengan spesifikasi kelas detektor
SSD (Detektor Tembakan Tunggal) , yang mencakup semua detektor NCS yang didukung. SSD selalu mempertimbangkan jumlah kotak pembatas yang sama (dan sangat besar) untuk setiap gambar, dan setelah memfilter deteksi dengan tingkat kepercayaan rendah dan menghapus frame yang tumpang tindih menggunakan Penindasan Non-maksimum, mereka biasanya memberikan yang terbaik 100-200. Inilah tepatnya parameter yang bertanggung jawab.
Tujuh nilai dalam deskripsi satu deteksi adalah sebagai berikut:
- nomor gambar dalam kumpulan tempat objek terdeteksi (dalam kasus kami, harus nol);
- kelas objek (0 - latar belakang, mulai dari 1 - kelas lain, hanya deteksi dengan kelas positif yang dikembalikan);
- kepercayaan akan adanya deteksi (dalam jangkauan [ 0 , 1 ] );
- koordinat x dinormalisasi dari sudut kiri atas kotak pembatas (dalam kisaran [ 0 , 1 ] );
- sama - koordinat-y;
- lebar kotak pembatas dinormalisasi (dalam kisaran [ 0 , 1 ] );
- juga - tinggi;
Kode untuk mengekstrak kotak pembatas dari keluaran detektor void get_detection_boxes(const float* predictions, int numPred, int w, int h, float thresh, std::vector<float>& probs, std::vector<cv::Rect>& boxes) { float score = 0; float cls = 0; float id = 0;
kita belajar
numPred dari detektor itu sendiri, dan
w,h - ukuran gambar untuk visualisasi.
Sekarang tentang bagaimana skema umum inferensi terlihat secara real time. Pertama kita menginisialisasi jaringan saraf dan kamera, mulai
cv::Mat untuk frame mentah dan satu lagi untuk frame dikurangi menjadi ukuran yang diinginkan. Kami mengisi frame kami dengan nol - ini akan menambah keyakinan bahwa pada satu awal jaringan saraf tidak akan menemukan apa pun. Kemudian kita memulai siklus inferensi:
- Kami memuat frame saat ini ke jaringan saraf menggunakan permintaan asinkron - NCS sudah mulai bekerja, dan saat ini kami memiliki kesempatan untuk menjadikan pekerjaan yang bermanfaat sebagai prosesor utama.
- Kami menampilkan semua deteksi sebelumnya pada bingkai sebelumnya, menggambar sebuah bingkai (jika perlu).
- Kami mendapatkan bingkai baru dari kamera, kompres ke ukuran yang diinginkan. Untuk Raspberry, saya sarankan menggunakan algoritma pengubahan ukuran paling sederhana - di OpenCV, ini adalah interpolasi tetangga terdekat. Ini tidak akan memengaruhi kualitas kinerja detektor, tetapi dapat menambah sedikit kecepatan. Saya juga cermin bingkai untuk visualisasi yang mudah (opsional).
- Sekarang saatnya untuk mendapatkan hasil dengan NCS dengan menyelesaikan permintaan inferensi. Program akan diblokir sampai hasilnya diterima.
- Kami memproses deteksi baru, pilih bingkai.
- Sisanya: bekerja dengan penekanan tombol, menghitung frame, dll.
Cara mengompilasinya
Dalam contoh InferenceEngine, saya tidak suka file CMake yang besar, dan saya memutuskan untuk menulis ulang semuanya dengan ringkas ke dalam Makefile saya:
g++ $(RPI_ARCH) \ -I/usr/include -I. \ -I$(OPENVINO_PATH)/deployment_tools/inference_engine/include \ -I$(OPENVINO_PATH_RPI)/deployment_tools/inference_engine/include \ -L/usr/lib/x86_64-linux-gnu \ -L/usr/local/lib \ -L$(OPENVINO_PATH)/deployment_tools/inference_engine/lib/ubuntu_16.04/intel64 \ -L$(OPENVINO_PATH_RPI)/deployment_tools/inference_engine/lib/raspbian_9/armv7l \ vino.cpp wrapper/vino_wrapper.cpp \ -o demo -std=c++11 \ `pkg-config opencv --cflags --libs` \ -ldl -linference_engine $(RPI_LIBS)
Tim ini akan bekerja pada Ubuntu dan Raspbian, berkat beberapa trik. Jalur untuk mencari header dan pustaka dinamis yang saya tunjukkan untuk Raspberry dan mesin Ubuntu. Dari perpustakaan, selain OpenCV, Anda juga harus menghubungkan
libinference_engine dan
libdl - perpustakaan untuk secara dinamis menghubungkan perpustakaan lain, diperlukan untuk membuat plugin memuat. Pada saat yang sama,
libmyriadPlugin sendiri tidak perlu ditentukan. Antara lain, untuk Raspberry I juga menghubungkan perpustakaan
Raspicam untuk bekerja dengan kamera (ini adalah
$(RPI_LIBS) ). Saya juga harus menggunakan standar C ++ 11.
Secara terpisah, perlu dicatat bahwa ketika mengkompilasi pada Raspberry,
-march=armv7-a diperlukan (ini adalah
$(RPI_ARCH) ). Jika Anda tidak menentukannya, program akan dikompilasi, tetapi akan macet dengan segfault diam. Anda juga dapat menambahkan optimasi menggunakan
-O3 , ini akan menambah kecepatan.
Apa detektornya?
NCS hanya mendukung pendeteksi SSD Caffe dari kotak, meskipun dengan beberapa trik kotor saya berhasil menjalankan
YOLO dari format Darknet di atasnya.
Single Shot Detector (SSD) adalah arsitektur populer di antara jaringan saraf ringan, dan dengan bantuan enkoder yang berbeda (atau jaringan backbone) Anda dapat secara fleksibel memvariasikan rasio kecepatan dan kualitas.
Saya akan bereksperimen dengan berbagai pendeteksi wajah:
- YOLO, diambil dari sini , dikonversi terlebih dahulu ke format Caffe, kemudian ke format NCS (hanya dengan NCSDK). Gambar 448 x 448.
- Detektor Mobilenet + SSD saya, tentang pelatihan yang saya bicarakan dalam publikasi sebelumnya . Saya masih memiliki versi terpangkas dari detektor ini, yang hanya melihat wajah-wajah kecil, dan pada saat yang sama sedikit lebih cepat. Saya akan memeriksa versi lengkap detektor saya di NCSDK dan OpenVINO. Gambar 300 x 300.
- Detektor deteksi wajah-adas-0001 dari OpenVINO: MobileNet + SSD. Gambar 384 x 672.
- OpenVINO face-detection-retail-0004 detector: ringan SqueezeNet + SSD. Gambar 300 x 300.
Untuk detektor dari OpenVINO, tidak ada skala dalam format Caffe atau format NCSDK, jadi saya hanya bisa meluncurkannya di OpenVINO.
Ubah detektor Anda menjadi format OpenVINO
Saya memiliki dua file dalam format Caffe: .prototxt dengan deskripsi jaringan dan .caffemodel dengan bobot. Saya perlu mendapatkan dua file dari mereka dalam format OpenVINO: .xml dan .bin masing-masing dengan deskripsi dan bobot. Untuk melakukan ini, gunakan skrip mo.py dari OpenVINO (alias Pengoptimal Model):
mo.py \ --framework caffe \ --input_proto models/face/ssd-face.prototxt \ --input_model models/face/ssd-face.caffemodel \ --output_dir models/face \ --model_name ssd-vino-custom \ --mean_values [127.5,127.5,127.5] \ --scale_values [127.5,127.5,127.5] \ --data_type FP16
output_dir menentukan direktori di mana file baru akan dibuat,
model_name adalah nama untuk file baru tanpa ekstensi,
data_type (FP16/FP32) adalah jenis keseimbangan dalam jaringan saraf (NCS hanya mendukung FP16).
mean_values, scale_values menetapkan rata-rata dan skala untuk memproses ulang gambar sebelum diluncurkan ke jaringan saraf. Konversi spesifik terlihat seperti ini:
(pixel values−mean values)/skala values
Dalam hal ini, nilainya dikonversi dari kisaran
[0,255] dalam jangkauan
[0,1] . Secara umum, skrip ini memiliki banyak parameter, beberapa di antaranya khusus untuk kerangka kerja individual, saya sarankan Anda melihat manual untuk skrip.
Distribusi OpenVINO untuk Raspberry tidak memiliki model yang sudah jadi, tetapi cukup mudah untuk diunduh.
Misalnya, seperti ini. wget --no-check-certificate \ https://download.01.org/openvinotoolkit/2018_R4/open_model_zoo/face-detection-retail-0004/FP16/face-detection-retail-0004.xml \ -O ./models/face/vino.xml; \ wget --no-check-certificate \ https://download.01.org/openvinotoolkit/2018_R4/open_model_zoo/face-detection-retail-0004/FP16/face-detection-retail-0004.bin \ -O ./models/face/vino.bin
Perbandingan detektor dan kerangka kerja
Saya menggunakan tiga opsi perbandingan: 1) Mesin NCS + Virtual dengan Ubuntu 16.04, prosesor Core i7, konektor USB 3.0; 2) NCS + Mesin yang sama, konektor USB 3.0 + kabel USB 2.0 (akan ada lebih banyak penundaan dalam pertukaran dengan perangkat); 3) NCS + Raspberry Pi 2 model B, Raspbian Stretch, konektor USB 2.0 + kabel USB 2.0.
Saya memulai detektor saya dengan OpenVINO dan NCSDK2, detektor dari OpenVINO hanya dengan framework asli mereka, YOLO hanya dengan NCSDK2 (kemungkinan besar, itu juga dapat dijalankan pada OpenVINO).
Tabel FPS untuk detektor yang berbeda terlihat seperti ini (angka perkiraan):
| Model | USB 3.0 | USB 2.0 | Raspberry pi |
|---|
| SSD khusus dengan NCSDK2 | 10.8 | 9.3 | 7.2 |
| SSD longrange khusus dengan NCSDK2 | 11.8 | 10.0 | 7.3 |
| YOLO v2 dengan NCSDK2 | 5.3 | 4.6 | 3.6 |
| SSD khusus dengan OpenVINO | 10.6 | 9.9 | 7.9 |
| OpenVINO deteksi wajah-ritel-0004 | 15.6 | 14.2 | 9.3 |
| OpenVINO face-detection-adas-0001 | 5.8 | 5.5 | 3.9 |
Catatan: kinerja diukur untuk seluruh program demo, termasuk pemrosesan dan visualisasi bingkai.YOLO adalah yang paling lambat dan paling tidak stabil dari semua. Ini sangat sering melewati deteksi dan tidak dapat bekerja dengan bingkai yang menyala.
Detektor yang saya latih bekerja dua kali lebih cepat, lebih tahan terhadap distorsi dalam bingkai, dan bahkan mendeteksi wajah kecil. Namun, kadang-kadang masih melewatkan deteksi dan kadang-kadang mendeteksi yang salah. Jika Anda memotong beberapa lapisan terakhir dari itu, itu akan menjadi sedikit lebih cepat, tetapi itu akan berhenti melihat wajah besar. Detektor yang sama yang diluncurkan melalui OpenVINO menjadi sedikit lebih cepat ketika menggunakan USB 2.0, kualitasnya tidak berubah secara visual.
Detektor OpenVINO, tentu saja, jauh lebih unggul daripada YOLO dan detektor saya. (Saya bahkan tidak akan mulai melatih detektor saya jika OpenVINO ada dalam bentuk saat ini pada waktu itu). Model retail-0004 secara signifikan lebih cepat dan pada saat yang sama secara praktis tidak ketinggalan, tetapi saya sedikit berhasil mengelabuinya (walaupun kepercayaan terhadap deteksi ini rendah):
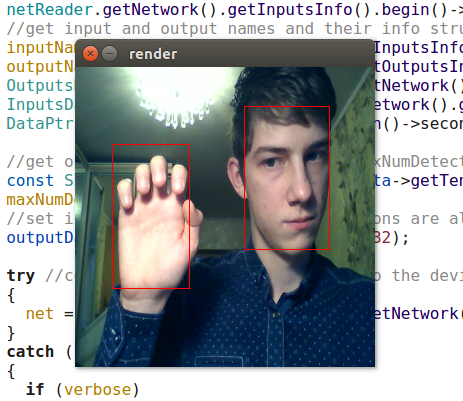 Serangan kompetitif kecerdasan alami pada buatan
Serangan kompetitif kecerdasan alami pada buatanDetektor adas-0001 jauh lebih lambat, tetapi berfungsi dengan gambar besar dan harus lebih akurat. Saya tidak melihat perbedaannya, tetapi saya memeriksa frame yang cukup sederhana.
Kesimpulan
Secara umum, sangat bagus bahwa pada perangkat berdaya rendah seperti Raspberry Pi Anda dapat menggunakan jaringan saraf, dan bahkan dalam waktu yang hampir nyata. OpenVINO menyediakan fungsionalitas yang sangat luas untuk inferensi jaringan saraf pada banyak perangkat yang berbeda - jauh lebih luas daripada yang saya jelaskan dalam artikel ini.
Saya pikir Neural Compute Stick dan OpenVINO akan sangat berguna dalam penelitian robot saya.