Orang-orang tua, mungkin, bahkan tidak akan mengingatnya, tetapi pada akhir tahun 2017 dalam diskusi di Internet gagasan beredar bahwa tren YouTube sering menampilkan video "ditutup-tutupi".
Oleh karena itu, pada malam tahun baru 2018, saya menulis sebuah utilitas untuk mengumpulkan informasi tentang video yang masuk ke tren. Untuk setiap video, nama, daftar tag, tanggal pembuatan diminta, dan riwayat perubahan dalam pernis / tidak suka / tampilan juga disimpan. Pengembangan dilakukan pada TypeScript untuk NodeJS, kode itu sendiri diposting di GitHub .
Hasilnya, sekarang ada peluang untuk membangun grafik yang indah:
Ada juga peluang untuk membuat grafik perubahan tren dengan kata kunci. Secara total, untuk tahun 2018, informasi dikumpulkan pada 29.271 video. Statistik sedang dikumpulkan sekarang.
Prinsip kerja umum
- Setiap 5 menit sekali, daftar tren saat ini diambil.
- Untuk setiap video baru, informasi dasar disimpan (judul, daftar tag, tanggal pembuatan)
- Berdasarkan judul dan tag, setiap video dipetakan ke cloud kata kunci.
- Menurut jadwal, informasi tentang suka / tidak suka / tayangan untuk setiap video diminta. Statistik dikumpulkan dalam dua hari, permintaan pertama kali dikirim pada interval 2 menit, kemudian interval meningkat. Jika ada kecurigaan kecurangan, maka intervalnya diatur lagi menjadi 2 menit.
Jika grafik perubahan dalam jumlah suka / tidak suka di salah satu bagian adalah garis lurus, maka hanya nilai pertama dan terakhir di bagian ini yang disimpan. Ini dilakukan untuk mengurangi volume basis data. Sekarang dalam tabel dengan statistik hanya ada 6908.449 catatan, pada disk tabel menempati 458 mb.
Prinsip deteksi otomatis markup
Bagi saya sendiri, saya merumuskan masalah sebagai berikut: Anda perlu menandai video yang memiliki "tangga" pada grafik perubahan suka / tidak suka. Langkah-langkah tangga ini ditentukan berdasarkan tiga pengukuran statistik yang berdekatan. Sudut antara dua garis diperhitungkan: satu garis ditarik antara pengukuran pertama dan kedua, yang kedua - antara kedua dan ketiga, serta panjang segmen. Grafik yang memiliki banyak penyimpangan kecil juga dicatat.
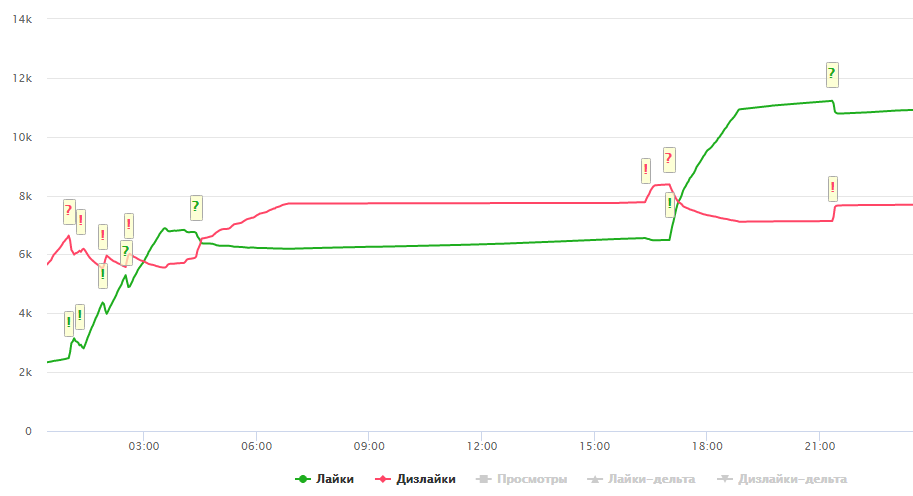
Contoh bagan yang mencurigakan:
Semua parameter algoritme ditentukan oleh saya secara manual dan diperiksa pada video yang sudah dikumpulkan pada waktu itu dan selama tahun itu perubahan dilakukan pada algoritma ini. Karena itu, memperlakukan dengan serius hasil seperti itu untuk setiap video individual mungkin tidak sepadan. Dalam pembelaan saya, saya dapat mengatakan bahwa ketika mengubah parameter, penghitungan ulang dimulai untuk semua video yang sudah dikumpulkan, oleh karena itu algoritma yang sama diterapkan pada semua video.
Secara umum, tidak mungkin untuk mengatakan apakah ada markup pada satu (atau beberapa) grafik perubahan suka / tidak suka. Perbedaan yang mencurigakan dapat dijelaskan dengan pengoperasian CQRS atau solar flare. Ya, satu grafik mulus, yang lain bertahap, tapi apakah mungkin semua video kadang-kadang menemukan perilaku seperti itu? Itulah sebabnya, untuk mengkompilasi keseluruhan gambar, informasi dikumpulkan dari semua video yang mencapai tren.
Bungkus statistik
Untuk 2018, algoritma menunjukkan hasil berikut:
Dugaan kecurangan suka: 180 video (0,32% dari total jumlah video)
Dugaan selingkuh karena tidak suka: 1303 video (4,45% dari total jumlah video)
Ada beberapa video dengan bagan kesukaan yang mencurigakan, tetapi ini tidak selalu terjadi: di bulan pertama tahun 2018, 96 video semacam itu direkam (lebih dari 50% dari semua suka yang mencurigakan di tahun itu). Namun, pada bulan Februari ada jauh lebih sedikit video seperti itu, hanya 8.
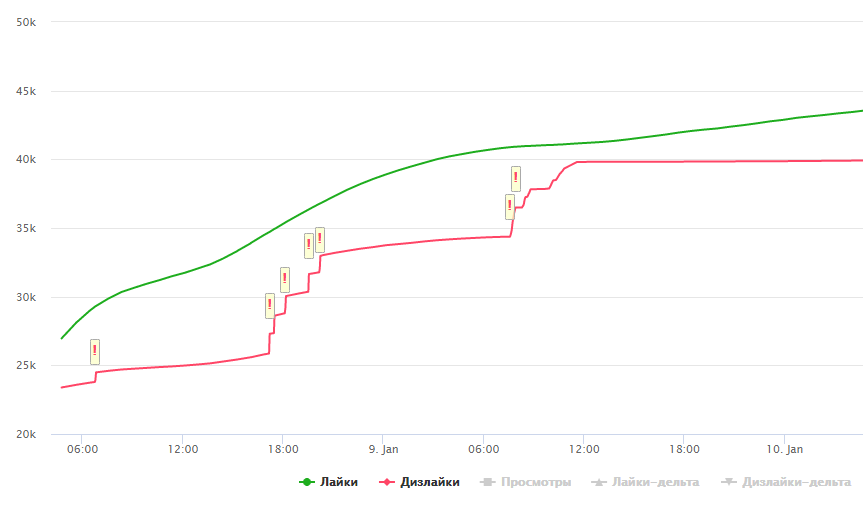
Di sini, Anda mungkin harus kembali ke orang-orang tua yang mungkin mengingat (atau tidak ingat) peristiwa yang terjadi pada 10 Januari 2018, ketika YouTube memblokir banyak saluran . Untuk bagian saya, saya dapat mengatakan bahwa di antara yang diblokir ada yang utilitas saya berhasil mengumpulkan informasi. Jadwalkan untuk salah satu video yang dihapus:

Dengan asumsi benar-benar ada kecurangan, tampaknya YouTube melakukan banyak pekerjaan dan sekarang Anda dapat menemukan video tren yang dicurigai suka tidak setiap hari (dan yang terjadi lebih sering terlihat seperti kecelakaan atau kesalahan). Di sisi lain, perbedaan markup seperti itu dapat dijelaskan oleh fakta bahwa, tidak seperti tidak suka, tidak masuk akal untuk memutar suka video yang sudah menjadi trendi.
Dan beberapa statistik lagi. Rata-rata, 21.569 suka dan 2.863 dislag mendapatkan video trending.
Dugaan kecurangan suka: 15502/4250
Kecurangan yang mencurigakan pada penampilan: 16868/22087
Dengan demikian, jika Anda melihat hasilnya, maka tidak ada gunanya untuk membangun suka, sementara sangat mungkin untuk meningkatkan persentase tidak suka.
Grafik yang mencurigakan karena tidak disukai tidak merata. Misalnya, pada saluran Yevgeny Roizman, dari 21 video yang menjadi tren, lebih dari setengahnya ditandai oleh algoritma sebagai luka oleh ketidaksukaan.
Mengenai grafik dari judul artikel ini. Jika kita berasumsi bahwa ada satu set akun dalam jumlah 5-10 ribu, yang pertama kali diberi perintah untuk tidak suka, dan kemudian tanpa menunggu akhir pekerjaan di set yang sama, mereka memberi perintah untuk menempatkan suka, maka Anda mungkin bisa mendapatkan jadwal yang sama.
Grafik teraneh yang pernah saya lihat:
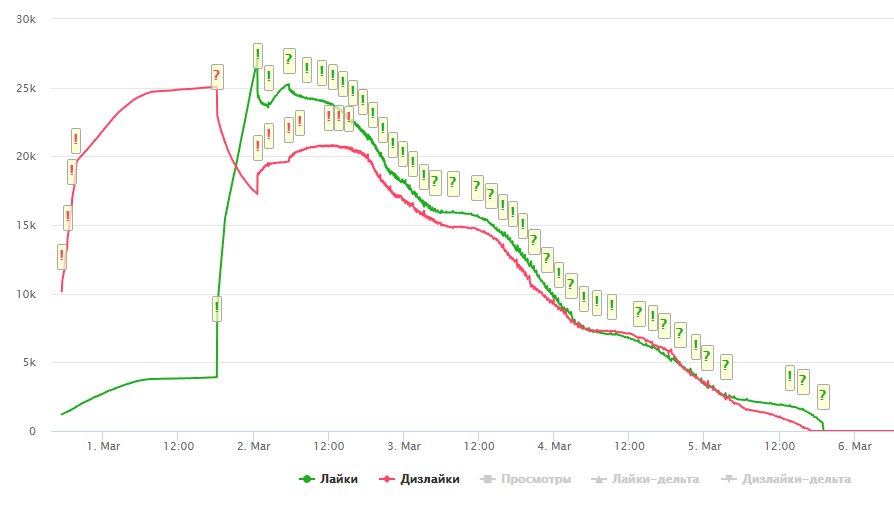
Saya akan berterima kasih jika seseorang menawarkan penjelasan tentang apa yang sedang terjadi di sini. Omong-omong, Anda dapat melihat bahwa menurut grafik ini, statistik dikumpulkan selama hampir satu minggu, bukan dua hari.
Prinsip algoritma untuk mengukur popularitas kata kunci
Seperti yang sudah dikatakan, untuk setiap video, nama dan set tag disimpan. Selanjutnya, nama dan masing-masing tag dibagi menjadi kata-kata yang terpisah, mereka dijalankan melalui stemmer dan disimpan sebagai cloud kata kunci untuk video.
Memiliki informasi tentang kapan video masuk ke tren dan ketika keluar dari tren, serta set kata untuk video, Anda dapat membuat grafik dari perubahan popularitas untuk masing-masing kata kunci. Saat ini, jadwal untuk mengubah utas kata kunci sedang dibuat setiap hari. Sebagai ukuran, total waktu (dalam jam) digunakan, di mana semua video dengan kata kunci ini dalam tren.
Contoh: dalam tren hanya ada dua video yang cocok dengan kata kunci. Satu video bertahan selama 5 jam dalam tren, yang lainnya 10 jam. Kemudian popularitas kata kunci diatur sama dengan 10 + 5 = 15.
Contoh Popularitas Kata Kunci
Menurut algoritma yang saya tulis di atas, peristiwa 2018 yang paling bergema dan paling terlihat bukanlah pemilihan atau bahkan sepak bola, tetapi tragedi di Kemerovo:
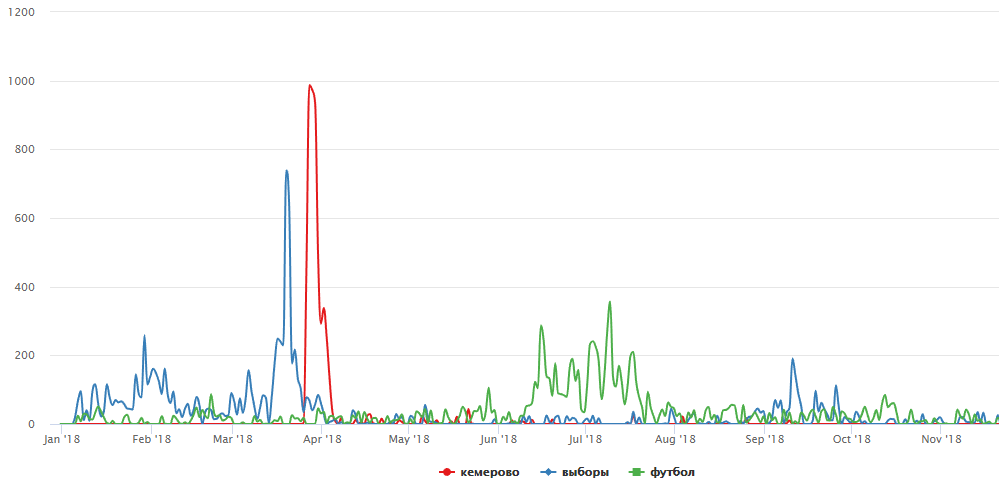
Tidak seperti semua peristiwa lainnya, tragedi Kemerovo memengaruhi semua orang, dan video tentang insiden ini membuat semua orang keluar dari tren.
Yah, sedikit politik:
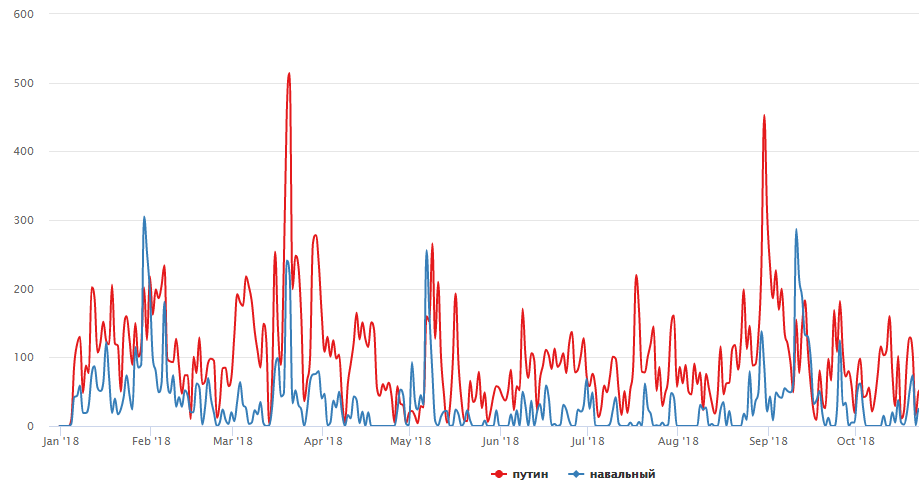
Bagaimana rasanya
Lihat grafik dan mainkan tren di sini .
Sekarang sistem berjalan di Amazon Cloud, dua contoh digunakan:
- t2.micro - server web
- t3.small adalah server dengan MySQL. Utilitas untuk mengumpulkan statistik dijalankan di server yang sama.
Mungkin, jika ada beban, server web akan jatuh terlebih dahulu, sedangkan server kedua akan terus mengumpulkan statistik. Ini saya untuk fakta bahwa tidak perlu terkejut jika semuanya berhenti berfungsi.
Basis data itu sendiri pada 01/23/2019 dapat diunduh di sini .
Juga, pada suatu waktu ia menulis dua plugin untuk chrome dan filrefox . Sekarang satu-satunya manfaat: tepat di daftar tren YouTube Anda dapat melihat jumlah suka / tidak suka untuk setiap video.