Di era kita, mesin telah berhasil mencapai akurasi 99% dalam memahami dan mendefinisikan fitur dan objek dalam gambar. Kami menjumpai ini setiap hari, misalnya: pengenalan wajah di kamera ponsel cerdas, kemampuan untuk mencari foto di google, memindai teks dari kode batang atau buku dengan kecepatan yang baik, dll. Efisiensi mesin seperti ini dimungkinkan berkat jenis jaringan saraf khusus yang disebut neural convolutional jaringan. Jika Anda seorang penggemar pembelajaran yang mendalam, Anda mungkin pernah mendengarnya, dan Anda dapat mengembangkan beberapa pengklasifikasi gambar. Kerangka pembelajaran mendalam modern seperti Tensorflow dan PyTorch menyederhanakan pembelajaran mesin gambar. Namun, pertanyaannya tetap: bagaimana data melewati lapisan jaringan saraf dan bagaimana komputer belajar darinya? Untuk mendapatkan tampilan yang jelas dari awal, kita menyelami konvolusi, memvisualisasikan gambar setiap lapisan.

Jaringan Saraf Konvolusional
Sebelum Anda mulai mempelajari jaringan saraf convolutional (SNA), Anda perlu belajar cara bekerja dengan jaringan saraf. Jaringan saraf meniru otak manusia untuk memecahkan masalah yang kompleks dan mencari pola dalam data. Selama beberapa tahun terakhir, mereka telah menggantikan banyak pembelajaran mesin dan algoritma visi komputer. Model dasar jaringan saraf terdiri dari neuron yang tersusun dalam lapisan. Setiap jaringan saraf memiliki lapisan input dan output dan beberapa lapisan tersembunyi ditambahkan kepadanya tergantung pada kompleksitas masalah. Saat mentransmisikan data melalui lapisan, neuron dilatih dan mengenali tanda-tanda. Representasi jaringan saraf ini disebut model. Setelah model dilatih, kami meminta jaringan untuk membuat perkiraan berdasarkan data uji.
SNS adalah jenis jaringan saraf khusus yang bekerja dengan baik dengan gambar. Ian Lekun mengusulkan mereka pada tahun 1998, di mana mereka mengenali nomor yang ada di gambar input. SNA juga digunakan untuk pengenalan suara, segmentasi gambar dan pemrosesan teks. Sebelum penciptaan jaringan saraf convolutional, perceptrons multilayer digunakan dalam konstruksi pengklasifikasi gambar. Klasifikasi gambar mengacu pada tugas mengekstraksi kelas dari gambar raster multichannel (warna, hitam dan putih). Multilayer perceptrons membutuhkan waktu lama untuk mencari informasi dalam gambar, karena setiap input harus dikaitkan dengan setiap neuron di lapisan berikutnya. SNA berkeliling mereka menggunakan konsep yang disebut konektivitas lokal. Ini berarti bahwa kami akan menghubungkan setiap neuron hanya ke daerah input lokal. Ini meminimalkan jumlah parameter, yang memungkinkan berbagai bagian jaringan untuk berspesialisasi dalam atribut tingkat tinggi seperti tekstur atau pola berulang. Bingung? Mari kita bandingkan bagaimana gambar ditransmisikan melalui multi-layer perceptrons (MPs) dan jaringan saraf convolutional.
Perbandingan MP dan SNA
Jumlah total entri dalam lapisan input untuk perceptron multilayer akan menjadi 784, karena gambar input memiliki ukuran 28x28 = 784 (dataset MNIST dipertimbangkan). Jaringan harus dapat memprediksi angka dalam gambar input, yang berarti bahwa output dapat menjadi milik salah satu dari kelas berikut dalam kisaran dari 0 hingga 9. Di lapisan output, kami mengembalikan perkiraan kelas, katakanlah, jika input ini adalah gambar dengan angka "3", kemudian pada lapisan output neuron yang sesuai "3" memiliki nilai yang lebih tinggi dibandingkan dengan neuron lainnya. Sekali lagi muncul pertanyaan: "Berapa banyak lapisan tersembunyi yang kita butuhkan dan berapa banyak neuron yang harus ada di masing-masing?" Misalnya, ambil kode MP berikut:
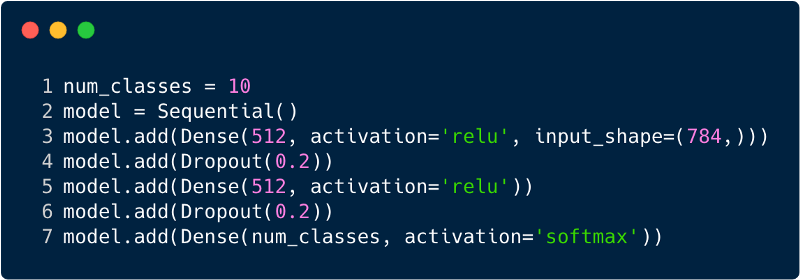
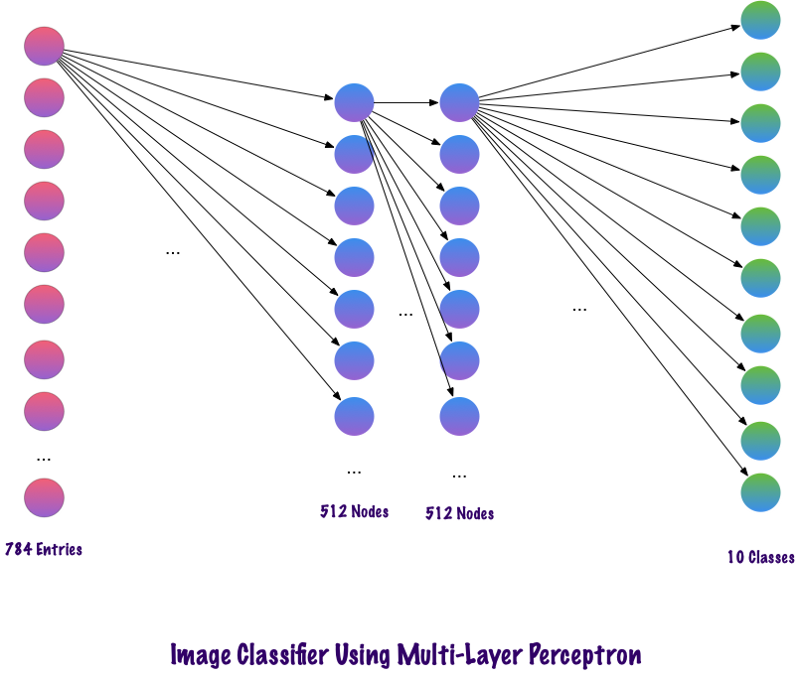
Kode di atas diimplementasikan menggunakan kerangka kerja yang disebut Keras. Lapisan tersembunyi pertama memiliki 512 neuron yang terhubung ke lapisan input 784 neuron. Lapisan tersembunyi berikutnya: lapisan pengecualian, yang memecahkan masalah pelatihan ulang. 0,2 berarti bahwa ada peluang 20% untuk tidak memperhitungkan neuron dari lapisan tersembunyi sebelumnya. Kami kembali menambahkan lapisan tersembunyi kedua dengan jumlah neuron yang sama seperti pada lapisan tersembunyi pertama (512), dan kemudian lapisan eksklusif lainnya. Akhirnya, mengakhiri set lapisan ini dengan lapisan output yang terdiri dari 10 kelas. Kelas yang paling penting adalah jumlah yang diprediksi oleh model. Ini adalah bagaimana jaringan multilayer terlihat setelah mengidentifikasi semua lapisan. Salah satu kelemahan dari multi-level perceptron adalah terhubung sepenuhnya, yang membutuhkan banyak waktu dan ruang.
Konvolt tidak menggunakan lapisan yang sepenuhnya terikat. Mereka menggunakan layer jarang, yang mengambil matriks sebagai input, yang memberikan keunggulan dibandingkan MP. Dalam MP, setiap node bertanggung jawab untuk memahami seluruh gambar. Di SNA, kami memecah gambar menjadi area (area piksel kecil lokal). Lapisan output menggabungkan data yang diterima dari setiap simpul tersembunyi untuk menemukan pola. Di bawah ini adalah gambar bagaimana lapisan terhubung.
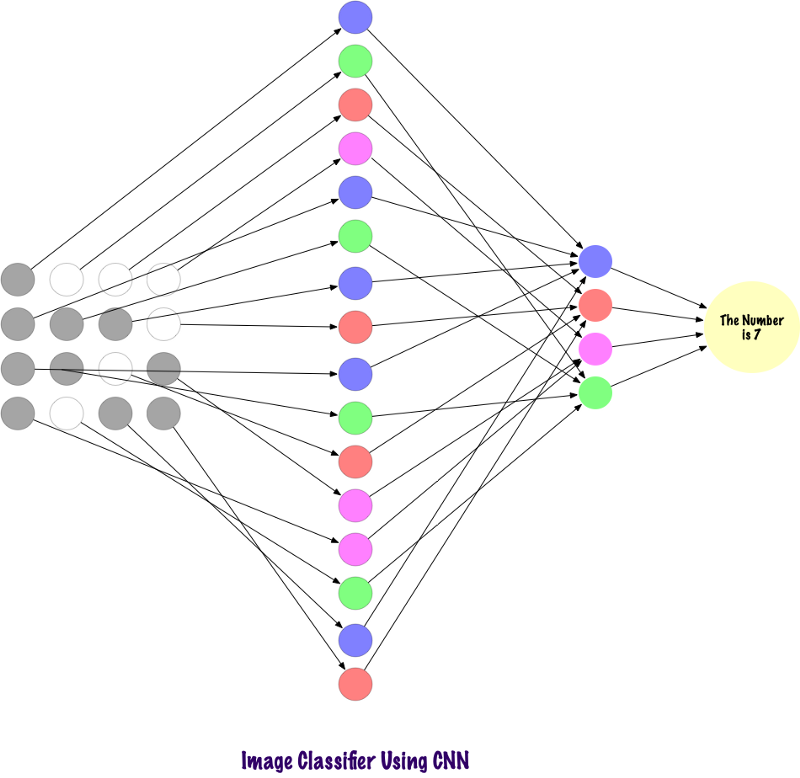
Sekarang mari kita lihat bagaimana SNA menemukan informasi dalam foto. Sebelum itu, kita perlu memahami bagaimana tanda-tanda diekstraksi. Dalam SNA, kami menggunakan lapisan yang berbeda, setiap lapisan mempertahankan tanda-tanda gambar, misalnya, memperhitungkan gambar anjing, ketika jaringan perlu mengklasifikasikan anjing, ia harus mengidentifikasi semua tanda, seperti mata, telinga, lidah, kaki, dll. Tanda-tanda ini rusak dan dikenali di tingkat jaringan lokal menggunakan filter dan inti.
Bagaimana komputer melihat gambar?
Seseorang yang melihat gambar dan memahami artinya terdengar sangat masuk akal. Katakanlah Anda berjalan, dan perhatikan banyak pemandangan di sekitar Anda. Bagaimana kita memahami alam dalam kasus ini? Kami memotret lingkungan menggunakan organ indera utama kami - mata, dan kemudian mengirimkannya ke retina. Semuanya terlihat cukup menarik, bukan? Sekarang mari kita bayangkan bahwa komputer melakukan hal yang sama. Di komputer, gambar ditafsirkan menggunakan seperangkat nilai piksel yang berkisar dari 0 hingga 255. Komputer melihat nilai-nilai piksel ini dan memahaminya. Sekilas, dia tidak tahu benda dan warna. Itu hanya mengenali nilai-nilai piksel, dan gambar itu setara dengan satu set nilai-nilai piksel untuk komputer. Kemudian, dengan menganalisis nilai-nilai piksel, ia secara bertahap mengetahui apakah gambar itu berwarna abu-abu atau berwarna. Gambar dalam skala abu-abu hanya memiliki satu saluran, karena setiap piksel mewakili intensitas satu warna. 0 berarti hitam, dan 255 berarti putih, varian hitam dan putih lainnya, yaitu abu-abu, ada di antaranya.
Gambar berwarna memiliki tiga saluran, merah, hijau dan biru. Mereka mewakili intensitas 3 warna (matriks tiga dimensi), dan ketika nilainya berubah secara bersamaan, ini memberikan satu set besar warna, benar-benar palet warna! Setelah itu, komputer mengenali kurva dan kontur objek dalam gambar. Semua ini dapat dipelajari dalam jaringan saraf convolutional. Untuk ini, kami akan menggunakan PyTorch untuk memuat dataset dan menerapkan filter ke gambar. Berikut ini adalah cuplikan kode.
Sekarang mari kita lihat bagaimana satu gambar dimasukkan ke dalam jaringan saraf.
img = np.squeeze(images[7]) fig = plt.figure(figsize = (12,12)) ax = fig.add_subplot(111) ax.imshow(img, cmap='gray') width, height = img.shape thresh = img.max()/2.5 for x in range(width): for y in range(height): val = round(img[x][y],2) if img[x][y] !=0 else 0 ax.annotate(str(val), xy=(y,x), color='white' if img[x][y]<thresh else 'black')

Ini adalah bagaimana angka "3" dipecah menjadi piksel. Dari himpunan digit tulisan tangan, "3" dipilih secara acak, di mana nilai piksel ditampilkan. Di sini ToTensor () menormalkan nilai piksel aktual (0–255) dan membatasinya hingga rentang dari 0 hingga 1. Mengapa ini? Karena memudahkan perhitungan di bagian berikutnya, baik untuk menafsirkan gambar, atau untuk menemukan pola umum yang ada di dalamnya.
Buat filter Anda sendiri
Filter, sesuai namanya, menyaring informasi. Dalam kasus jaringan saraf convolutional, ketika bekerja dengan gambar, informasi tentang piksel difilter. Kenapa kita harus memfilter sama sekali? Ingatlah bahwa komputer harus melalui proses belajar untuk memahami gambar, sangat mirip dengan cara seorang anak melakukannya. Dalam hal ini, bagaimanapun, kita tidak perlu bertahun-tahun! Singkatnya, dia belajar dari awal dan kemudian maju ke keseluruhan.
Oleh karena itu, jaringan pada awalnya harus mengetahui semua bagian kasar dari gambar, yaitu tepi, kontur, dan elemen tingkat rendah lainnya. Setelah mereka ditemukan, jalan untuk gejala yang kompleks diaspal. Untuk sampai kepada mereka, pertama-tama kita harus mengekstrak atribut tingkat rendah, lalu yang menengah, dan yang lebih tinggi. Filter adalah cara untuk mengekstrak informasi yang dibutuhkan pengguna, dan bukan hanya transfer data yang tidak jelas, karena itu komputer tidak memahami penataan gambar. Pada awalnya, fungsi tingkat rendah dapat diekstraksi berdasarkan filter tertentu. Filter di sini juga merupakan seperangkat nilai piksel, mirip dengan gambar. Ini dapat dipahami sebagai bobot yang menghubungkan lapisan-lapisan dalam jaringan saraf convolutional. Bobot atau filter ini dikalikan dengan nilai input untuk menghasilkan gambar perantara yang mewakili pemahaman komputer terhadap gambar. Kemudian mereka dikalikan dengan beberapa filter lagi untuk memperluas tampilan. Kemudian mendeteksi organ-organ yang terlihat dari seseorang (asalkan seseorang hadir dalam gambar). Belakangan, dengan dimasukkannya beberapa filter dan beberapa lapisan lagi, komputer berseru: “Oh, ya! Ini laki-laki. "
Jika kita berbicara tentang filter, maka kita memiliki banyak opsi. Anda mungkin ingin mengaburkan gambar, lalu menerapkan filter blur, jika Anda perlu menambahkan ketajaman, maka filter ketajaman akan datang untuk menyelamatkan, dll.
Mari kita lihat beberapa cuplikan kode untuk memahami fungsionalitas filter.

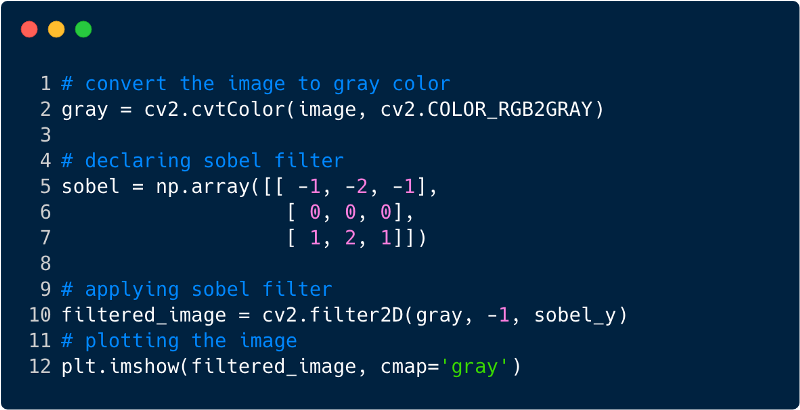

Ini adalah bagaimana gambar terlihat setelah menerapkan filter, dalam hal ini kami menggunakan filter Sobel.
Jaringan Saraf Konvolusional
Sejauh ini, kita telah melihat bagaimana filter digunakan untuk mengekstraksi fitur dari gambar. Sekarang, untuk melengkapi seluruh jaringan saraf convolutional, kita perlu tahu tentang semua lapisan yang kita gunakan untuk mendesainnya. Lapisan yang digunakan dalam SNA,
- Lapisan konvolusional
- Lapisan pooling
- Lapisan terikat sepenuhnya
Dengan ketiga lapisan, penggolong gambar konvolusional terlihat seperti ini:
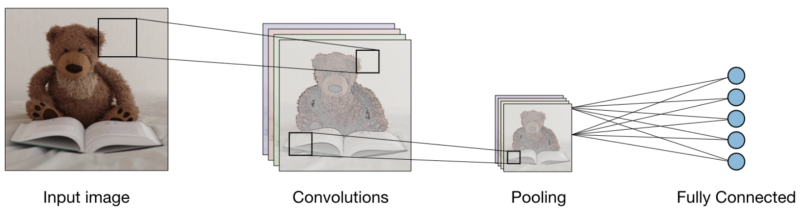
Sekarang mari kita lihat apa yang dilakukan setiap layer.
Lapisan convolutional (CONV) menggunakan filter yang melakukan operasi konvolusi dengan memindai gambar input. Hyperparameter-nya meliputi ukuran filter, yang bisa 2x2, 3x3, 4x4, 5x5 (tetapi tidak terbatas pada ini) dan langkah S. Hasilnya O disebut peta fitur atau peta aktivasi di mana semua fitur dihitung menggunakan lapisan input dan filter. Di bawah ini adalah gambar pembuatan peta fitur ketika menerapkan konvolusi,
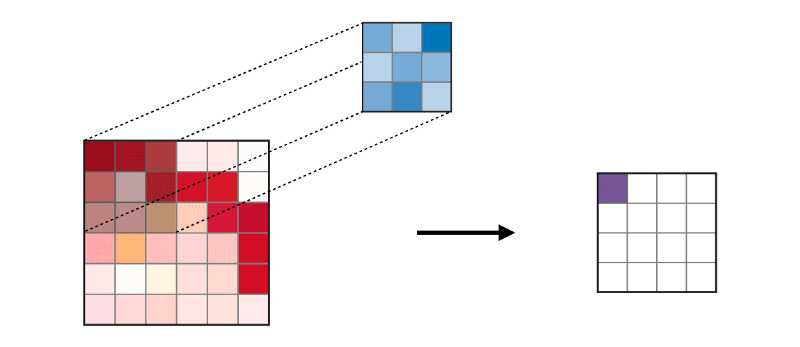 Lapisan gabungan (POOL)
Lapisan gabungan (POOL) digunakan untuk memadatkan fitur yang biasanya digunakan setelah lapisan konvolusi. Ada dua jenis operasi serikat - ini adalah serikat maksimum dan rata-rata, di mana nilai maksimum dan rata-rata dari karakteristik diambil, masing-masing. Berikut ini adalah operasi operasi gabungan,
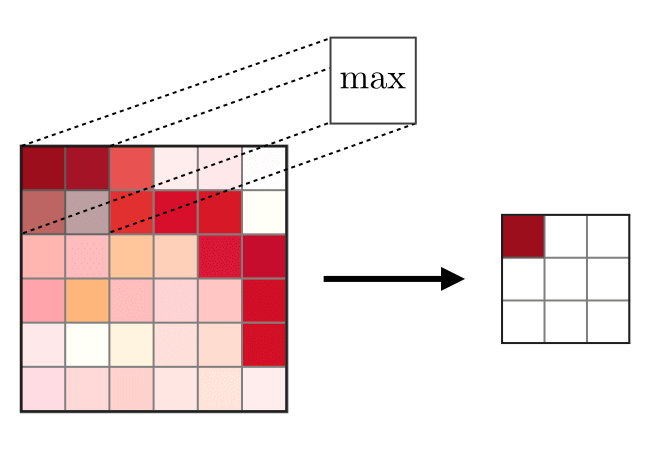
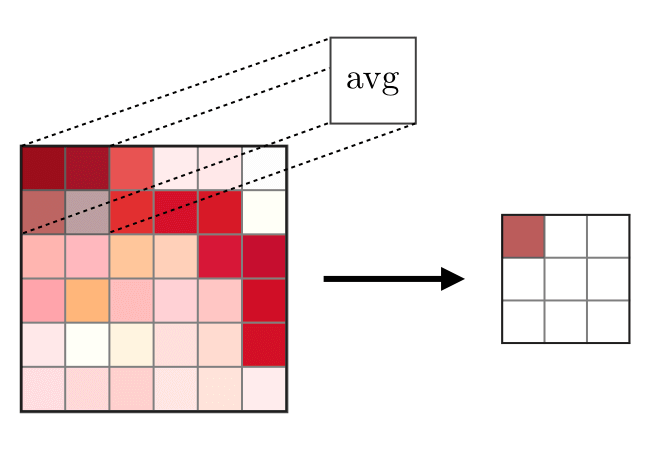 Fully terhubung lapisan (FCs)
Fully terhubung lapisan (FCs) beroperasi dengan input datar, di mana setiap input terhubung ke semua neuron. Mereka biasanya digunakan pada akhir jaringan untuk menghubungkan lapisan tersembunyi ke lapisan keluaran, yang membantu mengoptimalkan skor kelas.
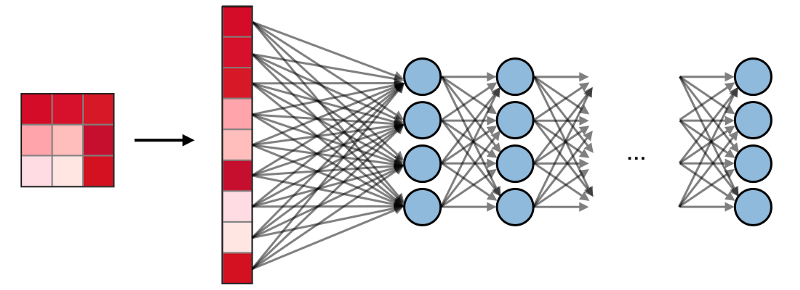
Visualisasi SNA di PyTorch
Sekarang kita memiliki ideologi lengkap untuk membangun SNA, mari kita terapkan SNA menggunakan kerangka PyTorch dari Facebook.
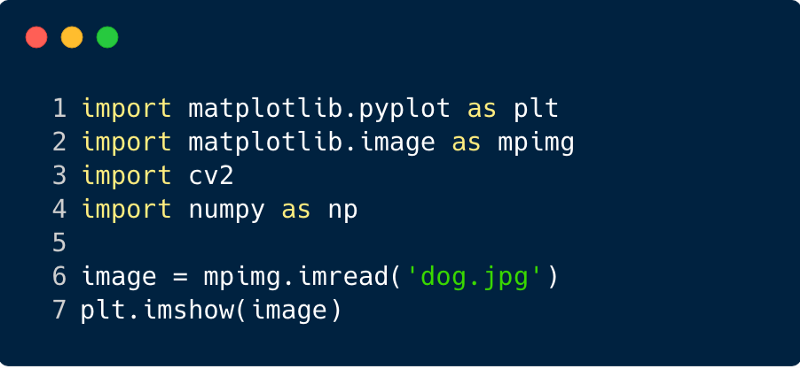
Langkah 1 : Unduh gambar input untuk dikirim melalui jaringan. (Di sini kita melakukannya dengan Numpy dan OpenCV)
import cv2 import matplotlib.pyplot as plt %matplotlib inline img_path = 'dog.jpg' bgr_img = cv2.imread(img_path) gray_img = cv2.cvtColor(bgr_img, cv2.COLOR_BGR2GRAY)
 Langkah 2
Langkah 2 : Render Filter
Mari kita visualisasikan filter untuk lebih memahami yang mana yang akan kita gunakan,
import numpy as np filter_vals = np.array([ [-1, -1, 1, 1], [-1, -1, 1, 1], [-1, -1, 1, 1], [-1, -1, 1, 1] ]) print('Filter shape: ', filter_vals.shape)
 Langkah 3
Langkah 3 : Tentukan SNA
SNA ini memiliki lapisan konvolusional dan lapisan penyatuan dengan fungsi maksimum, dan bobot diinisialisasi menggunakan filter yang ditunjukkan di atas,
import torch import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self, weight): super(Net, self).__init__()
Net( (conv): Conv2d(1, 4, kernel_size=(4, 4), stride=(1, 1), bias=False) (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) )
Langkah 4 : Render Filter
Sekilas filter yang digunakan,
def viz_layer(layer, n_filters= 4): fig = plt.figure(figsize=(20, 20)) for i in range(n_filters): ax = fig.add_subplot(1, n_filters, i+1) ax.imshow(np.squeeze(layer[0,i].data.numpy()), cmap='gray') ax.set_title('Output %s' % str(i+1)) fig = plt.figure(figsize=(12, 6)) fig.subplots_adjust(left=0, right=1.5, bottom=0.8, top=1, hspace=0.05, wspace=0.05) for i in range(4): ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[]) ax.imshow(filters[i], cmap='gray') ax.set_title('Filter %s' % str(i+1)) gray_img_tensor = torch.from_numpy(gray_img).unsqueeze(0).unsqueeze(1)
Filter:
 Langkah 5
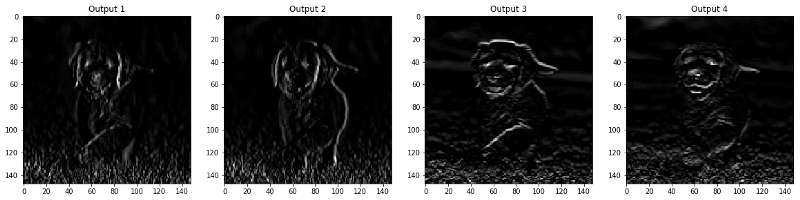
Langkah 5 : Hasil yang Difilter Menurut Lapisan
Gambar-gambar yang muncul di lapisan CONV dan POOL ditunjukkan di bawah ini.
viz_layer(activated_layer) viz_layer(pooled_layer)
Lapisan konvolusional

Lapisan Pooling
 Sumber
Sumber