Jadi, pada tanggal 4 Januari, jam 7:15, setelah menyeka mataku dari tidur, saya menemukan paket pesan di grup Telegram dari server Zabbix sehingga beban CPU pada salah satu server virtualisasi meningkat:
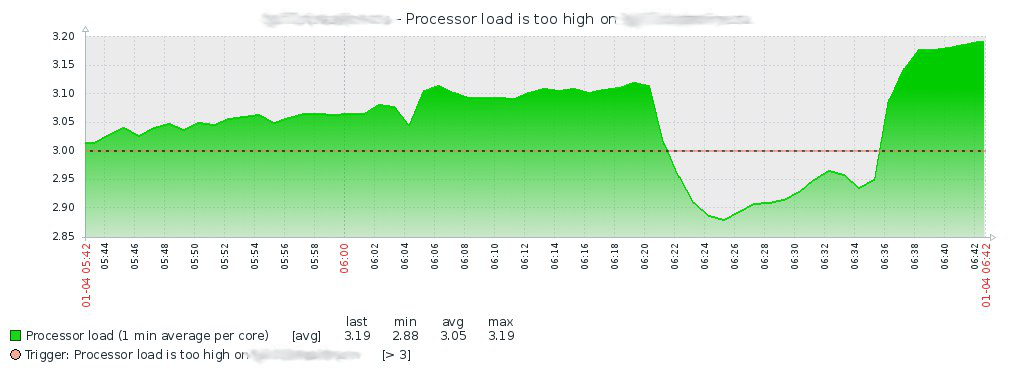
Setelah melihat sejarah di Zabbix, saya naik ke server dan mencari di dmesg, di mana saya menemukan yang berikut:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter. [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device
Saya naik ke penyimpanan di mana adaptor QLogic FC melihat, saya melihat bahwa pada 1 Januari pukul 19.54 salah satu drive dalam penyimpanan tidak digunakan, drive Spare diambil dan resilver berakhir pada 2 Januari pukul 9:11:

Saya berpikir: mungkin sesuatu berasal dari repositori atau sakelar FC, yang menyebabkan pengemudi marah dengan adaptor QLogic.
Menciptakan tugas di pelacak, me-restart server, semuanya berfungsi kembali sebagaimana mestinya, sekilas.
Mengenai hal ini ia menunda tindakan lebih lanjut sampai akhir liburan Tahun Baru.
Dengan dimulainya minggu kerja pada 9 Januari, ia mulai memilah penyebab kegagalan.
Karena pesan:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter.
tidak terlalu informatif, naik ke sumber driver.
Dilihat oleh kode driver, sebuah pesan dikeluarkan ketika driver diturunkan karena kesalahan pada PCI (linux / drivers / scsi / qla2xxx / qla_os.c (kernel v4.15)):
qla2x00_disable_board_on_pci_error(struct work_struct *work) { struct qla_hw_data *ha = container_of(work, struct qla_hw_data, board_disable); struct pci_dev *pdev = ha->pdev; scsi_qla_host_t *base_vha = pci_get_drvdata(ha->pdev); /* * if UNLOAD flag is already set, then continue unload, * where it was set first. */ if (test_bit(UNLOADING, &base_vha->dpc_flags)) return; ql_log(ql_log_warn, base_vha, 0x015b, "Disabling adapter.\n");
Saya mulai menggali lebih jauh, masuk ke BMC, saya melihat di Event Log:
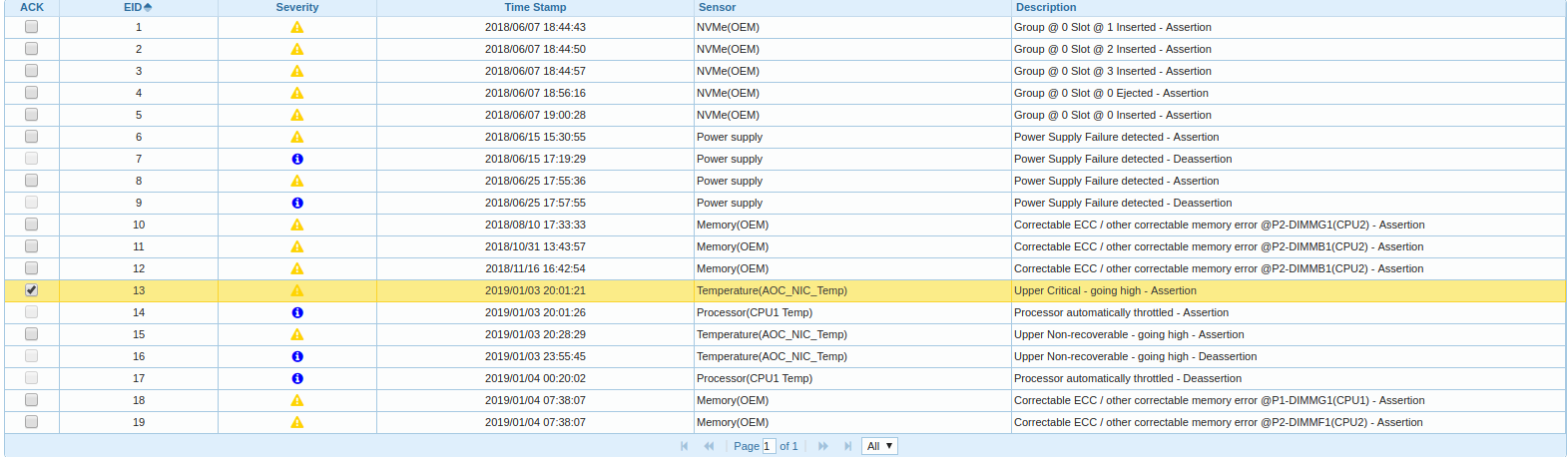
Ternyata salah satu dari dua simpul CPU dalam platform adalah pemanasan dan pelambatan, dan waktu pesan tentang pembongkaran driver adaptor FC berkorelasi dengan waktu mulai pelambatan.
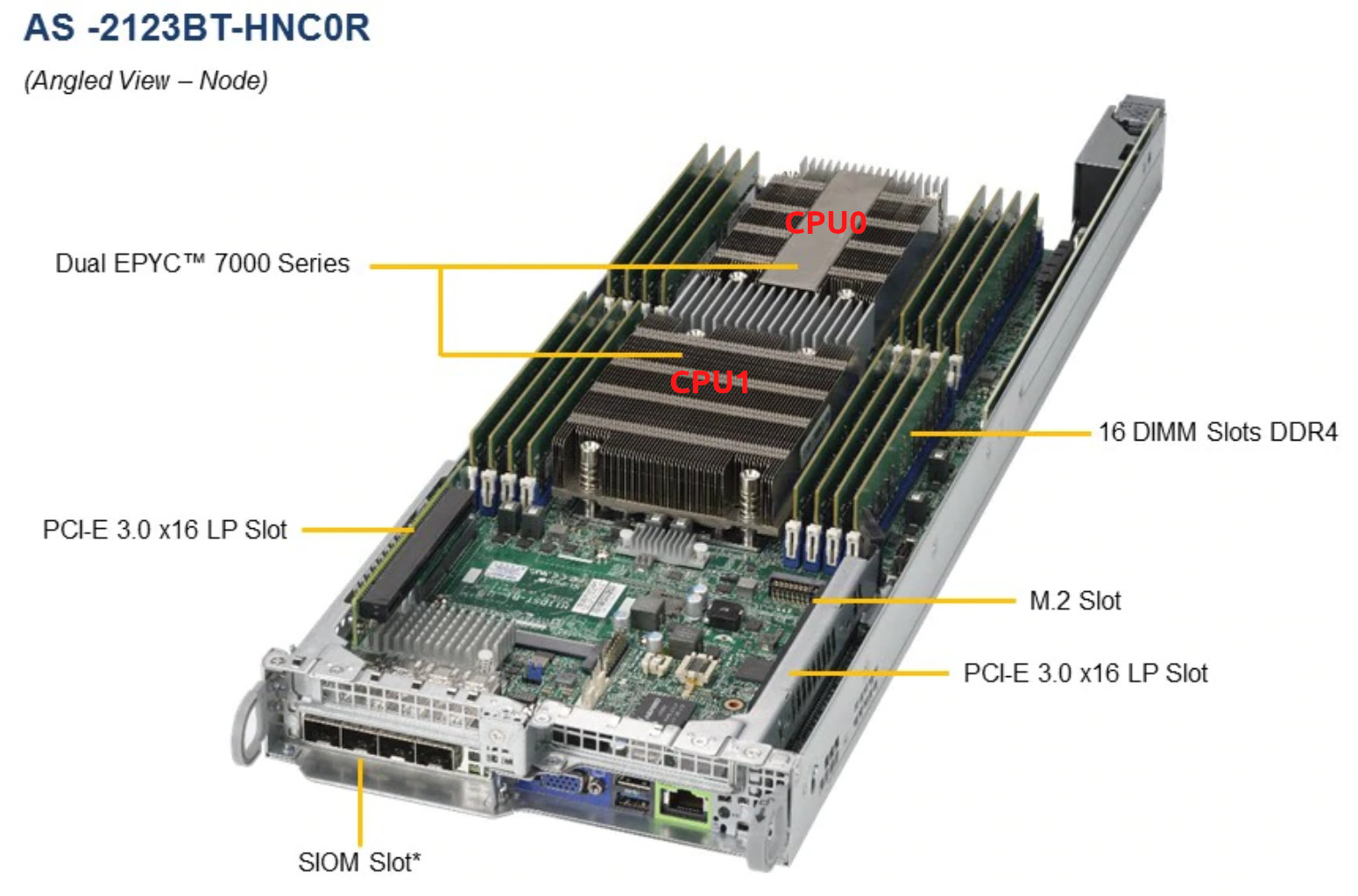
Di sini layak untuk membuat pernyataan bahwa platform server yang kami miliki di sini adalah https://www.supermicro.com/Aplus/system/2U/2123/AS-2123BT-HNC0R.cfm dengan dua EPYC 7601 untuk setiap node:
Saya memindahkannya ke pusat data, menghapus node dari server, mengubah thermal paste, menempelkannya kembali, tetapi masih memanas.
Kami perhatikan bahwa aliran udara di satu bagian server tidak sekuat di bagian lainnya. Setelah sedikit memuat semua node dengan stress-ng, menjadi jelas bahwa prosesor node di sisi kanan platform tidak meledak dengan baik dan suhu CPU kedua dalam dua node sangat cepat mencapai kritis.
Setelah mencoba mengubah parameter hembusan di BMC, ternyata tidak ada efek:
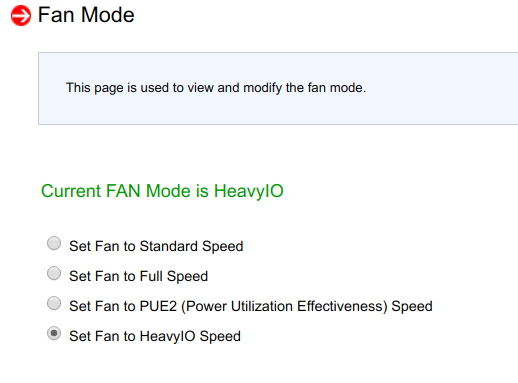
Restart BMC juga tidak berpengaruh.
Setelah melihat dalam Bacaan Sensor, saya melihat bahwa pada satu node dari 53 sensor, hanya 4 yang terdeteksi, dan pada node lainnya hanya 6:
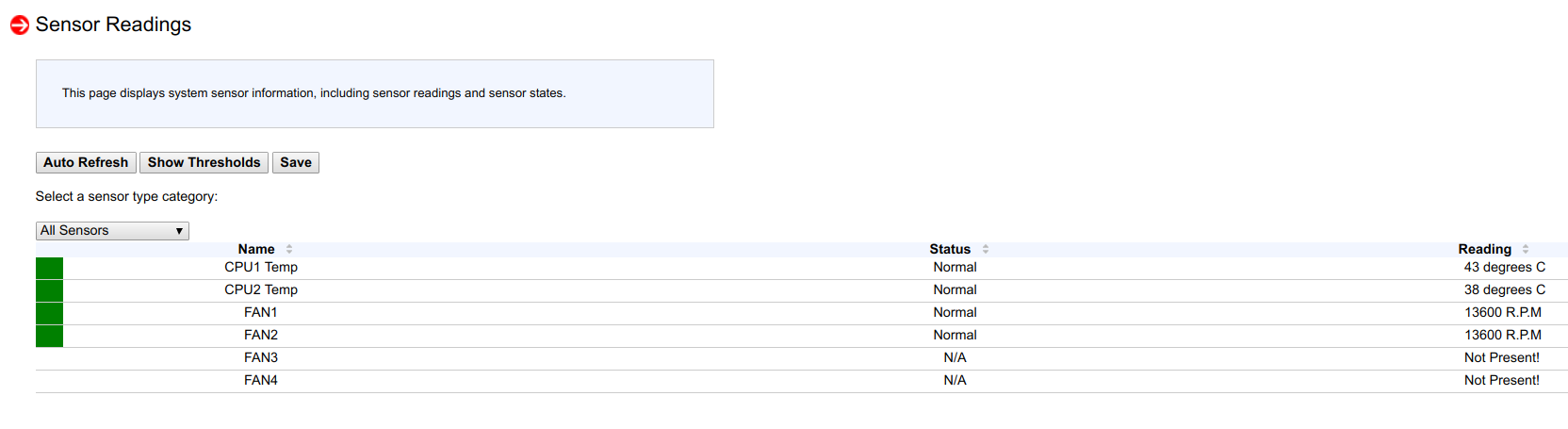
Dan kemudian, saya ingat ketika menginstal versi BIOS baru dan BMC baru ke node satu atau dua bulan yang lalu, pada dua node saya tidak mereset konfigurasi BMC ke parameter pabrik (untuk memeriksa satu kasus penyetelan tertentu).
Setelah mengatur ulang BMC ke parameter pabrik, ke-53 sensor kembali terdeteksi, kontrol kecepatan kipas kembali bekerja, prosesor berhenti menghangat.
Fakta bahwa penyebab pembongkaran driver QLogic adalah prosesor yang terlalu panas tidak akurat, tetapi saya tidak menemukan korelasi dekat lainnya.
Kesimpulan:
- setelah firmware BMC, bahkan jika semuanya berfungsi dengan baik pada pandangan pertama, masih layak untuk diatur ulang ke pengaturan pabrik;
- Tentu saja, pesan kesalahan suhu dan kernel harus dipantau dan ini wajar dalam rencana, tetapi tidak semuanya sekaligus.