Nama saya Vladislav, saya berpartisipasi dalam pengembangan
Tarantool - DBMS dan server aplikasi dalam satu botol. Dan hari ini saya akan memberi tahu Anda bagaimana kami menerapkan penskalaan horizontal di Tarantool menggunakan modul
VShard .
Pertama, sedikit teori.
Ada dua jenis penskalaan: horisontal dan vertikal. Horisontal dibagi menjadi dua jenis: replikasi dan sharding. Replikasi digunakan untuk skala komputasi, sharding digunakan untuk skala data.
Sharding dibagi menjadi dua jenis: sharding oleh rentang dan sharding oleh hash.
Saat beling dengan rentang, kami menghitung beberapa kunci beling dari setiap catatan di cluster. Kunci beling ini diproyeksikan ke garis lurus, yang dibagi menjadi rentang yang kami tambahkan ke simpul fisik yang berbeda.
Sharding dengan hash lebih sederhana: dari setiap record di cluster kami menganggap fungsi hash, kami menambahkan entri dengan nilai yang sama dari fungsi hash ke satu simpul fisik.
Saya akan berbicara tentang penskalaan horizontal menggunakan hash sharding.
Implementasi sebelumnya
Modul penskalaan horizontal pertama yang kami miliki adalah
Tarantool Shard . Ini adalah sharding dengan hash yang sangat sederhana, yang mempertimbangkan kunci shard dari kunci utama semua entri dalam cluster.
function shard_function(primary_key) return guava(crc32(primary_key), shard_count) end
Tetapi kemudian muncul tugas bahwa Tarantool Shard tidak dapat menangani karena tiga alasan mendasar.
Pertama, diperlukan
lokasi data terkait logis . Ketika kami memiliki data yang terhubung secara logis, kami selalu ingin menyimpannya di node fisik yang sama, tidak peduli bagaimana topologi cluster berubah atau balancing dilakukan. Dan Tarantool Shard tidak menjamin ini. Dia menganggap hash hanya dengan kunci primer, dan ketika menyeimbangkan kembali, bahkan catatan dengan hash yang sama dapat dipisahkan untuk beberapa waktu - transfernya bukan atom.
Masalah kurangnya lokalitas data paling menghambat kami. Saya akan memberi contoh. Ada bank tempat klien membuka akun. Data akun dan klien harus selalu disimpan bersama secara fisik sehingga dapat dibaca dalam satu permintaan, dipertukarkan dalam satu transaksi, misalnya, saat mentransfer uang dari akun. Jika Anda menggunakan sharding klasik dengan Tarantool Shard, maka nilai fungsi shard akan berbeda untuk akun dan pelanggan. Data mungkin pada node fisik yang berbeda. Ini sangat menyulitkan pekerjaan membaca dan transaksional dengan klien seperti itu.
format = {{'id', 'unsigned'}, {'email', 'string'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}} box.schema.create_space('account', {format = format})
Pada contoh di atas, bidang
id dapat dengan mudah tidak cocok dengan akun dan pelanggan. Mereka terhubung melalui bidang akun
customer_id dan
id customer_id . Bidang
id sama akan memecah keunikan kunci utama akun. Dan dengan cara lain Shard tidak mampu shard.
Masalah selanjutnya adalah
resharding lambat . Ini adalah masalah klasik semua pecahan hash. Intinya adalah ketika kita mengubah komposisi sebuah cluster, kita biasanya mengubah fungsi shard, karena biasanya tergantung pada jumlah node. Dan ketika fungsi berubah, Anda harus memeriksa semua entri di cluster dan menghitung ulang fungsi shard lagi. Mungkin mentransfer beberapa catatan. Dan saat kami mentransfernya, kami tidak tahu apakah data yang dibutuhkan oleh permintaan masuk berikutnya sudah ditransfer, mungkin mereka sekarang sedang dalam proses mentransfer. Oleh karena itu, selama pengulangan, perlu untuk setiap pembacaan untuk membuat permintaan untuk dua fungsi beling: yang lama dan yang baru. Permintaan menjadi dua kali lebih lambat, dan bagi kami itu tidak dapat diterima.
Fitur lain dari Tarantool Shard adalah bahwa ketika beberapa node dalam set replika gagal, itu menunjukkan
aksesibilitas baca yang buruk .
Solusi baru
Untuk mengatasi tiga masalah yang dijelaskan, kami menciptakan
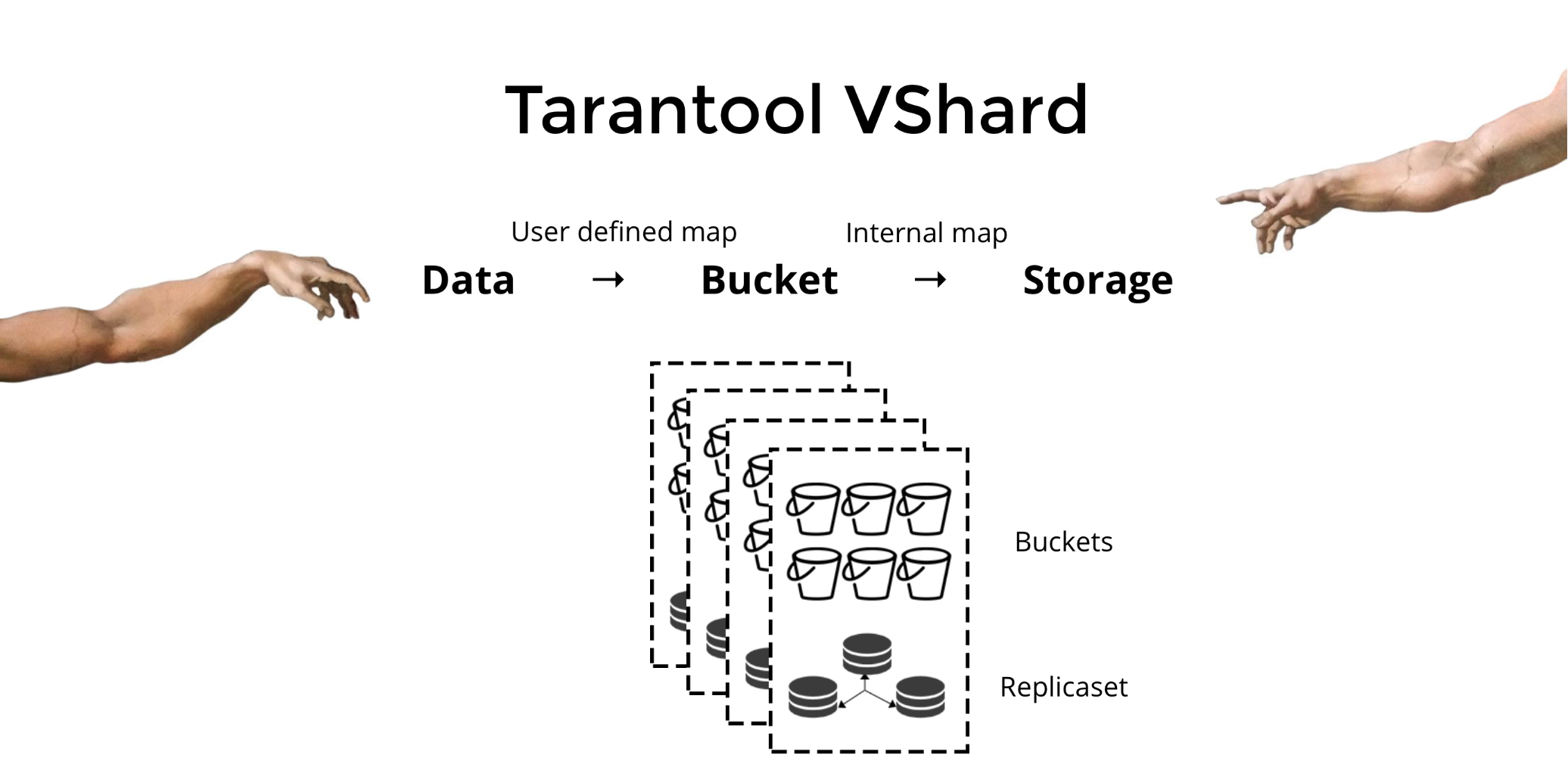
Tarantool VShard . Perbedaan utamanya adalah tingkat penyimpanan data divirtualkan: penyimpanan virtual muncul di atas yang fisik, dan catatan didistribusikan di antara mereka. Penyimpanan ini disebut bucket'ami. Pengguna tidak perlu memikirkan apa dan di mana simpul fisik berada. Bucket adalah unit data atom yang tidak dapat dibagi, seperti dalam sharding klasik satu tuple. VShard selalu menyimpan seluruh bucket pada satu simpul fisik dan selama pengulangan pengiriman semua data satu ember secara atom. Karena ini, lokalitas disediakan. Kami hanya perlu memasukkan data dalam satu ember, dan kami selalu dapat yakin bahwa data ini akan bersama dengan setiap perubahan di cluster.

Bagaimana saya bisa memasukkan data dalam satu ember? Dalam skema yang sebelumnya kami perkenalkan untuk klien bank, kami akan menambahkan
bucket id ke tabel sesuai dengan bidang baru. Jika data tertaut adalah sama, catatan akan berada di ember yang sama. Keuntungannya adalah kita dapat menyimpan catatan ini dengan
bucket id sama di ruang yang berbeda, dan bahkan di mesin yang berbeda.
bucket id disediakan tidak peduli bagaimana catatan ini disimpan.
format = {{'id', 'unsigned'}, {'email', 'string'}, {'bucket_id', 'unsigned'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}, {'bucket_id', 'unsigned'}} box.schema.create_space('account', {format = format})
Kenapa kita begitu bersemangat untuk ini? Jika kita memiliki sharding klasik, maka data dapat merayapi semua penyimpanan fisik yang hanya kita miliki. Dalam contoh dengan bank, saat meminta semua akun klien, Anda harus beralih ke semua node. Ternyata kesulitan membaca O (N), di mana N adalah jumlah toko fisik. Sangat lambat.
Berkat bucket'am dan lokalitas berdasarkan
bucket id kami selalu dapat membaca data dari satu node dalam satu permintaan, terlepas dari ukuran cluster.

Anda perlu menghitung
bucket id dan menetapkan nilai yang sama sendiri. Bagi sebagian orang, ini merupakan keuntungan, bagi seseorang kerugian. Saya menganggap itu keuntungan bahwa Anda dapat memilih fungsi untuk menghitung
bucket id sendiri.
Apa perbedaan utama antara sharding klasik dan sharding virtual dengan bucket?
Dalam kasus pertama, ketika kita mengubah komposisi cluster, kita memiliki dua status: saat ini (lama) dan yang baru, di mana kita harus pergi. Dalam proses transisi, Anda tidak hanya perlu mentransfer data, tetapi juga untuk menghitung ulang fungsi hash untuk semua catatan. Ini sangat merepotkan, karena pada waktu tertentu kita tidak tahu data mana yang sudah ditransfer dan mana yang tidak. Selain itu, ini bukan dapat diandalkan atau atomik, karena untuk transfer atom dari satu set catatan dengan nilai fungsi hash yang sama, perlu untuk menyimpan kondisi transfer secara terus-menerus jika perlu pemulihan. Ada konflik, kesalahan, Anda harus memulai ulang prosedur berkali-kali.
Sharding virtual jauh lebih sederhana. Kami tidak memiliki dua status cluster yang dipilih, kami hanya memiliki status bucket. Cluster menjadi lebih bermanuver, secara bertahap bergerak dari satu kondisi ke kondisi lainnya. Dan sekarang ada lebih dari dua negara. Berkat transisi yang lancar, Anda dapat mengubah saldo dengan cepat, menghapus penyimpanan yang baru ditambahkan. Artinya, kemampuan mengontrol keseimbangan sangat meningkat, menjadi granular.
Gunakan
Katakanlah kita memilih fungsi untuk
bucket id dan menuangkan begitu banyak data ke dalam cluster sehingga tidak ada lagi ruang. Sekarang kami ingin menambahkan node, dan agar data dipindahkan ke mereka sendiri. Di VShard, ini dilakukan sebagai berikut. Pertama, luncurkan node dan Tarantools baru pada mereka, dan kemudian perbarui konfigurasi VShard. Ini menggambarkan semua anggota cluster, semua replika, set replika, master, URI yang ditugaskan, dan banyak lagi. Kami menambahkan node baru ke konfigurasi, dan menggunakan fungsi
VShard.storage.cfg ,
VShard.storage.cfg menggunakannya pada semua node cluster.
function create_user(email) local customer_id = next_id() local bucket_id = crc32(customer_id) box.space.customer:insert(customer_id, email, bucket_id) end function add_account(customer_id) local id = next_id() local bucket_id = crc32(customer_id) box.space.account:insert(id, customer_id, 0, bucket_id) end
Seperti yang Anda ingat, dalam sharding klasik dengan perubahan jumlah node, fungsi shard juga berubah. Dalam VShard ini tidak terjadi, kami memiliki sejumlah penyimpanan virtual - bucket'ov. Ini adalah konstanta yang Anda pilih saat memulai cluster. Mungkin karena itu, skalabilitas terbatas, tetapi tidak juga. Anda dapat memilih sejumlah besar bucket'ov, puluhan dan ratusan ribu. Hal utama adalah bahwa harus ada setidaknya dua urutan besarnya lebih dari jumlah set replika maksimum yang pernah Anda miliki di cluster.
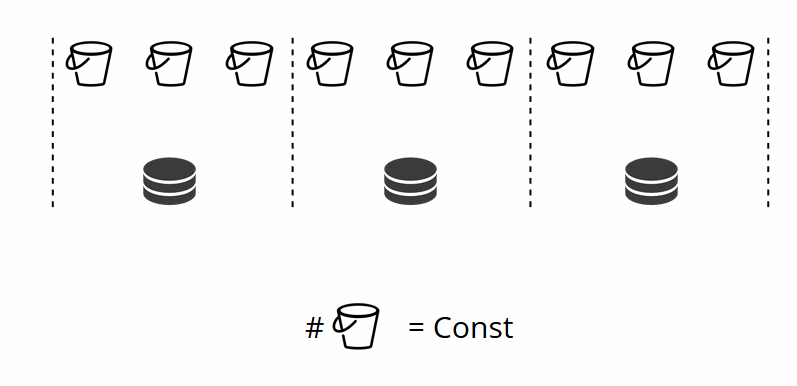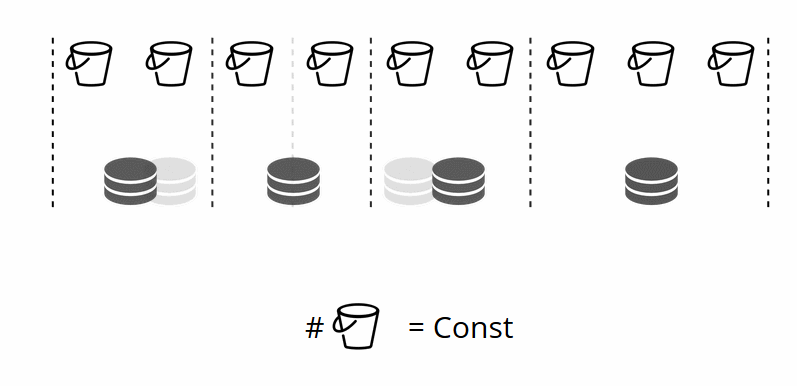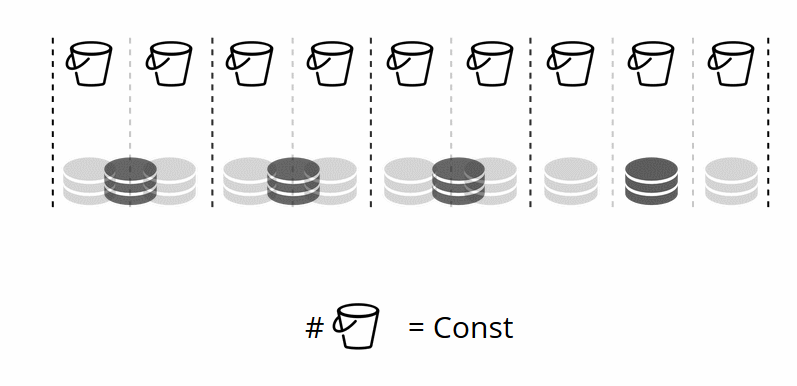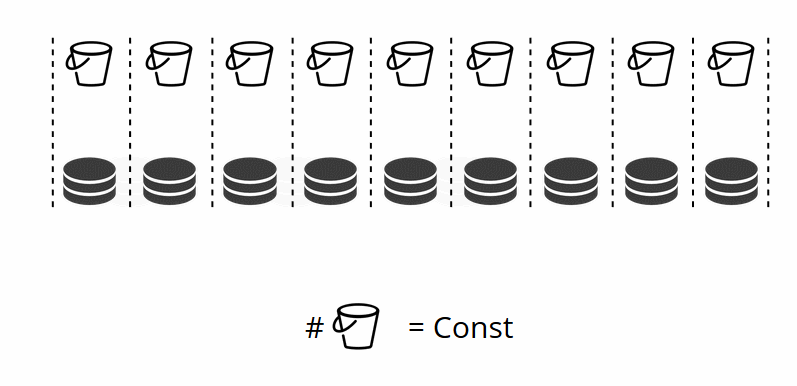
Karena jumlah penyimpanan virtual tidak berubah - dan fungsi beling hanya bergantung pada nilai ini - kita dapat menambahkan penyimpanan fisik sebanyak yang diperlukan tanpa menghitung ulang fungsi beling.
Bagaimana buket didistribusikan di antara toko fisik sendiri? Ketika VShard.storage.cfg dipanggil pada salah satu node, proses rebalancing terbangun. Ini adalah proses analitik yang menghitung keseimbangan sempurna dalam sebuah cluster. Dia pergi ke semua node fisik, bertanya siapa yang memiliki berapa bucket'ov, dan membangun rute untuk pergerakan mereka untuk rata-rata distribusi. Penyeimbang mengirimkan rute ke penyimpanan yang penuh sesak, dan mereka mulai mengirim ember. Setelah beberapa waktu, gugus menjadi seimbang.
Tetapi dalam proyek nyata, konsep keseimbangan sempurna mungkin berbeda. Sebagai contoh, saya ingin menyimpan lebih sedikit data pada satu set replika daripada yang lain, karena ada lebih sedikit ruang hard disk. VShard berpikir bahwa semuanya seimbang, dan sebenarnya penyimpanan saya hampir meluap. Kami telah menyediakan mekanisme untuk menyesuaikan aturan keseimbangan menggunakan bobot. Setiap set replika dan repositori dapat ditimbang. Ketika penyeimbang memutuskan kepada siapa untuk mengirim berapa ember, dia memperhitungkan
hubungan semua pasangan bobot.
Misalnya, satu toko memiliki berat 100, dan yang lain memiliki 200. Kemudian toko pertama akan menyimpan dua kali lebih sedikit ember daripada yang kedua. Harap dicatat bahwa saya sedang berbicara secara khusus tentang
rasio bobot. Makna absolut tidak berpengaruh. Anda dapat memilih bobot berdasarkan distribusi cluster 100%: satu toko memiliki 30%, yang lain memiliki 70%. Anda dapat menggunakan kapasitas penyimpanan dalam gigabytes sebagai dasar, atau Anda dapat mengukur bobot dalam jumlah bucket'ov. Hal utama adalah mengamati sikap yang Anda butuhkan.
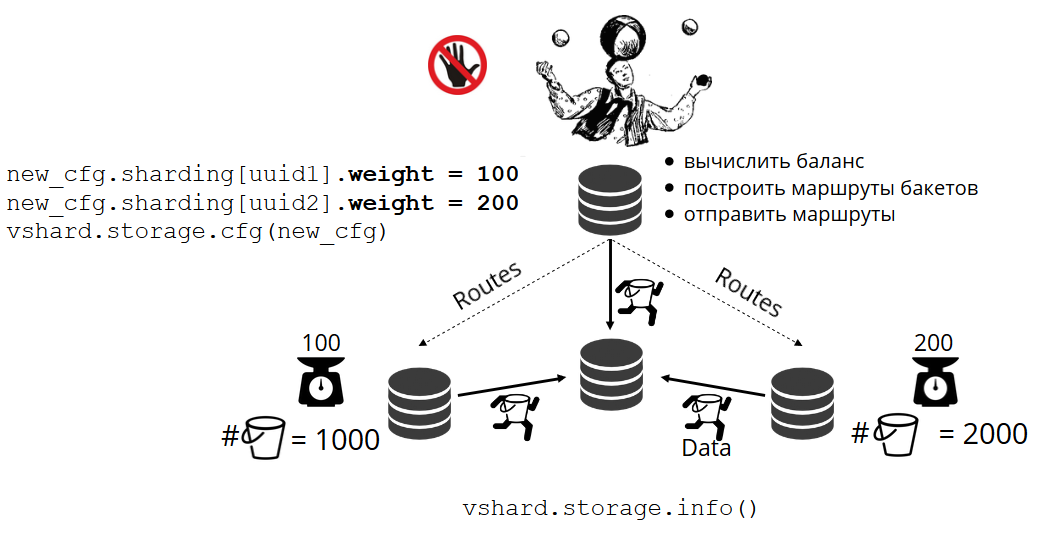
Sistem semacam itu memiliki efek samping yang menarik: jika Anda menetapkan bobot nol untuk beberapa toko, maka penyeimbang akan memerintahkan toko untuk mendistribusikan semua embernya. Setelah itu, Anda dapat menghapus seluruh set replika dari konfigurasi.
Transfer Ember Atom
Kami memiliki ember, menerima beberapa jenis permintaan baca dan tulis, dan kemudian penyeimbang meminta untuk mentransfernya ke penyimpanan lain. Bucket berhenti menerima permintaan untuk merekam, jika tidak mereka akan memiliki waktu untuk memperbaruinya selama transfer, maka mereka akan memiliki waktu untuk memperbarui pembaruan portabel, kemudian pembaruan portabel, dan seterusnya hingga tak terbatas. Oleh karena itu, catatan diblokir, dan Anda masih dapat membaca dari ember. Pemindahan bongkahan ke tempat baru dimulai. Setelah transfer selesai, ember akan kembali menerima permintaan. Di tempat lama, itu juga masih terletak, tetapi sudah ditandai sebagai sampah dan kemudian pengumpul sampah akan menghapusnya sepotong demi sepotong.
Setiap bucket dikaitkan dengan metadata yang disimpan secara fisik di disk. Semua langkah di atas disimpan ke disk, dan apa pun yang terjadi dengan repositori, keadaan bucket akan secara otomatis dikembalikan.
Anda mungkin memiliki pertanyaan:
- Apa yang akan terjadi pada permintaan yang bekerja dengan bucket ketika mereka mulai porting?
Ada dua jenis tautan dalam metadata setiap kotak: baca dan tulis. Ketika pengguna membuat permintaan ke ember, ia menunjukkan bagaimana ia akan bekerja dengannya, hanya baca atau baca tulis. Untuk setiap permintaan, penghitung referensi yang sesuai bertambah.
Mengapa saya memerlukan penghitung referensi untuk membaca permintaan? Katakanlah ember dipindahkan dengan diam-diam, dan di sini pemulung datang dan ingin menghapus ember ini. Dia melihat bahwa jumlah tautan lebih besar dari nol, jadi Anda tidak dapat menghapusnya. Dan ketika permintaan diproses, pemulung akan dapat menyelesaikan pekerjaannya.
Penghitung referensi untuk permintaan penulisan memastikan bahwa ember bahkan tidak mulai terbawa ketika setidaknya satu permintaan penulisan bekerja dengannya. Tetapi permintaan penulisan bisa datang terus-menerus, dan kemudian ember tidak akan pernah ditransfer. Faktanya adalah bahwa jika penyeimbang telah menyatakan keinginan untuk mentransfernya, maka permintaan rekaman baru akan mulai diblokir, dan sistem saat ini akan menunggu penyelesaian beberapa waktu habis. Jika permintaan tidak selesai dalam waktu yang ditentukan, sistem akan kembali menerima permintaan penulisan baru, menunda transfer bucket untuk beberapa waktu. Dengan demikian, penyeimbang akan melakukan upaya transfer sampai berhasil.
VShard memiliki API bucket_ref tingkat rendah jika Anda memiliki beberapa fitur tingkat tinggi. Jika Anda benar-benar ingin melakukan sesuatu sendiri, cukup akses API ini dari kodenya. - Apakah mungkin untuk tidak memblokir catatan sama sekali?
Itu tidak mungkin. Jika bucket berisi data penting yang membutuhkan akses tulis konstan, Anda harus memblokir transfernya sama sekali. Ada fungsi bucket_pin untuk ini, itu menempel erat ember ke set replika saat ini, mencegah transfernya. Dalam hal ini, bucket yang berdekatan dapat bergerak tanpa batasan.

Ada alat yang bahkan lebih kuat daripada bucket_pin - replika set blocking. Tidak lagi dilakukan dalam kode, tetapi melalui konfigurasi. Blocking melarang perpindahan bucket'ov dari set'a replika ini dan penerimaan yang baru. Dengan demikian, semua data akan selalu tersedia untuk direkam.

VShard.router
VShard terdiri dari dua submodul: VShard.storage dan VShard.router. Mereka dapat dibuat dan diskalakan secara independen bahkan pada satu contoh. Saat mengakses cluster, kami tidak tahu di mana bucket berada, dan VShard.router akan mencarinya dengan
bucket id untuk kami.
Mari kita lihat contoh bagaimana ini terlihat. Kami kembali ke cluster perbankan dan akun klien. Saya ingin dapat mengeluarkan semua akun klien tertentu dari cluster. Untuk melakukan ini, saya menulis fungsi biasa untuk pencarian lokal:
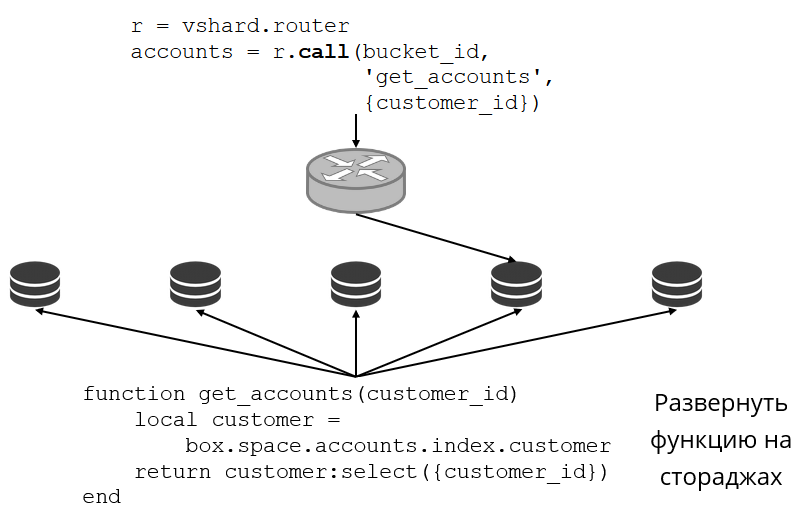
Dia mencari semua akun pelanggan dengan id-nya. Sekarang saya perlu memutuskan repositori mana yang akan memanggil fungsi ini. Untuk melakukan ini, saya menghitung
bucket id dari ID klien dalam permintaan saya dan meminta VShard.router untuk memanggil saya fungsi seperti itu di penyimpanan tempat bucket tinggal dengan
bucket id dihasilkan. Ada tabel routing dalam submodule, di mana lokasi ember di set replika ditentukan. Dan VShard.router proksi permintaan saya.
Tentu saja, itu mungkin terjadi bahwa saat ini dimulai pengerjaan ulang dan ember mulai bergerak. Router di latar belakang secara bertahap memperbarui tabel dalam potongan besar: ia menanyakan repositori untuk tabel bucket mereka saat ini.
Bahkan mungkin terjadi bahwa kita beralih ke bucket yang baru saja dipindahkan, dan router belum berhasil memperbarui tabel peruteannya. Kemudian dia akan beralih ke repositori lama, dan itu akan memberi tahu router tempat untuk mencari ember, atau hanya menjawab bahwa itu tidak memiliki data yang diperlukan. Kemudian router akan berkeliling semua penyimpanan untuk mencari ember yang diinginkan. Dan semua ini transparan bagi kami, kami bahkan tidak akan melihat ada kesalahan dalam tabel routing.
Baca ketidakstabilan
Ingat masalah yang awalnya kami alami:
- Tidak ada lokalitas data. Kami memutuskan dengan menambahkan bucket'ov.
- Resharding memperlambat segalanya dan memperlambat. Diimplementasikan ember'ami transfer data atom, menyingkirkan penghitungan fungsi beling.
- Bacaan tidak stabil.
Masalah terakhir diselesaikan oleh VShard.router menggunakan subsistem baca failover otomatis.
Router secara berkala mem-ping penyimpanan yang ditentukan dalam konfigurasi. Dan kemudian beberapa dari mereka berhenti ping. Router memiliki koneksi cadangan panas untuk setiap replika, dan jika yang saat ini berhenti merespons, itu akan pergi ke yang lain. Permintaan baca akan diproses secara normal, karena kita dapat membaca replika (tetapi tidak menulis). Kita dapat mengatur prioritas replika dimana router harus memilih failover untuk dibaca. Kami melakukan ini dengan zonasi.
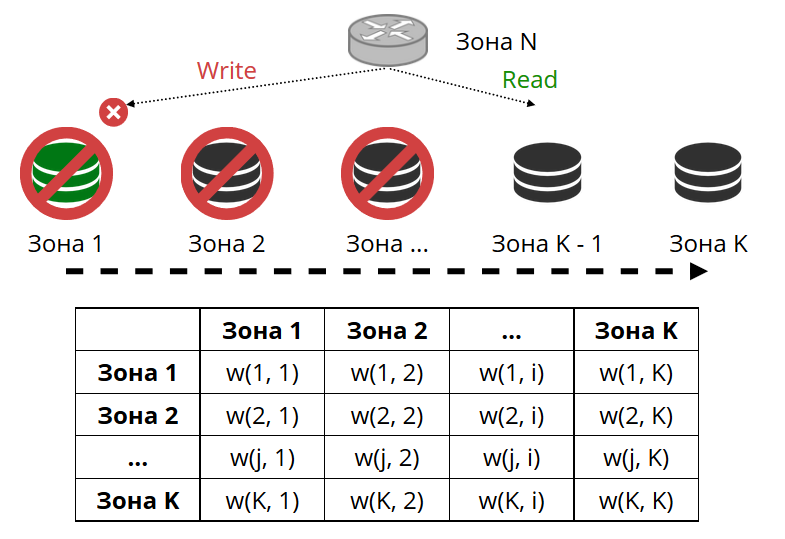
Kami menetapkan nomor zona untuk setiap replika dan setiap router dan mengatur tabel di mana kami menunjukkan jarak antara setiap pasangan zona. Ketika router memutuskan ke mana harus mengirim permintaan baca, itu akan memilih replika di zona yang paling dekat dengan permintaannya.
Bagaimana tampilannya dalam konfigurasi:
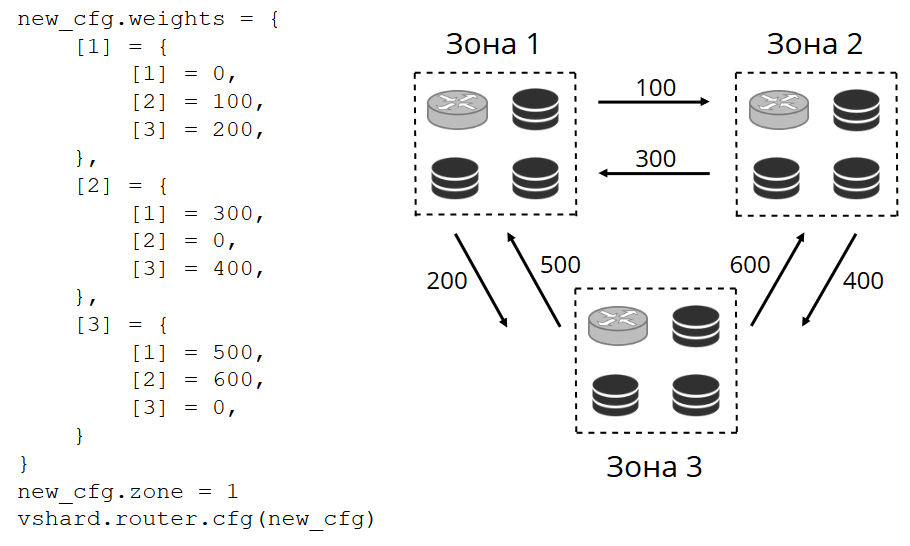
Dalam kasus umum, Anda bisa merujuk ke replika yang sewenang-wenang, tetapi jika cluster besar dan kompleks, sangat terdistribusi, maka zonasi sangat berguna. Rak server yang berbeda dapat menjadi zona, agar tidak memuat jaringan dengan lalu lintas. Atau bisa juga titik-titik yang secara geografis jauh dari satu sama lain.
Zonasi juga membantu dengan beragam kinerja replika. Misalnya, dalam setiap set replika kami memiliki satu replika cadangan, yang seharusnya tidak menerima permintaan, tetapi hanya menyimpan salinan data. Kemudian kita membuatnya di zona, yang akan sangat jauh dari semua router di tabel, dan mereka akan beralih ke itu dalam kasus yang paling ekstrem.
Merekam ketidakstabilan
Karena kita berbicara tentang read failover, bagaimana dengan write failover ketika mengubah wisaya? Di sini, VShard tidak begitu cerah: pemilihan master baru tidak diterapkan di dalamnya, Anda harus melakukannya sendiri. Ketika kita entah bagaimana memilihnya, perlu bahwa instance ini sekarang mengambil alih otoritas master. Kami memperbarui konfigurasi dengan menentukan
master = false untuk master lama, dan
master = true untuk yang baru, menerapkannya melalui VShard.storage.cfg dan menggulungnya ke penyimpanan. Maka semuanya terjadi secara otomatis. Master lama berhenti menerima permintaan tulis dan mulai menyinkronkan dengan yang baru, karena mungkin ada data yang sudah diterapkan pada master lama, tetapi yang baru belum tiba. Setelah itu, master baru memasuki peran dan mulai menerima permintaan, dan master lama menjadi replika. Beginilah cara menulis failover bekerja di VShard.
replicas = new_cfg.sharding[uud].replicas replicas[old_master_uuid].master = false replicas[new_master_uuid].master = true vshard.storage.cfg(new_cfg)
Bagaimana sekarang mengikuti semua ragam acara ini?
Dalam kasus umum, dua pegangan sudah cukup -
VShard.storage.info dan
VShard.router.info .
VShard.storage.info menampilkan informasi dalam beberapa bagian.
vshard.storage.info() --- - replicasets: <replicaset_2>: uuid: <replicaset_2> master: uri: storage@127.0.0.1:3303 <replicaset_1>: uuid: <replicaset_1> master: missing bucket: receiving: 0 active: 0 total: 0 garbage: 0 pinned: 0 sending: 0 status: 2 replication: status: slave Alerts: - ['MISSING_MASTER', 'Master is not configured for ''replicaset <replicaset_1>']
Yang pertama adalah bagian replikasi. Status set replika yang Anda terapkan fungsi ini ditampilkan: lag replikasi apa yang dimilikinya, dengan siapa ia memiliki koneksi dan dengan siapa itu tidak tersedia, siapa yang tersedia dan tidak tersedia, wizard mana yang dikonfigurasi untuk yang mana, dll.
Di bagian Bucket, Anda dapat melihat secara real time berapa banyak bucket'ov saat ini pindah ke set replika saat ini, berapa banyak yang meninggalkannya, berapa banyak yang sedang mengerjakannya, berapa banyak yang ditandai sebagai sampah, berapa banyak yang terpasang.
Bagian Alert adalah semacam campur aduk dari semua masalah yang VShard mampu menentukan secara independen: master tidak dikonfigurasi, tingkat redundansi tidak cukup, master ada di sana, dan semua replika telah gagal, dll.
Dan bagian terakhir adalah cahaya yang menyala merah ketika segalanya menjadi sangat buruk. Ini adalah angka dari nol hingga tiga, semakin banyak semakin buruk.
VShard.router.info memiliki bagian yang sama, tetapi artinya sedikit berbeda.
vshard.router.info() --- - replicasets: <replicaset_2>: replica: &0 status: available uri: storage@127.0.0.1:3303 uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7 bucket: available_rw: 500 uuid: <replicaset_2> master: *0 <replicaset_1>: replica: &1 status: available uri: storage@127.0.0.1:3301 uuid: 8a274925-a26d-47fc-9e1b-af88ce939412 bucket: available_rw: 400 uuid: <replicaset_1> master: *1 bucket: unreachable: 0 available_ro: 800 unknown: 200 available_rw: 700 status: 1 alerts: - ['UNKNOWN_BUCKETS', '200 buckets are not discovered']
Bagian pertama adalah replikasi. , : , replica set' , , , replica set' bucket' , .
Bucket bucket', ; bucket' ; , replica set'.
Alert, , , failover, bucket'.
, .
VShard?
— bucket'.
int32_max ? bucket' — 30 16 . bucket', . bucket', bucket'. , .
— -
bucket id . , - , bucket — . , bucket' , VShard bucket'. -, bucket' bucket, -. .
Ringkasan
Vshard :
- ;
- ;
- ;
- read failover;
- bucket'.
VShard . - . —
. , . .
—
lock-free bucket' . , bucket' . , .
—
. : - , , ? .