Prometheus 2.6.0 dioptimalkan memuat WAL, yang mempercepat proses startup.
Tujuan tidak resmi dari pengembangan Prometheus 2.x TSDB adalah untuk mempercepat peluncuran sehingga dibutuhkan tidak lebih dari satu menit. Dalam beberapa bulan terakhir, ada laporan bahwa prosesnya memakan waktu sedikit lebih lama, dan jika Prometheus restart karena alasan tertentu, maka ini sudah menjadi masalah. Hampir sepanjang waktu ini, WAL (pra-perekaman rekaman) dimuat, yang mencakup sampel dari beberapa jam terakhir yang belum dikompres menjadi blok. Pada akhir Oktober, saya akhirnya berhasil mengatasinya; hasilnya adalah PR # 440 , yang mengurangi waktu CPU sebesar 6,5 kali dan waktu perhitungan sebanyak 4 kali. Mari kita lihat bagaimana saya melakukan perbaikan ini.

Pertama, pengaturan tes diperlukan. Saya membuat program Go kecil yang menghasilkan TSDB dengan WAL dengan satu miliar sampel yang tersebar di 10.000 seri waktu. Kemudian saya membuka TSDB ini dan melihat berapa lama waktu yang dibutuhkan untuk menggunakan utilitas time (bukan struktur bawaan , karena tidak termasuk statistik memori), dan juga membuat profil CPU menggunakan paket runtime / pprof :
f, err := os.Create("cpu.prof") if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile()
Profil CPU tidak memungkinkan kami untuk secara langsung menentukan waktu perhitungan yang menarik bagi kami, namun ada korelasi yang signifikan. Hasilnya, pada komputer desktop saya (prosesor i7-3770 dengan 16 GB RAM dan solid state drive), pengunduhan memakan waktu sekitar 4 menit dan sedikit kurang dari 6 GB RAM pada puncaknya:
1727.50user 16.61system 4:01.12elapsed 723%CPU (0avgtext+0avgdata 5962812maxresident)k 23625165inputs+95outputs (196major+2042817minor)pagefaults 0swaps
Ini bukan buzz, jadi mari kita memuat profil menggunakan go tool pprof cpu.prof dan lihat berapa lama prosesnya jika Anda menggunakan perintah top .

Di sini flat adalah jumlah waktu yang dihabiskan untuk fungsi yang diberikan, dan cum adalah waktu yang dihabiskan untuk fungsi ini dan semua fungsi yang dipanggil olehnya. Mungkin juga berguna untuk melihat data ini dalam grafik untuk mendapatkan gagasan tentang pertanyaan itu. Saya lebih suka menggunakan perintah web untuk ini, tetapi ada opsi lain, termasuk file svg, png dan pdf.
Dapat dilihat bahwa sekitar sepertiga dari CPU kami dihabiskan untuk menambahkan sampel ke database internal, sekitar dua pertiga pada pemrosesan WAL secara umum, dan seperempat untuk membersihkan memori ( runtime.scanobject ). Mari kita lihat kode untuk yang pertama dari proses ini menggunakan list memSeries.*append :
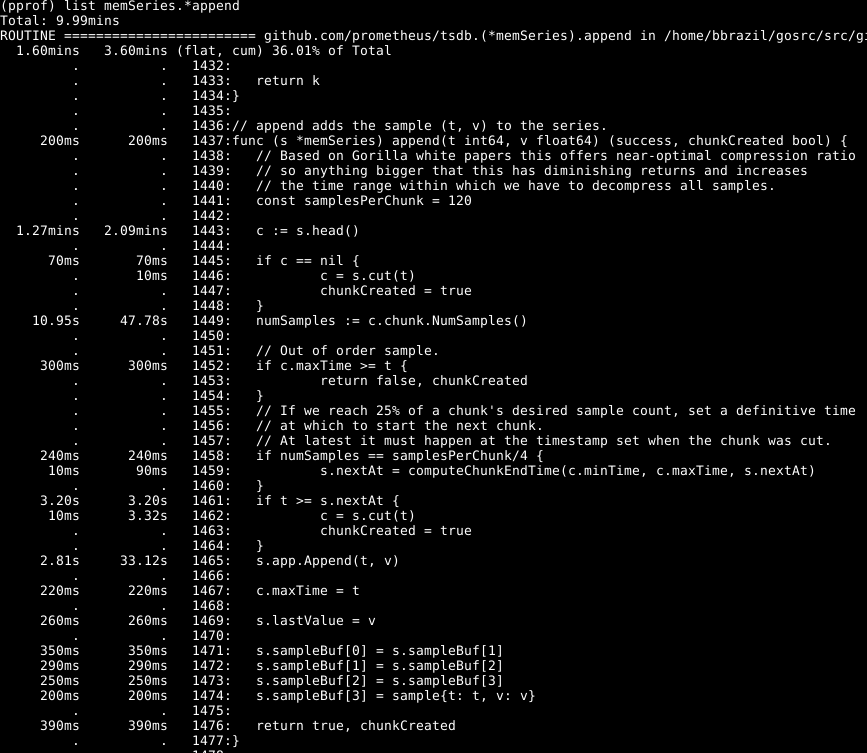
Berikut ini mencolok di sini: lebih dari separuh waktu dihabiskan untuk mendapatkan potongan kepala data untuk seri pada baris 1443. Juga, tidak sedikit waktu yang dihabiskan untuk mengatur jumlah sampel dalam bagian data ini pada baris 1449. Waktu yang dibutuhkan untuk menyelesaikan baris 1465 - Diharapkan, karena ini adalah inti dari tindakan fungsi ini. Oleh karena itu, saya berharap operasi membutuhkan sebagian besar waktu.
Lihatlah elemen memSeries.head : ini menghitung sepotong data yang dikembalikan setiap kali. Fragmen data berubah hanya setelah setiap 120 penambahan, dan dengan demikian, kita dapat menyimpan fragmen head saat ini dalam struktur data seri . Ini memakan sebagian RAM ( yang akan saya bahas nanti ), tetapi menghemat sejumlah besar CPU. Dan secara keseluruhan, itu juga mempercepat Prometheus.
Kemudian mari kita lihat Head.processWALSamples :
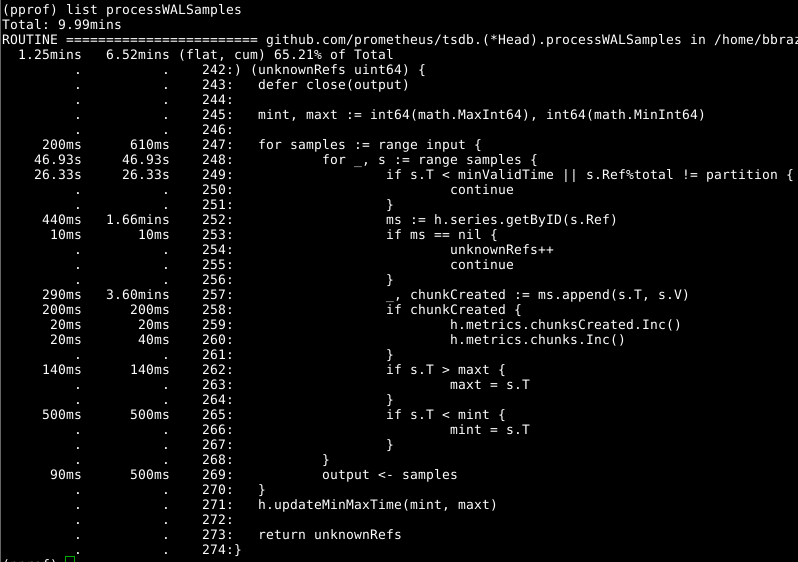
Add-on ini telah dioptimalkan di atas, jadi lihat pelakunya yang jelas berikutnya, getByID on line 252:
(kode)
Tampaknya ada semacam pemblokiran konflik, dan waktu terbuang untuk melakukan pencarian peta dua tingkat. Tembolok untuk setiap pengidentifikasi secara signifikan mengurangi indikator ini.
Layak Head.processWALSamples melihat Head.processWALSamples , dan Anda akan terkejut dengan berapa banyak waktu yang dihabiskan pada saluran 249. Mari kita kembali sedikit ke pertanyaan tentang bagaimana cara memuat WAL bekerja: Head.processWALSamples Head.processWALSamples dibuat untuk setiap CPU yang tersedia, di samping yang lain untuk membaca dan decoding WAL dari disk. Baris tersegmentasi oleh goroutine ini, sehingga konkurensi dapat menjadi keuntungan. Metode implementasi adalah sebagai berikut: semua sampel dikirim ke gorutin pertama, yang memproses elemen-elemen yang dibutuhkannya. Kemudian dia mengirimkan semua sampel ke gorutin kedua, yang memproses elemen-elemen yang dia butuhkan, dan seterusnya, sampai gorutin terakhir, Head.processWALSamples mengirimkan semua data kembali ke kontrol gorutin.
Sementara itu, add-on didistribusikan di seluruh kernel - yang Anda butuhkan - dan banyak tugas rangkap dilakukan di setiap gorutin, yang harus memproses semua sampel dan menghitung modul. Bahkan, semakin banyak core, semakin banyak pekerjaan yang digandakan. Saya membuat perubahan untuk mengelompokkan data dalam controller gourutin, sehingga setiap gorutin dari Head.processWALSamples sekarang hanya mendapatkan sampel yang dibutuhkan . Di komputer saya - 8 menjalankan gorutin - waktu kalkulasi sedikit dihemat, tetapi volume CPU-nya lumayan. Untuk komputer dengan sejumlah besar inti, manfaatnya harus lebih besar.
Dan lagi kita kembali ke pertanyaan: waktu untuk menghapus memori. Kami tidak dapat (biasanya) menentukan ini melalui profil CPU. Alih-alih, perhatikan profil memori dinamis untuk menemukan elemen yang menonjol. Ini membutuhkan beberapa perluasan kode di akhir program:
runtime.GC() hf, err := os.Create("heap.prof") if err != nil { log.Fatal(err) } pprof.WriteHeapProfile(hf)
Pembersihan memori formal dikaitkan dengan beberapa informasi dalam memori dinamis, pengumpulan dan pembersihannya hanya dilakukan selama pembersihan memori.
Kami kembali menggunakan alat yang sama, tetapi menentukan label -alloc_space , karena kami tertarik pada semua operasi alokasi memori, dan bukan hanya operasi yang menggunakan memori pada saat tertentu; dengan demikian, jalankan go tool pprof -alloc_space heap.prof . Jika Anda melihat distributor atas, pelakunya jelas:
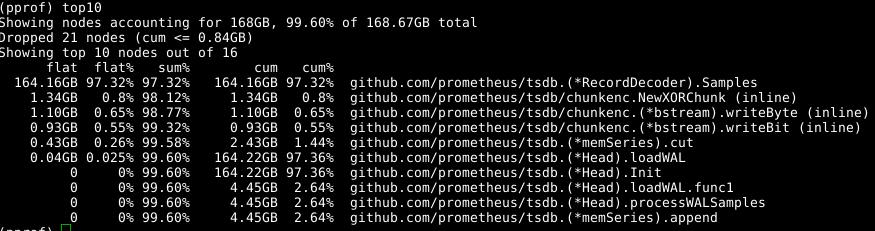
Lihatlah kodenya:
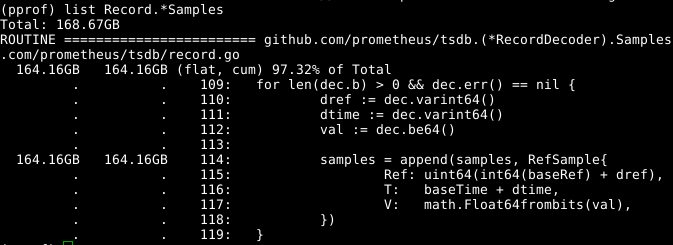
Susunan samples dapat diperluas tampaknya menjadi masalah. Jika kita dapat menggunakan kembali array pada saat yang sama dengan memanggil RecordDecoder.Samples . RecordDecoder.Samples , ini akan menghemat sejumlah besar memori. Ternyata kode itu dibuat dengan cara ini, tetapi kesalahan pengkodean kecil menyebabkan fakta bahwa itu tidak berfungsi. Jika Anda memperbaikinya , memori dihapus dalam 8 detik dari CPU, bukan 151 detik.
Hasil keseluruhan cukup nyata:
269.18user 10.69system 1:05.58elapsed 426%CPU (0avgtext+0avgdata 3529556maxresident)k 23174929inputs+70outputs (815major+1083172minor)pagefaults 0swap
Kami tidak hanya mengurangi waktu perhitungan hingga 4 kali, dan waktu CPU - sebesar 6,5 kali, tetapi juga jumlah memori yang digunakan berkurang lebih dari 2 GB.
Sepertinya semuanya sederhana, tetapi triknya adalah ini: Saya dengan sopan mencari-cari di basis kode dan menganalisis semuanya seolah-olah di belakang. Mempelajari kode, saya menemui jalan buntu beberapa kali, misalnya, ketika menghapus panggilan NumSamples , membaca dan mendekode di utas yang terpisah, serta dalam beberapa cara untuk melakukan segmentasi processWALSamples . Saya hampir yakin bahwa dengan mengatur jumlah gorutin, lebih banyak yang dapat dicapai, tetapi untuk tes ini harus dilakukan pada mesin yang lebih kuat daripada milikku, sehingga ada lebih banyak inti. Saya mencapai tujuan saya: produktivitas meningkat, dan saya menyadari bahwa lebih baik tidak membuat registri program terlalu besar, dan karena itu memutuskan untuk berhenti di sana.