Hai Nama saya Ivan Smurov, dan saya memimpin kelompok riset NLP di ABBYY. Anda dapat membaca tentang apa yang dilakukan grup kami di
sini . Saya baru-baru ini memberikan kuliah tentang Pemrosesan Bahasa Alami (NLP) di
School of Deep Learning - ini adalah grup di Fakultas Teknologi Matematika dan Ilmu Komputer Terapan di MIPT untuk siswa senior yang tertarik dalam pemrograman dan matematika. Mungkin tesis ceramah saya akan bermanfaat bagi seseorang, jadi saya akan membagikannya dengan Habr.
Karena tidak akan berhasil pada satu waktu, kami akan membagi artikel menjadi dua bagian. Hari ini saya akan berbicara tentang bagaimana jaringan saraf (atau pembelajaran dalam) digunakan dalam NLP. Pada bagian kedua artikel, kami akan fokus pada salah satu tugas NLP yang paling umum - tugas mengekstraksi entitas bernama (Named-entity recognition, NER) dan menganalisis secara rinci arsitektur solusi-solusinya.
Apa itu NLP?
Ini adalah berbagai tugas untuk memproses teks dalam bahasa alami (mis., Bahasa yang digunakan orang untuk berbicara dan menulis). Ada satu set tugas NLP klasik, solusinya adalah penggunaan praktis.
- Tugas pertama dan terpenting secara historis adalah terjemahan mesin. Ini telah dipraktikkan sejak lama, dan ada kemajuan luar biasa. Tetapi tugas untuk mendapatkan terjemahan yang sepenuhnya otomatis berkualitas tinggi (FAHQMT) tetap tidak terselesaikan. Di satu sisi, ini adalah mesin NLP, salah satu tugas terbesar yang dapat Anda lakukan.

- Tugas kedua adalah klasifikasi teks. Seperangkat teks diberikan, dan tugasnya adalah untuk mengklasifikasikan teks-teks ini ke dalam kategori. Yang mana Ini pertanyaan untuk korps.
Yang pertama dan salah satu cara paling praktis untuk menerapkannya dari sudut pandang praktis adalah klasifikasi huruf menjadi spam dan kasar (bukan spam).
Pilihan klasik lainnya adalah klasifikasi multikelas berita ke dalam kategori (rubrik) - kebijakan luar negeri, olahraga, top big, dll. Atau, katakanlah, Anda menerima surat dan ingin memisahkan pesanan dari toko online dari tiket pesawat dan pemesanan hotel.
Aplikasi klasik ketiga dari masalah klasifikasi teks adalah analisis sentimental. Misalnya, klasifikasi ulasan sebagai positif, negatif dan netral.
Karena ada begitu banyak kategori yang memungkinkan Anda dapat membagi teks menjadi, klasifikasi teks adalah salah satu tugas praktis NLP yang paling populer. - Tugas ketiga adalah mengambil entitas bernama, NER. Kami memilih di bagian teks yang sesuai dengan set entitas yang dipilih sebelumnya, misalnya, kita perlu menemukan semua lokasi, orang, dan organisasi dalam teks. Dalam teks "Ostap Bender - Direktur kantor" Horns and Hooves ", Anda harus memahami bahwa Ostap Bender adalah seseorang, dan" Horns and Hooves "adalah sebuah organisasi. Mengapa tugas ini diperlukan dalam praktik dan bagaimana menyelesaikannya, kita akan berbicara di bagian kedua artikel kami.
 Tugas keempat terhubung dengan yang ketiga - tugas mengekstraksi fakta dan hubungan (ekstraksi relasi). Misalnya, ada sikap kerja (Occupation). Dari teks "Ostap Bender - Direktur kantor" Horns and Hooves ", jelas bahwa pahlawan kita terhubung dengan hubungan profesional dengan" Horns and Hooves ". Hal yang sama dapat dikatakan dengan banyak cara lain: "Kantor Ostap Bender dipimpin oleh kantor" Horns and Hooves ", atau" Ostap Bender telah beralih dari putra sederhana Letnan Schmidt ke kepala kantor "Horns and Hooves". " Kalimat-kalimat ini berbeda tidak hanya dalam predikat, tetapi juga dalam struktur.
Tugas keempat terhubung dengan yang ketiga - tugas mengekstraksi fakta dan hubungan (ekstraksi relasi). Misalnya, ada sikap kerja (Occupation). Dari teks "Ostap Bender - Direktur kantor" Horns and Hooves ", jelas bahwa pahlawan kita terhubung dengan hubungan profesional dengan" Horns and Hooves ". Hal yang sama dapat dikatakan dengan banyak cara lain: "Kantor Ostap Bender dipimpin oleh kantor" Horns and Hooves ", atau" Ostap Bender telah beralih dari putra sederhana Letnan Schmidt ke kepala kantor "Horns and Hooves". " Kalimat-kalimat ini berbeda tidak hanya dalam predikat, tetapi juga dalam struktur.
Contoh hubungan lain yang sering disorot adalah Pembelian dan Penjualan, Kepemilikan, fakta kelahiran dengan atribut - tanggal, tempat, dll. (Kelahiran) dan beberapa lainnya.
Tugas tersebut tampaknya tidak memiliki aplikasi praktis yang jelas, tetapi, bagaimanapun, ia digunakan dalam penataan informasi yang tidak terstruktur. Selain itu, ini penting dalam sistem tanya jawab dan dialog, di mesin pencari - kapan pun Anda perlu menganalisis pertanyaan dan memahami jenis hubungannya, serta batasan apa yang ada pada jawabannya.

- Dua tugas berikutnya mungkin yang paling hype. Ini adalah sistem tanya jawab dan dialog (chat bots). Amazon Alexa, Alice adalah contoh klasik dari sistem percakapan. Agar mereka berfungsi dengan baik, banyak tugas NLP harus diselesaikan. Misalnya, klasifikasi teks membantu menentukan apakah kita termasuk dalam salah satu skenario obrolan berorientasi tujuan. Misalkan, "pertanyaan tentang nilai tukar." Ekstraksi relasi diperlukan untuk mengidentifikasi placeholder untuk templat skrip, dan tugas melakukan dialog tentang topik umum (“pembicara”) akan membantu kami dalam situasi di mana kami belum masuk ke dalam skenario mana pun.
Sistem tanya jawab juga merupakan hal yang dapat dimengerti dan bermanfaat. Anda mengajukan pertanyaan pada mobil, mobil mencari jawabannya di database atau badan teks. Contoh dari sistem tersebut adalah IBM Watson atau Wolfram Alpha. - Contoh lain dari masalah NLP klasik adalah sammarisasi. Pernyataan masalahnya sederhana - sistem input menerima teks yang besar, dan outputnya berupa teks yang lebih kecil, yang entah bagaimana mencerminkan konten yang besar. Sebagai contoh, sebuah mesin diperlukan untuk menghasilkan menceritakan kembali teks, namanya atau anotasi.

- Tugas populer lainnya adalah penambangan argumentasi, pencarian pembenaran dalam teks. Anda diberi fakta dan teks, Anda perlu menemukan pembenaran untuk fakta ini dalam teks.
Ini tidak berarti seluruh daftar tugas NLP. Ada lusinan dari mereka. Secara umum, segala sesuatu yang dapat dilakukan dengan teks dalam bahasa alami dapat dikaitkan dengan tugas-tugas NLP, hanya topik-topik yang tercantum adalah berdasarkan telinga, dan mereka memiliki aplikasi praktis yang paling jelas.
Mengapa sulit untuk menyelesaikan tugas-tugas NLP?
Kata-kata tugas tidak terlalu rumit, tetapi tugas itu sendiri sama sekali tidak sederhana, karena kami bekerja dengan bahasa alami. Fenomena polisemi (kata-kata polisemi memiliki makna awal yang sama) dan homonimi (kata-kata dengan makna berbeda diucapkan dan ditulis sama) adalah karakteristik dari bahasa alami. Dan jika seorang penutur asli bahasa Rusia memahami dengan baik bahwa
sambutan hangat memiliki sedikit kesamaan dengan
teknik bertarung , di satu sisi, dan
bir hangat , di sisi lain, sistem otomatis harus mempelajari ini untuk waktu yang lama. Mengapa lebih baik menerjemahkan "
Tekan bilah spasi untuk melanjutkan " ke membosankan "
Untuk melanjutkan, tekan bilah spasi " daripada "
Bilah pers ruang akan terus bekerja ."
- Polisemi: berhenti (proses atau bangunan), meja (organisasi atau objek), pelatuk (burung atau orang).
- Homonim: kunci, busur, kunci, kompor.

- Contoh klasik lain dari kompleksitas bahasa adalah kata ganti anafora. Sebagai contoh, marilah kita diberi teks " Petugas kebersihan dua jam salju, dia tidak puas ." Kata ganti "dia" dapat merujuk pada petugas kebersihan dan salju. Berdasarkan konteksnya, kita dengan mudah memahami bahwa dia adalah petugas kebersihan, bukan salju. Tetapi untuk mencapai hal itu komputer juga memahami hal ini dengan mudah tidaklah mudah. Masalah kata ganti anafora masih belum terpecahkan dengan baik, upaya aktif untuk meningkatkan kualitas keputusan berlanjut.
- Kompleksitas tambahan lainnya adalah elipsis. Misalnya, " Petya makan apel hijau, dan Masha makan apel merah ." Kami mengerti bahwa Masha makan apel merah. Namun, membuat mesin memahami ini juga tidak mudah. Sekarang tugas memulihkan elipsis sedang diselesaikan pada kasus-kasus kecil (beberapa ratus kalimat), dan pada mereka kualitas restorasi penuh terus terang lemah (urutan 0,5). Jelas bahwa untuk aplikasi praktis kualitas seperti itu tidak baik.
Ngomong-ngomong, tahun ini di konferensi
Dialog , lagu-lagu akan diadakan pada anafora dan gapping (sejenis elips) untuk bahasa Rusia. Untuk kedua tugas, case dirakit dengan volume beberapa kali lebih besar dari volume bangunan yang ada saat ini (apalagi, untuk gapping, volume case adalah urutan besarnya lebih besar dari volume case, tidak hanya untuk Rusia, tetapi untuk semua bahasa pada umumnya). Jika Anda ingin berpartisipasi dalam kompetisi di gedung-gedung ini,
klik di sini (dengan registrasi, tetapi tanpa SMS) .
Bagaimana Tugas NLP Dipecahkan
Tidak seperti pemrosesan gambar, Anda masih dapat menemukan artikel di NLP yang menjelaskan solusi yang menggunakan algoritma klasik seperti
SVM atau
Xgboost , bukan jaringan saraf, dan yang menunjukkan hasil yang tidak terlalu kalah dengan solusi canggih.
Namun, beberapa tahun yang lalu, jaringan saraf mulai mengalahkan model klasik. Penting untuk dicatat bahwa untuk sebagian besar tugas, solusi berdasarkan metode klasik adalah unik, sebagai aturan, tidak mirip dengan solusi untuk masalah lain baik dalam arsitektur maupun dalam cara pengumpulan dan pemrosesan atribut terjadi.
Namun, arsitektur jaringan saraf jauh lebih umum. Arsitektur jaringan itu sendiri, kemungkinan besar, juga berbeda, tetapi jauh lebih kecil, ada kecenderungan menuju universalisasi penuh. Namun, dengan fitur apa dan bagaimana tepatnya kita bekerja, sudah hampir sama untuk sebagian besar tugas NLP. Hanya lapisan terakhir dari jaringan saraf yang berbeda. Dengan demikian, kita dapat mengasumsikan bahwa satu pipa NLP telah terbentuk. Tentang bagaimana pengaturannya, sekarang kami akan memberi tahu Anda lebih banyak.
Pipeline nlp
Cara bekerja dengan tanda ini, yang kurang lebih sama untuk semua tugas.
Ketika berbicara tentang bahasa, unit dasar tempat kita bekerja adalah kata. Atau lebih tepatnya "token." Kami menggunakan istilah ini karena tidak terlalu jelas apa 2128506 - apakah ini sebuah kata atau tidak? Jawabannya tidak jelas. Token biasanya dipisahkan dari token lain dengan spasi atau tanda baca. Dan seperti yang dapat Anda pahami dari kesulitan yang kami jelaskan di atas, konteks setiap token sangat penting. Ada beberapa pendekatan yang berbeda, tetapi dalam 95% kasus, konteks yang dipertimbangkan selama kerja model adalah proposal yang menyertakan token awal.
Banyak tugas umumnya diselesaikan di tingkat proposal. Misalnya, terjemahan mesin. Lebih sering daripada tidak, kami hanya menerjemahkan satu kalimat dan tidak menggunakan konteks yang lebih luas sama sekali. Ada tugas-tugas di mana ini tidak terjadi, misalnya, sistem dialog. Penting untuk mengingat apa yang ditanyakan sistem sebelumnya sehingga dapat menjawab pertanyaan. Namun, tawaran tersebut juga merupakan unit utama yang kami gunakan untuk bekerja.
Oleh karena itu, dua langkah pertama dari pipeline yang dilakukan untuk menyelesaikan hampir semua tugas adalah segmentasi (membagi teks menjadi kalimat) dan tokenization (membagi kalimat menjadi token, yaitu, kata-kata individual). Ini dilakukan dengan algoritma sederhana.
Selanjutnya, Anda perlu menghitung karakteristik masing-masing token. Biasanya, ini terjadi dalam dua tahap. Yang pertama adalah menghitung atribut token konteks-independen. Ini adalah serangkaian tanda yang sama sekali tidak bergantung pada kata-kata lain di sekitar token kita. Atribut independen konteks umum adalah:
- embeddings
- tanda-tanda simbolik
- fitur tambahan khusus untuk tugas atau bahasa tertentu
Kita akan berbicara tentang embeddings dan tanda simbolik secara lebih rinci di bawah ini (tentang tanda simbolik - bukan hari ini, tetapi di bagian kedua artikel kami), tetapi untuk sekarang mari kita berikan contoh kemungkinan tanda tambahan.
Salah satu fitur yang paling umum digunakan adalah bagian ucapan atau tag POS (bagian ucapan). Fitur tersebut mungkin penting untuk menyelesaikan banyak masalah, misalnya, tugas parsing. Untuk bahasa dengan morfologi yang kompleks, seperti bahasa Rusia, karakter morfologis juga penting: misalnya, dalam hal ini kata benda, kata sifat macam apa. Dari sini kita dapat menarik kesimpulan berbeda tentang struktur proposal. Juga, morfologi diperlukan untuk lemmatization (pengurangan kata ke bentuk awal), dengan bantuan yang kita dapat mengurangi dimensi ruang fitur, dan oleh karena itu analisis morfologi secara aktif digunakan untuk sebagian besar masalah NLP.
Ketika kita memecahkan masalah di mana interaksi antara objek yang berbeda itu penting (misalnya, dalam tugas ekstraksi relasi atau ketika membuat sistem tanya-jawab), kita perlu tahu banyak tentang struktur proposal. Ini membutuhkan penguraian. Di sekolah, semua orang melakukan parsing kalimat untuk subjek, predikat, penambahan, dll. Analisis sintaksis adalah sesuatu dalam semangat ini, tetapi lebih rumit.
Contoh lain dari fitur tambahan adalah posisi token dalam teks. Kita dapat mengetahui apriori bahwa beberapa entitas lebih sering ditemukan di awal teks atau sebaliknya di akhir.
Semua bersama - embeddings, simbolik dan tanda tambahan - membentuk vektor tanda tanda yang tidak tergantung pada konteksnya.
Fitur yang sensitif terhadap konteks
Tanda-tanda token konteks adalah seperangkat tanda yang berisi informasi tidak hanya tentang token itu sendiri, tetapi juga tentang tetangganya. Ada berbagai cara untuk menghitung gejala-gejala ini. Dalam algoritme klasik, orang-orang sering hanya berjalan di dekat "jendela": mereka mengambil beberapa (misalnya, tiga) token ke yang asli dan beberapa token setelahnya, dan kemudian menghitung semua tanda di jendela tersebut. Pendekatan ini tidak dapat diandalkan, karena masing-masing informasi penting untuk analisis berada pada jarak yang lebih besar daripada jendela, kita mungkin kehilangan sesuatu.
Oleh karena itu, sekarang semua fitur konteks sensitif dihitung pada tingkat proposal dengan cara standar: menggunakan jaringan saraf berulang dua arah LSTM atau GRU. Untuk mendapatkan atribut token konteks-sensitif dari konteks-independen, atribut konteks-independen dari semua token penawaran diajukan ke Bidirectional RNN (tunggal atau multi-layer). Output dari Bidirectional RNN pada saat ke-i dalam waktu adalah tanda konteks-sensitif dari token saya, yang berisi informasi tentang kedua token sebelumnya (karena informasi ini terkandung dalam nilai ke-ke-R dari direct RNN), dan tentang yang berikutnya (t .k. informasi ini terkandung dalam nilai yang sesuai dari RNN terbalik).
Selanjutnya, untuk setiap tugas individu, kami melakukan sesuatu yang berbeda, tetapi beberapa lapisan pertama - hingga Bidirectional RNN, dapat digunakan untuk hampir semua tugas.
Metode memperoleh fitur ini disebut pipa NLP.
Perlu dicatat bahwa selama 2 tahun terakhir, para peneliti telah secara aktif berusaha meningkatkan pipa NLP - keduanya dalam hal kecepatan (misalnya, transformator - arsitektur berbasis perhatian sendiri yang tidak mengandung RNN dan oleh karena itu dapat belajar dan menerapkan lebih cepat), dan dengan sudut pandang tanda-tanda yang digunakan (sekarang mereka secara aktif menggunakan tanda-tanda berdasarkan model bahasa pra-dilatih, misalnya
ELMo , atau mereka menggunakan lapisan pertama dari model bahasa pra-dilatih dan melatihnya dalam kasus yang tersedia untuk tugas -
ULMFit ,
BERT ).
Pernikahan berbentuk kata
Mari kita lihat lebih dekat apa itu embedding. Secara kasar, penyematan adalah representasi singkat dari konteks sebuah kata. Mengapa penting untuk mengetahui konteks suatu kata? Karena kami percaya pada hipotesis distribusi - bahwa kata-kata yang memiliki arti yang sama digunakan dalam konteks yang sama.
Mari kita coba memberikan definisi yang kuat tentang penanaman. Embedding adalah pemetaan dari vektor diskrit fitur kategorikal ke dalam vektor kontinu dengan dimensi yang telah ditentukan.
Contoh kanonik dari embedding adalah embedding kata (embedding bentuk kata).
Apa yang biasanya bertindak sebagai vektor fitur diskrit? Vektor Boolean yang sesuai dengan semua nilai yang mungkin dari kategori tertentu (misalnya, semua bagian yang memungkinkan atau semua kata yang mungkin dari beberapa kamus terbatas).
Untuk embeddings bentuk kata, kategori ini biasanya merupakan indeks kata dalam kamus. Katakanlah ada kamus dengan dimensi 100 ribu. Dengan demikian, setiap kata memiliki vektor tanda-tanda tersendiri - vektor Boolean dimensi 100 ribu, di mana di satu tempat (indeks kata dalam kamus kami) adalah satu, dan sisanya nol.
Mengapa kami ingin memetakan vektor fitur diskrit kami ke dimensi yang diberikan terus menerus? Karena vektor dengan dimensi 100 ribu tidak terlalu nyaman digunakan untuk perhitungan, tetapi vektor bilangan bulat dimensi 100, 200, atau, misalnya, 300, jauh lebih nyaman.
Pada prinsipnya, kami mungkin tidak mencoba untuk memaksakan pembatasan tambahan pada pemetaan semacam itu. Tetapi karena kita sedang membangun pemetaan seperti itu, mari kita coba untuk memastikan bahwa vektor dari kata-kata yang memiliki makna yang sama juga dekat dalam beberapa hal. Ini dilakukan dengan menggunakan jaringan umpan maju sederhana.
Pelatihan Penanaman
Bagaimana cara melatih embeddings? Kami mencoba menyelesaikan masalah memulihkan kata demi konteks (atau sebaliknya, memulihkan konteks dengan kata). Dalam kasus yang paling sederhana, kita mendapatkan indeks dalam kamus kata sebelumnya (vektor Boolean dari dimensi kamus) sebagai input dan mencoba menentukan indeks dalam kamus kata kita. Ini dilakukan dengan menggunakan kisi-kisi dengan arsitektur yang sangat sederhana: dua lapisan yang terhubung sepenuhnya. Pertama datang lapisan yang sepenuhnya terhubung dari vektor Boolean dari dimensi kamus ke lapisan tersembunyi dari dimensi embedding (yaitu, hanya mengalikan vektor Boolean dengan matriks dari dimensi yang diinginkan). Dan sebaliknya, lapisan yang sepenuhnya terhubung dengan softmax dari lapisan dimensi tersembunyi yang disematkan ke vektor dimensi kamus. Berkat fungsi aktivasi softmax, kami mendapatkan distribusi probabilitas kata kami dan dapat memilih opsi yang paling mungkin.
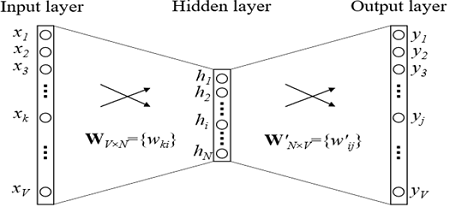
Dalam model yang digunakan dalam praktiknya, arsitekturnya lebih kompleks, tetapi tidak banyak. Perbedaan utama adalah bahwa kita menggunakan bukan satu vektor dari konteks untuk mendefinisikan kata kita, tetapi beberapa (misalnya, semua yang ada di jendela ukuran 3). Pilihan yang sedikit lebih populer adalah ketika kita mencoba untuk memprediksi bukan kata demi konteks, tetapi lebih pada konteks dengan kata. Pendekatan ini disebut Lewati-gram.
Mari kita beri contoh penerapan tugas yang diselesaikan selama pelatihan embeddings (dalam varian CBOW, prediksi kata berdasarkan konteks). Misalnya, anggap konteks token terdiri dari 2 kata sebelumnya.
Jika kita mempelajari tentang kumpulan teks tentang sastra Rusia modern dan konteksnya terdiri dari kata "penyair Marina", maka kemungkinan besar kata berikutnya yang paling mungkin adalah kata "Tsvetaeva".Kami menekankan sekali lagi, embeddings hanya dilatih pada tugas memprediksi kata demi konteks (atau sebaliknya konteks dengan kata), dan mereka dapat digunakan dalam situasi di mana kita perlu menghitung atribut token.Apapun pilihan yang kita pilih, arsitektur embeddings sangat sederhana, dan nilai tambahnya adalah mereka dapat dilatih tentang data yang tidak ditandai (memang, kami hanya menggunakan informasi tentang tetangga token kami, dan hanya teks itu sendiri yang diperlukan untuk menentukannya). Embeddings yang dihasilkan adalah konteks rata-rata untuk korpus seperti itu.Bentuk kata yang tertanam, sebagai suatu peraturan, dilatih pada korps terbesar dan paling mudah diakses untuk pelatihan. Biasanya ini semua Wikipedia dalam bahasa tersebut, karena dapat dikempiskan, dan setiap kasus lain yang bisa Anda dapatkan.Pertimbangan serupa digunakan dalam pra-pelatihan untuk arsitektur modern yang disebutkan di atas - ELMo, ULMFit, BERT. Mereka juga menggunakan data yang tidak berlabel untuk pelatihan, dan karena itu mereka belajar tentang bangunan terbesar yang tersedia (walaupun arsitekturnya sendiri, tentu saja, lebih rumit daripada dengan embeddings klasik).Mengapa embeddings?
Seperti yang telah disebutkan, ada 2 alasan utama untuk menggunakan embeddings.- -, , , - 100 . – : , , .
- -, . -. . . , , . , , . . , , .
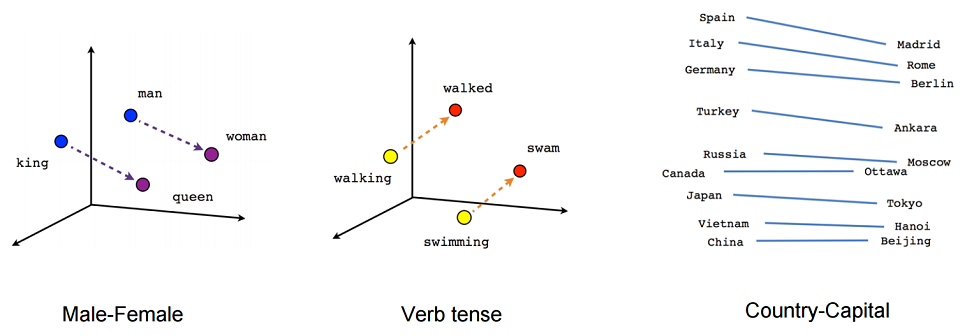 Tetapi orang tidak perlu berpikir bahwa aritmatika vektor seperti itu bekerja dengan andal. Dalam artikel di mana embedding diperkenalkan, ada contoh bahwa Angela mengacu pada Merkel dengan cara yang sama seperti Barack ke Obama, Nicolas ke Sarkozy dan Putin ke Medvedev. Oleh karena itu, mengandalkan aritmatika ini tidak sepadan, meskipun masih penting, dan jauh lebih mudah bagi komputer ketika mengetahui informasi ini, bahkan jika mengandung ketidakakuratan.Pada bagian selanjutnya dari artikel kami, kami akan berbicara tentang masalah NER. Kita akan berbicara tentang apa tugas ini, mengapa itu dibutuhkan dan perangkap apa yang mungkin tersembunyi dalam solusinya. Kita akan berbicara secara terperinci tentang bagaimana masalah ini diselesaikan dengan menggunakan metode klasik, bagaimana itu mulai diselesaikan dengan menggunakan jaringan saraf, dan kami akan menjelaskan arsitektur modern yang diciptakan untuk menyelesaikannya.
Tetapi orang tidak perlu berpikir bahwa aritmatika vektor seperti itu bekerja dengan andal. Dalam artikel di mana embedding diperkenalkan, ada contoh bahwa Angela mengacu pada Merkel dengan cara yang sama seperti Barack ke Obama, Nicolas ke Sarkozy dan Putin ke Medvedev. Oleh karena itu, mengandalkan aritmatika ini tidak sepadan, meskipun masih penting, dan jauh lebih mudah bagi komputer ketika mengetahui informasi ini, bahkan jika mengandung ketidakakuratan.Pada bagian selanjutnya dari artikel kami, kami akan berbicara tentang masalah NER. Kita akan berbicara tentang apa tugas ini, mengapa itu dibutuhkan dan perangkap apa yang mungkin tersembunyi dalam solusinya. Kita akan berbicara secara terperinci tentang bagaimana masalah ini diselesaikan dengan menggunakan metode klasik, bagaimana itu mulai diselesaikan dengan menggunakan jaringan saraf, dan kami akan menjelaskan arsitektur modern yang diciptakan untuk menyelesaikannya.