
Kembali pada awal 2018, sebuah artikel diterbitkan Belajar Penguatan Jauh Belum Bekerja ("Belajar dengan penguatan belum berfungsi."). Keluhan utama adalah bahwa algoritma pembelajaran modern dengan penguatan membutuhkan jumlah waktu yang sama untuk menyelesaikan masalah sebagai pencarian acak biasa.
Apakah ada yang berubah sejak saat itu? Tidak.
Pembelajaran yang diperkuat dianggap sebagai salah satu dari tiga jalur utama untuk membangun AI yang kuat. Tetapi kesulitan yang dihadapi oleh bidang pembelajaran mesin ini, dan metode yang para ilmuwan coba atasi dengan kesulitan ini, menunjukkan bahwa mungkin ada masalah mendasar dengan pendekatan ini sendiri.
Tunggu, apa satu dari tiga artinya? Apa dua lainnya?
Mengingat keberhasilan jaringan saraf dalam beberapa tahun terakhir dan analisis tentang bagaimana mereka bekerja dengan kemampuan kognitif tingkat tinggi, yang sebelumnya dianggap hanya karakteristik manusia dan hewan yang lebih tinggi, hari ini di komunitas ilmiah ada pendapat bahwa ada tiga pendekatan utama untuk menciptakan AI yang kuat di dasar jaringan saraf, yang dapat dianggap lebih atau kurang realistis:
1. Pengolah Kata
Dunia telah mengumpulkan sejumlah besar buku dan teks di Internet, termasuk buku teks dan buku referensi. Teks ini nyaman dan cepat untuk diproses di komputer. Secara teoritis, susunan teks ini harus cukup untuk melatih AI percakapan yang kuat.
Tersirat bahwa dalam susunan teks ini struktur dunia yang lengkap tercermin (setidaknya dijelaskan dalam buku teks dan buku referensi). Tapi ini sama sekali bukan fakta. Teks sebagai bentuk penyajian informasi sangat dipisahkan dari dunia tiga dimensi yang nyata dan perjalanan waktu kita hidup.
Contoh bagus AI yang dilatih pada larik teks adalah bot obrolan dan penerjemah otomatis. Karena untuk menerjemahkan teks Anda perlu memahami arti dari frasa dan menceritakannya kembali dengan kata-kata baru (dalam bahasa lain). Ada kesalahpahaman umum bahwa tata bahasa dan aturan sintaksis, termasuk deskripsi dari semua pengecualian yang mungkin, sepenuhnya menggambarkan bahasa tertentu. Ini tidak benar. Bahasa hanyalah alat bantu dalam kehidupan, ia mudah berubah dan beradaptasi dengan situasi baru.
Masalah dengan pemrosesan teks (bahkan oleh sistem pakar, bahkan jaringan saraf) adalah bahwa tidak ada seperangkat aturan, frasa mana yang harus diterapkan dalam situasi yang mana. Harap dicatat - bukan aturan untuk membangun frasa sendiri (apa yang dilakukan tata bahasa dan sintaksis), tetapi frasa apa dalam situasi yang mana. Dalam situasi yang sama, orang mengucapkan frasa dalam berbagai bahasa yang umumnya tidak saling terkait dalam hal struktur bahasa. Bandingkan frasa dengan kejutan yang luar biasa: "Ya Tuhan!" dan "o sial!". Nah, dan bagaimana cara membuat korespondensi di antara mereka, mengetahui model bahasa? Tidak mungkin. Itu terjadi secara kebetulan secara historis. Anda perlu mengetahui situasi dan apa yang biasanya mereka ucapkan dalam bahasa tertentu. Karena itulah penerjemah otomatis sangat tidak sempurna.
Apakah pengetahuan ini dapat dibedakan murni dari berbagai teks tidak diketahui. Tetapi jika penerjemah otomatis menerjemahkan dengan sempurna tanpa membuat kesalahan konyol dan konyol, maka ini akan menjadi bukti bahwa membuat AI yang kuat hanya berdasarkan teks adalah mungkin.
2. Pengenalan Gambar
Lihat gambar ini

Melihat foto ini, kami memahami bahwa pemotretan dilakukan pada malam hari. Dilihat dari bendera, angin berhembus dari kanan ke kiri. Dan dilihat dari lalu lintas kanan, kasus ini tidak terjadi di Inggris atau Australia. Tidak satu pun dari informasi ini ditunjukkan secara eksplisit dalam piksel gambar, ini adalah pengetahuan eksternal. Dalam foto hanya ada tanda-tanda dimana kita bisa menggunakan pengetahuan yang diperoleh dari sumber lain.
Apakah Anda tahu ada yang melihat gambar ini?Tentang itu dan pidatonya ... Dan temukan dirimu seorang gadis, akhirnya
Karena itu, diyakini bahwa jika Anda melatih jaringan saraf untuk mengenali objek dalam sebuah gambar, maka ia akan memiliki gagasan internal tentang bagaimana dunia nyata bekerja. Dan pandangan ini, yang diperoleh dari foto-foto, pasti akan sesuai dengan dunia nyata dan nyata kita. Tidak seperti array teks di mana ini tidak dijamin.
Nilai jaringan saraf yang dilatih pada jajaran foto-foto ImageNet (dan sekarang OpenImages V4 , COCO , KITTI , BDD100K dan lainnya) sama sekali bukan fakta pengakuan kucing dalam sebuah foto. Dan itu disimpan di lapisan kedua dari belakang. Di sinilah seperangkat fitur tingkat tinggi yang menggambarkan dunia kita berada. Vektor 1024 angka cukup untuk mendapatkan deskripsi dari 1000 kategori objek yang berbeda dengan akurasi 80% (dan dalam 95% kasus, jawaban yang benar adalah dalam 5 opsi terdekat). Pikirkan saja itu.
Itulah sebabnya fitur-fitur ini dari lapisan kedua dari belakang begitu berhasil digunakan dalam tugas yang sama sekali berbeda dalam visi komputer. Melalui Transfer Learning dan Fine Tuning. Dari vektor ini dalam 1024 angka Anda bisa mendapatkan, misalnya, peta kedalaman dari gambar
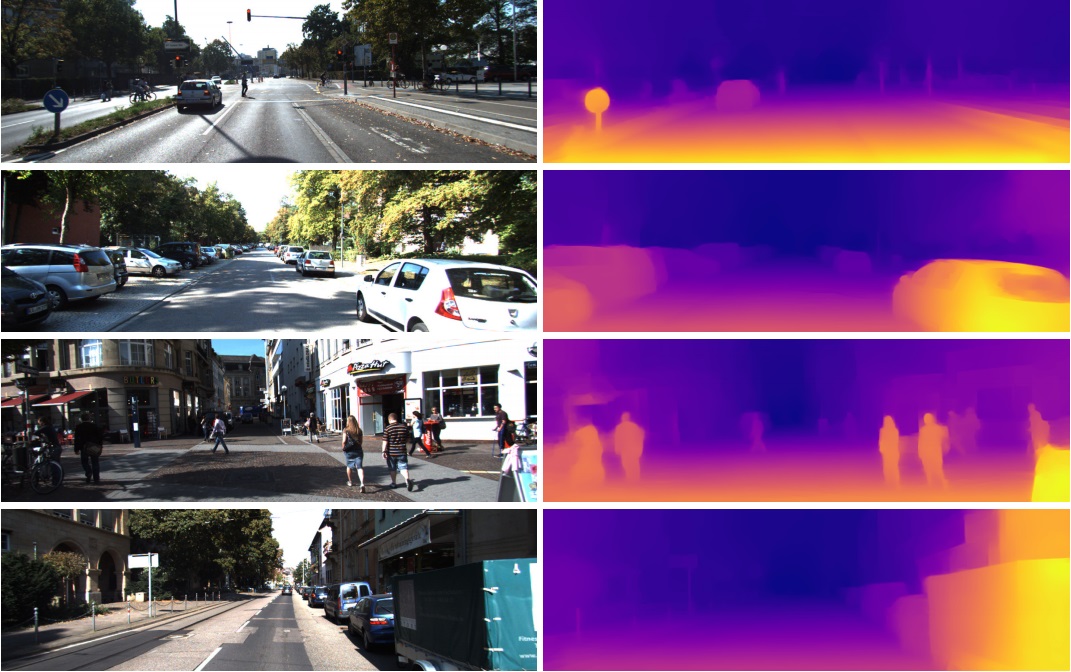
(contoh dari pekerjaan di mana jaringan Densenet-169 pra-terlatih yang praktis tidak berubah digunakan)
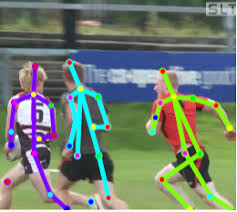
Atau menentukan pose seseorang. Ada banyak aplikasi.
Akibatnya, pengenalan gambar berpotensi digunakan untuk membuat AI yang kuat, karena itu benar-benar mencerminkan model dunia nyata kita. Satu langkah dari fotografi ke video, dan video adalah hidup kita, karena kita mendapatkan sekitar 99% informasi secara visual.
Tapi dari foto itu benar-benar tidak bisa dipahami bagaimana memotivasi jaringan saraf untuk berpikir dan menarik kesimpulan. Dia dapat dilatih untuk menjawab pertanyaan seperti "berapa banyak pensil di atas meja?" (kelas tugas ini disebut Penjawaban Visual, contoh dari set data seperti itu: https://visualqa.org ). Atau berikan deskripsi tekstual tentang apa yang terjadi di foto. Ini adalah kelas tugas Pengambilan Gambar .

Tetapi apakah kecerdasan ini? Setelah mengembangkan pendekatan ini, dalam waktu dekat, jaringan saraf akan dapat menjawab pertanyaan video seperti "Dua burung pipit duduk di kabel, salah satunya terbang, berapa banyak burung gereja yang tersisa?". Ini adalah matematika nyata, dalam kasus yang sedikit lebih rumit, tidak dapat diakses oleh hewan dan pada tingkat pendidikan sekolah manusia. Terutama jika, kecuali burung pipit, akan ada payudara yang duduk di sebelah mereka, tetapi mereka tidak perlu diperhitungkan, karena pertanyaannya hanya tentang burung pipit. Ya, itu pasti kecerdasan.
3. Pembelajaran Penguatan
Idenya sangat sederhana: untuk mendorong tindakan yang mengarah pada hadiah, dan untuk menghindari mengarah pada kegagalan. Ini adalah cara belajar universal dan, jelas, itu pasti dapat mengarah pada penciptaan AI yang kuat. Oleh karena itu, ada begitu banyak minat dalam Penguatan Pembelajaran dalam beberapa tahun terakhir.
Campur tapi jangan kocokTentu saja, yang terbaik adalah membuat AI yang kuat dengan menggabungkan ketiga pendekatan. Dalam gambar dan dengan pelatihan penguatan, Anda bisa mendapatkan AI tingkat hewan. Dan menambahkan nama teks objek ke gambar (lelucon, tentu saja - memaksa AI untuk menonton video di mana orang berinteraksi dan berbicara, seperti ketika mengajar bayi), dan melatih kembali pada susunan teks untuk mendapatkan pengetahuan (analog dari sekolah dan universitas kami), secara teori Anda bisa mendapatkan AI tingkat manusia. Mampu bicara.
Pembelajaran yang diperkuat memiliki satu nilai tambah yang besar. Dalam simulator, Anda dapat membuat model dunia yang disederhanakan. Jadi, untuk figur manusia, hanya 17 derajat kebebasan sudah cukup, bukan 700 pada orang yang hidup (jumlah otot). Oleh karena itu, dalam simulator Anda dapat menyelesaikan masalah dalam dimensi yang sangat kecil.
Ke depan, algoritma Reinforcement Learning modern tidak dapat secara sewenang-wenang mengendalikan model seseorang, bahkan dengan 17 derajat kebebasan. Artinya, mereka tidak dapat menyelesaikan masalah optimisasi, di mana terdapat 44 angka pada input dan 17 pada input. Hal ini dimungkinkan untuk melakukan ini hanya dalam kasus yang sangat sederhana, dengan penyesuaian kondisi awal dan hiperparameter. Dan bahkan dalam kasus ini, misalnya, untuk mengajarkan model humanoid dengan 17 derajat kebebasan untuk menjalankan, dan mulai dari posisi berdiri (yang jauh lebih sederhana), Anda memerlukan beberapa hari perhitungan pada GPU yang kuat. Dan kasus-kasus yang sedikit lebih rumit, misalnya, belajar bangun dari pose yang sewenang-wenang, mungkin tidak pernah belajar sama sekali. Ini sebuah kegagalan.
Selain itu, semua algoritma Penguatan Pembelajaran bekerja dengan jaringan saraf kecil yang menyedihkan, tetapi mereka tidak dapat mengatasi pembelajaran yang besar. Jaringan konvolusi besar hanya digunakan untuk mengurangi dimensi gambar menjadi beberapa fitur, yang diumpankan ke algoritma pembelajaran dengan penguatan. Humanoid berjalan yang sama dikendalikan oleh jaringan Feed Forward dengan dua atau tiga lapisan 128 neuron. Benarkah? Dan berdasarkan ini, apakah kita mencoba membangun AI yang kuat?
Untuk mencoba memahami mengapa ini terjadi dan apa yang salah dengan pembelajaran penguatan, Anda harus terlebih dahulu membiasakan diri dengan arsitektur dasar dalam Pembelajaran Penguatan modern.
Struktur fisik otak dan sistem saraf disetel oleh evolusi ke jenis hewan tertentu dan kondisi kehidupannya. Jadi, dalam perjalanan evolusi, seekor lalat mengembangkan sistem saraf dan kerja neurotransmitter di ganglia (analog otak pada serangga) dengan cepat untuk menghindari pemukul lalat. Yah, bukan dari pemukul lalat, tetapi dari burung yang telah memancing selama 400 juta tahun (hanya bercanda, burung itu sendiri muncul 150 juta tahun yang lalu, kemungkinan besar dari katak 360 juta tahun). Seekor badak cukup seperti sistem saraf dan otak untuk perlahan-lahan berbalik ke arah target dan mulai berlari. Dan di sana, seperti yang mereka katakan, badak memiliki penglihatan yang buruk, tetapi ini bukan masalahnya.
Tetapi di samping evolusi, setiap individu tertentu, mulai dari kelahiran dan sepanjang hidup, bekerja dengan tepat mekanisme pembelajaran yang biasa dengan penguatan. Dalam kasus mamalia, dan serangga juga , sistem dopamin bekerja dengan baik. Karyanya penuh dengan rahasia dan nuansa, tetapi semuanya bermuara pada kenyataan bahwa dalam hal menerima penghargaan, sistem dopamin, melalui mekanisme memori, entah bagaimana memperbaiki koneksi antara neuron yang aktif segera sebelumnya. Ini adalah bagaimana memori asosiatif terbentuk.
Yang, karena asosiatifitasnya, kemudian digunakan dalam pengambilan keputusan. Sederhananya, jika situasi saat ini (neuron aktif saat ini dalam situasi ini) melalui memori asosiatif mengaktifkan neuron kesenangan, maka individu tersebut memilih tindakan yang dia lakukan dalam situasi yang sama dan yang dia ingat. “Memilih tindakan” adalah definisi yang buruk. Tidak ada pilihan. Cukup diaktifkan neuron memori kesenangan, difiksasi oleh sistem dopamin untuk situasi tertentu, secara otomatis mengaktifkan neuron motorik, yang menyebabkan kontraksi otot. Ini jika tindakan segera diperlukan.
Pembelajaran artifisial dengan penguatan, sebagai bidang pengetahuan, perlu untuk memecahkan kedua masalah ini:
1. Pilih arsitektur jaringan saraf (apa yang telah dilakukan evolusi untuk kita)
Berita baiknya adalah bahwa fungsi kognitif yang lebih tinggi dilakukan dalam neokorteks pada mamalia (dan pada striatum pada hewan ) dilakukan dalam struktur yang kurang lebih seragam. Rupanya, ini tidak memerlukan beberapa "arsitektur" yang ditentukan dengan kaku.
Keragaman daerah otak mungkin karena alasan historis murni. Ketika, ketika mereka berevolusi, bagian-bagian baru otak tumbuh di atas bagian-bagian dasar yang tersisa dari hewan-hewan pertama. Dengan prinsip kerjanya - jangan sentuh. Di sisi lain, pada orang yang berbeda, bagian otak yang sama bereaksi terhadap situasi yang sama. Ini dapat dijelaskan oleh asosiasi (fitur dan "neuron nenek" yang terbentuk secara alami di tempat-tempat ini selama proses pembelajaran), dan fisiologi. Jalur pensinyalan yang dikodekan dalam gen mengarah tepat ke area ini. Tidak ada konsensus, tetapi Anda dapat membaca, misalnya, artikel terbaru ini: "Kecerdasan biologis dan buatan . "
2. Pelajari cara melatih jaringan saraf sesuai dengan prinsip-prinsip pembelajaran dengan penguatan
Inilah yang terutama dilakukan Pembelajaran Penguatan modern. Dan apa keberhasilannya? Tidak juga.
Pendekatan naif
Tampaknya sangat sederhana untuk melatih jaringan saraf dengan penguatan: kita melakukan tindakan acak, dan jika kita mendapatkan hadiah, maka kita menganggap tindakan yang diambil sebagai "referensi". Kami menempatkan mereka pada output dari jaringan saraf sebagai label standar dan melatih jaringan saraf dengan metode propagasi balik kesalahan sehingga menghasilkan output yang persis seperti itu. Pelatihan jaringan saraf yang paling umum. Dan jika tindakan menyebabkan kegagalan, maka abaikan saja kasus ini, atau tekan tindakan ini (kami menetapkan beberapa yang lain sebagai keluaran, misalnya, tindakan acak lainnya). Secara umum, ide ini mengulangi sistem dopamin.
Tetapi jika Anda mencoba untuk melatih jaringan saraf apa pun dengan cara ini, tidak peduli betapa rumitnya arsitektur, rekursif, konvolusional, atau distribusi langsung biasa, maka ... Itu tidak akan berhasil!
Mengapa Tidak dikenal
Diyakini bahwa sinyal yang berguna sangat kecil sehingga hilang terhadap latar belakang kebisingan. Oleh karena itu, jaringan tidak mempelajari metode standar untuk menyebarkan kesalahan. Hadiah jarang terjadi, mungkin sekali dalam ratusan atau bahkan ribuan langkah. Dan bahkan LSTM mengingat maksimal 100-500 poin dalam sejarah, dan kemudian hanya dalam tugas yang sangat sederhana. Tetapi pada yang lebih kompleks, jika ada 10-20 poin dalam sejarah, maka itu sudah bagus.
Tetapi akar masalahnya adalah dalam imbalan yang sangat langka (setidaknya dalam tugas-tugas yang bernilai praktis). Saat ini, kami tidak tahu bagaimana cara melatih jaringan saraf yang akan mengingat kasus-kasus terisolasi. Apa yang diatasi otak dengan kecemerlangan. Anda dapat mengingat sesuatu yang terjadi hanya sekali seumur hidup. Dan omong-omong, sebagian besar pelatihan dan pekerjaan intelek dibangun hanya pada kasus-kasus seperti itu.
Ini seperti ketidakseimbangan kelas yang mengerikan dari bidang pengenalan gambar. Tidak ada cara untuk menangani hal ini. Yang terbaik yang bisa mereka dapatkan sejauh ini adalah dengan mengirimkan ke input jaringan, bersama dengan situasi baru, situasi sukses dari masa lalu yang disimpan dalam buffer khusus buatan. Artinya, untuk terus mengajar tidak hanya kasus baru, tetapi juga yang lama berhasil. Secara alami, buffer seperti itu tidak dapat ditingkatkan secara tak terbatas, dan tidak jelas apa tepatnya yang harus disimpan di dalamnya. Masih mencoba entah bagaimana untuk sementara memperbaiki jalur di dalam jaringan saraf, yang aktif selama kasus yang sukses, sehingga pelatihan selanjutnya tidak menimpa mereka. Analogi yang agak dekat dengan apa yang terjadi di otak, menurut saya, meskipun mereka belum mencapai banyak keberhasilan dalam arah ini juga. Karena tugas-tugas baru yang terlatih dalam perhitungannya menggunakan hasil neuron yang meninggalkan jalur beku, sebagai akibatnya, sinyal hanya mengganggu yang beku baru, dan tugas lama berhenti bekerja. Ada pendekatan aneh lain: untuk melatih jaringan dengan contoh / tugas baru hanya dalam arah ortogonal untuk tugas sebelumnya ( https://arxiv.org/abs/1810.01256 ). Ini tidak menimpa pengalaman sebelumnya, tetapi secara drastis membatasi kapasitas jaringan.
Kelas algoritma terpisah yang dirancang untuk menangani bencana ini (dan pada saat yang sama memberi harapan untuk mencapai AI yang kuat) sedang dikembangkan di Meta-Learning. Ini adalah upaya untuk mengajarkan jaringan saraf beberapa tugas sekaligus. Tidak dalam arti bahwa ia mengenali gambar yang berbeda dalam satu tugas, yaitu, tugas yang berbeda di domain yang berbeda (masing-masing dengan distribusi sendiri dan lanskap solusi). Katakan, kenali gambar dan naiklah sepeda sekaligus. Sejauh ini, kesuksesan juga tidak terlalu baik, karena biasanya semuanya tergantung pada persiapan jaringan saraf terlebih dahulu dengan bobot universal umum, dan kemudian dengan cepat, hanya dalam beberapa langkah penurunan gradien, untuk menyesuaikannya dengan tugas tertentu. Contoh algoritma pembelajaran-meta adalah MAML dan Reptile .
Secara umum, hanya masalah ini (ketidakmampuan untuk belajar dari satu contoh sukses) yang mengakhiri pelatihan modern dengan penguatan. Semua kekuatan jaringan saraf sebelum fakta menyedihkan ini sejauh ini tidak berdaya.
Fakta ini, bahwa cara paling sederhana dan paling jelas tidak berhasil, memaksa para peneliti untuk kembali ke Reinforcement Learning berbasis tabel klasik. Yang, sebagai ilmu, muncul di jaman dahulu kala, ketika jaringan saraf bahkan tidak dalam proyek. Tapi sekarang, alih-alih secara manual menghitung nilai-nilai dalam tabel dan rumus, mari kita gunakan pendekatan kuat seperti jaringan saraf sebagai fungsi tujuan! Ini adalah inti dari Pembelajaran Penguatan modern. Dan perbedaan utamanya dari pelatihan jaringan saraf biasa.
Q-learning dan DQN
Penguatan Pembelajaran (bahkan sebelum jaringan saraf) dilahirkan sebagai ide yang agak sederhana dan orisinal: mari kita lakukan tindakan acak, dan kemudian untuk setiap sel dalam tabel dan setiap arah gerakan, kami menghitung menurut rumus khusus (disebut persamaan Bellman, kata ini Anda akan untuk bertemu di hampir setiap pekerjaan dengan pelatihan penguatan) seberapa baik sel ini dan arah yang dipilih. Semakin tinggi angka ini, semakin besar kemungkinan jalan ini menuju kemenangan.
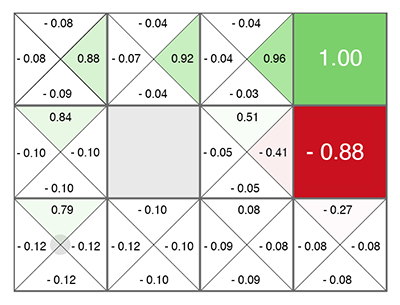
Tidak peduli di mana sel Anda muncul, bergeraklah sepanjang hijau yang tumbuh! (menuju angka maksimum di sisi sel saat ini).
Angka ini disebut Q (dari kata kualitas - kualitas pilihan, jelas), dan metodenya adalah Q-learning. Mengganti rumus untuk menghitung angka ini dengan jaringan saraf, atau lebih tepatnya mengajar jaringan saraf menggunakan rumus ini (ditambah beberapa trik yang terhubung murni dengan matematika pelatihan jaringan saraf), Deepmind mendapatkan metode DQN . Inilah yang pada tahun 2015 memenangkan tumpukan game Atari dan mengantarkan revolusi dalam Pembelajaran Penguatan Dalam.
Sayangnya, metode ini dalam arsitekturnya hanya bekerja dengan tindakan diskrit diskrit. Dalam DQN, keadaan saat ini (situasi saat ini) diumpankan ke input jaringan saraf, dan pada output jaringan saraf memprediksi nomor Q. Dan karena output jaringan mendaftar semua tindakan yang mungkin sekaligus (masing-masing dengan prediksi Q sendiri), ternyata jaringan saraf dalam DQN mengimplementasikan fungsi klasik Q (s, a) dari Q-learning. Q state action ( Q(s,a) s a). argmax Q , .
Q, . , Q- (.. Q , ). . , (Exploration), , , . , .
, ? 5 Atari, continuous ? , -1..1 0.1, , Atari. . , . 10 . - , 10 . . DQN , 17 . , , .
DQN, , , continuous ( ): DDQN, DuDQN, BDQN, CDQN, NAF, Rainbow. , Direct Future Prediction (DFP) , DQN . Q , DFP , . . , . , , , .
, Reinforcement Learning.
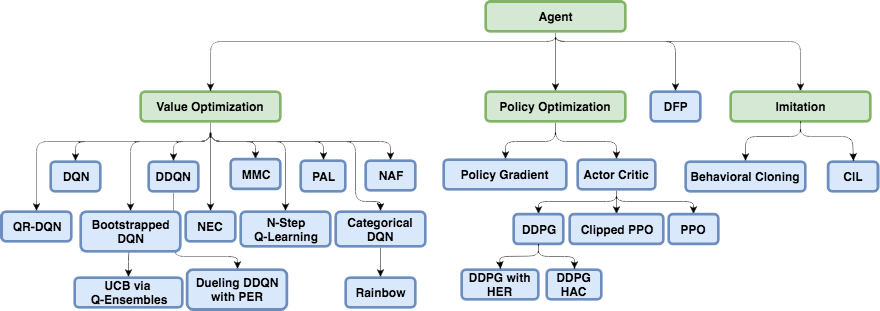
Policy Gradient
state, ( , ). , actions, . , R . ( ), ( ). . .
, R , , . ! . "" labels ( ), . , , R.
Policy Gradient. — , R, . — , , . , .
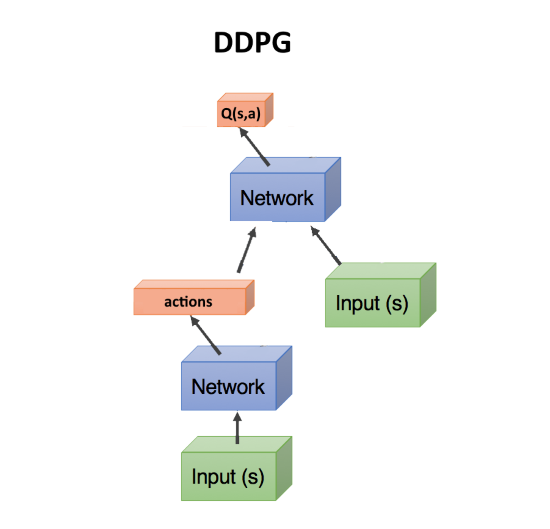
Actor-critic, DDPG
, — , . , Q- , DQN. state, action(s). state, action, , Q : Q(s,a).
, Q(s,a), ( critic, ), , ( , actor), R. , . actor-critic. Policy Gradient, , . .
DDPG. actions, continuous . DDPG continuous DQN .
Advantage Actor Critic (A3C/A2C)
critic Q(s,a) — , actor, DDPG. , .
, . , , , . , , , ( , ).
Q(s,a), Advantage: A(s,a) = Q(s,a) — V(s). A(s,a) Q(s,a) , — , V(s). A(s,a) > 0, , . A(s,a) < 0, , , .. .
V(s) state , ( s, a). — state, V(s). , state, V(s).
, Q(s,a) r, , A = r — V(s).
, V(s) ( ), — actor critic, ! state, head: actions, V(s). c , .. state. , .
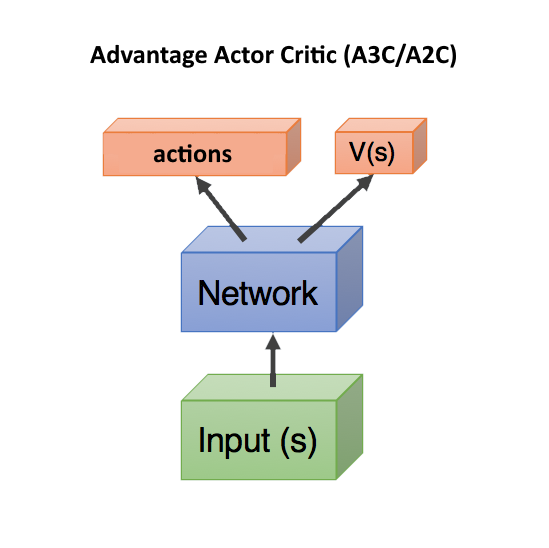
V(s) . V(s), action ( ), . Dueling Q-Network (DuDQN), Q(s,a) Q(s,a) = V(s) + A(a), .
Asynchronous Advantage Actor Critic (A3C) , , actor. batch . , actor. , , . , A2C — A3C, actor ( ). A2C , , .
TRPO, PPO, SAC
, .
, . Reinforcement Learning , , , — , . .
— TRPO PPO, state-of-the-art, Actor-Critic. PPO RL. , OpenAI Five Dota 2.
, TRPO PPO — , . , A3C/A2C , . , policy , . - gradient clipping , . , ( , ), , , - .
Baru-baru ini, algoritma Soft-Actor-Critic (SAC) telah mendapatkan popularitas. Tidak jauh berbeda dengan PPO, hanya tujuan yang ditambahkan ketika belajar meningkatkan entropi dalam kebijakan. Jadikan perilaku agen lebih acak. Tidak, tidak seperti itu. Bahwa agen itu dapat bertindak dalam situasi yang lebih acak. Ini secara otomatis meningkatkan keandalan kebijakan, setelah agen siap untuk situasi acak apa pun. Selain itu, SAC membutuhkan contoh pelatihan sedikit lebih sedikit daripada PPO, dan kurang sensitif terhadap pengaturan hyperparameter, yang juga merupakan nilai tambah. Namun, bahkan dengan SAC, untuk melatih humanoid berjalan dengan 17 derajat kebebasan, mulai dari posisi berdiri, Anda memerlukan sekitar 20 juta frame dan sekitar satu hari perhitungan pada satu GPU. Kondisi awal yang lebih sulit, misalnya, untuk mengajarkan humanoid untuk bangkit dari pose yang sewenang-wenang, mungkin tidak diajarkan sama sekali.
Total, rekomendasi umum dalam Pembelajaran Penguatan modern: gunakan SAC, PPO, DDPG, DQN (dalam urutan itu, turun).
Berbasis model
Ada pendekatan lain yang menarik, tidak langsung terkait dengan pembelajaran penguatan. Ini untuk membangun model lingkungan, dan menggunakannya untuk memprediksi apa yang akan terjadi jika kita mengambil tindakan.
Kerugiannya adalah tidak mengatakan tindakan apa pun yang harus diambil. Hanya tentang hasil mereka. Tetapi jaringan saraf seperti itu mudah untuk dilatih - cukup latih pada statistik apa pun. Ternyata sesuatu seperti simulator dunia yang didasarkan pada jaringan saraf.
Setelah itu, kami menghasilkan sejumlah besar tindakan acak, dan masing-masing didorong melalui simulator ini (melalui jaringan saraf). Dan kami melihat mana yang akan memberikan hadiah maksimal. Ada optimasi kecil - untuk menghasilkan tidak hanya tindakan acak, tetapi menyimpang sesuai dengan hukum normal dari lintasan saat ini. Dan memang, jika kita mengangkat tangan, maka dengan probabilitas tinggi kita perlu terus mengangkatnya. Karena itu, pertama-tama, Anda perlu memeriksa penyimpangan minimum dari lintasan saat ini.
Kuncinya di sini adalah bahwa bahkan simulator fisik primitif seperti MuJoCo atau pyBullet menghasilkan sekitar 200 FPS. Dan jika Anda melatih jaringan saraf untuk memprediksi maju setidaknya beberapa langkah, maka untuk lingkungan yang sederhana Anda dapat dengan mudah mendapatkan batch prediksi 2000-5000 sekaligus. Bergantung pada kekuatan GPU, Anda bisa mendapatkan perkiraan untuk puluhan ribu tindakan acak per detik karena paralelisasi dalam GPU dan kecepatan komputasi di jaringan saraf. Jaringan saraf di sini hanya bertindak sebagai simulator realitas yang sangat cepat.
Selain itu, karena jaringan saraf dapat memprediksi dunia nyata (ini adalah pendekatan berbasis model, dalam arti umum), maka pelatihan dapat dilakukan sepenuhnya dalam imajinasi, sehingga untuk berbicara. Konsep dalam Penguatan Pembelajaran ini disebut Dream Worlds, atau World Models. Ini berfungsi dengan baik, deskripsi yang baik ada di sini: https://worldmodels.imtqy.com . Selain itu, ia memiliki pasangan alami - mimpi biasa. Dan beberapa bergulir acara terbaru atau yang direncanakan di kepala.
Pembelajaran imitasi
Karena ketidakberdayaan yang tidak didukung algoritma Penguatan Pembelajaran bekerja pada dimensi besar dan tugas-tugas kompleks, orang-orang berangkat untuk setidaknya mengulangi tindakan para ahli dalam bentuk orang. Di sini, hasil yang baik dicapai (tidak dapat dicapai oleh Pembelajaran Penguatan konvensional). Jadi, OpenAI ternyata lulus dari permainan Revenge Montezuma . Triknya ternyata sederhana - untuk menempatkan agen segera di akhir permainan (di akhir lintasan yang ditunjukkan oleh orang tersebut). Di sana, dengan bantuan PPO, berkat kedekatan hadiah akhir, agen dengan cepat belajar berjalan di sepanjang lintasan. Setelah itu kami mengembalikannya sedikit, di mana ia dengan cepat belajar untuk mencapai tempat yang telah ia pelajari. Dan secara bertahap menggeser titik "respawn" di sepanjang lintasan sampai awal permainan, agen belajar untuk lulus / mensimulasikan lintasan ahli sepanjang permainan.
Hasil mengesankan lainnya adalah pengulangan gerakan untuk orang yang memotret di Motion Capture: DeepMimic . Resepnya mirip dengan metode OpenAI: setiap episode tidak dimulai dari awal jalan, tetapi dari titik acak di sepanjang jalan. Kemudian PPO berhasil mempelajari lingkungan sekitar titik ini.
Saya harus mengatakan bahwa algoritma Go-Explore yang sensasional dari Uber, yang melewati Montezuma's Revenge dengan catatan poin, sama sekali bukan algoritma Reinforcement Learning. Ini adalah pencarian acak biasa, tetapi dimulai dengan sel sel yang dikunjungi secara acak (sel kasar yang masuk ke beberapa keadaan). Dan hanya ketika lintasan sampai akhir permainan ditemukan oleh pencarian acak, jaringan saraf dilatih menggunakan Pembelajaran Imitasi. Dengan cara yang mirip dengan OpenAI, mis. mulai dari akhir lintasan.
Keingintahuan (Curiosity)
Konsep yang sangat penting dalam Pembelajaran Penguatan adalah Curiosity. Di alam, ini adalah mesin untuk penelitian lingkungan.
Masalahnya adalah bahwa sebagai ukuran rasa ingin tahu, Anda tidak dapat menggunakan kesalahan prediksi jaringan sederhana, apa yang akan terjadi selanjutnya. Kalau tidak, jaringan seperti itu akan menggantung di depan pohon pertama dengan dedaunan yang bergoyang. Atau di depan TV dengan perpindahan saluran acak. Karena hasil karena kompleksitas tidak mungkin untuk diprediksi dan kesalahan akan selalu besar. Namun, inilah alasan mengapa kita (orang) suka melihat dedaunan, air, dan api. Dan bagaimana orang lain bekerja =). Tetapi kami memiliki mekanisme perlindungan agar tidak menggantung selamanya.
Salah satu mekanisme tersebut diciptakan sebagai Inverse Model dalam Eksplorasi Curiosity-driven oleh
Prediksi yang diawasi sendiri . Singkatnya, seorang agen (jaringan saraf), selain memprediksi tindakan apa yang paling baik dilakukan dalam situasi tertentu, juga mencoba memprediksi apa yang akan terjadi pada dunia setelah tindakan diambil. Dan dia menggunakan prediksi dunia ini untuk langkah selanjutnya, sehingga dia dan langkah saat ini dapat memprediksi tindakannya yang diambil sebelumnya (ya, itu sulit, Anda tidak bisa mengetahuinya tanpa minum).
Ini mengarah ke efek penasaran: agen menjadi penasaran hanya pada apa yang bisa dia pengaruhi dengan tindakannya. Dia tidak bisa memengaruhi ranting-ranting pohon yang berayun, sehingga mereka menjadi tidak menarik baginya. Tapi dia bisa berjalan di sekitar distrik, jadi dia penasaran untuk berjalan dan menjelajahi dunia.
Namun, jika agen memiliki remote control TV yang mengganti saluran acak, maka ia dapat mempengaruhinya! Dan dia akan penasaran untuk mengklik saluran ad infinitum (karena dia tidak dapat memprediksi apa saluran berikutnya, karena itu acak). Upaya untuk menghindari masalah ini dilakukan oleh Google dalam karya Episodic Curiosity melalui Reachability .
Tetapi mungkin hasil yang terbaik adalah karena rasa ingin tahu, OpenAI saat ini memiliki gagasan Random Network Distillation (RND) . Esensinya adalah dibutuhkan jaringan kedua yang diinisialisasi secara acak, dan kondisi saat ini dimasukkan. Dan jaringan syaraf kerja utama kami mencoba menebak output dari jaringan syaraf ini. Jaringan kedua tidak dilatih, itu tetap tetap sepanjang waktu seperti yang diinisialisasi.
Apa gunanya Intinya adalah bahwa jika ada negara yang telah dikunjungi dan dipelajari oleh jaringan kerja kami, maka itu akan lebih atau kurang berhasil dapat memprediksi output dari jaringan kedua itu. Dan jika ini adalah keadaan baru, di mana kita belum pernah, maka jaringan saraf kita tidak akan dapat memprediksi output dari jaringan RND itu. Kesalahan dalam memprediksi output dari jaringan yang diinisialisasi secara acak ini digunakan sebagai indikator rasa ingin tahu (ini memberikan imbalan tinggi jika kita tidak dapat memprediksi hasilnya dalam situasi ini).
Mengapa ini bekerja tidak sepenuhnya jelas. Tetapi mereka menulis bahwa ini menghilangkan masalah ketika target prediksi adalah stokastik dan ketika tidak ada cukup data untuk membuat prediksi tentang apa yang akan terjadi selanjutnya (yang memberikan kesalahan prediksi besar dalam algoritma rasa ingin tahu biasa). Satu atau lain cara, tetapi RND benar-benar menunjukkan hasil penelitian yang sangat baik berdasarkan rasa ingin tahu dalam permainan. Dan mengatasi masalah TV acak.
Dengan RND, rasa ingin tahu di OpenAI untuk pertama kalinya jujur (dan tidak melalui pencarian acak awal, seperti di Uber) melewati level pertama dari Balas Dendam Montezuma. Tidak setiap waktu dan tidak dapat diandalkan, tetapi dari waktu ke waktu ternyata.

Apa hasilnya?
Seperti yang Anda lihat, hanya dalam beberapa tahun, Penguatan Pembelajaran telah datang jauh. Bukan hanya beberapa solusi yang berhasil, seperti dalam jaringan convolutional, di mana koneksi resudal dan lewati memungkinkan untuk melatih jaringan ratusan lapisan, bukannya selusin lapisan dengan fungsi aktivasi Relu saja, yang mengatasi masalah hilangnya gradien di sigmoid dan tanh. Dalam pembelajaran dengan penguatan, telah ada kemajuan dalam konsep dan dalam memahami alasan mengapa versi implementasi naif ini atau itu tidak berhasil. Kata kunci "tidak berfungsi."
Namun dari sudut pandang teknis, semuanya masih bertumpu pada prediksi semua nilai Q, V, atau A yang sama. Tidak ada ketergantungan waktu pada skala yang berbeda, seperti di otak (Hierarchical Reinforcement Learning tidak masuk hitungan, hierarki terlalu primitif di dalamnya dibandingkan dengan asosiatif dalam otak yang hidup). Tidak ada upaya untuk menghasilkan arsitektur jaringan yang dirancang khusus untuk pembelajaran penguatan, seperti yang terjadi dengan LSTM dan jaringan berulang lainnya untuk urutan waktu. Penguatan Belajar baik menginjak-injak di tempat, bersukacita dalam keberhasilan kecil, atau bergerak ke arah yang benar-benar salah.
Saya ingin percaya bahwa sekali dalam pembelajaran penguatan akan ada terobosan dalam arsitektur jaringan saraf, mirip dengan apa yang terjadi dalam jaringan convolutional. Dan kita akan melihat pembelajaran penguatan yang benar-benar bekerja. Belajar pada contoh yang terisolasi, dengan memori asosiatif yang bekerja dan bekerja pada skala waktu yang berbeda.