Bahasa R saat ini adalah salah satu alat paling kuat dan multifungsi untuk bekerja dengan data, tetapi seperti yang kita tahu hampir selalu, dalam sembarang madu ada lalat di salep. Faktanya adalah bahwa R adalah single-threaded secara default.
Kemungkinan besar ini tidak akan mengganggu Anda untuk waktu yang cukup lama, dan Anda tidak mungkin mengajukan pertanyaan ini. Tetapi misalnya, jika Anda dihadapkan dengan tugas mengumpulkan data dari sejumlah besar akun iklan dari API, misalnya Yandex.Direct, maka Anda dapat secara signifikan, setidaknya dua hingga tiga kali, mengurangi waktu yang diperlukan untuk mengumpulkan data menggunakan multithreading.

Topik multithreading di R bukanlah hal yang baru, dan telah berulang kali diangkat tentang Habré di sini , di sini dan di sini , tetapi publikasi terakhir berasal dari tahun 2013, dan sebagaimana mereka mengatakan bahwa segala sesuatu yang baru sudah lama terlupakan. Selain itu, multithreading sebelumnya dibahas untuk menghitung model dan melatih jaringan saraf, dan kita akan berbicara tentang menggunakan asinkron untuk bekerja dengan API. Meskipun demikian, saya ingin mengambil kesempatan ini untuk mengucapkan terima kasih kepada penulis artikel ini karena mereka banyak membantu saya dalam menulis artikel ini dengan publikasi mereka.
Isi
Bagian kedua dari artikel ini, yang berkaitan dengan opsi yang lebih modern untuk mengimplementasikan multithreading di R, tersedia di sini .
Apa itu multithreading
Satu-threading (Perhitungan berurutan) - mode perhitungan di mana semua tindakan (tugas) dilakukan secara berurutan, total durasi semua operasi yang diberikan dalam kasus ini akan sama dengan jumlah durasi semua operasi.
Multithreading (Parallel computing) - mode komputasi di mana tindakan tertentu (tugas) dilakukan secara paralel, mis. pada saat yang sama, sedangkan total waktu pelaksanaan semua operasi tidak akan sama dengan jumlah durasi semua operasi.
Untuk menyederhanakan persepsi, mari kita lihat tabel berikut:
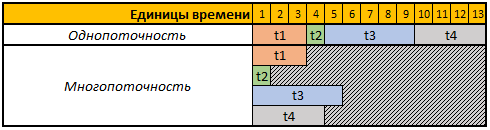
Baris pertama dari tabel yang diberikan adalah unit waktu bersyarat, dalam hal ini tidak masalah bagi kami detik, menit atau periode waktu lainnya.
Dalam contoh ini, kita perlu melakukan 4 operasi, setiap operasi dalam kasus ini memiliki durasi perhitungan yang berbeda, dalam mode single-threaded, semua 4 operasi akan dilakukan secara berurutan, oleh karena itu, total waktu untuk pelaksanaannya adalah t1 + t2 + t3 + t4, 3 + 1 + 5 + 4 = 13.
Dalam mode multi-utas, semua 4 tugas akan dilakukan secara paralel, mis. untuk memulai tugas berikutnya, tidak perlu menunggu sampai yang sebelumnya selesai, jadi jika kita memulai tugas kita dalam 4 utas, maka total waktu perhitungan akan sama dengan waktu perhitungan dari tugas terbesar, dalam kasus kami adalah tugas t3, durasi perhitungan yang dalam contoh kami adalah 5 unit sementara, masing-masing, dan waktu pelaksanaan semua 4 operasi dalam hal ini akan sama dengan 5 unit sementara.
Paket apa yang akan kita gunakan
Untuk perhitungan dalam mode multithreaded, kami akan menggunakan paket foreach , doSNOW dan doParallel .
Paket foreach memungkinkan Anda untuk menggunakan konstruksi foreach , yang pada dasarnya merupakan peningkatan untuk loop.
Paket doSNOW dan doParallel pada dasarnya adalah saudara kembar, memungkinkan Anda untuk membuat cluster virtual dan menggunakannya untuk melakukan komputasi paralel.
Di akhir artikel, menggunakan paket rbenchmark kami akan mengukur dan membandingkan durasi operasi pengumpulan data dari Yandex.Direct API menggunakan semua metode yang dijelaskan di bawah ini.
Untuk bekerja dengan Yandex.Direct API, kami akan menggunakan paket ryandexdirect, dalam artikel ini kami akan menggunakannya sebagai contoh, rincian lebih lanjut tentang kemampuan dan fungsinya dapat ditemukan dalam dokumentasi resmi .
Kode untuk menginstal semua paket yang diperlukan:
install.packages("foreach") install.packages("doSNOW") install.packages("doParallel") install.packages("rbenchmark") install.packages("ryandexdirect")
Tantangan
Anda harus menulis kode yang akan meminta daftar kata kunci dari sejumlah akun iklan Yandex.Direct. Hasilnya harus dikumpulkan dalam satu kerangka tanggal, di mana akan ada bidang tambahan dengan login akun iklan tempat kata kunci tersebut berada.
Selain itu, tugas kami adalah menulis kode yang akan melakukan operasi ini secepat mungkin pada sejumlah akun iklan.
Otorisasi di Yandex.Direct
Untuk bekerja dengan API platform periklanan Yandex.Direct, pada awalnya diharuskan untuk pergi melalui otorisasi di bawah setiap akun dari mana kami berencana untuk meminta daftar kata kunci.
Semua kode yang diberikan dalam artikel ini mencerminkan contoh bekerja dengan akun iklan Yandex.Direct reguler, jika Anda bekerja di bawah akun agen, Anda perlu menggunakan argumen AgencyAccount dan meneruskan login akun agen untuk itu. Anda dapat mengetahui lebih lanjut tentang bekerja dengan akun agen Yandex.Direct menggunakan paket ryandexdirect di sini .
Untuk otorisasi diperlukan untuk menjalankan fungsi yadirAuth dari paket yadirAuth , untuk mengulangi kode di bawah ini diperlukan untuk setiap akun dari mana Anda akan meminta daftar kata kunci dan parameter mereka.
ryandexdirect::yadirAuth(Login = " ")
Proses otorisasi di Yandex.Direct melalui paket ryandexdirect benar-benar aman, terlepas dari kenyataan bahwa ia melewati situs pihak ketiga. Saya sudah berbicara secara rinci tentang keamanan penggunaannya dalam artikel "Seberapa Aman Menggunakan Paket R untuk Bekerja dengan API Sistem Periklanan" .
Setelah otorisasi, file login.yadirAuth.RData akan dibuat di bawah setiap akun di direktori kerja Anda, yang akan menyimpan kredensial untuk setiap akun. Nama file akan dimulai pada login yang ditentukan dalam argumen Login . Jika Anda perlu menyimpan file bukan di direktori kerja saat ini, tetapi di beberapa folder lain, gunakan argumen TokenPath , tetapi dalam kasus ini ketika yadirGetKeyWords kata kunci menggunakan fungsi yadirGetKeyWords Anda juga perlu menggunakan argumen TokenPath dan menentukan path ke folder tempat Anda menyimpan file. dengan kredensial.
Solusi berurutan single-threaded menggunakan untuk loop
Cara termudah untuk mengumpulkan data dari beberapa akun sekaligus adalah dengan menggunakan for . Sederhana tetapi bukan yang paling efektif, karena salah satu prinsip pengembangan dalam bahasa R adalah untuk menghindari penggunaan loop dalam kode.
Di bawah ini adalah contoh kode untuk mengumpulkan data dari 4 akun menggunakan loop for, pada kenyataannya, Anda dapat menggunakan contoh ini untuk mengumpulkan data dari sejumlah akun iklan.
Kode 1: Kami memproses 4 akun menggunakan loop biasa library(ryandexdirect) # logins <- c("login_1", "login_2", "login_3", "login_4") # res1 <- data.frame() # for (login in logins) { temp <- yadirGetKeyWords(Login = login) temp$login <- login res1 <- rbind(res1, temp) }
Mengukur runtime menggunakan fungsi system.time menunjukkan hasil berikut:
Waktu kerja:
Pengguna: 178.83
sistem: 0,63
berlalu: 320.39
Pengumpulan kata kunci untuk 4 akun memerlukan waktu 320 detik, dan dari pesan informasi yang yadirGetKeyWords fungsi yadirGetKeyWords selama operasi, akun terbesar terlihat, 5970 kata kunci diterima, dan 142 detik diproses.
Solusi Multithreading di R
Saya sudah menulis di atas bahwa untuk multithreading kita akan menggunakan doParallel dan doParallel .
Saya ingin menarik perhatian pada kenyataan bahwa hampir semua API memiliki batasannya sendiri, dan API Yandex.Direct tidak terkecuali. Faktanya, bantuan untuk bekerja dengan Yandex.Direct API mengatakan:
Tidak lebih dari lima permintaan API simultan diizinkan atas nama satu pengguna.
Oleh karena itu, terlepas dari kenyataan bahwa dalam hal ini kami akan mempertimbangkan contoh dengan pembuatan 4 aliran, dalam bekerja dengan Yandex.Direct Anda dapat membuat 5 aliran bahkan jika Anda mengirim semua permintaan di bawah pengguna yang sama. Tetapi yang paling rasional untuk menggunakan 1 utas per 1 inti dari prosesor Anda, Anda dapat menentukan jumlah inti prosesor fisik menggunakan perintah parallel::detectCores(logical = FALSE) , jumlah core logis dapat ditemukan menggunakan parallel::detectCores(logical = TRUE) . Pemahaman yang lebih terperinci tentang inti fisik dan logis seperti apa yang dimungkinkan di Wikipedia .
Selain batas pada jumlah permintaan, ada batas harian pada jumlah poin untuk mengakses API Yandex.Direct, mungkin berbeda untuk semua akun, setiap permintaan juga mengkonsumsi jumlah titik yang berbeda tergantung pada operasi yang dilakukan. Misalnya, untuk menanyakan daftar kata kunci Anda akan dikurangkan 15 poin untuk kueri yang selesai dan 3 poin untuk setiap 2000 kata, Anda dapat mengetahui bagaimana poin dihapuskan dalam sertifikat resmi . Anda juga dapat melihat informasi tentang jumlah poin yang dicetak dan tersedia, serta batas harian mereka dalam pesan informasi yang dikembalikan ke konsol oleh fungsi yadirGetKeyWords .
Number of API points spent when executing the request: 60 Available balance of daily limit API points: 993530 Daily limit of API points:996000
Mari kita berurusan dengan doSNOW dan doParallel agar.
Paket DoSNOW dan fitur multithreaded
Kami menulis ulang operasi yang sama untuk mode perhitungan multi-utas, membuat 4 utas dalam kasus ini, dan alih-alih for loop, kami menggunakan konstruksi foreach .
Kode 2: Komputasi paralel dengan doSNOW library(foreach) library(doSNOW) # logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoSNOW(cl) res2 <- foreach(login = logins, # - .combine = 'rbind', # .packages = "ryandexdirect", # .inorder=F ) %dopar% {cbind(yadirGetKeyWords(Login = login), login) } stopCluster(cl)
Dalam hal ini, mengukur runtime menggunakan fungsi system.time menunjukkan hasil berikut:
Waktu kerja:
pengguna: 0,17
sistem: 0,08
berlalu: 151.47
Hasil yang sama, yaitu kami menerima koleksi kata kunci dari 4 akun Yandex.Direct dalam 151 detik, mis. 2 kali lebih cepat. Selain itu, saya hanya menulis dalam contoh terakhir berapa lama untuk memuat daftar kata kunci dari akun terbesar (142 detik), yaitu dalam contoh ini, total waktu hampir identik dengan waktu pemrosesan akun terbesar. Faktanya adalah bahwa dengan bantuan fungsi foreach , kami secara bersamaan meluncurkan proses pengumpulan data dalam 4 aliran, yaitu pada saat yang sama mengumpulkan data dari keempat akun, masing-masing, total waktu sama dengan waktu pemrosesan akun terbesar.
Saya makeCluster memberikan sedikit penjelasan pada kode 2 , fungsi makeCluster bertanggung jawab atas jumlah utas, dalam hal ini kami membuat sekelompok 4 inti prosesor, tetapi seperti yang saya tulis sebelumnya ketika bekerja dengan Yandex.Direct API, Anda dapat membuat 5 utas, terlepas dari berapa banyak akun. Anda perlu memproses 5-15-100 atau lebih, Anda dapat mengirim 5 permintaan ke API secara bersamaan.
Selanjutnya, fungsi registerDoSNOW memulai cluster yang dibuat.
Setelah itu kita menggunakan konstruksi foreach , seperti yang saya katakan sebelumnya, konstruksi ini merupakan peningkatan untuk loop. Anda menetapkan penghitung sebagai argumen pertama, dalam contoh yang saya sebut login dan itu akan mengulangi elemen-elemen vektor login di setiap iterasi, kita akan mendapatkan hasil yang sama di loop for jika kita menulis for ( login in logins) .
Selanjutnya, Anda perlu menunjukkan dalam argumen .com . Fungsi yang Anda gunakan untuk menggabungkan hasil yang diperoleh pada setiap iterasi, opsi yang paling umum adalah:
rbind - gabungkan tabel yang dihasilkan baris demi baris di bawah satu sama lain;cbind - gabungkan tabel yang dihasilkan di kolom;"+" - merangkum hasil yang diperoleh pada setiap iterasi.
Anda juga dapat menggunakan fungsi lain, bahkan yang ditulis sendiri.
Argumen .inorder = F memungkinkan Anda untuk mempercepat fungsi sedikit lebih banyak jika Anda tidak peduli bagaimana cara menggabungkan hasil, dalam hal ini urutannya tidak penting bagi kami.
Selanjutnya adalah operator %dopar% , yang memulai loop dalam mode komputasi paralel, jika Anda menggunakan operator %do% , maka iterasi akan dieksekusi secara berurutan, serta ketika menggunakan loop biasa for biasa.
Fungsi stopCluster menghentikan cluster.
Multithreading, atau lebih tepatnya konstruksi foreach dalam mode multithreaded, memiliki beberapa fitur, pada kenyataannya, dalam hal ini, kami memulai setiap proses paralel dalam sesi R baru yang bersih. Oleh karena itu, untuk menggunakan fungsi umum dan objek di dalamnya yang ditentukan di luar konstruksi foreach , Anda perlu mengekspornya menggunakan argumen .export . Argumen ini mengambil vektor teks yang berisi nama-nama objek yang akan Anda gunakan di dalam foreach .
Juga, foreach , dalam mode paralel, tidak melihat paket-paket yang sebelumnya terhubung secara default, sehingga mereka juga harus dilewatkan di dalam foreach menggunakan argumen .packages . Anda juga perlu mentransfer paket dengan mencantumkan nama mereka dalam vektor teks, misalnya .packages = c("ryandexdirect", "dplyr", "lubridate") . Dalam contoh kode di atas 2 , kita hanya dengan cara ini memuat paket ryandexdirect pada setiap iterasi foreach .
Paket DoParallel
Seperti yang saya tulis di atas, paket doSNOW dan doParallel adalah kembar, sehingga mereka memiliki sintaks yang sama.
Kode 5: Komputasi paralel dengan doParallel library(foreach) library(doParallel) logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoParallel(cl) res3 <- data.frame() res3 <- foreach(login=logins, .combine= 'rbind', .inorder=F) %dopar% {cbind(ryandexdirect::yadirGetKeyWords(Login = login), login) stopCluster(cl)
Waktu kerja:
pengguna: 0,25
sistem: 0,01
berlalu: 173.28
Seperti yang dapat Anda lihat dalam kasus ini, waktu eksekusi sedikit berbeda dari contoh sebelumnya dari kode komputasi paralel menggunakan paket doSNOW .
Tes kecepatan antara tiga pendekatan ditinjau
Sekarang jalankan tes kecepatan menggunakan paket rbenchmark .
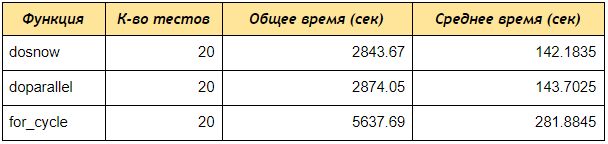
Seperti yang Anda lihat, bahkan pada pengujian 4 akun, paket doSNOW dan doParallel menerima data dengan kata kunci 2 kali lebih cepat daripada urutan untuk loop, jika Anda membuat sekelompok 5 core dan memproses 50 atau 100 akun, perbedaannya akan menjadi lebih signifikan.
Kode 6: Skrip untuk membandingkan kecepatan multithreading dan komputasi sekuensial # library(ryandexdirect) library(foreach) library(doParallel) library(doSNOW) library(rbenchmark) # for for_fun <- function(logins) { res1 <- data.frame() for (login in logins) { temp <- yadirGetKeyWords(Login = login) res1 <- rbind(res1, temp) } return(res1) } # foreach doSNOW dosnow_fun <- function(logins) { cl <- makeCluster(4) registerDoSNOW(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login } }) stopCluster(cl) return(res2) } # foreach doParallel dopar_fun <- function(logins) { cl <- makeCluster(4) registerDoParallel(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login) } }) stopCluster(cl) return(res2) } # within(benchmark(for_cycle = for_fun(logins = logins), dosnow = dosnow_fun(logins = logins), doparallel = dopar_fun(logins = logins), replications = c(20), columns=c('test', 'replications', 'elapsed'), order=c('elapsed', 'test')), { average = elapsed/replications })
Sebagai kesimpulan, saya akan memberikan penjelasan tentang kode 5 di atas, yang dengannya kami menguji kecepatan kerja.
Awalnya, kami membuat tiga fungsi:
for_fun - fungsi yang meminta kata kunci dari beberapa akun, mengurutkannya secara berurutan melalui siklus reguler.
dosnow_fun - fungsi yang meminta daftar kata kunci dalam mode multithreaded, menggunakan paket doSNOW .
dopar_fun - fungsi yang meminta daftar kata kunci dalam mode multithreaded, menggunakan paket doParallel .
Selanjutnya, di dalam konstruksi di dalam, kita menjalankan fungsi benchmark dari paket rbenchmark , menentukan nama tes (for_cycle, dosnow, doparallel), dan masing-masing fungsi yang kita tentukan fungsi, masing-masing: for_fun(logins = logins) ; dosnow_fun(logins = logins) ; dopar_fun(logins = logins) .
Argumen replikasi bertanggung jawab untuk jumlah tes, yaitu berapa kali kita akan menjalankan setiap fungsi.
Argumen kolom memungkinkan Anda menentukan kolom mana yang ingin Anda terima, dalam kasus kami 'pengujian', 'replikasi', 'berlalu' berarti mengembalikan kolom: nama pengujian, jumlah pengujian, total waktu pelaksanaan semua pengujian.
Anda juga dapat menambahkan kolom terhitung, ( { average = elapsed/replications } ), yaitu output akan menjadi kolom rata-rata yang akan membagi total waktu dengan jumlah tes, jadi kami menghitung waktu eksekusi rata-rata dari setiap fungsi.
order bertanggung jawab untuk menyortir hasil tes.
Kesimpulan
Pada artikel ini, pada prinsipnya, metode yang cukup universal untuk mempercepat pekerjaan dengan API dijelaskan, tetapi setiap API memiliki batasnya, oleh karena itu, khususnya dalam formulir ini, dengan begitu banyak utas, contoh di atas cocok untuk bekerja dengan Yandex.Direct API, untuk menggunakannya dengan API dari layanan lain, pada awalnya perlu membaca dokumentasi tentang batas-batas dalam API untuk jumlah permintaan yang dikirim secara bersamaan, jika tidak, Anda mungkin mendapatkan kesalahan Too Many Requests .
Kelanjutan artikel ini tersedia di sini .