
Pembelajaran mesin secara aktif digunakan di banyak bidang kehidupan kita. Algoritma membantu mengenali rambu-rambu lalu lintas, memfilter spam, mengenali wajah teman-teman kita di Facebook, dan bahkan membantu berdagang di bursa saham. Algoritma membuat keputusan penting, jadi Anda harus yakin bahwa itu tidak bisa dibodohi.
Pada artikel ini, yang merupakan seri pertama, kami akan memperkenalkan Anda pada masalah keamanan algoritma pembelajaran mesin. Ini tidak memerlukan tingkat tinggi pengetahuan tentang pembelajaran mesin dari pembaca, itu sudah cukup untuk memiliki gambaran umum tentang bidang ini.
Pertama, kami memberikan istilah yang digunakan dalam topik keamanan algoritma pembelajaran mesin:
Contoh permusuhan adalah vektor yang mengumpankan input ke suatu algoritma di mana algoritma menghasilkan output yang salah.
Serangan permusuhan - algoritma tindakan yang tujuannya adalah untuk mendapatkan contoh Adversarial.
Untuk memahami masalah contoh permusuhan, mari kita mengingat kembali salah satu tugas pembelajaran mesin - belajar dengan guru dalam menilai. Dalam masalah ini, kita memiliki pasangan "label-objek", dan kita harus belajar memprediksi nilai untuk objek baru.
Jika kita mempertimbangkan masalah ini dari sudut pandang geometris, perlu untuk membagi ruang sedemikian rupa untuk memprediksi kelas "benar" pada objek baru. Selain itu, jika kami memiliki kumpulan data umum (misalnya, untuk satu set digit tulisan tangan MNIST untuk memiliki semua jenis gambar dari semua digit), maka hyperplane ini dapat dilakukan secara ideal asalkan kelas-kelas dapat dipisahkan. Tetapi karena populasi umum paling sering tidak ada, untuk menyelesaikan masalah ini kami menggunakan algoritma pembelajaran mesin untuk memperkirakan hyperplane "ideal" seakurat mungkin menggunakan data yang kami miliki.
Setiap penyimpangan dari hyperplane dari yang ideal menimbulkan "celah" tertentu, jatuh ke mana objek diklasifikasikan secara tidak benar. Itulah sebabnya contoh-contoh seperti panda, yang diklasifikasikan sebagai owa, muncul. Dan tugas penyerang dikurangi menjadi mengubah vektor parameter objek sehingga jatuh ke dalam "celah" ini.
Contoh Serangan Musuh
Ada jaringan saraf yang mendeteksi wajah dalam sebuah foto. Dia berhasil mengatasi tugas (gambar di sebelah kiri). Tetapi setelah menambahkan sedikit noise pada foto ini (gambar di sebelah kanan), algoritma pada contoh permusuhan yang diperoleh (gambar di tengah) tidak lagi mendeteksi wajah dalam gambar.

Contoh ini, diperlihatkan dalam artikel " Serangan Adversarial pada Detektor Wajah menggunakan Neural Net Constrained Optimization berbasis ", menarik karena banyak sistem pengenalan wajah nyata menggunakan pendekatan jaringan saraf untuk mendeteksi wajah. Seseorang tidak akan melihat perbedaan ketika melihat kedua gambar.
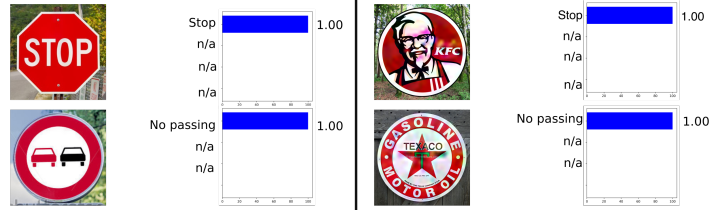
Contoh berikut diambil dari otomotif, yaitu pengenalan rambu lalu lintas. Contoh ini menarik karena contoh permusuhan tidak harus menjadi objek setidaknya agak dekat dengan objek di mana jaringan dilatih. Sebagai contoh, dalam Rogue Signs: Deceiving Traffic Sign Recognition dengan Malicious Ads and Logos , ditunjukkan bahwa contoh permusuhan dari tanda KFC akan “dikenali” oleh jaringan saraf asli sebagai tanda STOP dengan probabilitas 100%.
Banyak yang meragukan penggunaan contoh-contoh permusuhan di dunia nyata, karena contoh-contoh sebelumnya diuji pada komputer, sedangkan dalam kehidupan nyata objek seperti itu sulit diperoleh. Tapi ini tidak benar. Contoh Sintesis Robust Adversarial menunjukkan bahwa contoh permusuhan yang dibuat pada komputer dapat berhasil dicetak pada printer 3D, dan algoritme akan membuat kesalahan yang sama dengan simulasi komputer.

Di sini Anda melihat kura-kura dicetak pada printer 3D yang tidak dikenali sebagai kura-kura di sudut mana pun.
Contoh berikut menunjukkan apa yang dapat dilakukan jika kita melampaui pemahaman yang biasa tentang serangan permusuhan. Yaitu, memprogram ulang jaringan sumber untuk menggunakan muatannya sendiri. Dengan kata lain, kita belajar menggunakan jaringan saraf orang lain untuk menyelesaikan masalah yang ditimbulkan oleh penyerang. Sebagai contoh, Pemrograman Ulang Adversrial dari Neural Network menunjukkan bagaimana jaringan yang dilatih di ImageNet dengan sempurna menghitung jumlah kotak dalam gambar dan mengenali angka-angka dari set MNIST.
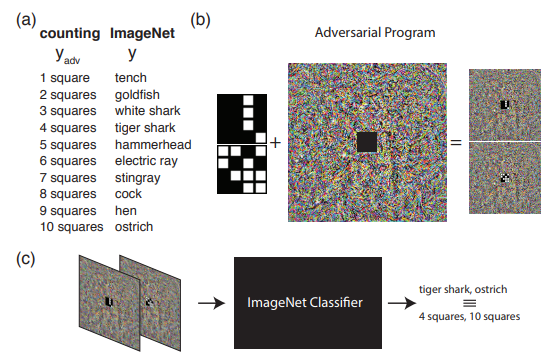
Gambar tersebut menunjukkan algoritma untuk bekerja dengan Pemrograman Ulang Adversarial, yang direkomendasikan untuk mengenal lebih baik di artikel asli.
Pada artikel ini, saya ingin berbicara secara khusus tentang metode untuk menghasilkan contoh permusuhan, dan pada artikel kedua kita akan beralih ke metode perlindungan dan algoritma pembelajaran mesin pengujian.
Klasifikasi Serangan
Semua serangan dapat dibagi menjadi 2 kelas: WhiteBox (WB) dan BlackBox (BB) . Dalam kasus WB, kita tahu semua informasi tentang model algoritma yang dilatih, sedangkan dalam kasus BB kita hanya memiliki akses ke input dan output dari model. Sebenarnya, opsi GrayBox masih dimungkinkan ketika kita tidak tahu informasi tentang model yang dilatih, tetapi ada informasi tentang jenis algoritma dan hyperparameter-nya. Tetapi jenis ini tidak menonjol di kelas yang terpisah, karena informasi tambahan tidak cukup untuk pergi ke WB, yang berarti bahwa ini hanya seperangkat informasi tambahan untuk melakukan serangan BB.
Selanjutnya, ada baiknya mengklasifikasikan serangan pada Targeted dan Non Targeted . Serangan yang ditargetkan berarti bahwa serangan dilakukan dalam arah tertentu. Sebagai contoh, pada dataset MNIST, kami melatih jaringan saraf dan mengambil gambar 0 dari set tes. Jaringan saraf terlatih menghasilkan probabilitas kelas 0 sebesar 1,00 pada objek ini. Jika kita ingin contoh permusuhan dikenali sebagai kelas 1 setelah menerapkan serangan permusuhan, maka kita akan menggunakan serangan yang ditargetkan. Kalau tidak, jika tidak terlalu penting bagi kita untuk kelas yang jaringan saraf akan menerima gambar (yang utama adalah bahwa itu bukan lagi kelas 0), maka serangan seperti itu akan menjadi Non Target.
Selain itu, serangan dibagi menjadi metrik yang menurutnya 2 objek dianggap serupa - norma. norma - jumlah parameter yang diubah. Jarak Euclidean antara dua vektor. perbedaan elemen-bijaksana maksimum antara dua vektor.
Perpustakaan Python
Pustaka data Python memungkinkan Anda untuk bekerja dengan contoh-contoh permusuhan. Ini adalah FoolBox, CleverHans dan ART-IBM.
| Kotak bodoh | Cleverhans | ART-IBM |
|---|
| Kerangka kerja yang didukung | TensorFlow, Keras, Theano, PyTorch, Lasagne, MXNet | TensorFlow, Keras | TensorFlow, Keras, janji MXNet, PyTorch |
Sekarang mari kita lihat serangan lebih detail, dan mulai dengan serangan WhiteBox.
Serangan L-BFGS
Pernyataan metode L-BFGS dapat ditulis sebagai berikut.
Karena itu kami ingin meminimalkan fungsi kerugian ke arah kelas target dengan pembatasan bahwa perubahan yang diperkenalkan minimal. Pada saat yang sama, diusulkan untuk memecahkan masalah seperti itu dalam artikel asli menggunakan metode L-BFGS, maka nama serangan ini.
Artikel asli - Properti menarik dari jaringan saraf
Serangan ini disajikan di 2 dari 3 perpustakaan yang sebelumnya disuarakan - FoolBox dan CleverHans.
Dan aplikasi serangan ini pada FoolBox membutuhkan 3 baris kode dengan Python:
from foolbox.attacks import LBFGSAttack attack = LBFGSAttack(fmodel) adversarial = attack(image, label)
Menggunakan L-BFGS akan membantu Anda menemukan contoh permusuhan terbaik berdasarkan keterbatasan Anda, tetapi, pertama, mencari contoh seperti itu bisa memakan waktu lama, dan kedua, sangat mungkin bahwa metode itu tidak akan konvergen.
Serangan FGSM
Tahap pengembangan selanjutnya adalah FGSM (Fast Sign Gradient Method), yang dapat ditampilkan menggunakan rumus:
Metode ini bekerja jauh lebih cepat daripada L-BFGS. Di sini kita hanya mengambil tanda-tanda dari fungsi gradien dari fungsi kehilangan semula, mengalikan tanda dengan beberapa , tambahkan ke gambar asli.

Berikut adalah contoh cara kerja metode ini. Peta kebisingan dengan sama dengan 0,007, dan ternyata foto panda sekarang diakui sebagai Gibbon dengan probabilitas 99,3%
Metode ini mudah diterapkan, tetapi pada saat yang sama, hasil dari metode ini sangat bising.
Artikel asli - Menjelaskan dan Memanfaatkan Contoh Musuh
Anda dapat menemukan implementasi metode ini di perpustakaan, dan menggunakan foolbox juga tidak akan memakan banyak waktu.
from foolbox.attacks import FGSM attack = FGSM(fmodel) adversarial = attack(image, label)
Serangan deepfool
DeepFool adalah Metode yang Tidak Ditargetkan. Perbedaan utama dari metode sebelumnya adalah mencoba membuat peta noise minimal, yang akan menipu algoritme. Metode ini tidak memungkinkan Anda untuk membuat satu kelas tertentu dari satu kelas, tetapi melakukan yang lain yang paling dekat dengan gambar aslinya.

Contoh menunjukkan gambar asli, di garis bawah - metode FGSM, dan di tengah - hanya serangan DeepFool. Dapat dilihat bahwa kartu suara jauh lebih kecil daripada dengan FGSM.
Artikel asli - DeepFool: metode sederhana dan akurat untuk menipu jaringan saraf yang dalam
Serangan semacam itu dapat dilakukan dengan menggunakan salah satu perpustakaan yang terdaftar, dan implementasi pada ART-IBM hanya membutuhkan 3 baris kode:
from art.attacks import DeepFool attack = DeepFool(model) img_adv = attack.generate(img)
Serangan peta saliency Jacobian
Dalam metode JSMA, turunan langsung dipertimbangkan, atas dasar yang mana peta gradien dibangun. Pada peta, setiap parameter objek sebenarnya sesuai dengan kontribusi parameter ini untuk mengubah hasil akhir dari algoritma. Dengan demikian, metode ini memungkinkan Anda untuk mengubah parameter sesedikit mungkin di objek yang diserang. Dan, karenanya, ia bekerja normal.
Artikel asli - Keterbatasan Pembelajaran Mendalam dalam Pengaturan Permusuhan
Serangan ini dapat dilakukan menggunakan CleverHans atau ART-IBM. Dan di CleverHans, tampilannya seperti ini:
from cleverhans.attacks import SaliencyMapMethod jsma = SaliencyMapMethod(model, sees=sees) jsma_params = { 'theta' : 1., 'gamma' : 0.1, 'clip_min' : 0., 'clip_max' : 1., 'y_target' : None} adv_x = jsma.generate_np(img, **jsma_params)
Serangan satu piksel
Pertanyaan logisnya adalah, berapa jumlah minimum piksel yang perlu diubah untuk melakukan serangan pada algoritma, dan karena banyak yang sudah menebak dengan nama serangan, 1 piksel sudah cukup.

Misalnya, gambar kuda dengan hanya satu piksel yang diubah menjadi katak dengan probabilitas 99,9%
Artikel asli - Satu serangan piksel untuk membodohi jaringan saraf yang dalam
Serangan ini hanya didukung di FoolBox, dan implementasinya adalah sebagai berikut:
from foolbox.attacks import SinglePixelAttack attack = SinglePixelAttack(fmodel) adversarial = attack(image,max_pixel=1)
Perlu disebutkan di sini dan mengatakan bahwa implementasi algoritma di Foolbox, dibandingkan dengan artikel asli, meskipun memiliki tujuan yang sama (untuk mengubah jumlah piksel tertentu dalam gambar), tetapi berbeda dalam metode memperoleh gambar.
Metode Berdasarkan Generalisasi Model BlackBox
Sebagian besar metode memerlukan pemahaman tentang bagaimana arsitektur model terstruktur, pengetahuan tentang nilai-nilai yang tepat dari parameternya, tetapi dalam praktiknya hal ini jarang dimungkinkan. Dan itu sebabnya muncul arah serangan terpisah - serangan BlacBox / GrayBox. Untuk serangan seperti itu, cukup memiliki akses ke input dan output dari model.
Salah satu metode untuk menerapkan serangan pada model BlackBox adalah menggeneralisasi model ini ke model Student (in the Substitute picture).
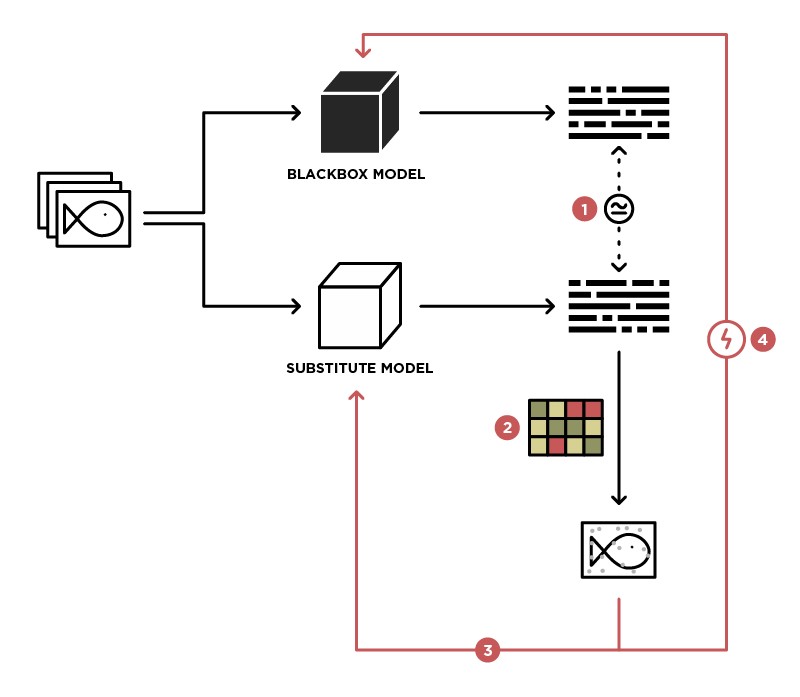
Memiliki akses untuk mengirim data ke model BlackBox (Guru) dan akses ke output dari model ini, kita dapat membuat dataset yang memungkinkan untuk melatih model kita sendiri (Siswa), dengan demikian menggeneralisasi model Guru. Setelah itu, Anda dapat menggunakan serangan WhiteBox pada model Siswa, dan dengan tingkat probabilitas tinggi serangan ini juga akan terjadi pada model Guru. Kemungkinan serangan seperti itu adalah semakin tinggi, semakin banyak pengetahuan tentang model Guru yang kita miliki. Sebagai contoh, kita tahu bahwa model Guru memproses gambar, paling sering arsitektur pra-terlatih (ResNet, Inception) dengan bobot ImageNet digunakan untuk pemrosesan gambar. Berdasarkan model Student dengan arsitektur yang sama, kemungkinan serangan yang berhasil akan dimaksimalkan.
Artikel asli - Serangan Black-Box Praktis terhadap Pembelajaran Mesin
Metode ini tidak disajikan di perpustakaan mana pun dan membutuhkan implementasi model Student yang independen, dan serangan terhadapnya dapat dilakukan menggunakan metode yang dijelaskan di atas.
Metode berbasis GAN
Tahap berikutnya dalam pengembangan serangan BlackBox adalah serangan yang didasarkan pada penyematan model BlackBox dalam arsitektur generative-adversarial network (GAN), sebuah jaringan yang memungkinkan pembuatan objek baru, yang selanjutnya akan ditransfer ke model Black-Box.
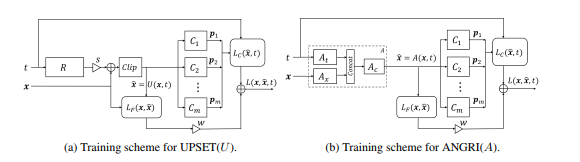
Metode ini memungkinkan pembuatan contoh permusuhan untuk hampir semua arsitektur. Ini juga membutuhkan akses ke pintu masuk dan keluar dari model yang diserang.
Baca lebih lanjut tentang metode ini dalam artikel asli - UPSET dan ANGRI: Memecah Pengklasifikasi Gambar Berperforma Tinggi
Seperti yang mungkin sudah Anda duga, metode ini tidak diwakili di salah satu perpustakaan.
Kesimpulan
Bahkan, ada sejumlah besar serangan. Artikel ini hanya mencakup beberapa saja. Kami berharap bahwa materi ini telah membantu Anda memahami konsep dasar dari contoh permusuhan dan algoritma pembuatannya. Untuk ulasan yang lebih rinci, kami sarankan Anda membaca artikel dan materi asli dari daftar referensi.
Sampai jumpa di artikel berikutnya, yang akan fokus pada metode melindungi dan menguji algoritma pembelajaran mesin.
Referensi
- Ancaman Serangan Musuh pada Pembelajaran Mendalam dalam Visi Komputer: Sebuah Survei - tinjauan yang bagus tentang metode serangan pada algoritma pembelajaran mendalam dalam Visi Komputer
- Pembelajaran Mesin Serang dengan Contoh Adversarial - blog OpenAI yang didedikasikan untuk contoh-contoh permusuhan
- Pembelajaran Mesin Adversari yang Luar Biasa - github dengan tautan ke banyak materi berguna tentang topik-topik permusuhan
- Presentasi tentang Pembelajaran Mesin Adversarial - Presentasi dari konferensi MoscowPythonConf2018 tentang Pembelajaran Mesin Adversarial