Pendahuluan
Dalam artikel sebelumnya (
"Bagian 2: Menggunakan blok PSoC UDB Cypress untuk mengurangi jumlah interupsi dalam printer 3D" ), saya mencatat satu fakta yang sangat menarik: jika sebuah mesin di UDB menghapus data dari FIFO terlalu cepat, ia berhasil melihat keadaan bahwa ada yang baru tidak ada data di FIFO, setelah itu masuk ke kondisi false
Idle . Tentu saja, saya tertarik pada fakta ini. Saya menunjukkan hasil yang terbuka kepada sekelompok kenalan. Satu orang menjawab bahwa ini semua sangat jelas, dan bahkan menyebutkan alasannya. Sisanya tidak kalah terkejutnya dengan saya di awal penelitian. Jadi, beberapa ahli tidak akan menemukan sesuatu yang baru di sini, tetapi akan lebih baik untuk membawa informasi ini kepada masyarakat umum sehingga semua programmer untuk mikrokontroler memilikinya.
Bukan berarti itu adalah semacam penutup. Ternyata semua ini terdokumentasi dengan baik, tetapi masalahnya bukan di utama, tetapi di dokumen tambahan. Dan secara pribadi, saya dalam ketidaktahuan bahagia, percaya bahwa DMA adalah subsistem yang sangat gesit yang dapat secara dramatis meningkatkan efisiensi program, karena ada transfer data yang sistematis tanpa mengganggu kenaikan register dan mengatur siklus ke perintah yang sama. Adapun meningkatkan efisiensi - semuanya benar, tetapi karena hal-hal yang sedikit berbeda.
Tetapi hal pertama yang pertama.
Eksperimen dengan Cypress PSoC
Mari kita membuat mesin sederhana. Secara kondisional akan memiliki dua status: status siaga dan status akan jatuh ke dalamnya ketika setidaknya ada satu byte data di FIFO. Memasuki kondisi ini, ia hanya akan mengambil data ini, dan sekali lagi gagal dalam keadaan istirahat. Kata "kondisional" tidak saya kutip tanpa sengaja. Kami memiliki dua FIFO, jadi saya akan membuat dua keadaan seperti itu, satu untuk setiap FIFO, untuk memastikan bahwa mereka benar-benar identik dalam perilaku. Grafik transisi untuk mesin ternyata seperti ini:
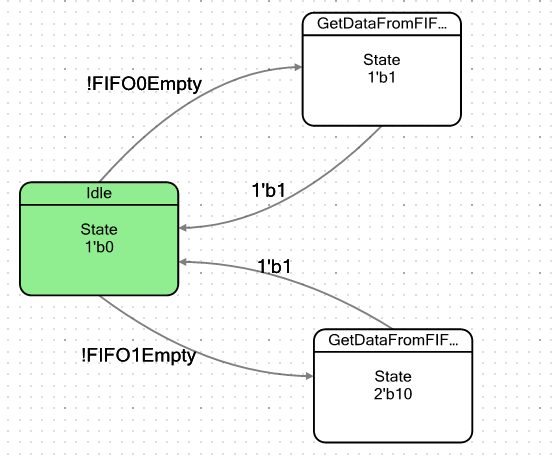
Bendera untuk keluar dari kondisi Idle didefinisikan sebagai berikut:
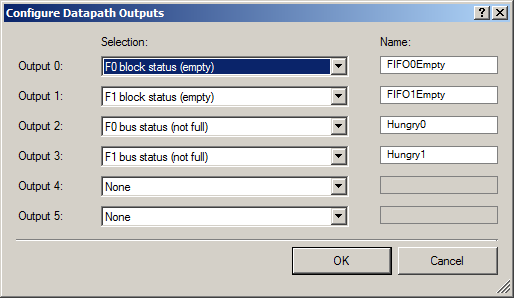
Jangan lupa untuk mengirimkan bit dari nomor status ke input Datapath:

Untuk bagian luar kami menampilkan dua kelompok sinyal: sepasang sinyal yang FIFO memiliki ruang kosong (sehingga DMA dapat mulai mengunggah data ke mereka), dan beberapa sinyal bahwa FIFO kosong (untuk menampilkan fakta ini pada osiloskop).

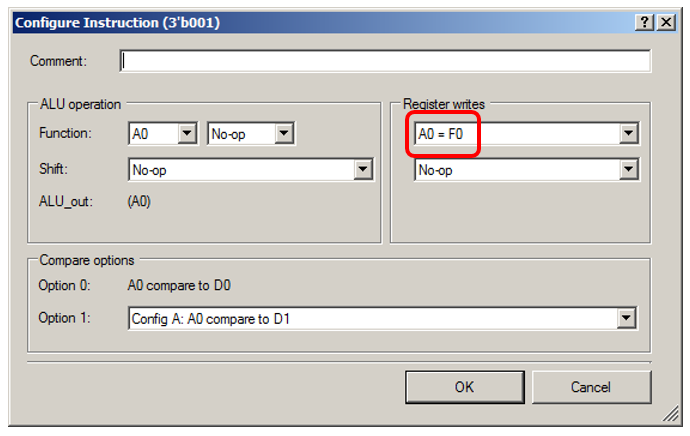
ALU akan secara fiktif mengambil data dari FIFO:

Biarkan saya menunjukkan kepada Anda rincian untuk negara “0001”:
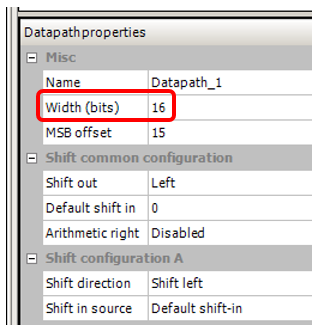
Saya juga mengatur lebar bus, yang ada di proyek di mana saya perhatikan efek ini, 16 bit:
Kami lolos ke skema proyek itu sendiri. Dari luar, saya memberikan tidak hanya sinyal bahwa FIFO kosong, tetapi juga pulsa clock. Ini akan memungkinkan saya melakukannya tanpa pengukuran kursor pada osiloskop. Saya hanya bisa mengambil tindakan dengan jari saya.
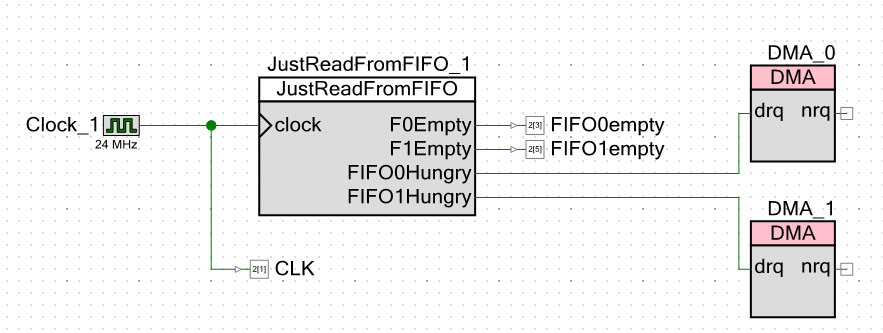
Ternyata, saya membuat kecepatan clock 24 megahertz. Frekuensi inti prosesor persis sama. Semakin rendah frekuensinya, semakin sedikit gangguan yang ada pada osiloskop Cina (secara resmi memiliki pita 250 MHz, tetapi kemudian megahertz Cina), dan semua pengukuran akan dilakukan sehubungan dengan pulsa clock. Apa pun frekuensinya, sistem akan tetap bekerja sehubungan dengan mereka. Saya akan menetapkan satu megahertz, tetapi lingkungan pengembangan melarang saya untuk memasukkan nilai frekuensi inti prosesor kurang dari 24 MHz.
Sekarang soal tes. Untuk menulis ke FIFO0, saya membuat fungsi ini:
void WriteTo0FromROM() { static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // DMA , uint8 channel = DMA_0_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(JustReadFromFIFO_1_Datapath_1_F0_PTR)); CyDmaChRoundRobin (channel,1); // , uint8 td = CyDmaTdAllocate(); // . , . CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR / TD_AUTO_EXEC_NEXT); // CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)JustReadFromFIFO_1_Datapath_1_F0_PTR)); // CyDmaChSetInitialTd(channel, td); // CyDmaChEnable(channel, 1); }
Kata ROM dalam nama fungsi disebabkan oleh fakta bahwa array yang akan dikirim disimpan di area ROM, dan Cortex M3 memiliki arsitektur Harvard. Kecepatan akses ke bus RAM dan bus ROM dapat bervariasi, saya ingin memeriksanya, jadi saya memiliki fungsi yang sama untuk mengirim array dari RAM (array
langkah tidak memiliki pengubah
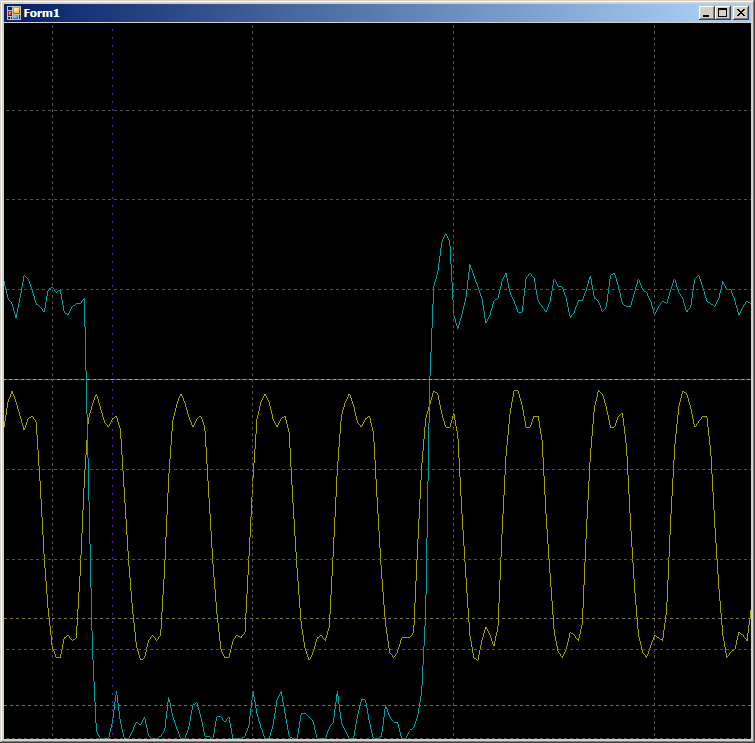
konstanta statis di tubuhnya). Nah, ada pasangan fungsi yang sama untuk mengirim ke FIFO1, register penerima berbeda di sana: bukan F0, tetapi F1. Jika tidak, semua fungsi identik. Karena saya tidak melihat banyak perbedaan dalam hasil, saya akan mempertimbangkan hasil memanggil persis fungsi di atas. Sinar kuning - pulsa clock, biru - output
FIFO0empty .

Pertama, periksa masuk akal mengapa FIFO diisi selama dua siklus clock. Mari kita lihat situs ini lebih terinci:
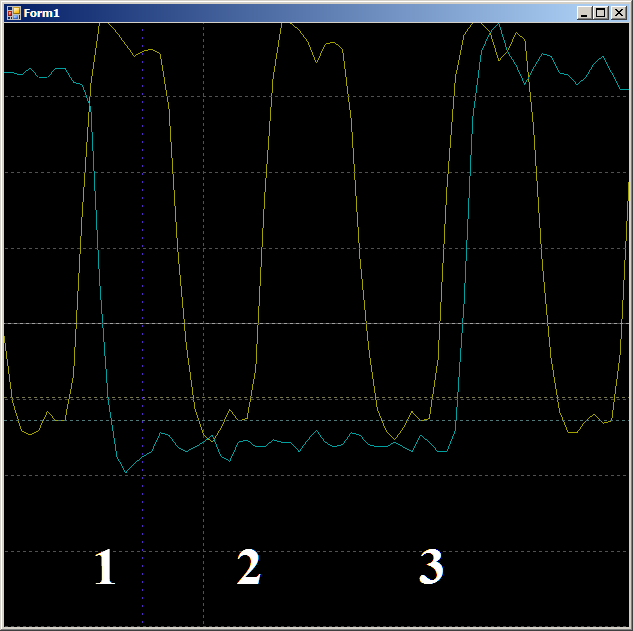
Di tepi 1, data jatuh ke FIFO, bendera
FIFO0enmpty turun. Di tepi 2, otomat memasuki kondisi
GetDataFromFifo1 . Pada tepi 3, dalam keadaan ini, data dari FIFO disalin ke register ALU, FIFO dikosongkan, bendera kosong FIFO
dinaikkan lagi. Artinya, bentuk gelombang berperilaku masuk akal, Anda dapat mengandalkannya pada siklus jam. Kami mendapat 9 buah.
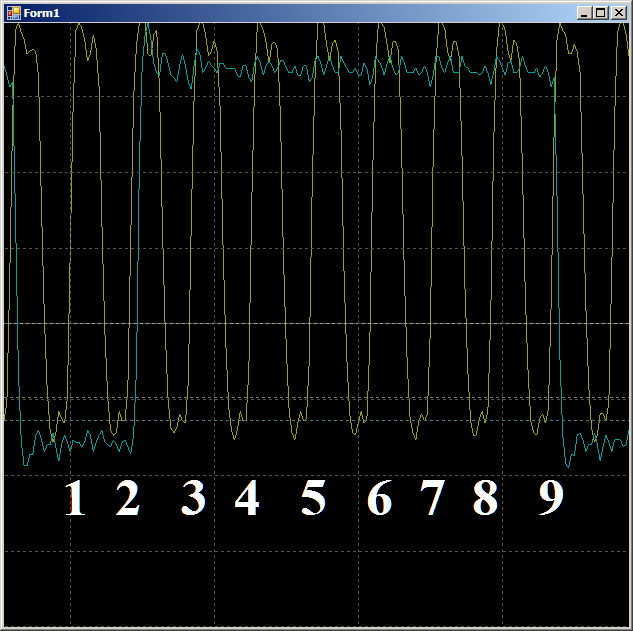 Secara total, di area yang diinspeksi, dibutuhkan 9 siklus clock untuk menyalin satu kata data dari RAM ke UDB menggunakan DMA.
Secara total, di area yang diinspeksi, dibutuhkan 9 siklus clock untuk menyalin satu kata data dari RAM ke UDB menggunakan DMA.Dan sekarang sama, tetapi dengan bantuan inti prosesor. Pertama, kode ideal yang sulit dicapai dalam kehidupan nyata:
volatile uint16_t* ptr = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; ptr[0] = 0; ptr[0] = 0;
apa yang akan berubah menjadi kode rakitan:
ldr r3, [pc, #8] ; (90 <main+0xc>) movs r2, #0 strh r2, [r3, #0] strh r2, [r3, #0] bn 8e <main+0xa> .word 0x40006898
Tidak ada istirahat, tidak ada siklus tambahan. Dua pasang tindakan berturut-turut ...
Mari kita buat kode sedikit lebih nyata (dengan overhead mengatur siklus, mengambil data dan menambah pointer):
void SoftWriteTo0FromROM() { // . // static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; uint16_t* src = steps; volatile uint16_t* dest = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; for (int i=sizeof(steps)/sizeof(steps[0]);i>0;i--) { *dest = *src++; } }
menerima kode assembler:
ldr r3, [pc, #14] ; (9c <CYDEV_CACHE_SIZE>) ldr r0, [pc, #14] ; (a0 <CYDEV_CACHE_SIZE+0x4>) add.w r1, r3, #28 ; 0x28 ldrh.w r2, [r3], #2 cmp r3, r1 strh r2, [r0, #0] bne.n 8e <main+0xa>
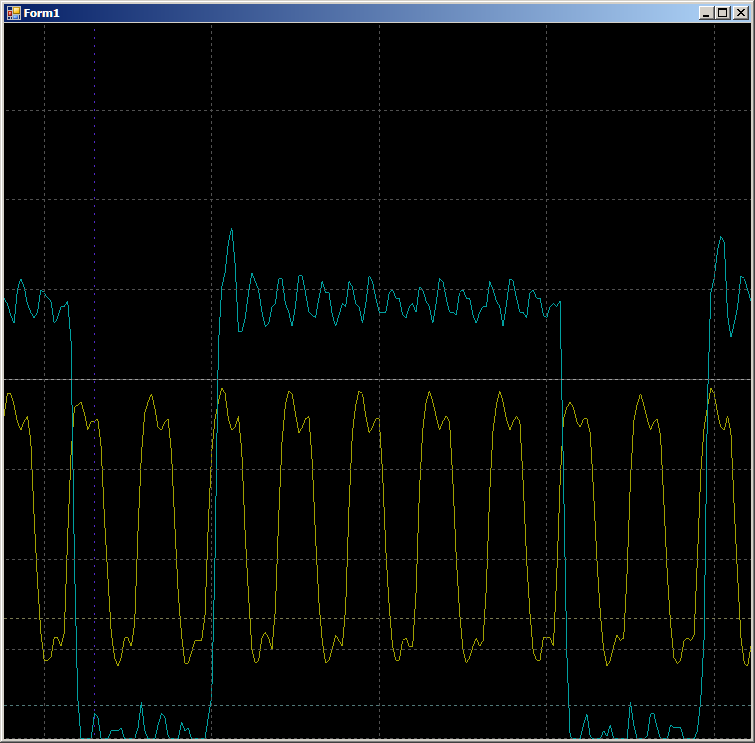
Pada osilogram kita hanya melihat 7 siklus per siklus versus sembilan dalam kasus DMA:
Sedikit tentang mitos
Sejujurnya, bagi saya itu awalnya mengejutkan. Entah bagaimana saya dulu percaya bahwa mekanisme DMA memungkinkan Anda mentransfer data dengan cepat dan efisien. 1/9 dari frekuensi bus tidak secepat itu. Tapi ternyata tidak ada yang menyembunyikannya. Dokumen TRM untuk PSoC 5LP bahkan berisi sejumlah pertimbangan teoretis, dan dokumen “AN84810 - PSoC 3 dan PSoC 5LP Advanced DMA Topics” menjelaskan secara terperinci proses mengakses DMA. Latensi yang harus disalahkan. Siklus pertukaran dengan bus membutuhkan sejumlah kutu. Sebenarnya, langkah-langkah inilah yang memainkan peran menentukan dalam terjadinya penundaan. Secara umum, tidak ada yang menyembunyikan apa pun, tetapi Anda perlu tahu ini.
Jika GPIF terkenal yang digunakan dalam FX2LP (arsitektur lain yang diproduksi oleh Cypress) tidak membatasi apa pun, maka di sini batas kecepatannya adalah karena latensi yang terjadi saat mengakses bus.Periksa DMA pada STM32
Saya sangat terkesan sehingga saya memutuskan untuk melakukan percobaan pada STM32. STM32F103 yang memiliki inti prosesor Cortex M3 yang sama diambil sebagai kelinci percobaan. Tidak memiliki UDB dari mana sinyal layanan dapat diturunkan, tetapi sangat mungkin untuk memeriksa DMA. Apa itu GPIO? Ini adalah satu set register di ruang alamat umum. Tidak apa-apa. Kami mengkonfigurasi DMA dalam mode salin "memori-memori", menentukan memori nyata (ROM atau RAM) sebagai sumber, dan register data GPIO tanpa penambahan alamat sebagai penerima. Kami akan mengirim ke sana secara bergantian 0 atau 1, dan memperbaiki hasilnya dengan osiloskop. Untuk memulai, saya memilih port B, lebih mudah untuk menghubungkannya di papan tempat memotong roti.

Saya sangat menikmati menghitung langkah dengan jari, bukan kursor. Apakah mungkin untuk melakukan hal yang sama pada pengontrol ini? Cukup! Ambil frekuensi clock referensi untuk osiloskop dari kaki MCO, yang terhubung ke port PA8 pada STM32F10C8T6. Pilihan sumber untuk kristal murah ini tidak besar (STM32F103 yang sama, tetapi lebih mengesankan, memberikan lebih banyak pilihan), kami akan mengirimkan sinyal SYSCLK ke output ini. Karena frekuensi pada MCO tidak boleh lebih tinggi dari 50 MHz, kami akan mengurangi kecepatan jam sistem keseluruhan menjadi 48 MHz. Kami akan mengalikan frekuensi kuarsa 8 MHz bukan dengan 9, tetapi dengan 6 (karena 6 * 8 = 48):

Teks yang sama: void SystemClock_Config(void) { RCC_OscInitTypeDef RCC_OscInitStruct; RCC_ClkInitTypeDef RCC_ClkInitStruct; RCC_PeriphCLKInitTypeDef PeriphClkInit; /**Initializes the CPU, AHB and APB busses clocks */ RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE; RCC_OscInitStruct.HSEState = RCC_HSE_ON; RCC_OscInitStruct.HSEPredivValue = RCC_HSE_PREDIV_DIV1; RCC_OscInitStruct.HSIState = RCC_HSI_ON; RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON; RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE; // RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL9; RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL6; if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK) { _Error_Handler(__FILE__, __LINE__); }
Kami akan memprogram MCO menggunakan perpustakaan
mcucpp dari Konstantin Chizhov (mulai sekarang saya akan melakukan semua panggilan ke peralatan melalui perpustakaan yang luar biasa ini):
// MCO Mcucpp::Clock::McoBitField::Set (0x4); // MCO Mcucpp::IO::Pa8::SetConfiguration (Mcucpp::IO::Pa8::Port::AltFunc); // Mcucpp::IO::Pa8::SetSpeed (Mcucpp::IO::Pa8::Port::Fastest);
Nah, sekarang kita atur output dari array data di GPIOB:
typedef Mcucpp::IO::Pb0 dmaTest0; typedef Mcucpp::IO::Pb1 dmaTest1; ... // GPIOB dmaTest0::ConfigPort::Enable(); dmaTest0::SetDirWrite(); dmaTest1::ConfigPort::Enable(); dmaTest1::SetDirWrite(); uint16_t dataForDma[]={0x0000,0x8001,0x0000,0x8001,0x0000, 0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001}; typedef Mcucpp::Dma1Channel1 channel; // dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set(); // , DMA channel::Init (channel::Mem2Mem|channel::MSize16Bits|channel::PSize16Bits|channel::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); while (1) { } }
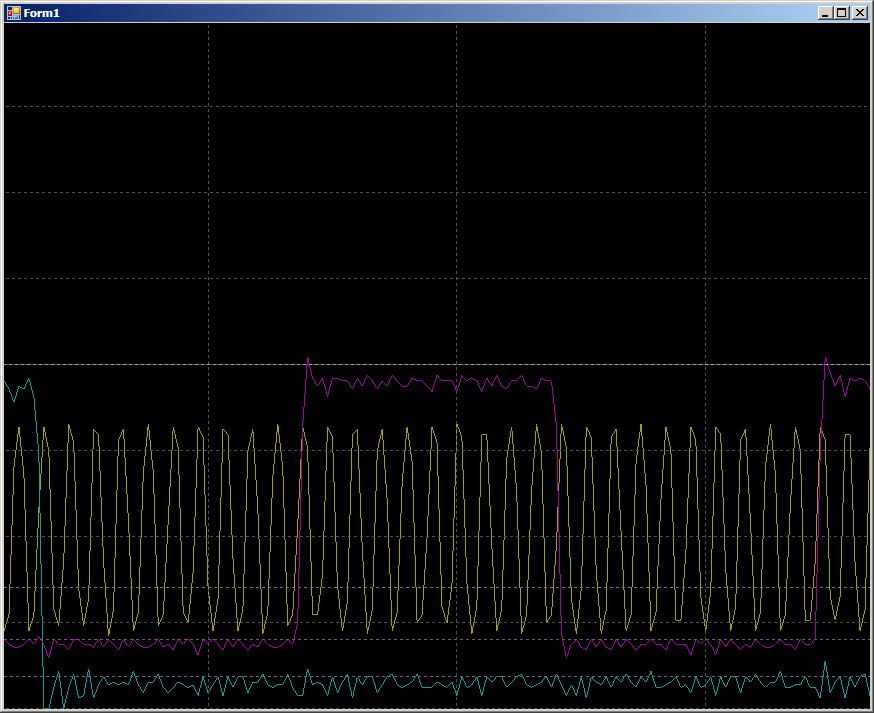
Bentuk gelombang yang dihasilkan sangat mirip dengan yang ada di PSoC.

Di tengah adalah punuk biru besar. Ini adalah proses inisialisasi DMA. Pulsa biru di sebelah kiri diterima sepenuhnya oleh perangkat lunak pada PB1. Regangkan mereka lebih lebar:

2 langkah per pulsa. Pengoperasian sistem seperti yang diharapkan. Tapi sekarang mari kita lihat area yang lebih besar ditandai pada bentuk gelombang utama dengan latar belakang biru gelap. Blok DMA sudah berjalan di lokasi ini.
10 siklus per perubahan jalur GPIO. Sebenarnya, pekerjaan berjalan dengan RAM, dan program ini dilingkarkan dalam siklus konstan. Tidak ada panggilan ke RAM dari inti prosesor. Bus sepenuhnya tersedia untuk unit DMA, tetapi 10 siklus. Tetapi pada kenyataannya, hasilnya tidak jauh berbeda dari yang terlihat di PSoC, jadi mulailah mencari Catatan Aplikasi yang terkait dengan DMA di STM32. Ada beberapa dari mereka. Ada AN2548 di F0 / F1, ada AN3117 di L0 / L1 / L3, ada AN4031 di F2 / F4 / F77. Mungkin ada lagi ...
Tetapi, bagaimanapun, dari mereka kita melihat bahwa di sini juga, latensi yang harus disalahkan. Selain itu, akses batch F103 ke bus dengan DMA tidak mungkin. Mereka dimungkinkan untuk F4, tetapi tidak lebih dari empat kata. Kemudian lagi masalah latensi akan muncul.
Mari kita coba melakukan tindakan yang sama, tetapi dengan bantuan catatan program. Di atas, kami melihat bahwa perekaman langsung ke port dilakukan secara instan. Tapi ada catatan yang agak sempurna. Baris:
// dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set();
tunduk pada pengaturan optimasi tersebut (Anda harus menentukan optimasi untuk waktu):

berubah menjadi kode assembler berikut:
STR r6,[r2,#0x00] MOV r0,#0x20000 STR r0,[r2,#0x00] STR r6,[r2,#0x00]
Dalam penyalinan nyata, akan ada panggilan ke sumber, ke penerima, perubahan dalam variabel loop, bercabang ... Secara umum, banyak overhead (yang, seperti yang diyakini, hanya menghilangkan DMA). Berapa kecepatan perubahan di port? Jadi, kami menulis:
uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
Kode C ++ ini berubah menjadi kode rakitan seperti itu:
MOVS r1,#0x0E LDRH r3,[r0],#0x02 STRH r3,[r2,#0x00] LDRH r3,[r0],#0x02 SUBS r1,r1,#2 STRH r3,[r2,#0x00] CMP r1,#0x00 BGT 0x080032A8
Dan kita mendapatkan:
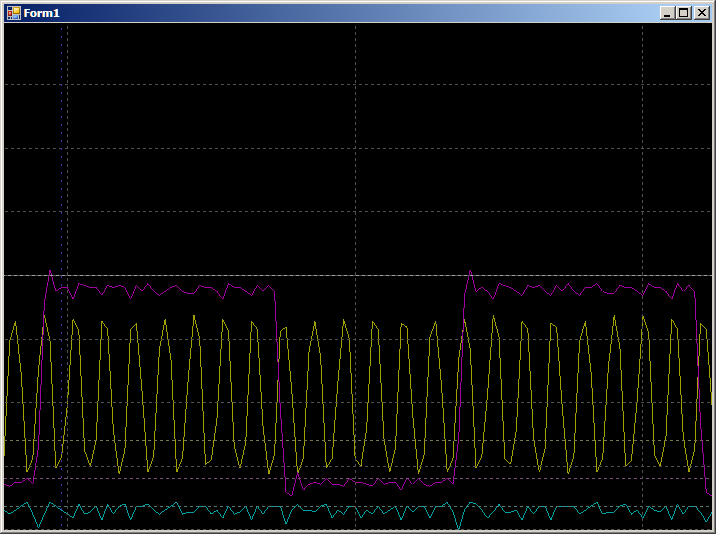
8 langkah di setengah siklus atas dan 6 di bagian bawah (saya periksa, hasilnya diulang untuk semua setengah periode). Perbedaan muncul karena pengoptimal membuat 2 salinan per iterasi. Oleh karena itu, 2 langkah dalam salah satu setengah periode ditambahkan ke operasi cabang.
Secara kasar, dengan menyalin perangkat lunak, 14 langkah dihabiskan untuk menyalin dua kata terhadap 20 langkah yang sama, tetapi oleh DMA. Hasilnya cukup terdokumentasi, tetapi sangat tidak terduga bagi mereka yang belum membaca literatur yang diperluas.Bagus Tetapi apa yang terjadi jika Anda mulai menulis data dalam dua aliran DMA sekaligus? Berapa kecepatan jatuh? Hubungkan blue ray ke PA0 dan tulis ulang program sebagai berikut:
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Pertama, mari kita periksa sifat dari pulsa:
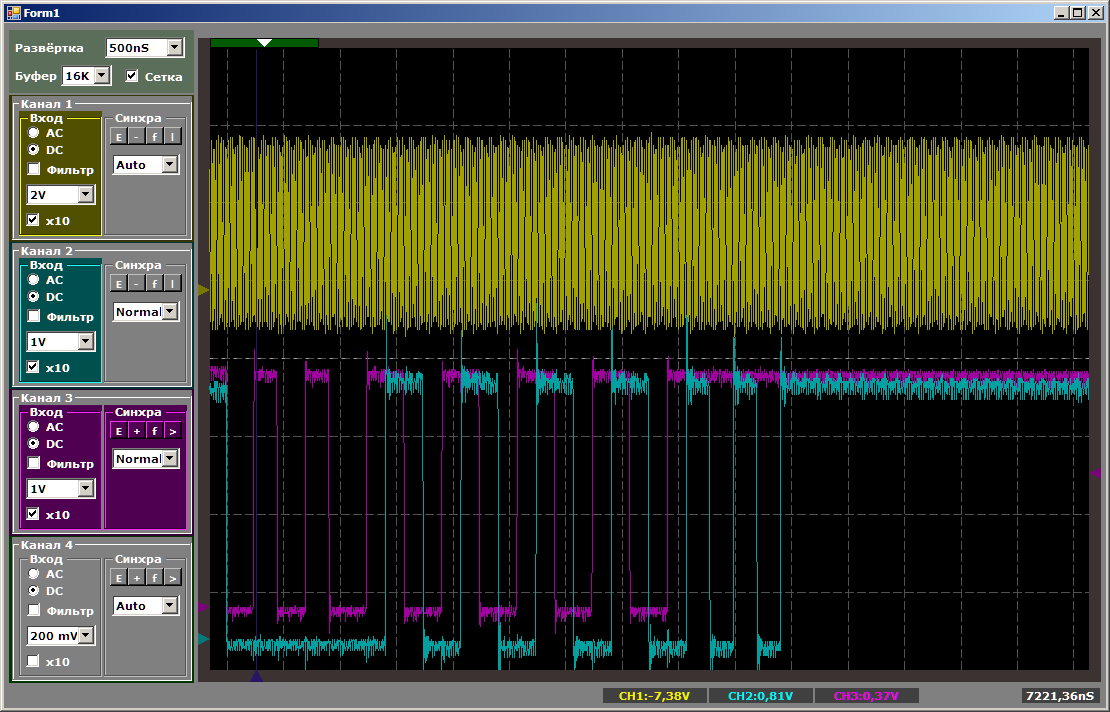
Saat saluran kedua sedang dicari, kecepatan salin untuk yang pertama lebih tinggi. Kemudian, saat menyalin berpasangan, kecepatan turun. Ketika saluran pertama selesai, saluran kedua mulai bekerja lebih cepat. Semuanya logis, tetap hanya untuk mengetahui dengan tepat berapa kecepatan turun.
Meskipun hanya ada satu saluran, perekaman membutuhkan 10 hingga 12 tindakan (digit mengambang).

Selama kolaborasi, kami mendapatkan 16 siklus per catatan di setiap port:
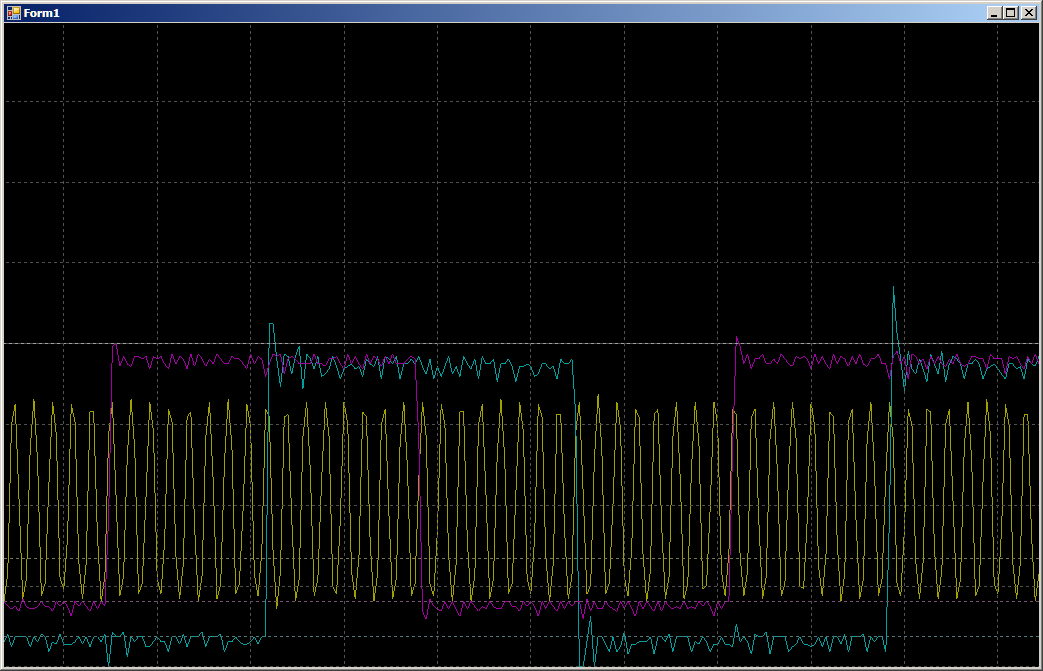
Artinya, kecepatannya tidak terbelah dua. Tetapi bagaimana jika Anda mulai menulis dalam tiga utas sekaligus? Kami menambahkan pekerjaan dengan PC15, karena PC0 bukan output (itu sebabnya bukan 0, 1, 0, 1 ..., tetapi 0x0000,0x8001, 0x0000, 0x8001 ... dikeluarkan dalam larik).
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; typedef Mcucpp::Dma1Channel3 channel3; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2);
Di sini hasilnya sangat tidak terduga sehingga saya mematikan balok yang menampilkan frekuensi jam. Kami tidak punya waktu untuk pengukuran. Kami melihat logika kerja.

Sampai saluran pertama selesai bekerja, yang ketiga tidak mulai bekerja. Tiga saluran sekaligus tidak berfungsi! Sesuatu tentang topik ini dapat disimpulkan dari AppNote ke DMA, dikatakan bahwa F103 hanya memiliki dua Engine dalam satu blok (dan kami menyalin menggunakan satu blok DMA, yang kedua adalah idle sekarang, dan volume artikel sudah sedemikian sehingga saya dapat menggunakannya Saya tidak akan). Kami menulis ulang program sampel sehingga saluran ketiga dimulai lebih awal dari yang lain:

Teks yang sama: // , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Gambar akan berubah sebagai berikut:

Saluran ketiga diluncurkan, bahkan bekerja sama dengan yang pertama, tetapi ketika yang kedua memasuki bisnis, yang ketiga digantikan sampai saluran pertama selesai.
Sedikit tentang prioritas
Sebenarnya, gambar sebelumnya terkait dengan prioritas DMA, ada beberapa. Jika semua saluran yang berfungsi memiliki prioritas yang sama, jumlah mereka ikut bermain. Dalam satu prioritas yang diberikan, yang memiliki jumlah lebih kecil adalah yang memiliki prioritas. Mari kita coba saluran ketiga untuk menunjukkan prioritas global yang berbeda, menaikkannya di atas yang lain (sepanjang jalan, kami juga akan meningkatkan prioritas saluran kedua):

Teks yang sama: channel3::Init (channel3::PriorityVeryHigh|channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel1::PriorityVeryHigh|channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
Sekarang yang pertama yang paling keren akan dirugikan.
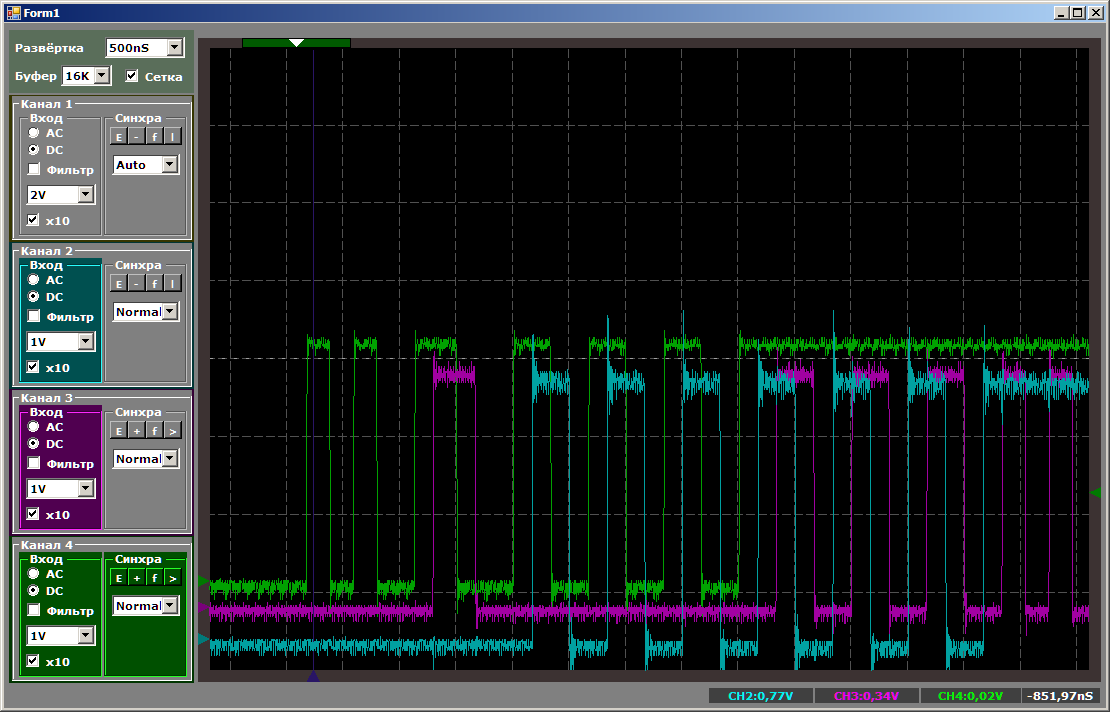
Secara total, kami melihat bahwa walaupun bermain dalam prioritas, STM32F103 tidak dapat meluncurkan lebih dari dua utas pada satu blok DMA. Pada prinsipnya, thread ketiga dapat dijalankan pada inti prosesor. Ini akan memungkinkan kami untuk membandingkan kinerja.
// , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
Pertama, gambaran umum, yang menunjukkan bahwa semuanya bekerja secara paralel dan inti prosesor memiliki kecepatan penyalinan tertinggi:
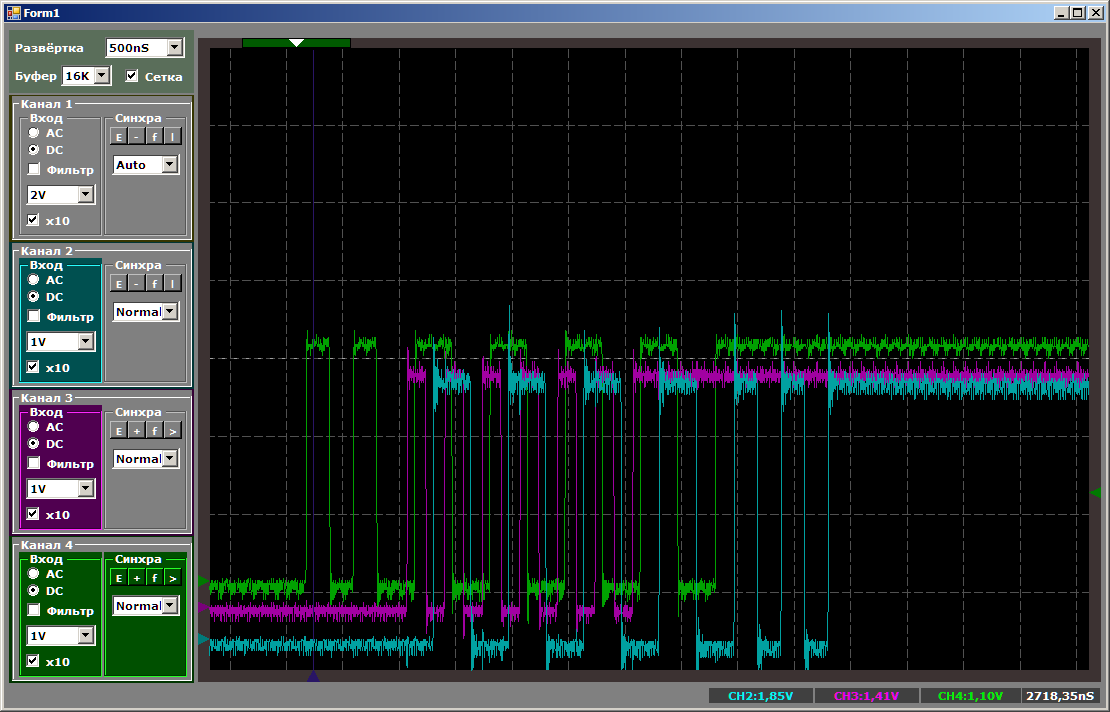
Dan sekarang saya akan memberikan semua orang kesempatan untuk menghitung langkah-langkah pada saat semua aliran salinan aktif:
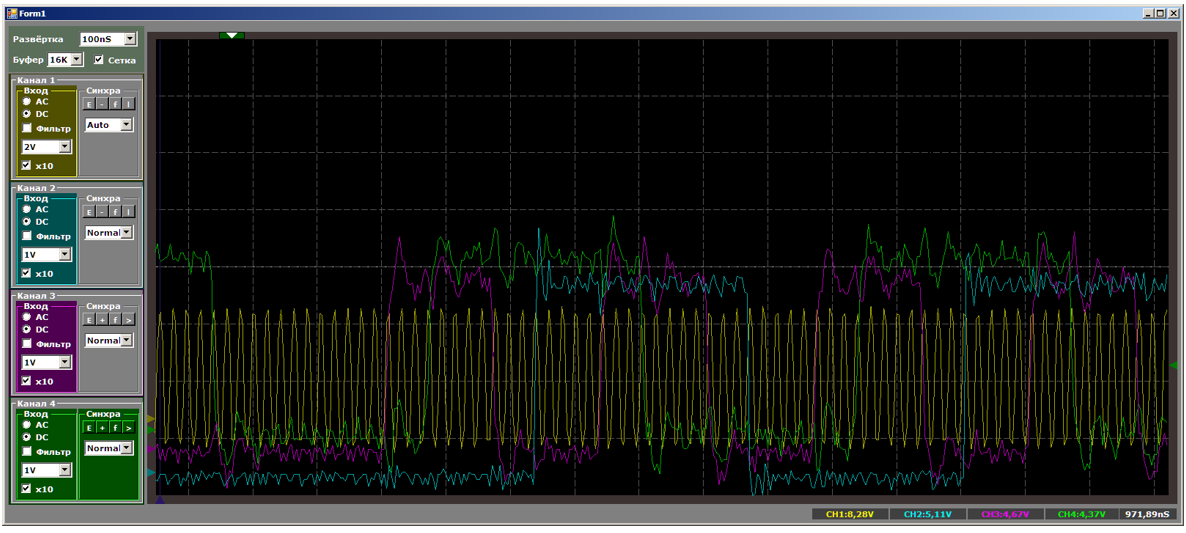
Inti prosesor memprioritaskan semua
Sekarang mari kita kembali ke fakta bahwa selama operasi dua-threaded, sementara saluran kedua disetel, yang pertama memberikan data untuk jumlah siklus clock yang berbeda. Fakta ini juga didokumentasikan dengan baik di AppNote pada DMA. Faktanya adalah bahwa selama pengaturan saluran kedua, permintaan untuk RAM dikirim secara berkala, dan inti prosesor memiliki prioritas lebih tinggi ketika mengakses RAM daripada inti DMA. Ketika prosesor meminta beberapa data, DMA mengambil siklus clock, ia menerima data dengan penundaan, oleh karena itu, itu disalin lebih lambat. Mari kita lakukan percobaan terakhir untuk hari ini. Mari kita bawa pekerjaan ke yang lebih nyata. Setelah memulai DMA, kami tidak akan masuk ke siklus kosong (ketika pasti tidak ada akses ke RAM), tetapi akan melakukan operasi penyalinan dari RAM ke RAM, tetapi operasi ini tidak akan berhubungan dengan operasi inti DMA:
channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint32_t src1[0x200]; uint32_t dest1 [0x200]; while (1) { uint32_t* src = src1; uint32_t* dest = dest1; for (int i=sizeof(src1)/sizeof(src1[0]);i>0;i--) { *dest++ = *src++; } }

Di beberapa tempat, siklus tersebut membentang dari 16 hingga 17 langkah. Saya takut itu akan menjadi lebih buruk.
Mulailah menggambar kesimpulan
Sebenarnya, kita beralih ke apa yang ingin saya katakan.
Saya akan mulai dari jauh. Beberapa tahun yang lalu, mulai mempelajari STM32, saya mempelajari versi MiddleWare untuk USB yang ada pada waktu itu dan bertanya-tanya mengapa pengembang menghapus transfer data melalui DMA. Jelaslah bahwa pada awalnya pilihan semacam itu sudah terlihat, kemudian dipindahkan ke halaman belakang, dan pada akhirnya hanya ada dasar-dasar darinya. Sekarang saya mulai curiga bahwa saya memahami pengembang.
Dalam
artikel pertama tentang UDB, saya mengatakan bahwa meskipun UDB dapat bekerja dengan data paralel, tidak mungkin itu dapat menggantikan GPIF dengan dirinya sendiri, karena bus USB PSoC berjalan pada Kecepatan Penuh versus Kecepatan Tinggi untuk FX2LP. Ternyata ada faktor pembatas yang lebih serius. DMA sama sekali tidak punya waktu untuk mengirimkan data pada kecepatan yang sama dengan yang diberikan GPIF, bahkan di dalam pengontrol, tanpa memperhitungkan bus USB.
Seperti yang Anda lihat, tidak ada DMA entitas tunggal. Pertama, masing-masing produsen membuatnya dengan caranya sendiri. Tidak hanya itu, bahkan satu produsen untuk keluarga yang berbeda dapat memvariasikan pendekatan untuk membangun DMA. Jika Anda berencana untuk memuat unit ini dengan serius, Anda harus mempertimbangkan apakah kebutuhan akan terpenuhi.
Mungkin, perlu untuk mengencerkan aliran pesimistis dengan satu komentar optimis. Saya bahkan akan menyorotnya.
DMA dari pengendali Cortex M memungkinkan Anda untuk meningkatkan kinerja sistem berdasarkan prinsip Javelins yang terkenal: "Luncurkan dan lupakan." Ya, menyalin data perangkat lunak sedikit lebih cepat. Tetapi jika Anda perlu menyalin banyak utas, pengoptimal tidak dapat membuat prosesor menggerakkan semuanya tanpa overhead register yang memuat ulang dan memutar putaran. Selain itu, untuk port yang lambat, prosesor masih harus menunggu ketersediaan, dan DMA melakukan ini di tingkat perangkat keras.Tetapi bahkan di sini berbagai nuansa dimungkinkan. Jika port hanya relatif lambat ... Nah, katakanlah, SPI beroperasi pada frekuensi setinggi mungkin, maka ada situasi yang secara teoritis memungkinkan ketika DMA tidak punya waktu untuk mengumpulkan data dari buffer dan terjadi luapan. Atau sebaliknya - letakkan data dalam register buffer. Ketika aliran data tunggal, ini tidak mungkin terjadi, tetapi ketika ada banyak dari mereka, kami melihat apa yang bisa terjadi overlay menakjubkan. Untuk mengatasinya, Anda harus mengembangkan tugas tidak secara terpisah, tetapi dalam kombinasi. Dan penguji mencoba untuk memprovokasi masalah seperti itu (seperti pekerjaan yang merusak bagi penguji).
Sekali lagi, tidak ada yang menyembunyikan data ini. Tetapi untuk beberapa alasan, semua ini biasanya tidak terdapat dalam dokumen utama, tetapi dalam Catatan Aplikasi. Jadi tugas saya adalah untuk menarik perhatian programmer ke fakta bahwa DMA bukanlah obat mujarab, tetapi hanya alat yang nyaman.
Tapi, tentu saja, tidak hanya programmer, tetapi juga pengembang perangkat keras. Katakanlah, di organisasi kami, kompleks perangkat lunak dan perangkat keras yang besar sedang dikembangkan untuk debugging jarak jauh dari sistem tertanam. Idenya adalah seseorang sedang mengembangkan perangkat, tetapi ingin memesan "firmware" di samping. Dan untuk beberapa alasan, tidak bisa menyediakan peralatan ke samping. Itu bisa sangat besar, bisa mahal, bisa unik dan “membutuhkannya sendiri”, kelompok yang berbeda dapat bekerja dengannya dalam zona waktu yang berbeda, menyediakan semacam pekerjaan multi-shift, dapat selalu diingat ... Secara umum, Anda dapat menemukan alasan banyak, kelompok kami membiarkan tugas ini begitu saja.
Dengan demikian, kompleks debugging harus dapat mensimulasikan sebanyak mungkin perangkat eksternal, dari simulasi sepele dari penekanan tombol ke berbagai protokol SPI, I2C, CAN, 4-20 mA dan lainnya, hal-hal lain, sehingga melalui mereka emulator dapat menciptakan kembali perilaku eksternal yang berbeda. blok yang terhubung ke peralatan yang sedang dikembangkan (saya pribadi pada suatu waktu membuat banyak simulator untuk debugging ground attachment untuk helikopter, di
situs web kami
kasus yang sesuai dicari dengan kata Cassel Aero ).
Jadi, dalam persyaratan teknis untuk pengembangan persyaratan tertentu. Begitu banyak SPI, begitu banyak I2C, begitu banyak GPIO. Mereka harus beroperasi pada frekuensi ekstrim ini dan itu. Segalanya tampak jelas. Kami menempatkan STM32F4 dan ULPI untuk bekerja dengan USB dalam mode HS. Teknologi ini terbukti. Tapi di sinilah akhir pekan yang panjang dengan liburan November, yang saya temukan bersama UDB. Melihat ada yang tidak beres, di malam hari saya mendapat hasil praktis yang diberikan di awal artikel ini. Dan saya menyadari bahwa semuanya, tentu saja, bagus, tetapi tidak untuk proyek ini. Seperti yang telah saya catat, ketika kinerja sistem puncak yang mungkin mendekati batas atas, semuanya harus dirancang tidak secara terpisah, tetapi dalam kompleks.
Tapi di sini desain tugas yang terintegrasi tidak bisa pada prinsipnya.
Hari ini kami bekerja dengan satu peralatan pihak ketiga, besok - dengan sangat berbeda. Bus akan digunakan oleh programmer untuk setiap kasus emulasi sesuai kebijakan mereka. Oleh karena itu, opsi ditolak, sejumlah jembatan FTDI berbeda ditambahkan ke sirkuit. Di dalam bridge, satu, dua atau empat fungsi akan diselesaikan sesuai dengan skema yang kaku, dan di antara bridge-host USB host akan menyelesaikan semuanya. Sayang
Dalam tugas ini, saya tidak bisa mempercayai DMA. Anda dapat, tentu saja, mengatakan bahwa programmer kemudian akan keluar, tetapi jam untuk proses trik adalah biaya tenaga kerja yang harus dihindari.Tapi ini ekstrem. Paling sering, Anda hanya perlu mengingat keterbatasan subsistem DMA (misalnya, memperkenalkan faktor koreksi 10: jika Anda memerlukan aliran 1 juta transaksi per detik, pertimbangkan bahwa ini bukan 1 juta, tetapi 10 juta siklus) dan pertimbangkan kinerja dalam kombinasi.