
"2048" dalam beberapa minggu menandai 5 tahun, yang berarti saatnya untuk menulis sesuatu yang didedikasikan untuk permainan yang luar biasa ini.
Topik permainan independen kecerdasan buatan dalam sebuah teka-teki sangat informatif. Ada berbagai cara untuk mengimplementasikannya dan hari ini kami akan menganalisis yang relatif mudah. Yaitu, kami akan mengajarkan pikiran komputer untuk mengumpulkan derajat dua menggunakan metode Monte Carlo.

Artikel ini ditulis dengan dukungan EDISON Software, sebuah perusahaan yang mengembangkan aplikasi mobile dan menyediakan layanan pengujian perangkat lunak .
Inspirasi untuk pekerjaan ini adalah diskusi tentang stackoverflow, di mana
orang-orang pintar menyarankan cara yang efektif untuk permainan komputer . Rupanya, cara terbaik adalah metode minimax dengan kliping alpha-beta dan dalam beberapa hari publikasi berikutnya akan dikhususkan untuk itu.
Metode kasino disarankan oleh pengguna stackoverflow
 Ronenz
Ronenz sebagai bagian dari diskusi di atas. Seluruh bagian selanjutnya adalah terjemahan dari publikasi.
Metode Monte Carlo
Saya menjadi tertarik pada ide AI untuk game ini, di mana
tidak ada kecerdasan hard-coded (yaitu, tidak ada heuristik, penilaian, dll.). AI harus “hanya tahu” aturan main dan “mengerti” permainan. Ini membedakannya dari kebanyakan AI (seperti di utas ini), karena gameplay, pada kenyataannya, kekuatan brutal dikendalikan oleh fungsi penilaian, mencerminkan pemahaman manusia tentang permainan.
Algoritma AI
Saya menemukan algoritma permainan yang sederhana namun mengejutkan baik: untuk menentukan langkah selanjutnya untuk keadaan lapangan tertentu, AI memainkan permainan dalam RAM, membuat
gerakan acak hingga permainan berakhir dengan kekalahan. Ini dilakukan beberapa kali, dengan skor akhir dilacak. Kemudian, skor akhir rata-rata dihitung dengan mempertimbangkan kursus awal. Langkah awal yang menunjukkan hasil rata-rata tertinggi dipilih sebagai langkah yang sebenarnya dipilih.
Dengan 100 berjalan untuk setiap belokan awal, AI sampai ke ubin 2048 di 80% kasus dan ubin 4096 di 50% kasus. Saat menggunakan 10.000 run, 2048 diperoleh dalam 100% kasus, 70% untuk 4.096 dan sekitar 1% untuk 8.192.
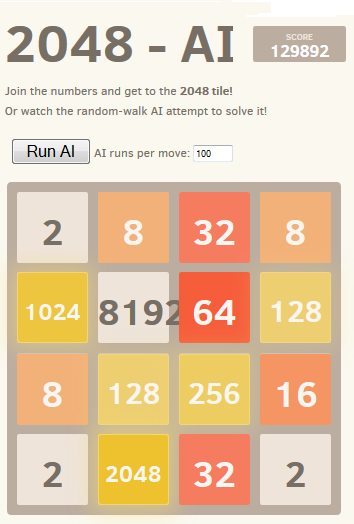 Lihat beraksi
Lihat beraksiHasil terbaik yang dicapai ditunjukkan pada tangkapan layar:
Fakta yang menarik untuk algoritma ini adalah bahwa meskipun game dengan gerakan yang dieksekusi secara acak diharapkan menjadi sangat buruk, namun, memilih yang terbaik (atau paling tidak buruk, jika Anda suka) bergerak mengarah ke gameplay yang sangat baik: tipikal permainan AI Monte Carlo dapat mencetak 70.000 poin untuk 3000 gerakan, tetapi game dengan permainan arbitrer di memori dari posisi mana pun memberikan rata-rata 340 poin tambahan untuk sekitar 40 gerakan tambahan sebelum kalah. (Anda dapat memverifikasi ini sendiri dengan memulai AI dan membuka konsol debug.)
Grafik ini menggambarkan konsep ini: garis biru menunjukkan skor permainan setelah setiap gerakan. Garis merah menunjukkan hasil
terbaik dari algoritma, secara sewenang-wenang membuat gerakan dari posisi ini ke akhir permainan. Bahkan, nilai merah "menarik" yang biru, karena mereka adalah kalimat terbaik dari algoritma. Menariknya, garis merah sedikit di atas garis biru di setiap titik, tetapi garis biru mengurangi kesenjangan semakin banyak.
Saya merasa agak mengejutkan bahwa algoritme tidak selalu mengantisipasi gameplay yang baik, dan tetap memilih langkah yang menghasilkannya (proses yang baik).
Kemudian saya menemukan bahwa metode ini dapat diklasifikasikan sebagai
algoritma pencarian pohon Monte Carlo .
Implementasi dan tautan
Pertama, saya membuat versi JavaScript yang dapat
dilihat beraksi di sini . Versi ini dapat menjalankan 100 proses dalam jumlah waktu yang wajar. Buka konsol untuk informasi lebih lanjut. (
sumber )
Kemudian, untuk bermain-main, saya menggunakan infrastruktur @nneonneo yang sangat dioptimalkan dan mengimplementasikan versi saya di C ++. Versi ini memungkinkan hingga 100.000 berjalan per putaran dan bahkan 1.000.000 jika Anda siap menunggu. Termasuk instruksi perakitan. Semuanya berfungsi di konsol, dan juga memiliki remote control untuk pemutaran di versi web. (
sumber )
Hasil
Anehnya, peningkatan jumlah proses tidak secara fundamental meningkatkan gameplay. Tampaknya strategi ini memiliki batas 80.000 poin dengan ubin 4096 dan semua hasil yang lebih kecil sangat dekat dengan mencapai ubin 8192. Peningkatan dalam jumlah lari dari 100 menjadi 100.000 meningkatkan kemungkinan mencapai batas ini (dari 5% hingga 40%), tetapi tidak mengatasinya.
Pertunjukan 10.000 lari dengan peningkatan sementara hingga 1.000.000 di dekat posisi kritis memungkinkan untuk mengatasi penghalang ini dalam kurang dari 1% kasus dengan jumlah poin maksimum yang dicetak 129892 dan ubin 8192.
Perbaikan dan optimalisasi
Setelah menerapkan algoritma ini, saya mencoba banyak perbaikan, termasuk penggunaan peringkat minimum atau maksimum atau kombinasi nilai minimum, maksimum dan rata-rata. Saya juga mencoba menggunakan kedalaman: alih-alih mencoba menyelesaikan K menjalankan per putaran, saya mencoba gerakan K per daftar gerakan dengan panjang tertentu (misalnya, "atas, atas, kiri") dan memilih langkah pertama dari daftar langkah dengan kemenangan terbaik.
Kemudian saya menerapkan pohon skor yang memperhitungkan probabilitas bersyarat bahwa ia akan dapat menyelesaikan langkah setelah daftar gerakan tertentu.
Namun, tidak satu pun dari ide-ide ini yang menunjukkan keunggulan nyata dibandingkan ide pertama yang sederhana. Saya meninggalkan kode komentar untuk ide-ide ini di sumber C ++.
Saya menambahkan mekanisme Pencarian Dalam, yang sementara meningkatkan jumlah berjalan menjadi 1.000.000 ketika salah satu berjalan secara tidak sengaja berhasil mencapai ubin tertinggi berikutnya. Ini menyebabkan peningkatan kinerja waktu.
Saya akan tertarik untuk mengetahui apakah ada yang punya ide perbaikan lain yang mendukung independensi AI dari area subjek?
Opsi dan klon 2048
Untuk bersenang-senang, saya juga mengimplementasikan AI sebagai bookmarklet, menghubungkannya ke kontrol game. Ini memungkinkan Anda untuk bekerja dengan gim asli dan banyak variasinya.
Hal ini dimungkinkan karena sifat AI yang independen domain. Beberapa opsi cukup orisinal, seperti klon heksagonal.
2048.xlsm
Aplikasi Excel itu sendiri
dapat diunduh dari Google .
Gambar dapat diklik - gambar ukuran penuh akan terbuka.
Secara singkat tentang antarmuka dan fungsionalitas aplikasi.
Untuk mulai bermain, Anda harus mengklik tombol "
Pengguna: mulai permainan ". Ketika Anda menekan tombol ini lagi, tulisan berubah dari "
Pengguna: mulai permainan " menjadi "
Pengguna: akhiri permainan " dan sebaliknya, yaitu, kapan saja Anda dapat menghentikan permainan dan kemudian mulai lagi. Saat permainan berhenti, Anda dapat secara manual mengubah perataan di lapangan, meningkatkan atau memperburuk posisi Anda untuk menguji atau memverifikasi beberapa ide.
Selama permainan itu sendiri, Anda dapat bergerak dengan dua cara:
- Keyboard: cukup dengan menekan tombol "atas", "bawah", "kiri", "kanan".
- Dengan mouse: mengklik sel dengan panah besar yang menunjukkan arah yang diinginkan.
Tombol "
Bidang Baru " membersihkan lapangan bermain dan secara acak menempatkan "dua" dan "empat" di atasnya.
Yang paling menarik adalah bahwa metode Monte Carlo diimplementasikan, persis dalam bentuk di mana pria dengan stackoverflow mengusulkannya. Pada setiap posisi, komputer dalam memori melewati cabang acak untuk setiap gerakan pertama ("atas", "turun", "kiri", "kanan") hingga menyebabkan kerugian. Secara statistik, arah yang paling disukai ditandai dengan warna merah di tabel khusus di bawah ini. Anda dapat menggunakannya sebagai petunjuk jika Anda melihat permainan Anda sendiri macet dan Anda perlu menyelamatkan diri. ;)
Di atas tabel terdapat kotak centang dengan opsi analisis. Saat ini, hanya Monte Carlo yang telah diputuskan, sisanya akan ditambahkan dalam beberapa hari mendatang (sebagai akibatnya akan ada lebih banyak bahaya dengan memperbarui aplikasi excel dan penjelasan teori).
Ada juga tombol
AI: game . Dengan mengkliknya, asisten komputer akan membuat satu gerakan sesuai dengan metode Monte Carlo atau yang lain yang dipilih dalam kelompok saklar (minimax dan jaringan saraf akan bekerja dalam daftar ini sedikit kemudian).
Semua artikel seri AI dan 2048