Jika Anda hidup di antara orang-orang gila, Anda harus belajar menjadi orang gila sendiriPernahkah Anda mencoba "belajar untuk menjadi gila"? Tugas non-sepele. Anda bahkan tidak akan menemukan teknik normal, karena semua orang menjadi gila dengan caranya sendiri. Upaya pertama saya: teori konspirasi. Teorinya tidak melibatkan praktik, yang berarti Anda tidak perlu bekerja keras. Sekali lagi, dalam situasi apa pun, tidak ada yang akan menderita.
Bagaimana cara membuat teori konspirasi?Membuat teori konspirasi relatif sederhana. Kami membutuhkan ide yang cukup sederhana untuk diterima oleh 90% populasi. Itu harus kontroversial sehingga 5% dari populasi dapat menjelaskan 90% idiot apa mereka. Akhirnya, kita perlu penelitian yang tidak dimengerti oleh 95% orang, tetapi digunakan 90% sebagai argumen "orang terbukti lebih pintar daripada kita ...".
Komputasi kuantum adalah bidang yang bagus untuk studi semacam itu. Anda dapat menggulung skema sederhana, tetapi kata "kuantum" akan menambah bobot pada hasilnya.
Objek penelitian adalah permainan, karena objeknya adalah karena anak muda yang sederhana dan akrab. Siapa yang terlibat dalam komputasi kuantum dan game? Google
Jadi, teori sesat: setelah 5 tahun, Page dan Green akan memutuskan siapa yang akan menjadi hal utama di Google, dan melakukannya dengan bantuan permainan. Masing-masing dari mereka memiliki sekelompok peneliti. Tim AlphaGo dengan jaringan saraf
tempur mereka menarik lawan di Go. Lawan terpaksa mencari metode baru, dan masih menemukan instrumen keunggulan
total : komputasi kuantum.
Bisakah saya menggunakan Quantum Computing untuk game? Mudah Mari kita tunjukkan misalnya bahwa permainan "pemburu rubah" dapat "diselesaikan" dalam 6 gerakan. Demi kredibilitas, kami membatasi diri hingga 15 qubit (quirk editor online tidak meniru lebih dari lima belas), demi kesederhanaan, kami mengabaikan batasan arsitektur prosesor dan koreksi kesalahan.
Aturannya
Sangat sederhana.
Ada lima lubang yang disusun secara berurutan (kami beri nomor 0-1-2-3-4). Salah satunya adalah rubah. Setiap malam, rubah bergerak ke bulu berikutnya ke kiri atau ke kanan. Setiap pagi, pemburu dapat memeriksa satu lubang untuk dipilih. Tugas pemburu adalah menangkap rubah. Tugas rubah adalah untuk bertahan hidup. Secara teori, rubah dapat lari dari pemburu selamanya. Dalam praktiknya, ada strategi kemenangan: periksa lubang 1-2-3-1-2-3. Hanya strategi ini yang akan saya uji.
Membangun skema
Mari kita mulai dengan inisiasi qubit 0-1-2-3-4 (5 lubang).
Di sini Anda dapat mengedit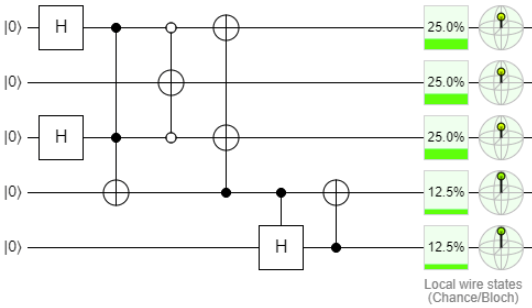
Bahkan, setelah inisiasi, kami memiliki sistem di mana, setelah pengukuran, satu qubit akan tunggal. Probabilitas "kesatuan" berbeda untuk setiap qubit, tetapi dalam kasus kami ini tidak kritis. Kita harus meninggalkan ruang untuk diskusi tentang skema (dan teori kita pada saat bersamaan).
Pada Q #, kami mendapatkan kode seperti ini:
operation TestStrategy () : (Result) { let res = Zero; using(qubits=Qubit[16]) {
TestStrategy akan menguji strategi kami 1-2-3-1-2-3, InitFoxHoles () bertanggung jawab hanya untuk inisiasi lubang rubah. Mari kita periksa inisiasinya. Salin TestStrategy, mulai inisiasi, ukur 5 qubit pertama dan kembalikan nilainya.
operation TestInit(): (Result, Result, Result, Result, Result) { body { mutable res0 = Zero; mutable res1 = Zero; mutable res2 = Zero; mutable res3 = Zero; mutable res4 = Zero; using(qubits=Qubit[16]) {
Kami akan menjalankan tes seribu kali (beberapa kali berjalan adalah khas dari algoritma kuantum, di beberapa tempat bahkan diperlukan). Kode panggilan - di bawah spoiler, hasil: pada layar di bawah ini.
Uji inisiasi dengan cepat static void TestInitiation() { using (var sim = new QuantumSimulator()) { var initedQubitsValues = Enumerable.Range(0, 5) .ToDictionary(qubitIndex => qubitIndex, oneMesaured => 0); for (int i = 0; i < 1000; i++) { (Result, Result, Result, Result, Result) result = TestInit.Run(sim).Result; if (result.Item1 == Result.One) { initedQubitsValues[0]++; } if (result.Item2 == Result.One) { initedQubitsValues[1]++; } if (result.Item3 == Result.One) { initedQubitsValues[2]++; } if (result.Item4 == Result.One) { initedQubitsValues[3]++; } if (result.Item5 == Result.One) { initedQubitsValues[4]++; } } Console.WriteLine($"Qubit-0 initiations: {initedQubitsValues[0]}"); Console.WriteLine($"Qubit-1 initiations: {initedQubitsValues[1]}"); Console.WriteLine($"Qubit-2 initiations: {initedQubitsValues[2]}"); Console.WriteLine($"Qubit-3 initiations: {initedQubitsValues[3]}"); Console.WriteLine($"Qubit-4 initiations: {initedQubitsValues[4]}"); } }

Ada yang salah. Distribusi yang hampir seragam diharapkan. Alasannya sederhana: pada langkah 3, saya membalikkan qubit ketiga, bukan yang pertama: (Terkendali (X)) ([daftar [0], daftar [2]], daftar [3]);
tidak baik copy-paste lama.
Kami memperbaiki kode, menjalankan tes:

Sudah lebih baik. Anda dapat melihat kode di lobak, versi
Komit 1Di mana menjalankan rubah?
Pilih qubit kelima (penomoran dimulai dari atas) di bawah arahan rubah saat ini. Kami setuju bahwa nol berarti gerakan ke bawah, unit berarti gerakan ke atas. Jelas, jika rubah sudah berada di lubang nol - itu harus bergerak ke bawah. Jika rubah berada di lubang keempat, ia bergerak ke atas. Dalam kasus lain, rubah dapat bergerak ke atas dan ke bawah. Menurut aturan sederhana ini, kita dapat mengatur "qubit dari arah saat ini" ke 0, 1, atau superposisi nol dan satu. Kami melihat kode di repositori,
Komit 2 .
 Skema di editor.
Skema di editor.Kode dan tes
static void TestMovementDirectionSetup() { using (var sim = new QuantumSimulator()) { List<string> results = new List<string>(); string initedCubit = null; string moveDirection = null; for (int i = 0; i < 1000; i++) { (Result, Result, Result, Result, Result, Result) result = Quantum.FoxHunter.TestMovementDirectionSetup.Run(sim).Result; if (result.Item1 == Result.One) { initedCubit = "0"; } if (result.Item2 == Result.One) { initedCubit = "1"; } if (result.Item3 == Result.One) { initedCubit = "2"; } if (result.Item4 == Result.One) { initedCubit = "3"; } if (result.Item5 == Result.One) { initedCubit = "4"; } if (result.Item6 == Result.One) { moveDirection = "1"; } else { moveDirection = "0"; } results.Add($"{initedCubit}{moveDirection}"); } foreach(var group in results .GroupBy(result => result) .OrderBy(group => group.Key)) { Console.WriteLine($"{group.Key} was measured {group.Count()} times"); } Console.WriteLine($"\r\nTotal measures: {results.Count()}"); } }

Gerakan
Diimplementasikan oleh SWAP yang terkontrol. Jika qubit pengendali adalah single - swap down. Jika qubit pengontrol adalah nol, kami bertukar.
 Skema di editor
Skema di editor .
Q #: pernyataan untuk tes operation TestFirstMovement(): (Result, Result, Result, Result, Result, Result) { body { mutable res0 = Zero; mutable res1 = Zero; mutable res2 = Zero; mutable res3 = Zero; mutable res4 = Zero; mutable res5 = Zero; using(qubits=Qubit[16]) { InitFoxHoles(qubits); SetupMovementDirection(qubits); MakeMovement(qubits); set res0 = M(qubits[0]); set res1 = M(qubits[1]); set res2 = M(qubits[2]); set res3 = M(qubits[3]); set res4 = M(qubits[4]); set res5 = M(qubits[5]); ResetAll(qubits);
Kode C # static void TestFirstMove() { using (var sim = new QuantumSimulator()) { List<string> results = new List<string>(); string initedCubit = null; string moveDirection = null; for (int i = 0; i < 1000; i++) { (Result, Result, Result, Result, Result, Result) result = Quantum.FoxHunter.TestFirstMovement.Run(sim).Result; if (result.Item1 == Result.One) { initedCubit = "0"; } if (result.Item2 == Result.One) { initedCubit = "1"; } if (result.Item3 == Result.One) { initedCubit = "2"; } if (result.Item4 == Result.One) { initedCubit = "3"; } if (result.Item5 == Result.One) { initedCubit = "4"; } if (result.Item6 == Result.One) { moveDirection = "1"; } else { moveDirection = "0"; } results.Add($"{initedCubit}{moveDirection}"); }
Kode dapat dilihat di
Komit 3 .
Kami membuat 6 gerakan
Akhirnya, kami memilih qubit keenam untuk status permainan (rubah gratis / rubah tidak gratis). Unit ini sesuai dengan rubah gratis. Kami akan bergerak lebih jauh hanya dengan qubit status tunggal.
Qubit 7,8,9,10,11 akan menyimpan sejarah pergerakan. Setelah setiap gerakan, kita akan menukar salah satu dari mereka dengan qubit dari arah saat ini (ini akan memungkinkan kita untuk menyimpan sejarah bergerak dan mengatur ulang qubit dari arah saat ini sebelum setiap gerakan).
 Skema terlampir
Skema terlampir .
Q #: pernyataan untuk tes operation TestSixMovements(): (Result) { body { mutable res = Zero; using(qubits=Qubit[16]) { ResetAll(qubits); InitFoxHoles(qubits); X(qubits[6]);
C #: pengujian static void TestMovements() { using (var sim = new QuantumSimulator()) { int zerosCount = 0; for (int i = 0; i < 1000; i++) { Result result = Quantum.FoxHunter.TestSixMovements.Run(sim).Result; if(result == Result.Zero) { zerosCount++; } } Console.WriteLine($"\r\nTotal zeroes: {zerosCount}"); } }
Kami melihat
Komit 4 .
Sentuhan akhir
Kami memiliki kesalahan di sirkuit. Karena kami menguji strategi 1-2-3-1-2-3, kami memeriksa setiap lubang dua kali. Dengan demikian, setelah menangkap rubah pada langkah pertama, kita akan melewati status qubit dua kali (pada langkah pertama dan keempat).
Untuk menghindari situasi ini, kami menggunakan 12 qubit untuk memperbaiki status setelah bergerak 4-5-6. Selain itu, kami menambahkan definisi kemenangan: jika setidaknya satu dari status qubit berubah menjadi nol, kami menang.
 Skema terakhir
Skema terakhir .
T #: perbaiki operator 6 move operation MakeSixMovements(qubits: Qubit[]) : Unit { body {
T #: memperbaiki strategi pengujian operator 1-2-3-1-2-3 operation TestStrategy () : (Result) {
C #: jalankan pemeriksaan terakhir static void RunFoxHunt() { Stopwatch sw = new Stopwatch(); sw.Start(); using (var sim = new QuantumSimulator()) { var foxSurvives = 0; var hunterWins = 0; for (int i = 0; i < 1000; i++) { var result = (Result)(TestStrategy.Run(sim).Result); if (result == Result.Zero) { foxSurvives++; } else { hunterWins++; } } Console.WriteLine($"Fox survives: \t{foxSurvives}"); Console.WriteLine($"Hunter wins: \t{hunterWins}"); } sw.Stop(); Console.WriteLine($"Experiment finished. " + $"Time spent: {sw.ElapsedMilliseconds / 1000} seconds"); }
 Berkomitmen 5
Berkomitmen 5 .
Apa yang mengikuti dari ini
Pada prinsipnya, skema ini dapat dioptimalkan baik dalam jumlah qubit dan dalam jumlah operasi. Optimalisasi sepele untuk jumlah qubit adalah untuk menyingkirkan qubit-13, hanya mengembalikan 6 dan 12. Optimasi untuk operasi - untuk membuat bidikan pertama segera setelah inisiasi. Namun, biarkan ini bekerja untuk teknisi Google.
Seperti yang Anda lihat, siapa pun yang dangkal akrab dengan komputasi kuantum dapat dengan aman memainkan "pemburu rubah." Jika kami memiliki sedikit qubit lagi, kami dapat menemukan solusi optimal, dan tidak memeriksa yang ada. Sangat mungkin bahwa tic-tac-toe (dan versi kuantum mereka), catur, catur, Go akan jatuh berikutnya.
Pada saat yang sama, masalah "solvabilitas" game seperti DotA, Starcraft dan Doom tetap terbuka. Untuk komputasi kuantum, penyimpanan seluruh riwayat klik adalah karakteristik. Kami mengambil APM (Tindakan Per Menit) dari 500, kalikan dengan jumlah pemain, kalikan dengan jumlah menit, tambahkan keacakan permainan itu sendiri - jumlah qubit yang diperlukan untuk menyimpan semua informasi tumbuh terlalu cepat.
Jadi, memilih game dalam kompetisi kecil antara Brin dan Page dapat memainkan peran yang menentukan. Namun, generasi game yang “sama sulitnya” untuk komputer klasik dan kuantum layak mendapatkan teorinya sendiri.