
Nama saya Elena Rastorgueva, saya bertanggung jawab untuk produk Factor di
HFLabs . Factor adalah perusahaan algoritmik yang sangat rumit, yang memproses data pada skala industri.
Dalam artikel itu, saya akan memberi tahu Anda bagaimana kami mulai menguji "Faktor", bagaimana autotest dikembangkan dan mengapa kami sampai pada kerangka kerja yang ditulis sendiri.
Produk macam apa ini - “Faktor”
"Factor" membersihkan data dalam database dengan jutaan pelanggan: menghapus kesalahan ketik pada nama, telepon dan email, memeriksa paspor, melakukan lebih banyak hal. Yang paling sulit adalah memperbaiki alamat surat.
 Alamat ditulis dalam ratusan cara, sehingga Factor memiliki alat algoritmik yang kuat di bawah tenda
Alamat ditulis dalam ratusan cara, sehingga Factor memiliki alat algoritmik yang kuat di bawah tenda"Factor" berfungsi sebagai layanan: input data - data keluaran.
Ini adalah sistem tanpa kewarganegaraan di mana setiap panggilan independen dari yang sebelumnya. Stateless sangat menyederhanakan kehidupan penguji. Jauh lebih sulit untuk menguji sistem stateful ketika urutan tindakan penting.
Produk harus dapat diandalkan sebagai ISS, karena digunakan oleh bank, operator seluler, asuransi, dan pengecer tingkat Lenta. Kami menjawab kesalahan dengan kepala kami sejauh tidak adanya kesalahan adalah bagian dari SLA dalam kontrak dengan pelanggan.
Karena persyaratan reliabilitas autotests, kami menulis dari awal pengembangan. Salah satu kriteria untuk kesiapan tugas adalah "Menambahkan AutoTests".
Dimulai dengan pemeriksaan manual dan autotest
Kami meluncurkan Factor pada tahun 2005 dan pertama kali mengujinya dengan tangan kami. Di pagi hari, tester menjalankan autotest pada file dengan kasus dan membandingkan hasil pemrosesan data dengan hasil hari sebelumnya: apa yang berubah setelah kode kemarin melakukan.
Prosesnya bisa memakan waktu setengah hari, penyelarasan ini tidak baik. Oleh karena itu, kami mengambil set tes minimum untuk fungsionalitas utama dan dibungkus dengan unit test. Tes ini cepat, dan pengembang sendiri menjalankannya sebelum melakukan.
Tes unit sangat nyaman dan sangat cepat sehingga kami menambahkan ribuan dari mereka. Dan kemudian kami menabraknya: ketika tes terlihat seperti selembar ribuan keping kode, tidak mudah untuk menggulir ke tempat yang tepat. Belum lagi menambah atau memperbarui.
 Tes unit untuk memeriksa format SNILS
Tes unit untuk memeriksa format SNILSSelain itu, sesuatu yang tidak terduga tiba-tiba muncul di data industri yang tidak mencakup pengujian unit. Misalnya, pelanggan baru datang dengan fitur baru di alamat, unit test tidak mencakup fitur ini. Anda harus duduk dan melihat tes mana yang akan ditambahkan untuk data baru. Kami masih melakukan ini secara manual.
Buat kerangka kerja Anda sendiri
Dalam pengujian unit tradisional, data dan kode digabungkan, sulit untuk menemukan bagian yang tepat.
Oleh karena itu, kami mencoba autotest dalam paradigma
Data Driven Testing (DDT) . DDT adalah ketika data untuk pengujian disimpan secara terpisah dari kode untuk pengujian.
Kasus dimuat dari file excel, mereka berada di kolom "Data mentah" dan "Hasil yang diharapkan". DDT adalah sebuah terobosan: memperbarui kasus di "exelnik" lebih sederhana.
Sedikit demi sedikit, kami mengembangkan pendekatan dan mengembangkan kerangka pengujian kami sendiri. Ini menerima file teks sebagai input, di dalamnya adalah sumber data dan hasil yang diharapkan.
 Kami menolak dari file excel sebagai penyimpanan: file teks terbuka lebih cepat, tidak mengubah konten, lebih mudah untuk mengumpulkan data dari mereka
Kami menolak dari file excel sebagai penyimpanan: file teks terbuka lebih cepat, tidak mengubah konten, lebih mudah untuk mengumpulkan data dari merekaKerangka kerja ini dibantu oleh alat standar:
- TeamCity secara otomatis menjalankan tes setiap malam;
- testNG membandingkan hasil yang diharapkan dan aktual.
 Jika hasilnya berbeda dari yang diharapkan, di TeamCity tes akan memerah. Jika semuanya sebagaimana mestinya, tes ini berwarna hijau
Jika hasilnya berbeda dari yang diharapkan, di TeamCity tes akan memerah. Jika semuanya sebagaimana mestinya, tes ini berwarna hijauMemodifikasi kerangka kerja untuk Anda sendiri
12 tahun telah berlalu sejak itu. Selama ini, kerangka kerja telah ditumbuhi dengan kemampuan yang tidak ada dalam solusi standar.
Akuntansi untuk status tugas di Jira. HFLabs mematuhi
Test Driven Development : pertama kami menulis tes atau menambahkan kasus uji untuk perilaku baru, dan baru kemudian mengubah fungsinya.
Kami mematikan kasus baru dengan mengomentari saluran. Kalau tidak, mereka pertama kali jatuh dan ikut campur, karena case menambahkan fitur atau perbaikan bug sebelumnya.
Tetapi tugas tersebut mungkin tidak dapat menyelesaikan kasus uji yang sesuai: bug akan menjadi sangat langka atau pelanggan akan membawa sesuatu yang lebih penting. Beberapa tugas tergantung selama berbulan-bulan dengan prioritas rendah, dan kasus-kasus yang terputus diakumulasikan. Pada saat yang sama, tidak jelas tugas apa yang dimiliki setiap kasus, apakah kasus ini dapat dihapus.
Oleh karena itu, kami menambahkan nomor tugas ke kasing yang terputus dan mengacaukan sedikit otomatisasi. Sekarang semuanya berjalan seperti ini:
- test case dinonaktifkan dengan mencocokkannya dengan tugas terbuka di Jira;

Untuk melampirkan kasing ke tugas, tulis di depannya # dan nomor tugas
- kerangka kerja menjalankan tes bahkan pada kasus yang dinonaktifkan. Tetapi mengabaikan crash saat tugas terbuka di Jira;
- begitu tugas ditutup, tes mulai jatuh pada kasus-kasus yang melekat padanya. Ini adalah sinyal: mereka melewati tugas, tetapi lupa menghidupkan kasing;
- jika tiba-tiba tes untuk kasus terputus mulai lulus dengan tugas terbuka, kerangka kerja juga akan menginformasikan hal ini. Mungkin sudah waktunya untuk mengaktifkan case atau menutup tugas yang dilampirkan padanya (ditambah memperbarui catatan rilis dan menginformasikan pelanggan).

Kerangka kerja mengatakan kasus terputus sedang terjadi. Mungkin seseorang memperbaiki kode sebagai bagian dari tugas lain, dan sekarang semuanya berfungsi
Jadi kami menyelamatkan TDD dan mengalahkan kelupaan saat mengelola kasus uji.
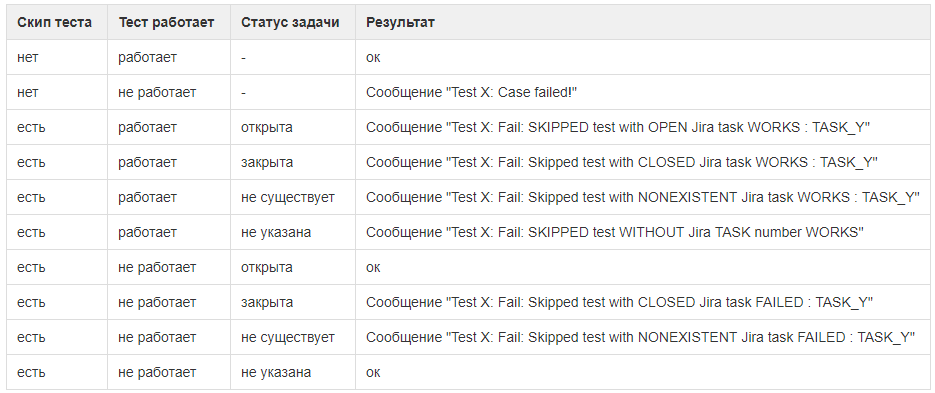 Kami mendokumentasikan semua opsi dengan status kasus uji dan tugas terkait, agar tidak lupaMemperbarui kasus uji dalam mode semi-otomatis.
Kami mendokumentasikan semua opsi dengan status kasus uji dan tugas terkait, agar tidak lupaMemperbarui kasus uji dalam mode semi-otomatis. Tampaknya jika tes gagal, cari kesalahan dalam kode. Tetapi bagi kami ini tidak selalu terjadi. Terkadang kasus pengujian perlu diperbarui, karena persyaratan untuk hasilnya telah berubah.
Misalnya, sebelum pelanggan di alamat yang dibuka ingin "g. Moskow ”dalam satu bidang. Sekarang dia telah mengubah arsitektur database, dia ingin "kota" di satu bidang, "Moskow" di bidang lain. Sudah waktunya untuk mengubah kasus uji.
Untuk tes jatuh, TeamCity menunjukkan perbedaan antara hasil yang diharapkan dan hasil aktual. Sebelumnya, kami menyalin perbedaan ini dan memperbarui test case dengan tangan kami. Untuk perubahan besar-besaran - acara yang sangat mahal.
 Contoh nyata: kami mengajarkan "Faktor" untuk menentukan negara dengan nomor telepon, tes di TeamCity turun. Sebuah tolok ukur baru dapat diambil dari hasil aktual, tetapi butuh waktu lama
Contoh nyata: kami mengajarkan "Faktor" untuk menentukan negara dengan nomor telepon, tes di TeamCity turun. Sebuah tolok ukur baru dapat diambil dari hasil aktual, tetapi butuh waktu lamaKami membuat kerangka kerja memperbarui tolok ukur itu sendiri. Untuk melakukan ini, setelah menjalankan tes, ini menggantikan hasil pembersihan yang diharapkan dalam standar dengan yang sebenarnya di mana mereka tidak cocok. Hasilnya disimpan dalam artefak sebagai file pembaruan kasus.
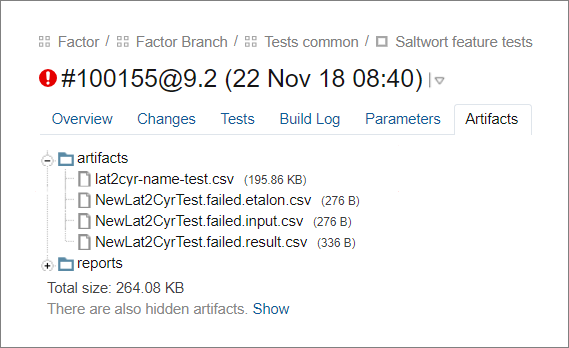 File pertama adalah patokan baru di mana kerangka kerja telah memperbarui hasil yang diharapkan. File yang tersisa adalah data input, standar lama dan data aktual untuk kasus yang terjatuh.
File pertama adalah patokan baru di mana kerangka kerja telah memperbarui hasil yang diharapkan. File yang tersisa adalah data input, standar lama dan data aktual untuk kasus yang terjatuh.Dengan tolok ukur baru, penguji memperbarui kasing dalam tiga langkah.
- Unduh file yang dihasilkan.
- Memeriksa melalui alat penggabungan apa saja perubahan yang ada di tolok ukur baru. Hanya menyisakan yang diperlukan.
- Berkomitmen
 Penguji memeriksa apakah pembaruan dalam standar baru sudah benar dan komit
Penguji memeriksa apakah pembaruan dalam standar baru sudah benar dan komitYa, jika diperbarui tanpa pertimbangan, tidak ada hal baik yang akan terjadi. Tetapi ada risiko memperbarui tanpa pertimbangan saat bekerja secara manual.
Stabilisasi data uji dengan bertopik. "Factor" mengembalikan data yang diproses dalam lusinan bidang. Ada banyak komponen dalam satu alamat saja: indeks, wilayah, tipe wilayah, tipe kota, kota, tipe jalan, rumah, gedung, gedung, apartemen. Bagi mereka, "Faktor" menangkap IFTS, OKATO, OKTMO dan bahkan hal-hal kecil. Jadi dari satu baris pada input lusinan nilai diperoleh.
Tidak semua bidang dari hasil perlu diperiksa dengan kasus uji. Misalnya, pengenalan alamat yang sama secara langsung tergantung pada direktori negara - FIAS. Dan di dalamnya bidang berubah secara teratur, untuk tugas-tugas kami mereka benar-benar asing. Memperbarui beberapa kode CLADR untuk rumah menjatuhkan ratusan kasus uji.
Kami menambahkan bertopik pada hasil yang diharapkan ketika kami menyadari bahwa kami membuang-buang waktu kami menganalisis jatuh tidak penting.
Ketika bidang tidak perlu diperiksa sama sekali, penguji menulis simbol dalam hasil yang diharapkan:
$$ DNV $$ . Kapan bidang harus diisi, tetapi nilainya sendiri tidak penting:
$$ NE $$ .
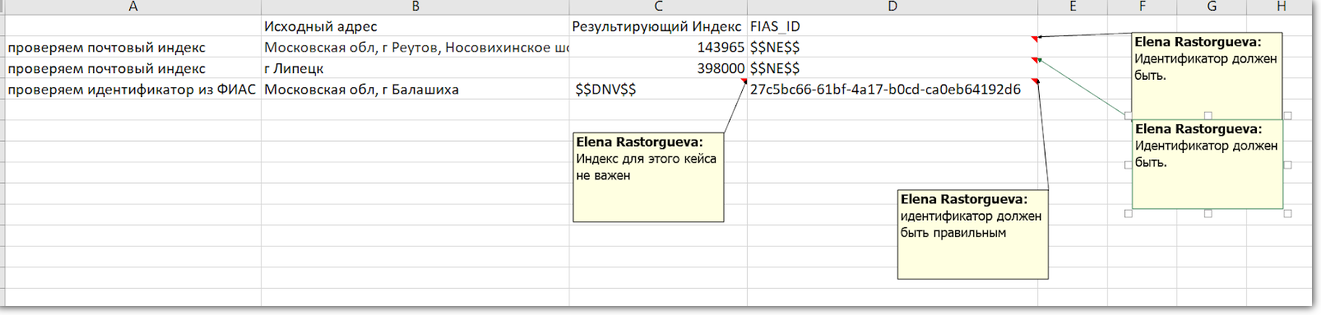 ID FIAS selalu ada di alamat, jadi kami memeriksa semua tes. Jika bidang itu kosong, ada sesuatu yang salah. Tetapi indeks mungkin tidak, oleh karena itu, ketika memeriksa ID FIAS, kami mengabaikan indeks
ID FIAS selalu ada di alamat, jadi kami memeriksa semua tes. Jika bidang itu kosong, ada sesuatu yang salah. Tetapi indeks mungkin tidak, oleh karena itu, ketika memeriksa ID FIAS, kami mengabaikan indeksAnda bisa pergi ke arah lain dan memisahkan tes: masing-masing bidang memiliki sendiri. Tapi itu sulit, karena tidak semuanya bisa diisolasi. Misalnya, "kota" dan "jalan" adalah bagian dari alamat dan tanpa satu sama lain tidak masuk akal.
Kerangka kerja yang ditulis sendiri lebih nyaman
Karena itu, saya sama sekali tidak menganggap membuat kerangka kerja saya sendiri sebagai upaya bodoh. Jika kami tidak membuat alat sendiri, kami tidak akan menerima begitu banyak peluang baru dan fleksibilitas seperti itu.
Mematikan kotak teks dengan status tugas, menghasilkan tolok ukur baru, dan bertopik untuk hasilnya adalah hal-hal yang sekarang diminta penguji kami dalam kerangka kerja lain. Jika kami mengambil solusi standar, kami tidak akan pernah bisa melakukan itu.
Jika Anda suka melakukan hal-hal rumit dalam usaha, datanglah kepada kami. Sekarang kami mencari pengembang java , gaji dari 135.000 ₽ tanpa pajak penghasilan pribadi.