Kami terus berbicara tentang proyek penelitian bersama antara siswa kami dan JetBrains Research. Pada artikel ini, kita akan berbicara tentang penguatan algoritma pembelajaran mendalam yang digunakan untuk mensimulasikan aparatus motor manusia.
Mensimulasikan semua gerakan manusia yang mungkin dan menggambarkan semua skenario perilaku adalah tugas yang agak sulit. Jika kita belajar memahami bagaimana seseorang bergerak, dan dapat mereproduksi gerakannya “dalam gambar dan rupa” - ini akan sangat memudahkan pengenalan robot di banyak bidang. Hanya agar robot belajar mengulang dan menganalisis gerakan itu sendiri, dan pembelajaran mesin diterapkan.

Tentang diri saya
Nama saya Alexandra Malysheva, saya lulusan sarjana di bidang Matematika Terapan dan Ilmu Komputer di St. Petersburg Academic University, dan sejak musim gugur tahun ini, saya adalah mahasiswa pascasarjana tahun pertama di HSE St. Petersburg dalam Pemrograman dan Analisis Data. Selain itu, saya bekerja di laboratorium Sistem Agen dan Pembelajaran Bertulang, Penelitian JetBrains, dan juga mengadakan kelas - kuliah dan praktik - dalam program sarjana HSE St. Petersburg.
Saat ini saya sedang mengerjakan beberapa proyek di bidang pembelajaran mendalam dengan penguatan (kami mulai berbicara tentang apa ini di artikel sebelumnya). Dan hari ini saya ingin menunjukkan proyek pertama saya, yang mengalir dengan lancar dari tesis saya.
Deskripsi tugas

Untuk mensimulasikan peralatan motor manusia, diciptakan lingkungan khusus yang mencoba mensimulasikan dunia fisik seakurat mungkin untuk menyelesaikan masalah tertentu. Sebagai contoh, kompetisi
NIPS 2017 berfokus pada pembuatan robot humanoid yang mensimulasikan berjalan manusia.
Untuk mengatasi masalah ini, metode pembelajaran yang mendalam dengan penguatan biasanya digunakan, yang mengarah pada strategi yang baik, tetapi tidak optimal. Selain itu, dalam kebanyakan kasus, waktu pelatihan terlalu lama.
Seperti telah dicatat dengan benar dalam
artikel sebelumnya , masalah utama dalam transisi dari tugas fiksi / sederhana ke tugas nyata / praktis adalah bahwa imbalan dalam masalah seperti itu biasanya sangat jarang. Misalnya, kita dapat mengevaluasi jalur jarak jauh hanya ketika agen telah mencapai garis finish. Untuk melakukan ini, ia perlu melakukan urutan tindakan yang kompleks dan benar, yang tidak selalu terjadi. Masalah ini dapat diatasi dengan memberikan agen di contoh awal tentang cara "bermain" - yang disebut demonstrasi ahli.
Saya menggunakan pendekatan ini untuk menyelesaikan masalah ini. Ternyata secara signifikan meningkatkan kualitas pelatihan, kita dapat menggunakan video yang menunjukkan gerakan seseorang saat berjalan. Secara khusus, Anda dapat mencoba menggunakan koordinat pergerakan bagian tubuh tertentu (misalnya kaki) yang diambil dari video di YouTube.
Lingkungan
Dalam tugas belajar penguatan, interaksi agen dan lingkungan dipertimbangkan. Salah satu lingkungan modern untuk memodelkan peralatan motor manusia adalah lingkungan simulasi OpenSim menggunakan mesin fisika Simbody.
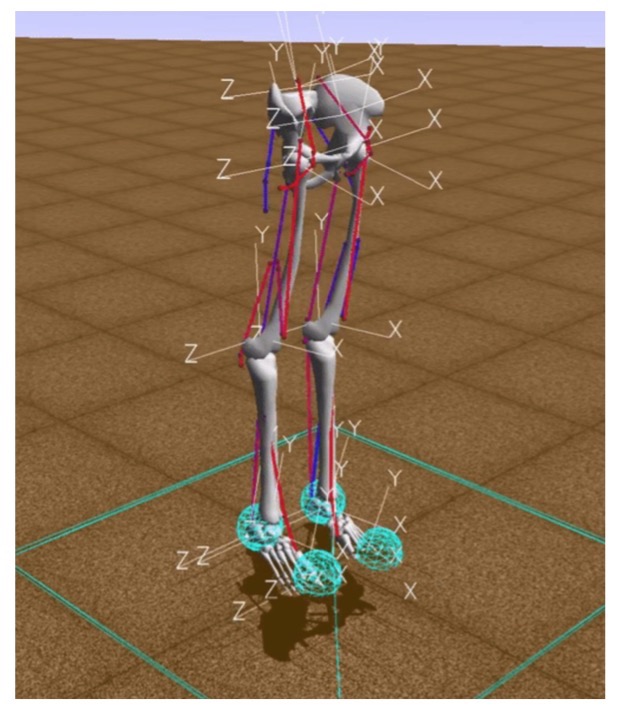
Dalam lingkungan ini, "lingkungan" adalah dunia tiga dimensi dengan rintangan, "agen" adalah robot humanoid dengan enam sendi (pergelangan kaki, lutut dan pinggul pada dua kaki) dan otot yang mensimulasikan perilaku otot manusia, dan "aksi agen" adalah nilai nyata dari 0 hingga 1, yang menentukan ketegangan otot yang ada.
Hadiah dihitung sebagai perubahan posisi panggul sepanjang sumbu x dikurangi penalti untuk menggunakan ligamen. Jadi, di satu sisi, Anda harus melangkah sejauh mungkin dalam waktu tertentu, dan, di sisi lain, membuat otot Anda bekerja sesedikit mungkin. Episode pelatihan berakhir jika 1000 iterasi tercapai, atau ketinggian panggul di bawah 0,65 meter, yang berarti model orang tersebut jatuh.
Implementasi basis
Tujuan utama pelatihan penguatan adalah untuk mengajarkan robot untuk bergerak cepat dan efisien di lingkungan.
Untuk menguji hipotesis tentang apakah pelatihan dalam demonstrasi membantu, perlu untuk menerapkan algoritma dasar yang akan belajar berlari cepat, tetapi tidak optimal, seperti banyak contoh yang ada.
Untuk melakukan ini, kami menerapkan beberapa trik:
- Untuk memulainya, perlu untuk menyesuaikan lingkungan OpenSim agar dapat menggunakan algoritma pembelajaran penguatan secara efektif. Secara khusus, dalam deskripsi lingkungan, kami menambahkan koordinat dua dimensi dari posisi bagian-bagian tubuh relatif terhadap panggul.
- Jumlah contoh melewati jarak karena simetri media meningkat. Pada posisi awal, agen berdiri secara simetris sehubungan dengan sisi kiri dan kanan tubuh. Oleh karena itu, setelah satu jarak, Anda dapat menambahkan dua contoh sekaligus: yang terjadi, dan cermin yang simetris relatif ke sisi kiri atau kanan tubuh agen.
- Untuk meningkatkan kecepatan algoritma, bingkai dilewati: algoritma untuk memilih tindakan agen berikutnya diluncurkan hanya setiap iterasi ketiga, dalam kasus lain, tindakan yang dipilih terakhir diulang. Dengan demikian, jumlah iterasi peluncuran algoritma pemilihan tindakan agen berkurang dari 1000 menjadi 333, yang mengurangi jumlah perhitungan yang diperlukan.
- Modifikasi sebelumnya sangat mempercepat pembelajaran, tetapi proses pembelajarannya masih lambat. Oleh karena itu, metode percepatan juga diterapkan, dikaitkan dengan penurunan keakuratan perhitungan: jenis nilai yang digunakan dalam vektor keadaan agen diubah dari ganda menjadi mengambang.

Grafik ini menunjukkan peningkatan setelah masing-masing optimasi yang dijelaskan di atas, itu menunjukkan hadiah yang diterima untuk suatu era dari saat pelatihan.
Jadi, apa hubungannya YouTube dengan itu?
Setelah mengembangkan model dasar, kami menambahkan generasi hadiah berdasarkan fungsi potensial. Fungsi potensial diperkenalkan untuk memberikan informasi yang bermanfaat kepada robot tentang dunia di sekitar kita: kita mengatakan bahwa beberapa posisi tubuh yang diambil oleh karakter yang sedang berjalan di video lebih "menguntungkan" (artinya, ia menerima hadiah yang lebih besar untuk mereka) daripada yang lain.
Kami membangun fungsi berdasarkan data video yang diambil dari video YouTube yang menggambarkan jalannya orang nyata dan karakter manusia dari kartun dan permainan komputer. Fungsi potensial total didefinisikan sebagai jumlah fungsi potensial untuk setiap bagian tubuh: panggul, dua lutut dan dua kaki. Mengikuti pendekatan berbasis potensial pada pembentukan remunerasi, pada setiap iterasi algoritma, agen diberikan dengan remunerasi tambahan yang sesuai dengan perubahan potensi kondisi sebelumnya dan saat ini. Fungsi potensial dari masing-masing bagian tubuh dibangun menggunakan jarak terbalik antara koordinat yang sesuai dari bagian tubuh dalam data yang dihasilkan video dan robot humanoid.
Kami memeriksa tiga sumber data:
 Becker Alan. Animating Walk Cycles - 2010
Becker Alan. Animating Walk Cycles - 2010 ProcrastinatorPro. QWOP Speedrun - 2010
ProcrastinatorPro. QWOP Speedrun - 2010 ShvetsovLeonid.HumanSpeedrun - 2015
ShvetsovLeonid.HumanSpeedrun - 2015... dan tiga fungsi jarak yang berbeda:
Di sini dx (dy) adalah perbedaan absolut antara koordinat x (y) dari bagian tubuh terkait yang diambil dari data video dan koordinat x (y) agen.
Berikut ini adalah hasil yang diperoleh dengan membandingkan berbagai sumber data untuk fungsi potensial berdasarkan PF2:

Hasil
Perbandingan produktivitas antara level dasar dan pendekatan pembentukan hadiah

Ternyata pembentukan remunerasi secara signifikan mempercepat pembelajaran, mencapai kecepatan ganda dalam 12 jam pelatihan. Hasil akhir setelah 24 jam masih menunjukkan keunggulan yang signifikan dari pendekatan menggunakan metode fungsi potensial.
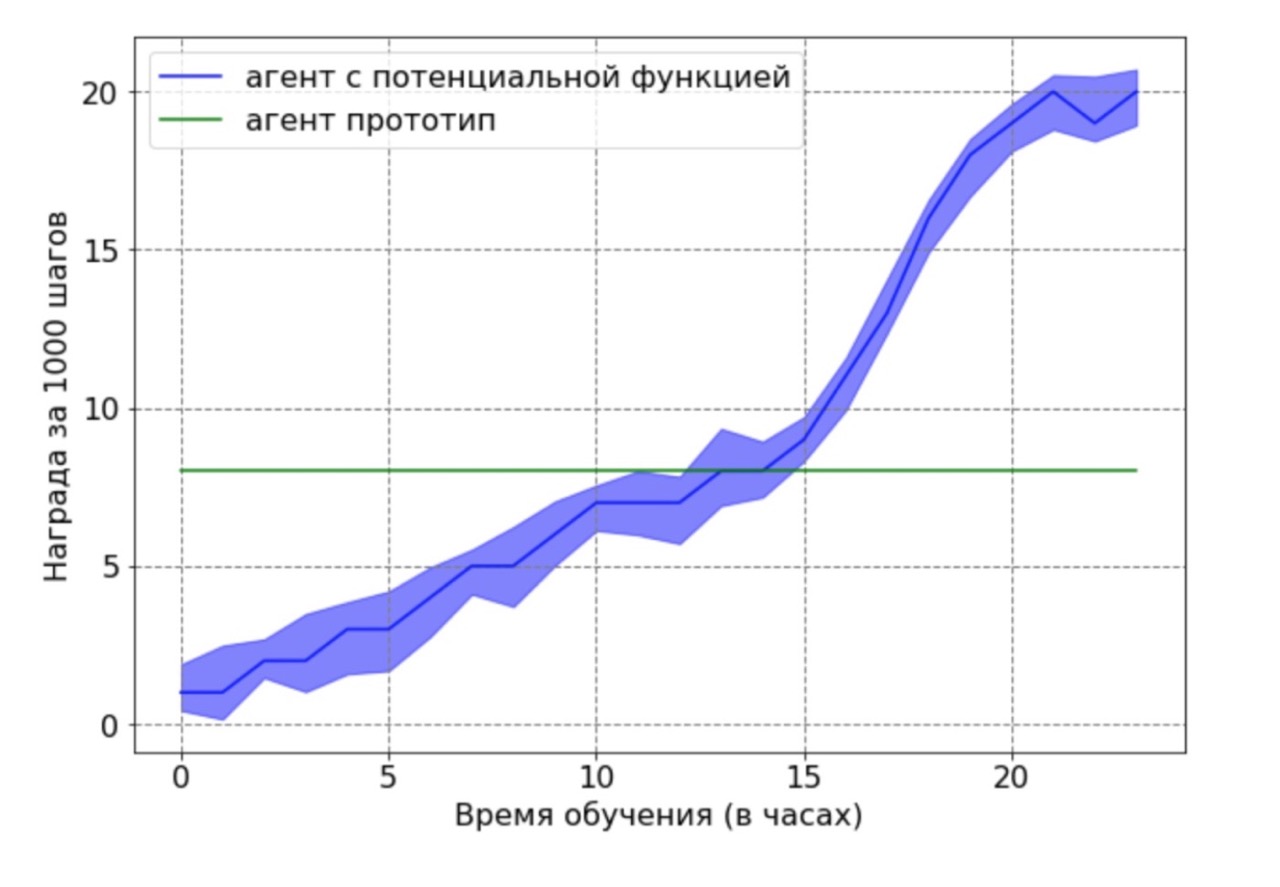
Secara terpisah, saya ingin mencatat hasil penting berikut: kami dapat membuktikan secara teoritis bahwa remunerasi berdasarkan fungsi potensial tidak memperburuk kebijakan yang optimal. Untuk menunjukkan keunggulan ini dalam konteks ini, kami menggunakan agen suboptimal yang dihasilkan oleh agen dasar setelah 12 jam pelatihan. Agen prototipe yang dihasilkan digunakan sebagai sumber data untuk fungsi potensial. Jelas, agen yang diperoleh dengan pendekatan ini tidak akan bekerja secara optimal, dan posisi kaki dan lutut dalam banyak kasus tidak akan berada dalam posisi optimal. Kemudian, agen yang dilatih oleh algoritma DDPG menggunakan fungsi potensial dilatih pada data yang diperoleh. Selanjutnya, perbandingan dibuat dari hasil pembelajaran agen dengan fungsi potensial dengan agen prototipe. Jadwal pelatihan agen menunjukkan bahwa agen RL mampu mengatasi kinerja sumber data yang tidak optimal.
Langkah pertama dalam sains
Saya menyelesaikan proyek kelulusan cukup awal. Saya ingin mencatat bahwa kami memiliki pendekatan yang sangat bertanggung jawab untuk melindungi ijazah. Sejak September, siswa mengetahui topik, kriteria penilaian, apa dan kapan harus dilakukan. Ketika semuanya sudah jelas, sangat nyaman untuk bekerja, tidak ada perasaan "Saya punya satu tahun ke depan, saya bisa mulai melakukan minggu depan / bulan / enam bulan". Akibatnya, jika Anda bekerja secara efisien, Anda bisa mendapatkan hasil akhir dari tesis pada Tahun Baru, dan menghabiskan waktu yang tersisa untuk menyiapkan model, mengumpulkan hasil yang signifikan secara statistik dan menulis teks diploma. Itulah yang terjadi pada saya.
Dua bulan sebelum ijazah dipertahankan, saya sudah menyiapkan naskah pekerjaan, dan penasihat ilmiah saya, Aleksey Aleksandrovich Shpilman, menyarankan untuk menulis artikel tentang
Lokakarya tentang Agen Adaptive and Learning (ALA) di ICML-AAMAS. Satu-satunya hal yang perlu saya lakukan adalah menerjemahkan dan mengemas ulang tesis saya. Akibatnya, kami mengirim artikel ke konferensi dan ... itu diterima! Ini adalah publikasi pertama saya dan saya sangat senang ketika saya melihat surat dengan kata "Diterima" di surat saya. Sayangnya, pada saat yang sama saya berlatih di Korea Selatan dan tidak dapat menghadiri konferensi secara pribadi.
Selain
menerbitkan dan mengakui pekerjaan yang dilakukan, konferensi pertama memberi saya hasil yang menyenangkan. Alexey Alexandrovich mulai menarik saya untuk menulis ulasan tentang karya orang lain. Sepertinya bagi saya ini sangat berguna untuk mendapatkan pengalaman dalam mengevaluasi ide-ide baru: dengan cara ini Anda dapat belajar menganalisis pekerjaan yang ada, memeriksa ide untuk orisinalitas dan relevansi.
Menulis artikel tentang lokakarya itu bagus, tetapi di jalur utama lebih baik
Setelah Korea, saya mendapat magang di JetBrains Research dan terus mengerjakan proyek. Pada titik inilah kami menguji tiga formula berbeda untuk fungsi potensial dan membuat perbandingan. Kami benar-benar ingin membagikan hasil pekerjaan kami, jadi kami memutuskan untuk menulis artikel lengkap di konferensi lagu utama
ICARCV di Singapura.
Menulis artikel di bengkel adalah baik, tetapi di jalur utama lebih baik. Dan, tentu saja, saya sangat senang ketika mengetahui bahwa artikel itu diterima! Selain itu, kolega dan sponsor kami dari JetBrains setuju untuk membayar perjalanan saya ke konferensi. Bonus besar adalah kesempatan untuk berkenalan dengan Singapura.
Ketika tiket sudah dibeli, hotel sudah dipesan dan saya hanya bisa mendapatkan visa, saya menerima surat melalui pos:

Saya tidak dikeluarkan visa meskipun fakta bahwa saya memiliki dokumen yang mengkonfirmasi pidato saya di konferensi! Ternyata Kedutaan Singapura tidak menerima aplikasi dari gadis yang belum menikah dan menganggur di bawah usia 35 tahun. Dan bahkan jika gadis itu bekerja, tetapi tidak menikah, peluang untuk mendapatkan penolakan masih sangat besar.
Untungnya, saya mengetahui bahwa warga Federasi Rusia yang bepergian dalam transit dapat tinggal di Singapura hingga 96 jam. Akibatnya, saya terbang ke Malaysia melalui Singapura, di mana saya menghabiskan hampir delapan hari total. Konferensi itu sendiri berlangsung selama enam hari. Karena pembatasan, saya menghadiri empat yang pertama, maka saya harus pergi untuk kembali karena penutupan. Setelah konferensi, saya memutuskan untuk merasa seperti turis dan hanya berjalan di sekitar kota selama dua hari dan mengunjungi museum.
Saya menyiapkan pidato di ICARCV sebelumnya, di St. Petersburg. Berlatih di bengkel pelatihan penguatan. Karena itu, berbicara di konferensi itu mengasyikkan, tetapi tidak menakutkan. Presentasi itu sendiri berlangsung 15 menit, tetapi setelah itu ada bagian pertanyaan, yang sepertinya sangat berguna bagi saya.
Saya ditanyai beberapa pertanyaan menarik yang memunculkan ide-ide baru. Misalnya, tentang cara kami menandai data. Dalam pekerjaan kami, kami menandai data secara manual, dan kami ditawari untuk menggunakan perpustakaan yang secara otomatis memahami di mana bagian-bagian tubuh manusia berada. Sekarang kami baru saja mulai mengimplementasikan ide ini. Anda dapat membaca seluruh pekerjaan di
sini .
Di ICARCV, saya senang berkomunikasi dengan para ilmuwan dan belajar banyak ide baru. Jumlah artikel menarik yang saya temui dalam beberapa hari ini lebih banyak daripada empat tahun sebelumnya. Sekarang ada "hype" untuk pembelajaran mesin di dunia, dan setiap hari puluhan artikel baru muncul di Internet, di antaranya sangat sulit untuk menemukan sesuatu yang berharga. Bagi saya, ini adalah hal yang layak untuk menghadiri konferensi: untuk menemukan komunitas yang membahas topik-topik baru yang menarik, belajar tentang ide-ide baru dan membagikan ide mereka sendiri. Dan berteman!