Halo Nama saya Ivan Davydov, saya terlibat dalam riset kinerja di Yandex.Money.
Bayangkan Anda memiliki server yang kuat, yang masing-masing menampung sejumlah aplikasi. Jika tidak banyak, mereka tidak saling mengganggu pekerjaan masing-masing - mereka nyaman dan nyaman. Setelah Anda datang ke layanan microser dan mengambil bagian dari fungsi "berat" dalam aplikasi terpisah.
Di sini Anda dapat terbawa, dan akan ada terlalu banyak layanan mikro, yang karenanya akan menjadi sulit untuk mengelolanya dan memastikan toleransi kesalahan mereka. Akibatnya, selusin aplikasi yang memperjuangkan sumber daya bersama akan "dibundel" di setiap server. Ini akan berubah menjadi "keluarga besar", tetapi dalam keluarga besar jangan klik dengan paruh Anda!
Pernah kami juga menghadapi ini. Kisah saya adalah tentang malam yang berat dan tanpa tidur, ketika saya duduk di bawah lampu di malam hari dan menembaki prod. Semuanya dimulai dengan fakta bahwa kami mulai memperhatikan masalah jaringan di server pertempuran.
Mereka sangat memengaruhi kinerja dan membuat drawdown yang signifikan. Pada saat yang sama, ternyata kesalahan yang sama terjadi dengan aliran pengguna biasa, tetapi pada tingkat yang jauh lebih kecil.
Masalahnya terletak pada pemanfaatan soket TCP lebih dari 100%. Ini terjadi ketika semua soket pada server terus-menerus membuka dan menutup. Karena itu, ada masalah jaringan interaksi antara aplikasi dan berbagai jenis kesalahan muncul - host jarak jauh tidak tersedia, koneksi HTTP / HTTPS (koneksi / batas waktu baca, peer SSL dimatikan secara salah) rusak dan lainnya.
Bahkan jika Anda tidak memiliki layanan pembayaran elektronik sendiri, tidak terlalu sulit untuk menilai tingkat rasa sakit selama penjualan reguler - lalu lintas meningkat beberapa kali, dan penurunan kinerja dapat menyebabkan kerugian yang signifikan. Jadi kami sampai pada dua kesimpulan - kita perlu mengevaluasi bagaimana kapasitas saat ini digunakan, dan mengisolasi aplikasi dari satu sama lain.
Untuk mengisolasi aplikasi, kami memutuskan untuk menggunakan kontainerisasi. Untuk melakukan ini, kami menggunakan hypervisor yang berisi banyak wadah terpisah dengan aplikasi. Ini memungkinkan Anda untuk mengisolasi sumber daya prosesor, memori, perangkat input / output, jaringan, serta pohon proses, pengguna, sistem file, dan sebagainya.
Dengan pendekatan ini, setiap aplikasi memiliki lingkungannya sendiri, yang menyediakan fleksibilitas, isolasi, keandalan, dan meningkatkan kinerja sistem secara keseluruhan. Ini adalah solusi yang cantik dan elegan, tetapi sebelum itu Anda perlu menjawab sejumlah pertanyaan:
- Berapa margin kinerja yang dimiliki oleh satu instance aplikasi saat ini?
- Bagaimana aplikasi diskalakan dan apakah ada redundansi sumber daya dalam konfigurasi saat ini?
- Apakah mungkin untuk meningkatkan kinerja satu contoh dan apa hambatannya?
Dengan pertanyaan seperti itu, rekan-rekan mendatangi kami - tim peneliti kinerja.
Apa yang kita lakukan
Kami melakukan segalanya untuk memastikan kinerja layanan kami dan, pertama-tama, kami meneliti dan memperbaikinya untuk proses bisnis produksi kami. Setiap proses bisnis, baik itu membayar barang di toko dengan dompet atau mentransfer uang antar pengguna, pada dasarnya, mewakili bagi kami rantai permintaan dalam sistem.
Kami melakukan eksperimen dan menyiapkan laporan untuk mengevaluasi kinerja sistem pada intensitas tinggi permintaan yang masuk. Laporan tersebut berisi metrik kinerja dan uraian terperinci tentang masalah dan kemacetan yang teridentifikasi. Dengan bantuan informasi ini, kami meningkatkan dan mengoptimalkan sistem kami.
Menilai potensi setiap aplikasi diperumit oleh fakta bahwa beberapa layanan microser yang menggunakan kekuatan semua instans yang terlibat berpartisipasi dalam organisasi dari urutan permintaan proses bisnis.
Secara metaforis, kita tahu kekuatan pasukan kita, tetapi tidak tahu potensi masing-masing pejuang. Oleh karena itu, selain penelitian yang sedang berlangsung, perlu untuk menilai sumber daya yang digunakan sebagai bagian dari proses manajemen kapasitas. Proses ini disebut Manajemen Kapasitas.
Penelitian kami membantu mengidentifikasi dan mencegah kurangnya sumber daya, memperkirakan pembelian besi dan memiliki data akurat tentang kemampuan saat ini dan potensi sistem. Sebagai bagian dari proses ini, kinerja aplikasi aktual (median dan maksimum) dimonitor dan data pada stok saat ini disediakan.
Inti dari manajemen kapasitas adalah untuk menemukan keseimbangan antara sumber daya yang dikonsumsi dan produktivitas.
Pro:
- Setiap saat diketahui apa yang terjadi dengan kinerja setiap aplikasi.
- Lebih sedikit risiko saat menambahkan layanan microser baru.
- Biaya lebih rendah untuk pembelian peralatan baru.
- Kapasitas yang sudah ada digunakan dengan lebih cerdas.
Bagaimana manajemen kapasitas bekerja
Mari kita kembali ke situasi kita dengan banyak aplikasi. Kami melakukan penelitian yang tujuannya adalah untuk mengevaluasi bagaimana kapasitas digunakan pada server produksi.
Singkatnya, rencana tindakan adalah sebagai berikut:
- Tentukan intensitas pengguna pada aplikasi tertentu.
- Buat profil pemotretan.
- Mengevaluasi kinerja setiap instance aplikasi.
- Tingkat skalabilitas.
- Kompilasi laporan dan kesimpulan tentang jumlah instance minimum yang diperlukan untuk setiap aplikasi dalam lingkungan pertempuran.
Dan sekarang lebih terinci.
Alat-alatnya
Kami menggunakan Heka dan Zabbix untuk mengumpulkan metrik intensitas khusus. Grafana digunakan untuk memvisualisasikan metrik yang dikumpulkan.
Zabbix diperlukan untuk memonitor sumber daya server, seperti: CPU, Memori, koneksi jaringan, DB dan lainnya. Heka menyediakan data tentang jumlah dan waktu pelaksanaan permintaan masuk / keluar, pengumpulan metrik pada antrian aplikasi internal dan jumlah data lainnya yang tak ada habisnya. Grafana adalah alat visualisasi yang fleksibel yang digunakan oleh tim Yandex.Money yang berbeda. Kami tidak terkecuali.
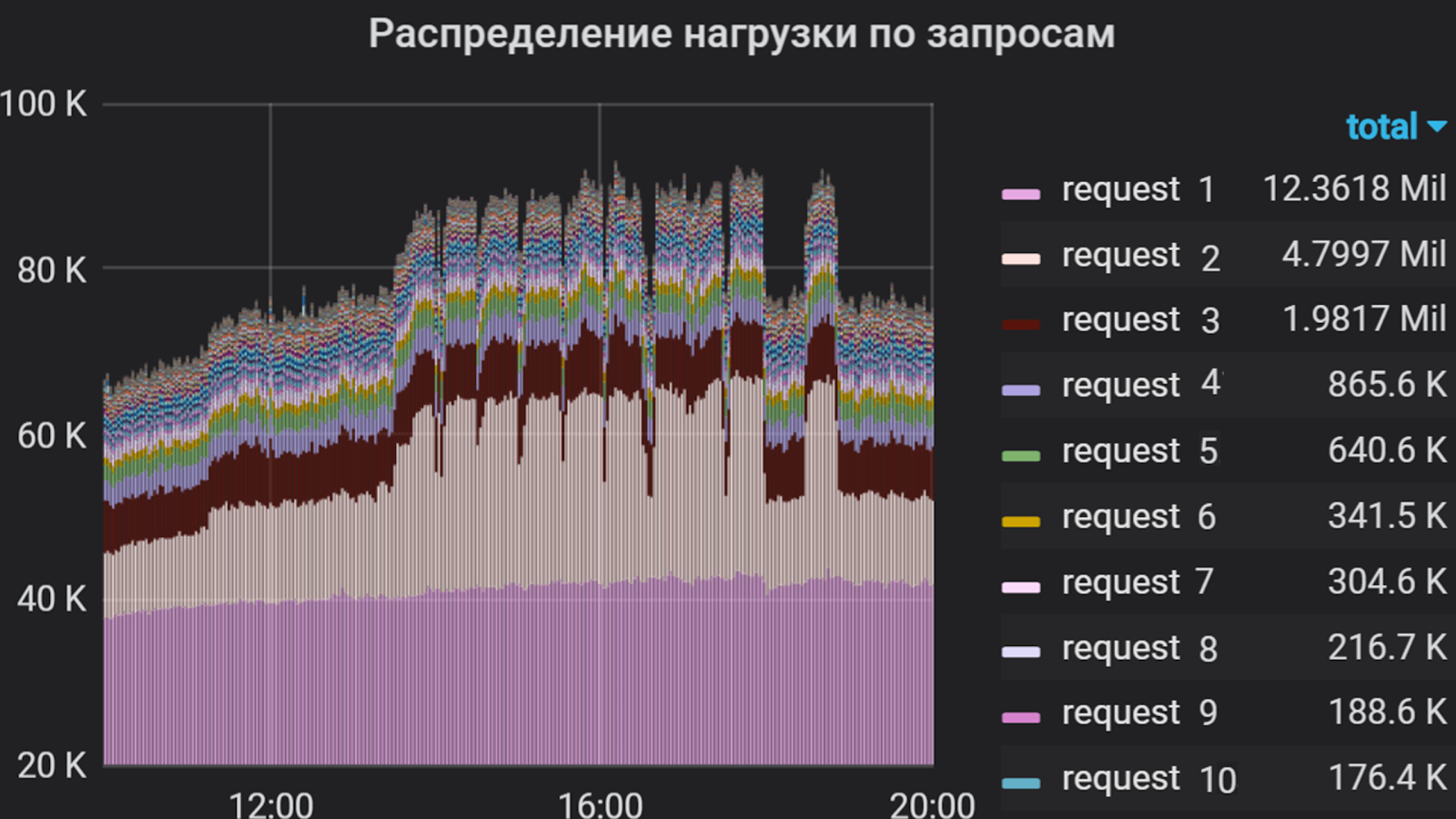
Grafana dapat menunjukkan, misalnya, hal-hal seperti itu
Apache JMeter digunakan sebagai generator lalu lintas. Dengan bantuannya, skenario pemotretan dikompilasi, yang mencakup implementasi permintaan, pemantauan validitas respons, kontrol fleksibel dari aliran umpan, dan banyak lagi. Alat ini memiliki pro dan kontra, tetapi untuk lebih dalam "mengapa produk ini?" Saya tidak akan.
Selain JMeter, kerangka yandex-tank digunakan - alat untuk pengujian stres dan analisis kinerja layanan web dan aplikasi. Ini memungkinkan Anda untuk menyambungkan modul Anda untuk mendapatkan fungsi yang diinginkan dan menampilkan hasilnya di konsol atau dalam bentuk grafik. Hasil penembakan kami ditampilkan di Lunapark (analog dengan https://overload.yandex.net ), di mana kami dapat mengamatinya secara rinci dalam waktu nyata, hingga puncak kedua, memberikan kelonggaran yang diperlukan dan cukup, dan dengan demikian merespons dengan lebih cepat terhadap semburan, timbul dari pemotretan. Dalam graphane, seseorang juga dapat menyesuaikan diskresi, tetapi solusi ini lebih mahal dalam hal sumber daya fisik dan logis. Dan kadang-kadang kita bahkan mengunggah data mentah dan memvisualisasikannya melalui GUI Jmeter. Tapi hanya - sst!
Berbicara tentang degradasi. Hampir semua gangguan yang terjadi dalam aplikasi di bawah arus lalu lintas yang besar dengan cepat dianalisis menggunakan Kibana . Tapi ini juga bukan obat mujarab - beberapa masalah jaringan hanya dapat dianalisis dengan menghapus dan menganalisis lalu lintas.
Menggunakan Grafana, kami menganalisis intensitas pengguna dalam aplikasi selama beberapa bulan. Kami memutuskan untuk mengambil total waktu prosesor untuk mengeksekusi permintaan sebagai unit pengukuran, yaitu jumlah permintaan dan waktu eksekusi mereka diperhitungkan. Jadi kami menyusun daftar permintaan yang paling "berat", yang merupakan sebagian besar aliran ke aplikasi. Daftar inilah yang menjadi dasar profil penembakan.

Intensitas pengguna per aplikasi selama beberapa bulan
Membidik dan melihat profil
Kami menyebut meluncurkan skrip sebagai bagian dari percobaan. Profil ini terdiri dari dua bagian.
Bagian pertama adalah menulis skrip permintaan. Selama implementasi, perlu untuk menganalisis intensitas pengguna untuk setiap permintaan aplikasi yang masuk dan membuat rasio persentase di antara mereka untuk mengidentifikasi yang paling dipanggil dan yang sudah berjalan lama. Bagian kedua adalah pemilihan parameter pertumbuhan aliran: dengan intensitas apa dan untuk berapa lama memuat.
Untuk kejelasan yang lebih besar, metodologi untuk menyusun profil paling baik ditunjukkan dengan contoh.
Grafana membuat grafik yang mencerminkan intensitas pengguna dan bagian dari setiap permintaan dalam aliran total. Berdasarkan distribusi dan waktu respons ini untuk setiap permintaan, grup dibuat di JMeter, yang masing-masing merupakan generator traffic independen. Skenario hanya didasarkan pada permintaan yang paling "berat", karena sulit untuk mengimplementasikan semuanya (dalam beberapa aplikasi ada lebih dari seratus), dan ini tidak selalu diperlukan karena intensitasnya yang relatif rendah.

Persentase Pertanyaan
Studi ini menguji intensitas pengguna dalam aliran konstan, dan "ledakan" yang terjadi secara berkala paling sering dianggap secara pribadi.
Dalam contoh kita, dua kelompok dipertimbangkan. Grup pertama termasuk "permintaan 1" dan "permintaan 2" dalam rasio 1 ke 2. Demikian pula, kelompok kedua termasuk permintaan 3 dan 4. Permintaan yang tersisa untuk komponen jauh kurang intens, jadi kami tidak memasukkannya dalam skrip.

Kueri pengelompokan di Jmeter
Berdasarkan waktu respons rata-rata untuk masing-masing kelompok, kinerja diperkirakan dengan rumus:
x = 1000 / t, di mana t adalah median waktu, ms
Kami mendapatkan hasil perhitungan dan memperkirakan intensitas perkiraan dengan meningkatnya jumlah utas:
TPS = x * p, di mana p adalah jumlah utas, TPS adalah transaksi per detik, dan x adalah hasil dari perhitungan sebelumnya.
Jika permintaan diproses dalam 500 ms, maka dengan satu aliran kami memiliki 2 Tps, dan dengan 100 utas sebaiknya memiliki 200 Tps. Berdasarkan hasil yang diperoleh, parameter pertumbuhan awal dapat dipilih. Setelah iterasi pertama penelitian, parameter ini biasanya disesuaikan.
Saat skenario pemotretan siap, kami memulai pemotretan - pemotretan selama satu menit dalam satu aliran. Ini dilakukan untuk memeriksa operabilitas skrip dengan aliran konstan, untuk mengevaluasi waktu respons terhadap permintaan di setiap grup dan untuk mendapatkan persentase rasio permintaan.
Saat menjalankan profil ini, kami menemukan bahwa pada intensitas yang sama, persentase permintaan dipertahankan, karena waktu respons rata-rata di grup kedua lebih panjang daripada di yang pertama. Oleh karena itu, kami menetapkan laju aliran yang sama untuk kedua kelompok. Dalam kasus lain, perlu untuk secara eksperimental memilih parameter untuk masing-masing kelompok secara terpisah.
Dalam contoh ini, intensitas diterapkan secara bertahap, yaitu sejumlah aliran ditambahkan pada interval tertentu.

Opsi Pertumbuhan Intensitas
Parameter pertumbuhan intensitas adalah sebagai berikut:
- Jumlah target utas adalah 100 (ditentukan saat melihat).
- Pertumbuhan selama 1000 detik (~ 16 menit).
- 100 langkah.
Jadi, setiap 10 detik kami menambahkan satu aliran. Interval antara menambahkan utas dan jumlah utas yang ditambahkan bervariasi tergantung pada perilaku sistem pada langkah tertentu. Seringkali, intensitas disuplai dengan pertumbuhan yang halus, sehingga Anda dapat melacak status sistem di setiap tahap.
Menembak
Biasanya, penembakan dimulai pada malam hari dari server jarak jauh. Pada saat ini, lalu lintas pengguna minimal - ini berarti bahwa pemotretan tidak akan memengaruhi pengguna, dan kesalahan dalam hasilnya akan lebih sedikit.
Menurut hasil penembakan pertama dalam satu contoh, kami menyesuaikan jumlah utas dan waktu pertumbuhan, menganalisis perilaku sistem secara keseluruhan dan menemukan penyimpangan dalam pekerjaan. Setelah semua penyesuaian, pemotretan berulang menjadi satu instance dimulai. Pada tahap ini, kami menentukan kinerja maksimum dan memantau penggunaan sumber daya perangkat keras dari kedua server dengan aplikasi dan semua yang ada di belakangnya.
Menurut hasil pemotretan, kinerja satu instance aplikasi kami adalah sekitar 1000 Tps. Pada saat yang sama, peningkatan waktu respons untuk semua permintaan dicatat tanpa meningkatkan produktivitas, yaitu, kami mencapai saturasi, tetapi bukan degradasi.
Pada tahap selanjutnya, kami membandingkan hasil yang diperoleh dari contoh lain. Ini penting, karena perangkat keras dapat berbeda, yang berarti bahwa instance yang berbeda dapat memberikan indikator yang sangat berbeda. Begitu juga dengan kami - beberapa server ternyata menjadi urutan besarnya lebih produktif karena generasi dan karakteristik. Oleh karena itu, kami mengidentifikasi sekelompok server dengan hasil terbaik dan menyelidiki skalabilitasnya.
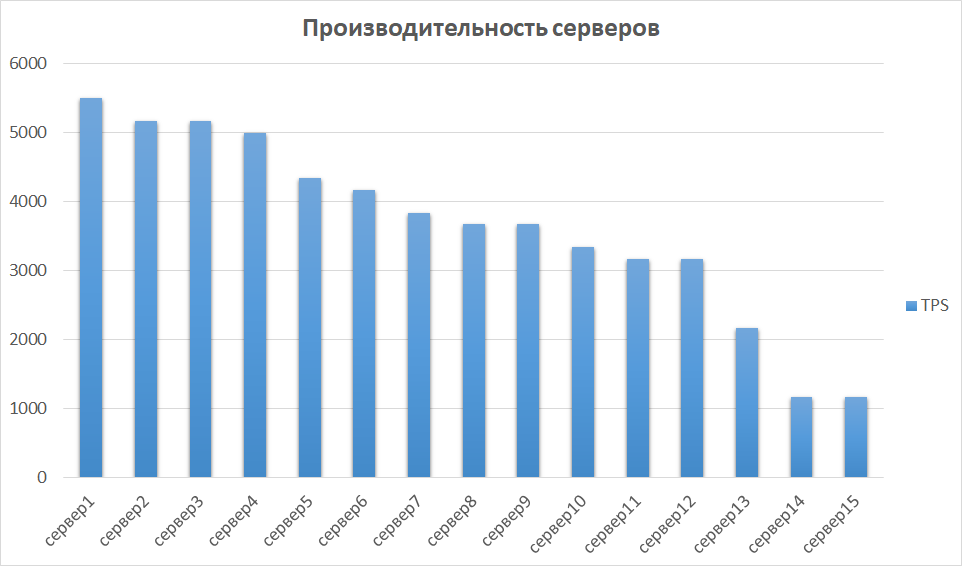
Perbandingan kinerja server
Skalabilitas dan bottlenecking
Langkah selanjutnya adalah menyelidiki kinerja pada instance 2, 3, dan 4. Secara teori, kinerja harus tumbuh secara linear dengan meningkatnya jumlah instance. Dalam praktiknya, ini biasanya tidak demikian.
Dalam contoh kita, itu ternyata menjadi pilihan yang hampir sempurna.

Alasan untuk pertumbuhan produktivitas jenuh adalah kelelahan kolam konektor sebelum backend berikutnya. Ini diselesaikan dengan mengontrol ukuran kumpulan pada sisi keluar dan masuk dan mengarah pada peningkatan kinerja aplikasi.
Dalam penelitian lain, kami menemukan lebih banyak hal menarik. Eksperimen telah menunjukkan bahwa seiring dengan kinerja, pemanfaatan CPU dan koneksi basis data berkembang pesat. Dalam kasus kami, ini terjadi karena dalam konfigurasi dengan satu instance kami berlari ke pengaturan kami sendiri untuk kumpulan aplikasi, dan dengan dua contoh kami menggandakan nomor ini, sehingga menggandakan aliran keluar. Basis data tidak siap untuk volume seperti itu. Karena itu, kumpulan ke database mulai menjadi tersumbat, persentase CPU yang dikonsumsi mencapai tanda kritis 99%, dan waktu pemrosesan permintaan meningkat, dan sebagian lalu lintas jatuh sama sekali. Dan kami sudah mendapatkan hasil seperti itu di dua contoh!
Untuk akhirnya meyakinkan diri kita sendiri akan ketakutan kita, kita menembak 3 kali. Hasilnya kira-kira sama seperti pada dua yang pertama, kecuali bahwa mereka dengan cepat mengalami gangguan.
Ada contoh lain dari "colokan", yang, menurut pendapat saya, adalah yang paling menyakitkan - ini adalah kode yang ditulis dengan buruk. Mungkin ada apa pun yang Anda inginkan, mulai dari kueri basis data yang berjalan dalam hitungan menit, diakhiri dengan kode yang salah mengalokasikan memori mesin Java.
Ringkasan
Akibatnya, margin aplikasi yang diselidiki dalam aplikasi contoh kami memiliki margin kinerja lebih dari 5 kali.
Untuk meningkatkan produktivitas, perlu untuk menghitung jumlah kumpulan prosesor yang cukup dalam pengaturan aplikasi. Dua contoh untuk aplikasi tertentu sudah cukup, dan penggunaan semua 15 yang tersedia berlebihan.
Setelah penelitian, hasil berikut diperoleh:
- Intensitas pengguna selama 1 bulan ditentukan dan dipantau.
- Margin kinerja satu contoh aplikasi telah diidentifikasi.
- Hasilnya diperoleh tentang kesalahan yang terjadi di bawah aliran besar.
- Kemacetan untuk pekerjaan lebih lanjut tentang peningkatan produktivitas telah diidentifikasi.
- Jumlah minimum contoh yang cukup untuk operasi aplikasi yang benar telah diidentifikasi. Dan, akibatnya, penggunaan kapasitas yang berlebihan terungkap.
Hasil penelitian membentuk dasar proyek untuk transfer komponen ke dalam wadah, yang akan kita bahas dalam artikel berikut. Sekarang kita dapat mengatakan dengan pasti berapa banyak kontainer dan dengan karakteristik apa yang perlu dimiliki, bagaimana menggunakan kapasitasnya secara rasional dan apa yang harus dikerjakan untuk memastikan kinerja yang tepat.
Datanglah ke ruang obrolan telegram kami yang nyaman di mana Anda selalu dapat meminta saran, membantu kolega, dan hanya berbicara tentang penelitian produktivitas.
Itu saja untuk hari ini. Ajukan pertanyaan di komentar dan berlangganan blog Yandex.Money - segera kita akan berbicara tentang phishing dan cara menghindarinya.