Game telah digunakan selama beberapa dekade sebagai salah satu cara utama untuk menguji dan mengevaluasi keberhasilan sistem kecerdasan buatan. Ketika peluang tumbuh, para peneliti mencari game dengan kompleksitas yang semakin meningkat, yang akan mencerminkan berbagai elemen pemikiran yang diperlukan untuk menyelesaikan masalah ilmiah atau terapan dari dunia nyata. Dalam beberapa tahun terakhir, StarCraft dianggap sebagai salah satu strategi real-time yang paling fleksibel dan kompleks dan salah satu yang paling populer di kancah e-sports dalam sejarah, dan sekarang StarCraft juga telah menjadi tantangan utama untuk penelitian AI.
AlphaStar adalah sistem kecerdasan buatan pertama yang mampu mengalahkan pemain profesional terbaik. Dalam serangkaian pertandingan yang berlangsung pada 19 Desember, AlphaStar menang telak atas Grzegorz Komincz (
MaNa ) dari
Liquid , salah satu
pemain terkuat di dunia , dengan skor 5: 0. Sebelum itu, pertandingan demonstrasi yang sukses juga dimainkan melawan rekan setimnya Dario Wünsch (
TLO ). Pertandingan diadakan sesuai dengan semua aturan profesional pada
kartu turnamen khusus dan tanpa batasan apa pun.
Meskipun keberhasilan yang signifikan dalam permainan seperti
Atari ,
Mario ,
Quake III Arena, dan
Dota 2 , teknisi AI tidak berhasil melawan kompleksitas StarCraft. Hasil terbaik dicapai dengan secara manual membangun elemen dasar sistem, dengan memberlakukan berbagai batasan pada aturan permainan, dengan menyediakan sistem dengan kemampuan manusia super, atau dengan bermain di peta yang disederhanakan. Tetapi bahkan nuansa ini membuatnya tidak mungkin untuk mendekati level pemain profesional. Berlawanan dengan ini, AlphaStar memainkan permainan penuh menggunakan jaringan saraf dalam, yang dilatih berdasarkan data permainan mentah, menggunakan metode
mengajar dengan guru dan
belajar dengan penguatan .
Tantangan utama
StarCraft II adalah dunia fantasi fiksi dengan kaya, gameplay multi-level. Seiring dengan edisi aslinya, ini adalah game terbesar dan paling sukses sepanjang masa, yang telah bertarung dalam turnamen selama lebih dari 20 tahun.

Ada banyak cara untuk bermain, tetapi yang paling umum dalam e-sports adalah turnamen satu lawan satu yang terdiri dari 5 pertandingan. Untuk memulai, pemain harus memilih satu dari tiga balapan - zergs, protoss atau terrans, yang masing-masing memiliki karakteristik dan kemampuannya sendiri. Karenanya, pemain profesional paling sering mengkhususkan diri dalam satu balapan. Setiap pemain mulai dengan beberapa unit kerja yang mengekstraksi sumber daya untuk membangun gedung, unit lain, atau mengembangkan teknologi. Hal ini memungkinkan pemain untuk merebut sumber daya lain, membangun pangkalan yang lebih canggih dan mengembangkan kemampuan baru untuk mengecoh lawan. Untuk menang, pemain harus dengan sangat hati-hati menyeimbangkan gambaran ekonomi secara keseluruhan, yang disebut "makro", dan kontrol tingkat rendah dari masing-masing unit, yang disebut "mikro".
Kebutuhan untuk menyeimbangkan tujuan jangka pendek dan jangka panjang dan beradaptasi dengan situasi yang tidak terduga menimbulkan tantangan besar bagi sistem yang pada kenyataannya sering berubah menjadi sepenuhnya tidak fleksibel. Memecahkan masalah ini membutuhkan terobosan di beberapa bidang AI:
Game Theory : StarCraft adalah game di mana, seperti di "Stone, Scissors, Paper", tidak ada strategi kemenangan tunggal. Oleh karena itu, dalam proses pembelajaran, AI harus terus mengeksplorasi dan memperluas wawasan pengetahuan strategisnya.
Informasi yang tidak lengkap : Tidak seperti catur atau pergi, di mana pemain melihat segala sesuatu yang terjadi, di StarCraft informasi penting sering disembunyikan dan harus secara aktif digali melalui intelijen.
Perencanaan jangka panjang : Seperti dalam tugas-tugas dunia nyata, hubungan sebab-akibat mungkin tidak instan. Gim juga dapat bertahan satu jam atau lebih, oleh karena itu tindakan yang dilakukan pada awal gim mungkin sama sekali tidak memiliki arti penting dalam jangka panjang.
Waktu Nyata : Bertolak belakang dengan permainan papan tradisional, di mana para peserta bergiliran, di StarCraft, para pemain melakukan tindakan terus menerus, bersama dengan berlalunya waktu.
Ruang aksi besar : Ratusan unit dan bangunan yang berbeda harus dipantau secara bersamaan, dalam waktu nyata, yang memberikan ruang peluang kombinatorial yang sangat besar. Selain itu, banyak tindakan bersifat hierarkis dan dapat berubah dan melengkapi sepanjang jalan. Parameterisasi permainan kami memberikan rata-rata sekitar 10 hingga 26 tindakan per unit waktu.
Mengingat tantangan ini, StarCraft telah menjadi tantangan besar bagi para peneliti AI. Kompetisi StarCraft dan StarCraft II yang sedang berlangsung berakar pada peluncuran
BroodWar API pada tahun 2009. Diantaranya adalah
Kompetisi AIIDE StarCraft AI ,
Kompetisi CIG StarCraft ,
Turnamen Student StarCraft AI, dan
Tangga AI Starcraft II .
Catatan : Pada 2017, PatientZero menerbitkan di Habré terjemahan yang sangat baik dari " Sejarah Kompetisi AI di Starcraft ".Untuk membantu komunitas mengeksplorasi masalah-masalah ini lebih lanjut, kami,
bekerja sama dengan Blizzard pada tahun 2016 dan 2017, menerbitkan perangkat
PySC2 , yang mencakup susunan replay anonim terbesar yang pernah diterbitkan. Berdasarkan pekerjaan ini, kami menggabungkan pencapaian teknik dan algoritmik kami untuk menciptakan AlphaStar.
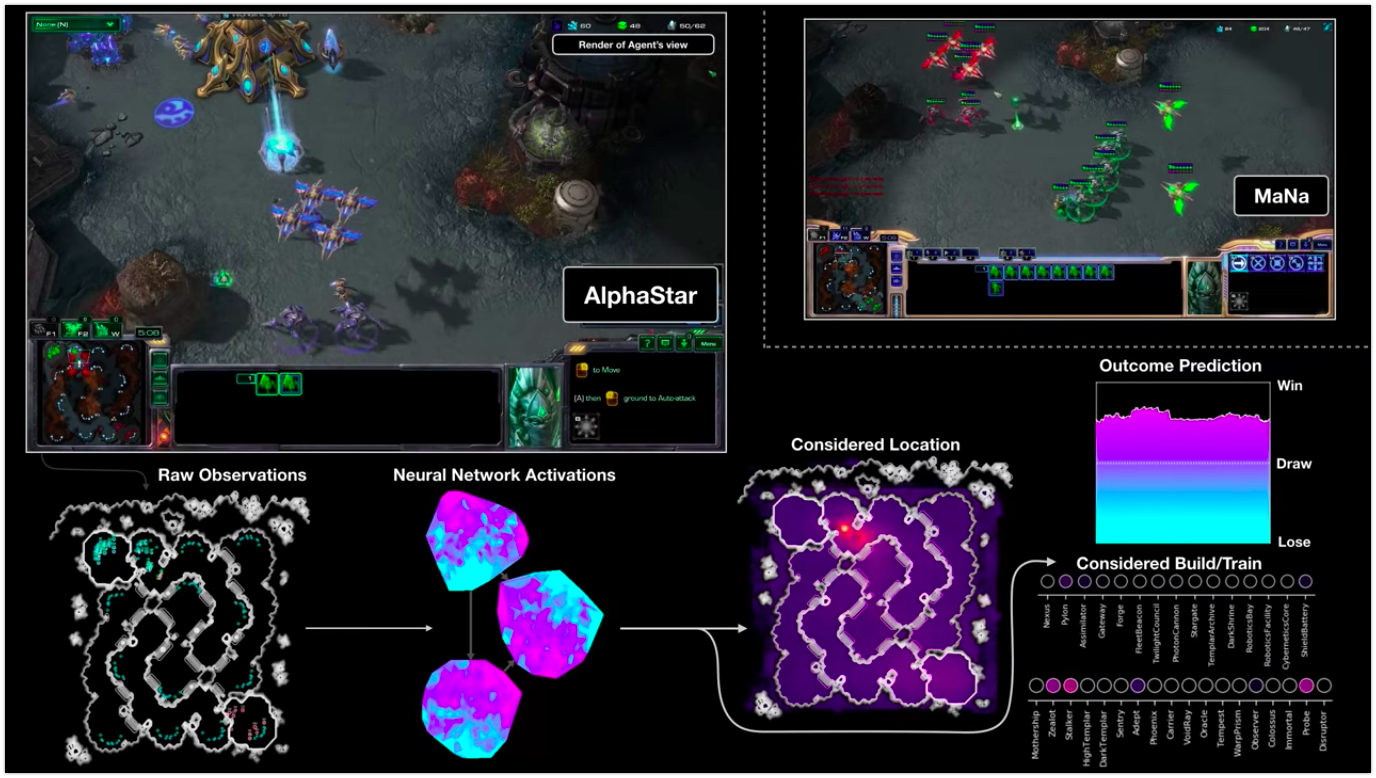
 Visualisasi AlphaStar selama pertarungan melawan MaNa, menunjukkan permainan atas nama agen - data awal yang diamati, aktivitas jaringan saraf, beberapa tindakan yang diusulkan dan koordinat yang diperlukan, serta perkiraan hasil pertandingan. Tampilan pemain MaNa juga ditampilkan, tetapi tentu saja tidak dapat diakses oleh agen.
Visualisasi AlphaStar selama pertarungan melawan MaNa, menunjukkan permainan atas nama agen - data awal yang diamati, aktivitas jaringan saraf, beberapa tindakan yang diusulkan dan koordinat yang diperlukan, serta perkiraan hasil pertandingan. Tampilan pemain MaNa juga ditampilkan, tetapi tentu saja tidak dapat diakses oleh agen.Bagaimana pelatihannya
Perilaku AlphaStar dihasilkan
oleh jaringan saraf pembelajaran yang dalam, yang menerima data mentah melalui antarmuka (daftar unit dan propertinya) dan memberikan urutan instruksi yang merupakan tindakan dalam permainan. Lebih khusus, arsitektur jaringan saraf menggunakan pendekatan "torso
transformator ke unit, dikombinasikan dengan
inti LSTM yang mendalam ,
kepala kebijakan regresif otomatis dengan
jaringan pointer , dan
baseline nilai terpusat "
(untuk akurasi istilah yang dibiarkan tanpa terjemahan) . Kami percaya bahwa model-model ini selanjutnya akan membantu mengatasi tugas pembelajaran mesin penting lainnya, termasuk pemodelan urutan jangka panjang dan ruang output yang besar seperti terjemahan, pemodelan bahasa, dan representasi visual.
AlphaStar juga menggunakan algoritma pembelajaran multi-agen baru. Jaringan saraf ini awalnya dilatih menggunakan metode pembelajaran berbasis guru berdasarkan replay anonim yang
tersedia melalui Blizzard. Hal ini memungkinkan AlphaStar untuk mempelajari dan mensimulasikan strategi mikro dan makro dasar yang digunakan oleh pemain dalam turnamen. Agen ini mengalahkan level AI built-in "Elite", yang setara dengan level pemain di liga emas dalam 95% game uji.
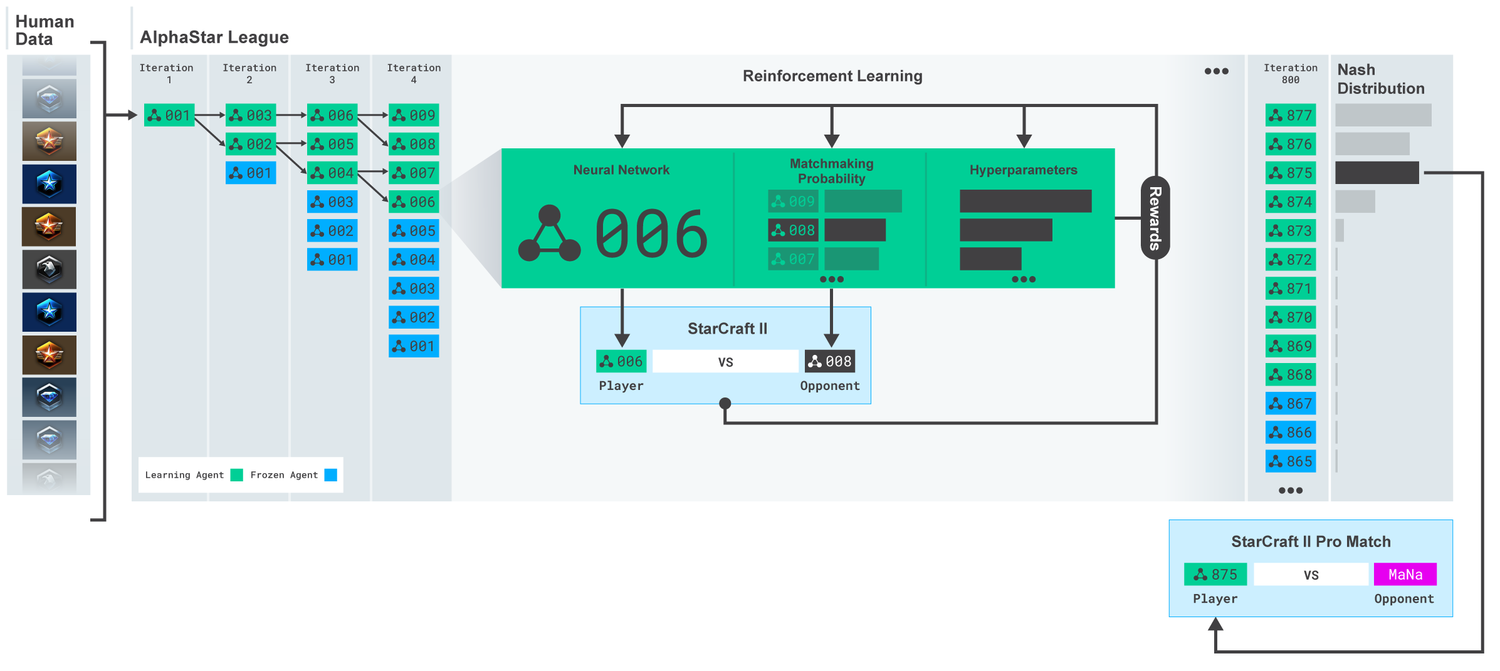 League AlphaStar. Agen awalnya dilatih berdasarkan replay pertandingan manusia, dan kemudian berdasarkan pertandingan kompetitif di antara mereka sendiri. Pada setiap iterasi, lawan baru bercabang dan yang asli membeku. Kemungkinan bertemu lawan dan hiperparameter lainnya menentukan tujuan pembelajaran untuk setiap agen, yang meningkatkan kompleksitas, yang mempertahankan keragaman. Parameter agen diperbarui dengan pelatihan penguatan berdasarkan hasil pertandingan melawan lawan. Agen terakhir dipilih (tanpa penggantian) berdasarkan distribusi Nash.
League AlphaStar. Agen awalnya dilatih berdasarkan replay pertandingan manusia, dan kemudian berdasarkan pertandingan kompetitif di antara mereka sendiri. Pada setiap iterasi, lawan baru bercabang dan yang asli membeku. Kemungkinan bertemu lawan dan hiperparameter lainnya menentukan tujuan pembelajaran untuk setiap agen, yang meningkatkan kompleksitas, yang mempertahankan keragaman. Parameter agen diperbarui dengan pelatihan penguatan berdasarkan hasil pertandingan melawan lawan. Agen terakhir dipilih (tanpa penggantian) berdasarkan distribusi Nash.Hasil ini kemudian digunakan untuk memulai proses pembelajaran penguatan multi-agen. Untuk ini, sebuah liga diciptakan di mana agen lawan bermain melawan satu sama lain, sama seperti orang mendapatkan pengalaman dengan bermain turnamen. Pesaing baru ditambahkan dengan cara ke liga, dengan duplikasi agen saat ini. Bentuk pelatihan baru ini, meminjam beberapa ide dari metode pembelajaran penguatan dengan unsur-unsur algoritma genetika (
berbasis populasi ), memungkinkan Anda untuk membuat proses terus menerus mengeksplorasi ruang permainan strategis StarCraft yang luas, dan memastikan bahwa agen mampu menahan strategi yang paling kuat, bukan melupakan yang lama.
 Skor MMR (Match Making Rating) - indikator perkiraan keterampilan pemain. Untuk rival di liga AlphaStar selama pelatihan, dibandingkan dengan liga online Blizzard.
Skor MMR (Match Making Rating) - indikator perkiraan keterampilan pemain. Untuk rival di liga AlphaStar selama pelatihan, dibandingkan dengan liga online Blizzard.Ketika liga berkembang dan agen-agen baru diciptakan, strategi kontra muncul yang mampu mengalahkan yang sebelumnya. Sementara beberapa agen hanya meningkatkan strategi yang sebelumnya mereka temui, agen lain menciptakan yang sama sekali baru, termasuk pesanan bangunan baru yang tidak biasa, komposisi unit, dan manajemen makro. Sebagai contoh, sejak awal, "keju" berkembang - terburu-buru cepat dengan bantuan meriam
Foton atau
Templar Kegelapan . Tetapi ketika proses pembelajaran bergerak maju, strategi berisiko ini dibuang, memberi jalan kepada orang lain. Misalnya, produksi jumlah pekerja yang berlebih untuk mendapatkan tambahan sumber daya atau sumbangan dari dua
Orakel untuk menyerang pekerja musuh dan merusak ekonominya. Proses ini mirip dengan bagaimana pemain reguler menemukan strategi baru dan mengalahkan pendekatan populer lama, selama bertahun-tahun sejak rilis StarCraft.
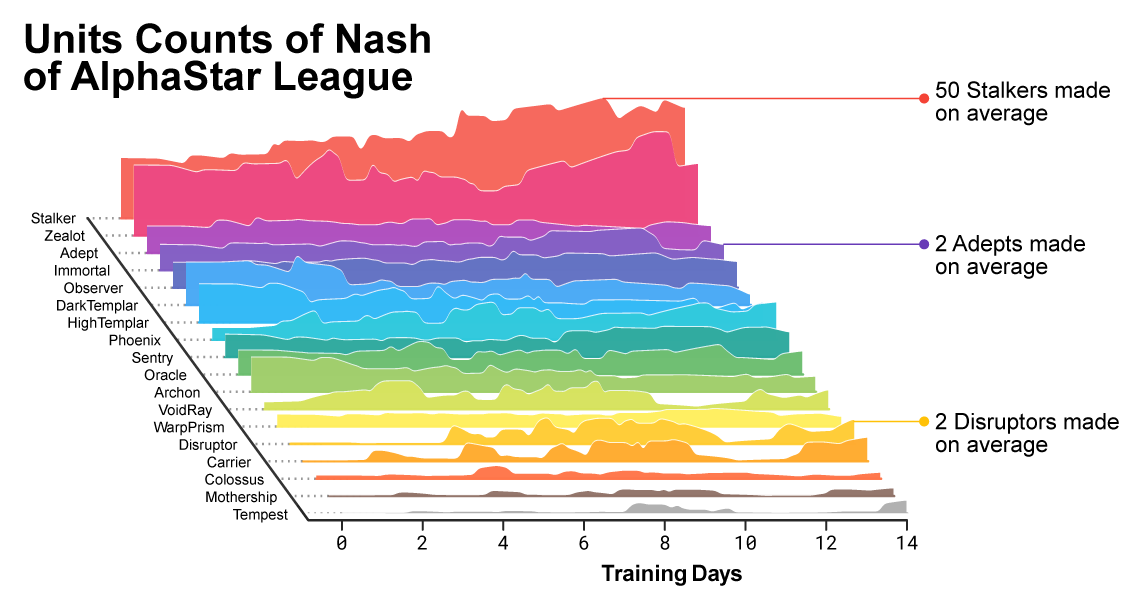 Saat pelatihan berlangsung, terlihat bagaimana komposisi unit yang digunakan oleh agen berubah.
Saat pelatihan berlangsung, terlihat bagaimana komposisi unit yang digunakan oleh agen berubah.Untuk memastikan keragaman, masing-masing agen diberkahi dengan tujuan belajarnya sendiri. Misalnya, lawan mana yang harus dikalahkan agen ini, atau motivasi intrinsik lainnya yang menentukan permainan agen. Agen tertentu mungkin memiliki tujuan untuk mengalahkan satu lawan tertentu, dan yang lainnya seluruh pilihan lawan, tetapi hanya unit tertentu. Tujuan-tujuan ini telah berubah selama proses pembelajaran.
 Visualisasi interaktif (fitur-fitur interaktif tersedia di artikel aslinya ), yang menunjukkan saingannya dengan AlphaStar League. Agen yang bermain melawan TLO dan MaNa ditandai secara terpisah.
Visualisasi interaktif (fitur-fitur interaktif tersedia di artikel aslinya ), yang menunjukkan saingannya dengan AlphaStar League. Agen yang bermain melawan TLO dan MaNa ditandai secara terpisah.Koefisien (bobot) dari jaringan saraf dari masing-masing agen diperbarui menggunakan pelatihan penguatan berdasarkan permainan dengan lawan untuk mengoptimalkan tujuan pembelajaran spesifik mereka. Aturan untuk memperbarui bobot adalah algoritma pembelajaran baru yang efektif “algoritma pembelajaran penguatan
aktor-kritik dari luar kebijakan dengan
replay pengalaman ,
pembelajaran imitasi diri , dan
distilasi kebijakan ”
(untuk akurasi istilah yang dibiarkan tanpa terjemahan) .
 Gambar menunjukkan bagaimana satu agen (titik hitam), yang dipilih sebagai hasil untuk pertandingan melawan MaNa, mengembangkan strateginya dibandingkan dengan lawan (titik berwarna) dalam proses pelatihan. Setiap poin mewakili lawan di liga. Posisi titik menunjukkan strategi, dan ukuran - frekuensi yang dipilih sebagai lawan untuk agen MaNa dalam proses pembelajaran.
Gambar menunjukkan bagaimana satu agen (titik hitam), yang dipilih sebagai hasil untuk pertandingan melawan MaNa, mengembangkan strateginya dibandingkan dengan lawan (titik berwarna) dalam proses pelatihan. Setiap poin mewakili lawan di liga. Posisi titik menunjukkan strategi, dan ukuran - frekuensi yang dipilih sebagai lawan untuk agen MaNa dalam proses pembelajaran.Untuk melatih AlphaStar, kami menciptakan sistem terdistribusi yang dapat diskalakan berdasarkan
Google TPU 3, yang menyediakan proses pelatihan paralel seluruh populasi agen dengan ribuan salinan StarCraft II yang sedang berjalan. Liga AlphaStar berlangsung 14 hari menggunakan 16 TPU untuk setiap agen. Selama pelatihan, setiap agen berpengalaman hingga 200 tahun pengalaman bermain StarCraft secara real time. Versi terakhir dari Agen AlphaStar berisi semua komponen
distribusi Nash Liga. Dengan kata lain, campuran strategi yang paling efektif yang ditemukan selama pertandingan. Dan konfigurasi ini dapat dijalankan pada satu desktop GPU standar. Deskripsi teknis lengkap sedang disiapkan untuk publikasi dalam jurnal ilmiah peer-review.
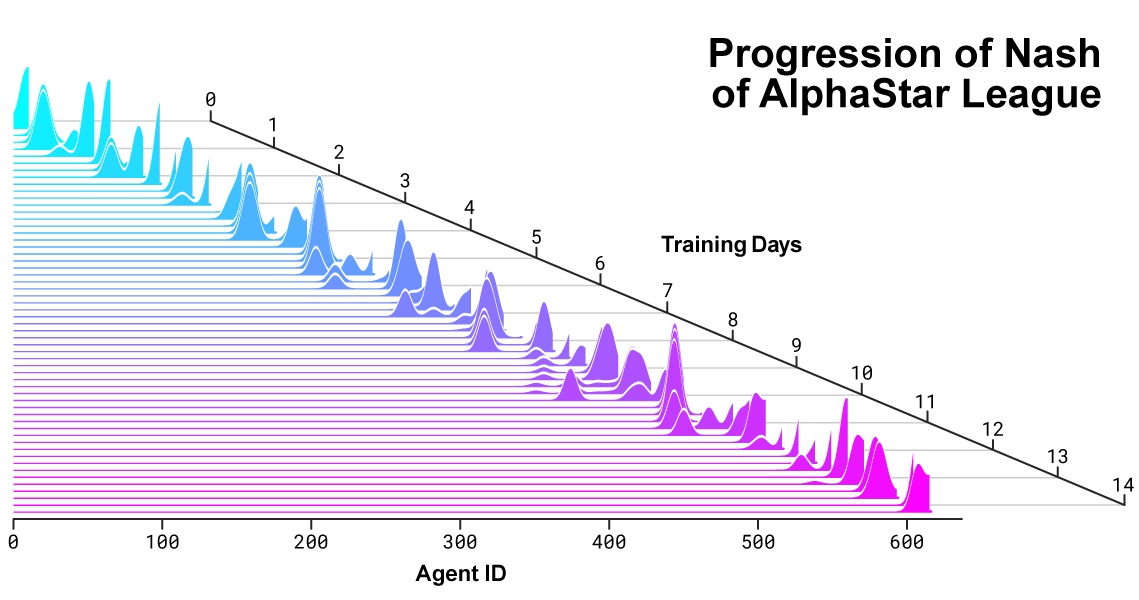 Distribusi Nash antara saingan selama pengembangan liga dan penciptaan lawan baru. Distribusi Nash, yang merupakan pesaing komplementer yang paling tidak dapat dieksploitasi, menghargai pemain baru, sehingga menunjukkan kemajuan yang berkelanjutan atas semua pesaing sebelumnya.
Distribusi Nash antara saingan selama pengembangan liga dan penciptaan lawan baru. Distribusi Nash, yang merupakan pesaing komplementer yang paling tidak dapat dieksploitasi, menghargai pemain baru, sehingga menunjukkan kemajuan yang berkelanjutan atas semua pesaing sebelumnya.Bagaimana AlphaStar bertindak dan melihat permainan
Pemain profesional seperti TLO atau MaNa dapat melakukan ratusan aksi per menit (
APM ). Tapi ini jauh lebih sedikit daripada kebanyakan
bot yang
ada yang secara independen mengontrol setiap unit dan menghasilkan ribuan, jika tidak puluhan ribu tindakan.
Dalam permainan kami melawan TLO dan MaNa, AlphaStar mempertahankan APM rata-rata 280, yang jauh lebih sedikit daripada pemain profesional, meskipun tindakannya mungkin lebih akurat. APM yang rendah ini terutama disebabkan oleh fakta bahwa AlphaStar mulai belajar berdasarkan replay dari pemain biasa dan mencoba meniru cara bermain manusia. Selain itu, AlphaStar bereaksi dengan penundaan antara pengamatan dan tindakan rata-rata sekitar 350 ms.
 Distribusi APM AlphaStar dalam pertandingan melawan MaNa dan TLO, dan penundaan keseluruhan antara pengamatan dan tindakan.
Distribusi APM AlphaStar dalam pertandingan melawan MaNa dan TLO, dan penundaan keseluruhan antara pengamatan dan tindakan.Selama pertandingan melawan TLO dan MaNa, AlphaStar berinteraksi dengan mesin game StarCraft melalui antarmuka mentah, yaitu, ia bisa melihat atribut unit musuh dan yang terlihat di peta secara langsung, tanpa harus memindahkan kamera - bermain secara efektif dengan tampilan yang berkurang dari seluruh wilayah. . Berlawanan dengan ini, manusia yang hidup harus dengan jelas mengelola "ekonomi perhatian" agar dapat secara konstan memutuskan di mana memfokuskan kamera. Namun, analisis game AlphaStar mengungkapkan bahwa itu secara implisit mengontrol fokus. Rata-rata, agen mengalihkan konteks perhatiannya sekitar 30 kali per menit, seperti MaNa dan TLO.
Selain itu, kami mengembangkan versi kedua AlphaStar. Sebagai pemain manusia, versi AlphaStar ini dengan jelas memilih kapan dan di mana harus memindahkan kamera. Dalam perwujudan ini, persepsinya terbatas pada informasi di layar, dan tindakan juga hanya diperbolehkan pada area layar yang terlihat.
 Kinerja AlphaStar saat menggunakan antarmuka dasar dan antarmuka kamera. Grafik menunjukkan bahwa agen baru yang bekerja dengan kamera dengan cepat mencapai kinerja yang sebanding untuk agen yang menggunakan antarmuka dasar.
Kinerja AlphaStar saat menggunakan antarmuka dasar dan antarmuka kamera. Grafik menunjukkan bahwa agen baru yang bekerja dengan kamera dengan cepat mencapai kinerja yang sebanding untuk agen yang menggunakan antarmuka dasar.Kami melatih dua agen baru, satu menggunakan antarmuka dasar dan satu yang seharusnya belajar bagaimana mengontrol kamera, bermain melawan liga AlphaStar. Setiap agen pada awalnya dilatih dengan seorang guru berdasarkan pertandingan manusia, diikuti dengan pelatihan dengan penguatan yang dijelaskan di atas. Versi AlphaStar, yang menggunakan antarmuka kamera, mencapai hasil yang hampir sama dengan versi dengan antarmuka dasar, melebihi angka 7000 MMR pada papan peringkat internal kami. Dalam pertandingan demonstrasi, MaNa mengalahkan prototipe AlphaStar menggunakan kamera. Kami melatih versi ini hanya 7 hari. Kami berharap bahwa kami akan dapat mengevaluasi versi yang sepenuhnya terlatih dengan kamera dalam waktu dekat.
Hasil ini menunjukkan bahwa keberhasilan AlphaStar dalam pertandingan melawan MaNa dan TLO pada dasarnya adalah hasil dari manajemen makro dan mikro yang baik, dan bukan hanya rasio klik yang besar, reaksi cepat atau akses ke informasi pada antarmuka dasar.
Hasil permainan AlphaStar vs pemain profesional
StarCraft memungkinkan pemain untuk memilih satu dari tiga balapan - terrans, zerg atau protoss. Kami memutuskan bahwa AlphaStar saat ini akan berspesialisasi dalam satu ras tertentu, protoss, untuk mengurangi waktu pelatihan dan variasi dalam mengevaluasi hasil liga domestik kami. Tetapi harus dicatat bahwa proses pembelajaran yang serupa dapat diterapkan pada ras apa pun. Agen kami dilatih untuk memainkan StarCraft II versi 4.6.2 dalam mode protoss versus protoss pada peta CatalystLE. Untuk mengevaluasi kinerja AlphaStar, kami awalnya menguji agen kami dalam pertandingan melawan TLO - pemain profesional untuk zerg dan pemain untuk protoss level "GrandMaster". AlphaStar memenangkan pertandingan dengan skor 5: 0, menggunakan berbagai unit dan membangun pesanan. "Saya terkejut seberapa kuat agen itu," katanya. “AlphaStar mengambil strategi terkenal dan membalikkannya. Agen tersebut menunjukkan strategi yang bahkan tidak pernah saya pikirkan. Dan ini menunjukkan bahwa masih ada cara untuk bermain yang masih belum sepenuhnya dipahami. "
Setelah satu minggu latihan ekstra, kami bermain melawan MaNa, salah satu pemain StarCraft II paling kuat di dunia, dan salah satu dari 10 pemain protos teratas. AlphaStar kali ini menang 5-0, menunjukkan keterampilan mikro-manajemen dan strategi-makro yang kuat. "Saya kagum melihat AlphaStar menggunakan pendekatan paling maju dan strategi berbeda di setiap pertandingan, menunjukkan gaya permainan yang sangat manusiawi yang tidak pernah saya harapkan untuk dilihat," katanya. “Saya menyadari betapa kuatnya gaya permainan saya tergantung pada penggunaan kesalahan berdasarkan reaksi manusia. Dan itu menempatkan game pada level yang sama sekali baru. Kami semua dengan antusias berharap untuk melihat apa yang terjadi selanjutnya. "
AlphaStar dan masalah sulit lainnya
Terlepas dari kenyataan bahwa StarCraft hanyalah sebuah permainan, bahkan jika itu sangat sulit, kami berpikir bahwa teknik yang mendasari AlphaStar mungkin berguna dalam menyelesaikan masalah lain. Sebagai contoh, jenis arsitektur jaringan saraf ini mampu mensimulasikan sekuens yang sangat lama dari kemungkinan tindakan, dalam gim yang sering berlangsung hingga satu jam dan berisi puluhan ribu tindakan berdasarkan informasi yang tidak lengkap. Setiap frame di StarCraft digunakan sebagai satu langkah input. Dalam hal ini, jaringan saraf setiap langkah tersebut memprediksi urutan tindakan yang diharapkan untuk seluruh permainan yang tersisa. Tugas mendasar untuk membuat ramalan yang kompleks untuk urutan data yang sangat panjang ditemukan dalam banyak masalah di dunia nyata, seperti ramalan cuaca, pemodelan iklim, memahami bahasa, dll. Kami sangat senang mengenali potensi besar yang dapat diterapkan di area ini, menggunakan pengalaman yang telah kami peroleh. dalam proyek AlphaStar.
Kami juga berpikir bahwa beberapa metode pengajaran kami mungkin berguna dalam mempelajari keamanan dan keandalan AI. Salah satu masalah yang paling sulit di bidang AI adalah jumlah opsi di mana sistem mungkin salah.
Dan pemain profesional di masa lalu dengan cepat menemukan cara untuk memotong AI, menggunakan kesalahannya dengan cara yang asli. Pendekatan AlphaStar yang inovatif, berdasarkan pelatihan di liga, menemukan pendekatan seperti itu dan membuat keseluruhan proses lebih dapat diandalkan dan terlindungi dari kesalahan tersebut. Kami senang bahwa potensi pendekatan ini dapat membantu meningkatkan keamanan dan keandalan sistem AI secara umum. Terutama di bidang-bidang kritis seperti energi, di mana sangat penting untuk bereaksi dengan benar dalam situasi sulit.Mencapai permainan tingkat tinggi di StarCraft merupakan terobosan besar dalam salah satu video game paling menantang yang pernah dibuat. Kami percaya bahwa pencapaian ini, bersama dengan keberhasilan dalam proyek lain, baik itu AlphaZero atau AlphaFold , , .
11MaNa
AlphaStar MaNa