
DeepMind, anak perusahaan Alphabet, yang bergerak dalam penelitian di bidang kecerdasan buatan, telah mengumumkan tonggak baru dalam pencarian besar ini:
untuk pertama kalinya, AI mengalahkan orang tersebut dalam strategi Starcraft II . Pada Desember 2018, jaringan saraf convolutional bernama
AlphaStar menyebarkan pemain profesional
TLO (Dario Wünsch, Jerman) dan
MaNa (Grzegorz Kominz, Polandia), mencetak sepuluh kemenangan. Perusahaan mengumumkan acara ini kemarin dalam
siaran langsung di YouTube dan Twitch.
Dalam kedua kasus, baik orang dan program diputar sebagai protoss. Meskipun TLO tidak berspesialisasi dalam balapan ini, tetapi MaNa melakukan perlawanan serius, dan bahkan memenangkan satu pertandingan.
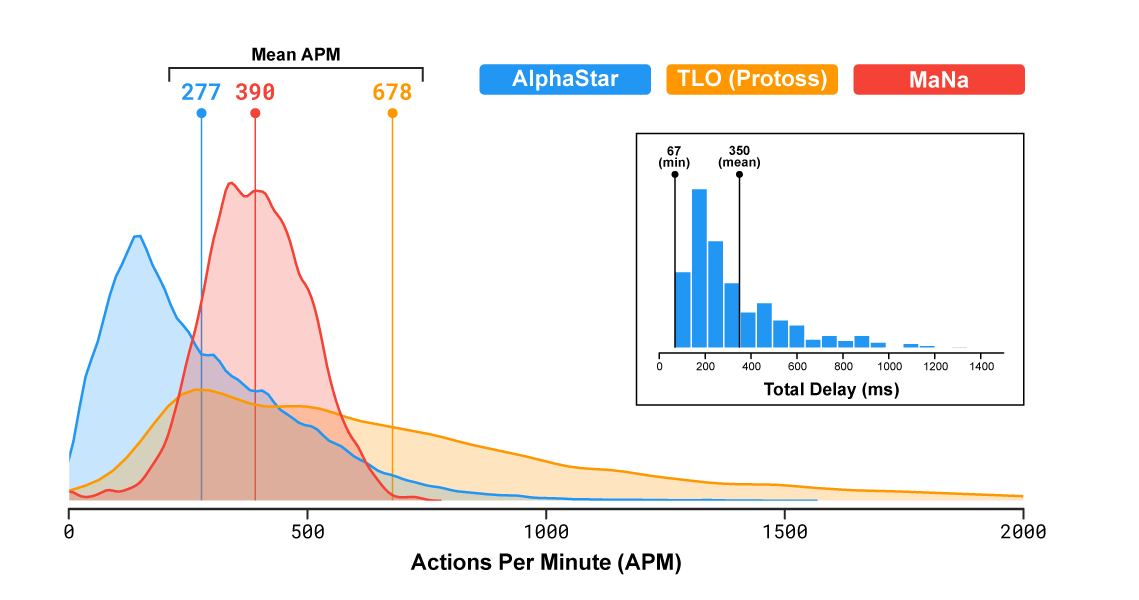
Dalam strategi real-time yang populer, pemain mewakili satu dari tiga balapan yang bersaing untuk sumber daya, membangun struktur, dan bertarung di peta besar. Penting untuk dicatat bahwa kecepatan program dan visibilitasnya di medan perang terbatas sehingga AlphaStar tidak mendapatkan keuntungan yang tidak adil atas orang-orang (koreksi: tampaknya, visibilitas hanya terbatas pada pertandingan terakhir). Sebenarnya, menurut statistik, program ini bahkan melakukan tindakan lebih sedikit per menit daripada orang: rata-rata 277 untuk AlphaStar, 390 untuk MaNa, 678 untuk TLO.
 Video ini
Video ini menunjukkan pandangan permainan dari sudut pandang agen AI di pertandingan kedua melawan MaNa. Pandangan dari sisi manusia juga diperlihatkan, tetapi itu tidak tersedia untuk program.
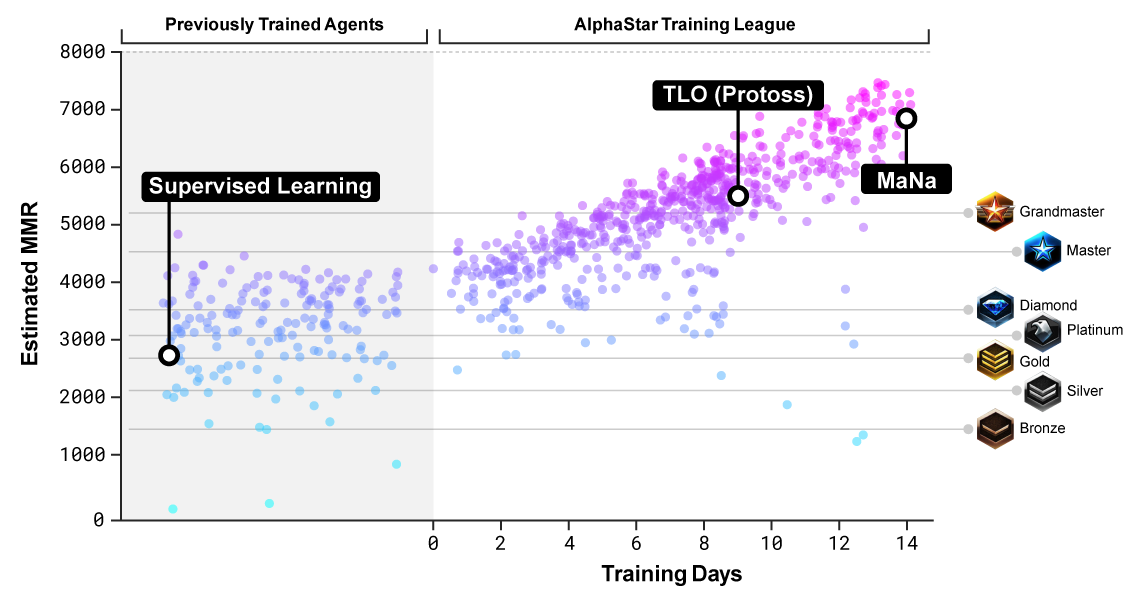
AlphaStar dilatih untuk bermain untuk protos di lingkungan yang disebut AlphaStar League. Pertama, jaringan saraf menghabiskan tiga hari melihat rekaman permainan, kemudian bermain dengan dirinya sendiri, menggunakan teknik yang dikenal sebagai pelatihan penguatan, mengasah keterampilan.
Pada bulan Desember, mereka pertama kali mengadakan sesi permainan melawan TLO, di mana lima versi berbeda dari AlphaStar diuji. Pada kesempatan ini, TLO
mengeluh bahwa dia tidak bisa beradaptasi dengan permainan lawan. Program ini menang dengan skor 5-0.
Setelah mengoptimalkan pengaturan jaringan saraf, pertandingan diselenggarakan seminggu kemudian melawan MaNa. Program ini kembali memenangkan lima pertandingan, tetapi MaNa membalas dendam di pertandingan terakhir melawan versi terbaru dari algoritma langsung, jadi dia memiliki sesuatu yang bisa dibanggakan.
 Penilaian tingkat lawan di mana jaringan saraf dilatih
Penilaian tingkat lawan di mana jaringan saraf dilatihUntuk memahami prinsip-prinsip perencanaan strategis, AlphaStar harus menguasai pemikiran khusus. Metode yang dikembangkan untuk permainan ini berpotensi berguna dalam banyak situasi praktis ketika diperlukan strategi yang kompleks: misalnya, perdagangan atau perencanaan militer.
Starcraft II bukan hanya gim yang sangat menantang. Ini juga merupakan permainan dengan informasi yang tidak lengkap, di mana pemain tidak selalu dapat melihat tindakan lawan mereka. Itu juga tidak memiliki strategi yang optimal. Dan dibutuhkan waktu untuk hasil dari tindakan pemain untuk menjadi jelas: ini juga membuat belajar menjadi sulit. Tim DeepMind menggunakan arsitektur jaringan saraf yang sangat khusus untuk menyelesaikan masalah ini.
Pembelajaran terbatas dalam permainan
DeepMind dikenal sebagai pengembang perangkat lunak yang mengalahkan profesional go dan catur terbaik dunia. Sebelum ini, perusahaan mengembangkan beberapa algoritma yang belajar memainkan game Atari sederhana. Video game adalah cara yang bagus untuk mengukur kemajuan dalam kecerdasan buatan dan membandingkan komputer dengan orang. Namun, ini adalah area pengujian yang sangat sempit. Seperti program sebelumnya, AlphaStar hanya melakukan satu tugas, meskipun sangat baik.
Kita dapat mengatakan bahwa AI tujuan sempit yang lemah menguasai keterampilan perencanaan strategis dan taktik operasi tempur. Secara teoritis, keterampilan ini dapat berguna di dunia nyata. Namun dalam praktiknya hal ini belum tentu demikian.
Beberapa ahli percaya bahwa aplikasi AI yang sangat terspesialisasi tidak ada hubungannya dengan AI yang kuat: "Program yang telah belajar memainkan video game atau papan permainan khusus dengan sangat baik di tingkat" manusia super "
benar -
benar hilang dengan sedikit perubahan kondisi (mengubah latar belakang layar atau mengubah posisi) virtual "Platform" untuk mengalahkan "bola"), - kata profesor ilmu komputer di negara Universitas Portland, Melanie Mitchell dalam artikel
"kecerdasan buatan berlari ke dalam ponima penghalang tions " . - Ini hanya beberapa contoh yang menunjukkan tidak dapat diandalkannya program AI terbaik, jika situasinya sedikit berbeda dari yang di mana mereka dilatih. Kesalahan dalam sistem ini berkisar dari konyol dan tidak berbahaya hingga berpotensi menimbulkan bencana. ”
Profesor percaya bahwa perlombaan komersialisasi AI memberikan tekanan besar pada para peneliti untuk menciptakan sistem yang bekerja "cukup baik" dalam tugas-tugas sempit. Tetapi pada akhirnya, pengembangan AI yang andal membutuhkan studi yang lebih mendalam tentang kemampuan kita sendiri dan pemahaman baru tentang mekanisme kognitif yang kita gunakan sendiri:
Pemahaman kita sendiri tentang situasi yang kita hadapi didasarkan pada "konsep akal sehat" yang luas dan intuitif tentang bagaimana dunia bekerja dan tujuan, motif, dan kemungkinan perilaku makhluk hidup lainnya, terutama orang lain. Selain itu, pemahaman kita tentang dunia didasarkan pada kemampuan dasar kita untuk menggeneralisasi apa yang kita ketahui, untuk membentuk konsep abstrak dan menggambar analogi - singkatnya, secara fleksibel menyesuaikan konsep kita dengan situasi baru. Selama beberapa dekade, para peneliti telah bereksperimen dengan mengajarkan akal sehat intuisi AI dan kemampuan manusia yang berkelanjutan untuk menggeneralisasi, tetapi sedikit kemajuan telah dibuat dalam masalah yang sangat sulit ini.
Jaringan saraf AlphaStar hanya bisa bermain untuk protoss sejauh ini. Pengembang mengumumkan rencana untuk melatihnya di masa depan untuk bermain untuk balapan lain.