
Sekali lagi, mengendarai mobil di sekitar kota asal saya dan berkeliling di lubang lain, saya berpikir: apakah jalan "baik" seperti itu ada di mana-mana di negara kami dan saya memutuskan bahwa kami harus menilai situasi secara objektif dengan kualitas jalan di negara kami.
Formalisasi tugas
Di Rusia, persyaratan untuk kualitas jalan dijelaskan dalam GOST R 50597-2017 “Jalan dan jalan. Persyaratan untuk kondisi operasional dapat diterima dalam kondisi memastikan keselamatan jalan. Metode Kontrol. " Dokumen ini menetapkan persyaratan untuk mencakup jalan, sisi jalan, garis pembatas, trotoar, trotoar pejalan kaki, dll., Dan juga menetapkan jenis kerusakan.
Karena tugas menentukan semua parameter jalan cukup luas, saya memutuskan untuk mempersempitnya sendiri dan hanya fokus pada masalah menentukan cacat dalam cakupan jalan. Dalam GOST R 50597-2017, cacat berikut pada lapisan jalan dibedakan:
- lubang
- istirahat
- drawdowns
- bergeser
- sisir
- melacak
- pengikat berkeringat
Saya memutuskan untuk mengatasi cacat ini.
Pengumpulan Data
Di mana saya bisa mendapatkan foto yang menggambarkan bagian jalan yang cukup besar, dan bahkan dengan referensi geolokasi? Jawabannya datang dalam rhinestones - panorama di peta Yandex (atau Google), namun, setelah sedikit mencari, saya menemukan beberapa opsi alternatif:
- menerbitkan mesin pencari untuk gambar untuk permintaan yang relevan;
- foto di situs untuk menerima keluhan (Rosyama, warga negara Marah, Kebajikan, dll.)
- Opendatascience meminta proyek untuk mendeteksi cacat jalan dengan dataset yang ditandai - github.com/sekilab/RoadDamageDetector
Sayangnya, analisis opsi ini menunjukkan bahwa mereka tidak cocok untuk saya: mengeluarkan mesin pencari memiliki banyak kebisingan (banyak foto yang bukan jalan, berbagai render, dll.), Foto dari situs untuk menerima keluhan hanya berisi foto dengan pelanggaran besar pada permukaan aspal , ada beberapa foto dengan sedikit pelanggaran cakupan dan tanpa pelanggaran di situs-situs ini, dataset dari proyek RoadDamageDetector dikumpulkan di Jepang dan tidak mengandung sampel dengan pelanggaran cakupan besar, serta jalan tanpa cakupan sama sekali.
Karena opsi alternatif tidak cocok, kami akan menggunakan panorama Yandex (saya mengecualikan opsi panorama Google, karena layanan ini disajikan di lebih sedikit kota di Rusia dan diperbarui lebih jarang). Dia memutuskan untuk mengumpulkan data di kota-kota dengan populasi lebih dari 100 ribu orang, serta di pusat-pusat federal. Saya membuat daftar nama kota - ada 176 di antaranya, kemudian ternyata hanya 149 di antaranya yang memiliki panorama. Saya tidak akan mempelajari fitur parsing tiles, saya akan mengatakan bahwa pada akhirnya saya mendapat 149 folder (satu untuk setiap kota) di mana terdapat total 1,7 juta foto. Misalnya, untuk Novokuznetsk, foldernya tampak seperti ini:

Dengan jumlah foto yang diunduh, kota-kota dibagikan sebagai berikut:
MejaKota
| Jumlah foto, pcs
|
|---|
Moskow
| 86048
|
Saint Petersburg
| 41376
|
Saransk
| 18880
|
Podolsk
| 18560
|
Krasnogorsk
| 18208
|
Lyubertsy
| 17760
|
Kaliningrad
| 16928
|
Kolomna
| 16832
|
Mytishchi
| 16192
|
Vladivostok
| 16096
|
Balashikha
| 15968
|
Petrozavodsk
| 15968
|
Ekaterinburg
| 15808
|
Novgorod Veliky
| 15744
|
Naberezhnye Chelny
| 15680
|
Krasnodar
| 15520
|
Nizhny Novgorod
| 15488
|
Khimki
| 15296
|
Tula
| 15296
|
Novosibirsk
| 15264
|
Tver
| 15200
|
Miass
| 15104
|
Ivanovo
| 15072
|
Vologda
| 15008
|
Zhukovsky
| 14976
|
Kostroma
| 14912
|
Samara
| 14880
|
Korolev
| 14784
|
Kaluga
| 14720
|
Cherepovets
| 14720
|
Sevastopol
| 14688
|
Pushkino
| 14528
|
Yaroslavl
| 14464
|
Ulyanovsk
| 14400
|
Rostov-on-Don
| 14368
|
Domodedovo
| 14304
|
Kamensk-Uralsky
| 14208
|
Pskov
| 14144
|
Yoshkar-Ola
| 14080
|
Kerch
| 14080
|
Murmansk
| 13920
|
Togliatti
| 13920
|
Vladimir
| 13792
|
Elang
| 13792
|
Syktyvkar
| 13728
|
Dolgoprudny
| 13696
|
Khanty-Mansiysk
| 13664
|
Kazan
| 13600
|
Engels
| 13440
|
Arkhangelsk
| 13280
|
Bryansk
| 13216
|
Omsk
| 13120
|
Syzran
| 13088
|
Krasnoyarsk
| 13056
|
Shchelkovo
| 12928
|
Penza
| 12864
|
Chelyabinsk
| 12768
|
Cheboksary
| 12768
|
Nizhny Tagil
| 12672
|
Stavropol
| 12672
|
Ramenskoye
| 12640
|
Irkutsk
| 12608
|
Angarsk
| 12608
|
Tyumen
| 12512
|
Odintsovo
| 12512
|
Ufa
| 12512
|
Magadan
| 12512
|
Perm
| 12448
|
Kirov
| 12256
|
Nizhnekamsk
| 12224
|
Makhachkala
| 12096
|
Nizhnevartovsk
| 11936
|
Kursk
| 11904
|
Sochi
| 11872
|
Tambov
| 11840
|
Pyatigorsk
| 11808
|
Volgodonsk
| 11712
|
Ryazan
| 11680
|
Saratov
| 11616
|
Dzerzhinsk
| 11456
|
Orenburg
| 11456
|
Gundukan
| 11424
|
Volgograd
| 11264
|
Izhevsk
| 11168
|
Krisostomus
| 11136
|
Lipetsk
| 11072
|
Kislovodsk
| 11072
|
Surgut
| 11040
|
Magnitogorsk
| 10912
|
Smolensk
| 10784
|
Khabarovsk
| 10752
|
Kopeysk
| 10688
|
Maykop
| 10656
|
Petropavlovsk-Kamchatsky
| 10624
|
Taganrog
| 10560
|
Barnaul
| 10528
|
Sergiev Posad
| 10368
|
Elista
| 10304
|
Sterlitamak
| 9920
|
Simferopol
| 9824
|
Tomsk
| 9760
|
Orekhovo-Zuevo
| 9728
|
Astrakhan
| 9664
|
Evpatoria
| 9568
|
Noginsk
| 9344
|
Chita
| 9216
|
Belgorod
| 9120
|
Biysk
| 8928
|
Rybinsk
| 8896
|
Severodvinsk
| 8832
|
Voronezh
| 8768
|
Blagoveshchensk
| 8672
|
Novorossiysk
| 8608
|
Ulan-Ude
| 8576
|
Serpukhov
| 8320
|
Komsomolsk-on-Amur
| 8192
|
Abakan
| 8128
|
Norilsk
| 8096
|
Yuzhno-Sakhalinsk
| 8032
|
Obninsk
| 7904
|
Essentuki
| 7712
|
Bataysk
| 7648
|
Volzhsky
| 7584
|
Novocherkassk
| 7488
|
Berdsk
| 7456
|
Arzama
| 7424
|
Pervouralsk
| 7392
|
Kemerovo
| 7104
|
Elektrostal
| 6720
|
Derbent
| 6592
|
Yakutsk
| 6528
|
Murom
| 6240
|
Nefteyugansk
| 5792
|
Reutov
| 5696
|
Birobidzhan
| 5440
|
Novokuybyshevsk
| 5248
|
Salekhard
| 5184
|
Novokuznetsk
| 5152
|
Novy Urengoy
| 4736
|
Noyabrsk
| 4416
|
Novocheboksarsk
| 4352
|
Yelets
| 3968
|
Kaspiysk
| 3936
|
Stary Oskol
| 3840
|
Artyom
| 3744
|
Zheleznogorsk
| 3584
|
Salavat
| 3584
|
Prokopyevsk
| 2816
|
Gorno-Altaysk
| 2464
|
Mempersiapkan dataset untuk pelatihan
Jadi, kumpulan data disusun, bagaimana sekarang, memiliki foto ruas jalan dan objek yang berdekatan, mengetahui kualitas aspal yang digambarkan di atasnya? Saya memutuskan untuk memotong sepotong foto berukuran 350 * 244 piksel di tengah foto asli tepat di bawah tengah. Kemudian kurangi potongan potongan secara horizontal ke ukuran 244 piksel. Gambar yang dihasilkan (ukuran 244 * 244) akan menjadi input untuk encoder convolutional:

Untuk lebih memahami data apa yang saya tangani, 2000 gambar pertama yang saya tandai sendiri, gambar-gambar lainnya ditandai oleh karyawan Yandex.Tolki. Di depan mereka saya mengajukan pertanyaan dalam susunan kata berikut.
Tunjukkan permukaan jalan yang Anda lihat di foto:
- Tanah / Reruntuhan
- Paving batu, ubin, trotoar
- Rel, rel kereta api
- Air, genangan air besar
- Aspal
- Tidak ada jalan di foto / Benda asing / Cakupan tidak terlihat karena mobil
Jika pemain memilih "Aspal", muncul menu yang menawarkan untuk mengevaluasi kualitasnya:
- Cakupan luar biasa
- Sedikit celah tunggal / lubang tunggal dangkal
- Retak besar / Retak kisi / lubang tunggal tunggal
- Lubang Besar / Lubang Dalam / Lapisan Hancur
Seperti yang ditunjukkan oleh uji coba tugas, pelaksana Y. Toloki tidak berbeda dalam integritas pekerjaan - mereka secara tidak sengaja mengklik bidang dengan mouse dan mempertimbangkan tugas selesai. Saya harus menambahkan pertanyaan kontrol (ada 46 foto dalam tugas, 12 di antaranya adalah kontrol) dan memungkinkan penerimaan tertunda. Sebagai pertanyaan kontrol, saya menggunakan foto-foto yang saya buat sendiri. Saya mengotomatiskan penerimaan yang tertunda - Y. Toloka memungkinkan Anda untuk mengunggah hasil kerja ke file CSV, dan memuat hasil verifikasi tanggapan. Verifikasi jawaban berfungsi sebagai berikut - jika tugas tersebut berisi lebih dari 5% jawaban salah untuk mengendalikan pertanyaan, maka dianggap tidak terpenuhi. Selain itu, jika kontraktor mengindikasikan jawaban yang secara logika mendekati benar, maka jawabannya dianggap benar.
Hasilnya, saya mendapat sekitar 30 ribu foto yang ditandai, yang saya putuskan untuk distribusikan dalam tiga kelas untuk pelatihan:
- "Bagus" - foto yang diberi label "Aspal: Pelapis Sangat Baik" dan "Aspal: Retak Tunggal Kecil"
- "Tengah" - foto yang diberi label "Paving stones, tiles, trotoar", "Rails, rail railway" dan "Asphalt: Big cracks / Grid cracks / single minor lents"
- "Besar" - foto berlabel "Tanah / Hancur batu", "Air, genangan air besar" dan "Aspal: Sejumlah besar lubang / lubang dalam / Trotoar yang hancur"
- Foto dengan tag "Tidak ada jalan di foto / Benda asing / Cakupan tidak terlihat karena mobil" jumlahnya sangat sedikit (22 pcs.) Dan saya mengecualikan mereka dari pekerjaan lebih lanjut
Pengembangan dan pelatihan pengklasifikasi
Jadi, data dikumpulkan dan diberi label, kami melanjutkan ke pengembangan classifier. Biasanya, untuk tugas-tugas klasifikasi gambar, terutama ketika pelatihan pada dataset kecil, encoder konvolusional siap pakai digunakan, untuk output yang terhubung dengan pengklasifikasi baru. Saya memutuskan untuk menggunakan classifier sederhana tanpa lapisan tersembunyi, lapisan input ukuran 128 dan lapisan output ukuran 3. Saya memutuskan untuk segera menggunakan beberapa opsi siap pakai yang dilatih di ImageNet sebagai encoders:
- Xception
- Resnet
- Awal
- Vgg16
- Densenet121
- Mobilenet
Berikut adalah fungsi yang membuat model Keras dengan encoder yang diberikan:
def createModel(typeModel): conv_base = None if(typeModel == "nasnet"): conv_base = keras.applications.nasnet.NASNetMobile(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "xception"): conv_base = keras.applications.xception.Xception(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "resnet"): conv_base = keras.applications.resnet50.ResNet50(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "inception"): conv_base = keras.applications.inception_v3.InceptionV3(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "densenet121"): conv_base = keras.applications.densenet.DenseNet121(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "mobilenet"): conv_base = keras.applications.mobilenet_v2.MobileNetV2(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "vgg16"): conv_base = keras.applications.vgg16.VGG16(include_top=False, input_shape=(224,224,3), weights='imagenet') conv_base.trainable = False model = Sequential() model.add(conv_base) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.0002))) model.add(Dropout(0.3)) model.add(Dense(3, activation='softmax')) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
Untuk pelatihan, saya menggunakan generator dengan augmentasi (karena kemungkinan augmentasi yang tertanam dalam Keras tampaknya bagi saya tidak cukup, maka saya menggunakan perpustakaan
Augmentor ):
- Lereng
- Distorsi acak
- Ternyata
- Tukar warna
- Bergeser
- Ubah kontras dan kecerahan
- Menambahkan noise acak
- Pangkas
Setelah augmentasi, foto-foto tampak seperti ini:

Kode Generator:
def get_datagen(): train_dir='~/data/train_img' test_dir='~/data/test_img' testDataGen = ImageDataGenerator(rescale=1. / 255) train_generator = datagen.flow_from_directory( train_dir, target_size=img_size, batch_size=16, class_mode='categorical') p = Augmentor.Pipeline(train_dir) p.skew(probability=0.9) p.random_distortion(probability=0.9,grid_width=3,grid_height=3,magnitude=8) p.rotate(probability=0.9, max_left_rotation=5, max_right_rotation=5) p.random_color(probability=0.7, min_factor=0.8, max_factor=1) p.flip_left_right(probability=0.7) p.random_brightness(probability=0.7, min_factor=0.8, max_factor=1.2) p.random_contrast(probability=0.5, min_factor=0.9, max_factor=1) p.random_erasing(probability=1,rectangle_area=0.2) p.crop_by_size(probability=1, width=244, height=244, centre=True) train_generator = keras_generator(p,batch_size=16) test_generator = testDataGen.flow_from_directory( test_dir, target_size=img_size, batch_size=32, class_mode='categorical') return (train_generator, test_generator)
Kode menunjukkan bahwa augmentasi tidak digunakan untuk data uji.
Memiliki generator yang disetel, Anda dapat mulai melatih model, kami akan melakukannya dalam dua tahap: pertama, hanya melatih classifier kami, kemudian sepenuhnya seluruh model.
def evalModelstep1(typeModel): K.clear_session() gc.collect() model=createModel(typeModel) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=4, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, ) return model def evalModelstep2(model): early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3) model.layers[0].trainable=True model.trainable=True model.compile(optimizer=keras.optimizers.Adam(lr=1e-5), loss='binary_crossentropy', metrics=['accuracy']) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=25, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, callbacks=[early_stopping_callback] ) return model def full_fit(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] for model_name in model_names: print("#########################################") print("#########################################") print("#########################################") print(model_name) print("#########################################") print("#########################################") print("#########################################") model = evalModelstep1(model_name) model = evalModelstep2(model) model.save("~/data/models/model_new_"+str(model_name)+".h5")
Panggil full_fit () dan tunggu. Kami menunggu lama.
Sebagai hasilnya, kami akan memiliki enam model terlatih, kami akan memeriksa keakuratan model-model ini pada bagian terpisah dari data berlabel; Saya menerima yang berikut:
Nama model
| Akurasi%
|
Xception
| 87.3
|
Resnet
| 90.8
|
Awal
| 90.2
|
Vgg16
| 89.2
|
Densenet121
| 90.6
|
Mobilenet
| 86.5
|
Secara umum, tidak banyak, tetapi dengan sampel pelatihan yang kecil, orang tidak bisa berharap lebih. Untuk sedikit meningkatkan akurasi, saya menggabungkan output model dengan rata-rata:
def create_meta_model(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] model_input = Input(shape=(244,244,3)) submodels=[] i=0; for model_name in model_names: filename= "~/data/models/model_new_"+str(model_name)+".h5" submodel = keras.models.load_model(filename) submodel.name = model_name+"_"+str(i) i+=1 submodels.append(submodel(model_input)) out=average(submodels) model = Model(inputs = model_input,outputs=out) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
Akurasi yang dihasilkan adalah 91,3%. Atas hasil ini, saya memutuskan untuk berhenti.
Menggunakan Classifier
Akhirnya classifier siap dan dapat digunakan! Saya menyiapkan data input dan menjalankan pengklasifikasi - sedikit lebih dari sehari dan 1,7 juta foto telah diproses. Sekarang bagian yang menyenangkan adalah hasilnya. Segera bawa sepuluh kota pertama dan terakhir dalam jumlah relatif jalan dengan cakupan yang baik:

Tabel lengkap (gambar yang dapat diklik) Dan berikut adalah peringkat kualitas jalan oleh subyek federal:
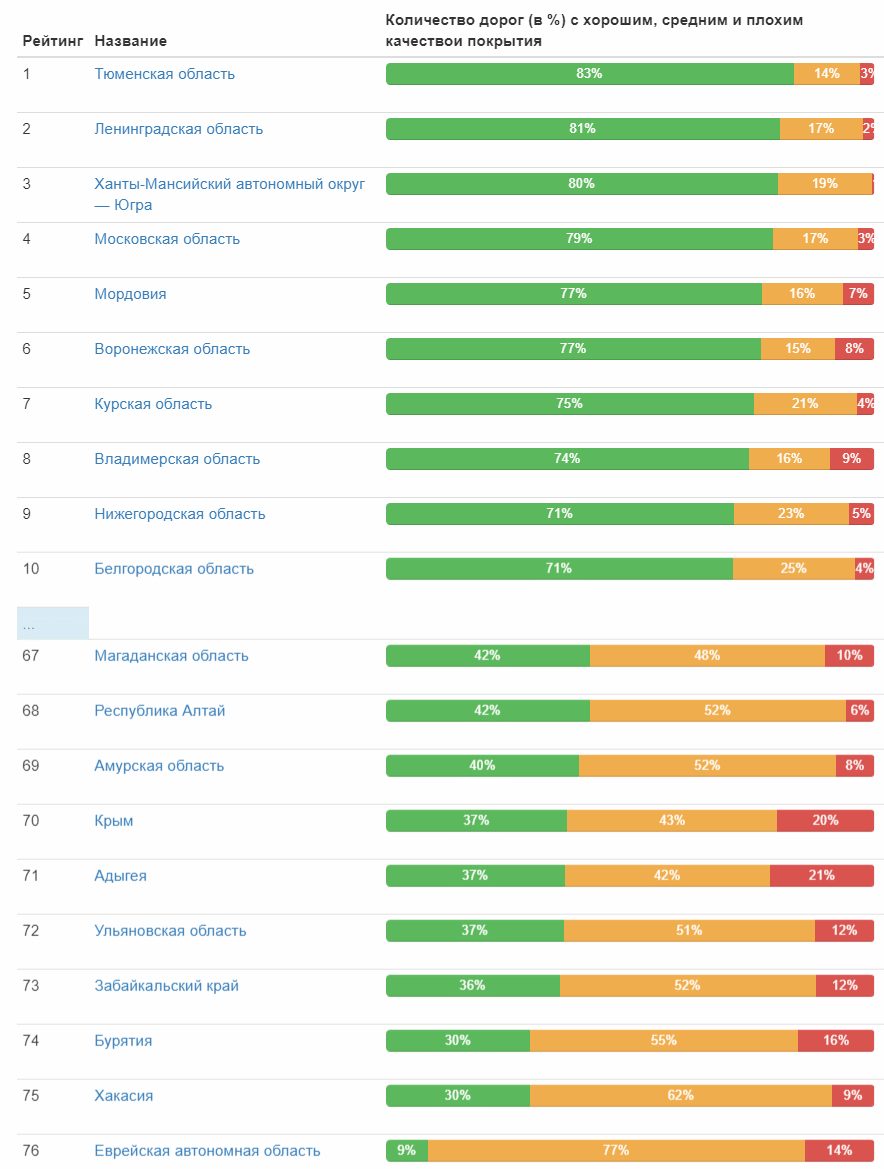
Peringkat menurut distrik federal:
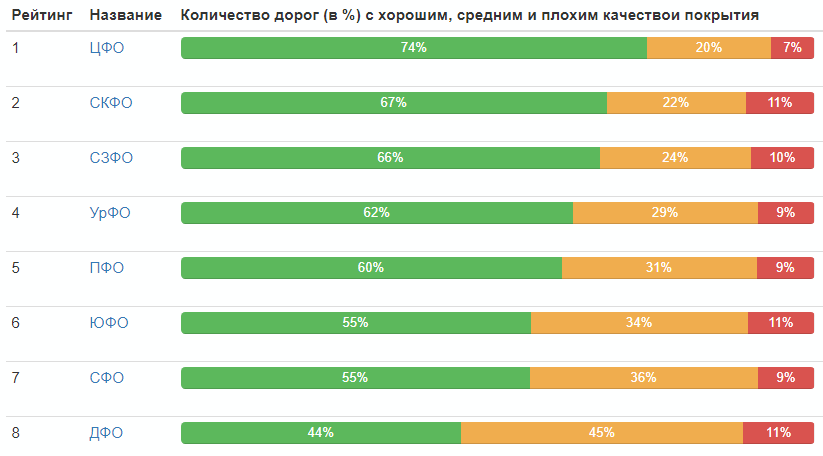
Distribusi kualitas jalan di Rusia secara keseluruhan:

Yah, itu saja, semua orang bisa menarik kesimpulan sendiri.
Akhirnya, saya akan memberikan foto terbaik di setiap kategori (yang menerima nilai maksimum di kelas mereka):
PS Dalam komentar, cukup tepat menunjukkan kurangnya statistik pada tahun-tahun penerimaan foto-foto. Saya memperbaiki dan memberikan tabel:
Tahun
| Jumlah foto, pcs
|
| 2008 | 37 |
| 2009 | 13 |
| 2010 | 157030 |
| 2011 | 60724 |
| 2012 | 42387 |
| 2013 | 12148
|
| 2014 | 141021
|
| 2015 | 46143
|
| 2016 | 410385
|
| 2017 | 324279
|
| 2018 | 581961
|