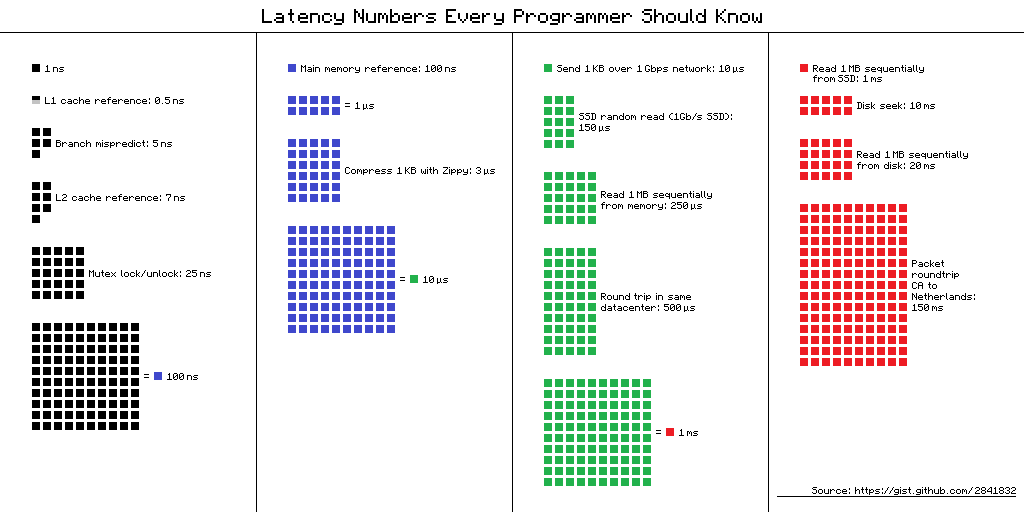
Nomor Latensi yang Harus Diketahui Setiap Programmer - tabel "penundaan yang harus diketahui oleh setiap programmer." Ini berisi nilai rata-rata waktu untuk melakukan operasi komputer dasar pada 2012. Ada beberapa pandangan alternatif untuk tabel ini, dan ini adalah salah satunya.
 Tautan ke sumber skema
Tautan ke sumber skemaTetapi apa manfaatnya bagi pengembang seluler dari informasi ini pada tahun 2019? Tampaknya tidak, tetapi
Dmitry Kurkin (
SClown ) dari tim Yandex.Navigator berpikir: "Seperti apa meja itu untuk iPhone modern?" Apa yang terjadi, dalam versi teks revisi laporan Dmitry di
AppsConf .
Untuk apa ini?
Mengapa programmer harus tahu angka-angka ini? Dan apakah itu relevan untuk pengembang seluler? Ada dua tugas utama yang bisa diselesaikan dengan bantuan angka-angka ini.
Memahami skala waktu di komputer
Ambil situasi sederhana - percakapan telepon. Kita dapat dengan mudah mengetahui kapan proses ini cepat dan kapan: beberapa detik sangat cepat, beberapa menit adalah percakapan rata-rata, dan satu jam atau lebih sangat lama. Dengan memuat halaman, itu serupa: dalam waktu kurang dari satu detik - cepat, beberapa detik - tertahankan, dan satu menit adalah bencana, pengguna mungkin tidak menunggu untuk mengunduh.
Tapi bagaimana dengan operasi seperti menambahkan nomor ke array - "insert cepat" yang kadang-kadang orang suka bicarakan dalam wawancara? Berapa yang dibutuhkan untuk smartphone? Nanodetik, mikrodetik, atau milidetik? Saya telah bertemu beberapa orang yang bisa mengatakan bahwa 1 milidetik adalah waktu yang lama, tetapi dalam kasus kami begitu.
Rasio kecepatan berbagai komponen komputer
Waktu pelaksanaan operasi pada berbagai perangkat dapat bervariasi hingga puluhan atau ratusan kali. Misalnya, waktu akses ke memori utama adalah 100 kali berbeda dari mengakses cache L1. Ini adalah perbedaan besar, tetapi tidak terbatas. Jika kita memiliki makna khusus untuk ini, maka ketika mengoptimalkan aplikasi kita, kita dapat mengevaluasi apakah akan ada penambahan waktu atau tidak.

"Nomor latensi" dalam kehidupan nyata
Ketika saya melihat angka-angka ini, saya menjadi tertarik pada perbedaan antara cache dan akses memori. Jika saya hati-hati memasukkan data saya dalam 64 Kbytes, yang tidak terlalu kecil, maka kode saya akan bekerja 100 kali lebih cepat - cepat, semuanya akan terbang!

Saya segera ingin memeriksanya, menunjukkannya kepada kolega saya, dan menerapkannya sedapat mungkin. Saya memutuskan untuk memulai dengan alat standar yang ditawarkan Apple - XCTest dengan MeasBlock. Tes diatur sebagai berikut: mengalokasikan array, mengisinya dengan angka, XOR'il mereka dan mengulangi algoritme 10 kali, pasti. Setelah itu, saya melihat berapa banyak waktu yang dibutuhkan untuk satu elemen.
| Ukuran penyangga | Total waktu | Waktunya untuk operasi |
| 50 kb | 1,5 ms | 30 ns |
| 500 kb | 12 md | 24 ns |
| 5000 kb | 85 ms | 17 ns |
Ukuran buffer meningkat 100 kali, dan waktu untuk operasi tidak hanya meningkat 100 kali, tetapi menurun hampir 2 kali.
Tuan-tuan, petugas, mereka mengkhianati kita ?!Setelah hasil seperti itu, keraguan besar merayapi saya bahwa angka-angka ini dapat dilihat dalam kehidupan nyata. Mungkin tidak mungkin bagi aplikasi reguler untuk merasakan perbedaan ini. Atau mungkin pada platform seluler semuanya berbeda.
Saya mulai mencari cara untuk melihat perbedaan kinerja antara cache dan memori utama. Selama pencarian, saya menemukan sebuah artikel di mana penulis mengeluh bahwa ia memiliki benchmark yang berjalan di Mac dan iPhone-nya dan tidak menunjukkan penundaan ini. Saya mengambil alat ini dan mendapatkan hasilnya - seperti di apotek. Waktu akses memori meningkat cukup jelas ketika ukuran buffer melebihi ukuran cache yang sesuai.
 LMbench
LMbench membantu saya mendapatkan hasil ini. Ini adalah patokan yang dibuat oleh Larry McVoy, salah satu pengembang kernel Linux, yang memungkinkan Anda untuk mengukur waktu akses memori, biaya beralih thread dan operasi sistem file, dan bahkan waktu yang dibutuhkan oleh operasi prosesor utama: penambahan, pengurangan, dll. Menurut patokan ini Texas Instruments menyajikan
data pengukuran yang
menarik untuk prosesornya. LMBench ditulis dalam C, jadi tidak sulit untuk menjalankannya di iOS.
Biaya Memori
Berbekal alat yang luar biasa, saya memutuskan untuk melakukan pengukuran serupa, tetapi untuk perangkat seluler yang sebenarnya - untuk iPhone. Pengukuran utama dilakukan pada 5S, dan kemudian saya mendapatkan hasilnya ketika perangkat lain jatuh ke tangan saya. Karena itu, jika perangkat tidak ditentukan, maka itu adalah 5S.
Akses memori
Untuk tes ini, array khusus digunakan, yang diisi dengan elemen yang saling referensi. Setiap elemen adalah penunjuk ke elemen lain. Array tidak dilalui oleh indeks, tetapi dengan transisi dari satu node ke yang lain. Elemen-elemen ini tersebar di array sehingga, ketika mengakses elemen baru, sesering mungkin itu tidak ada dalam cache, tetapi diturunkan dari RAM. Pengaturan ini mengganggu cache sebanyak mungkin.
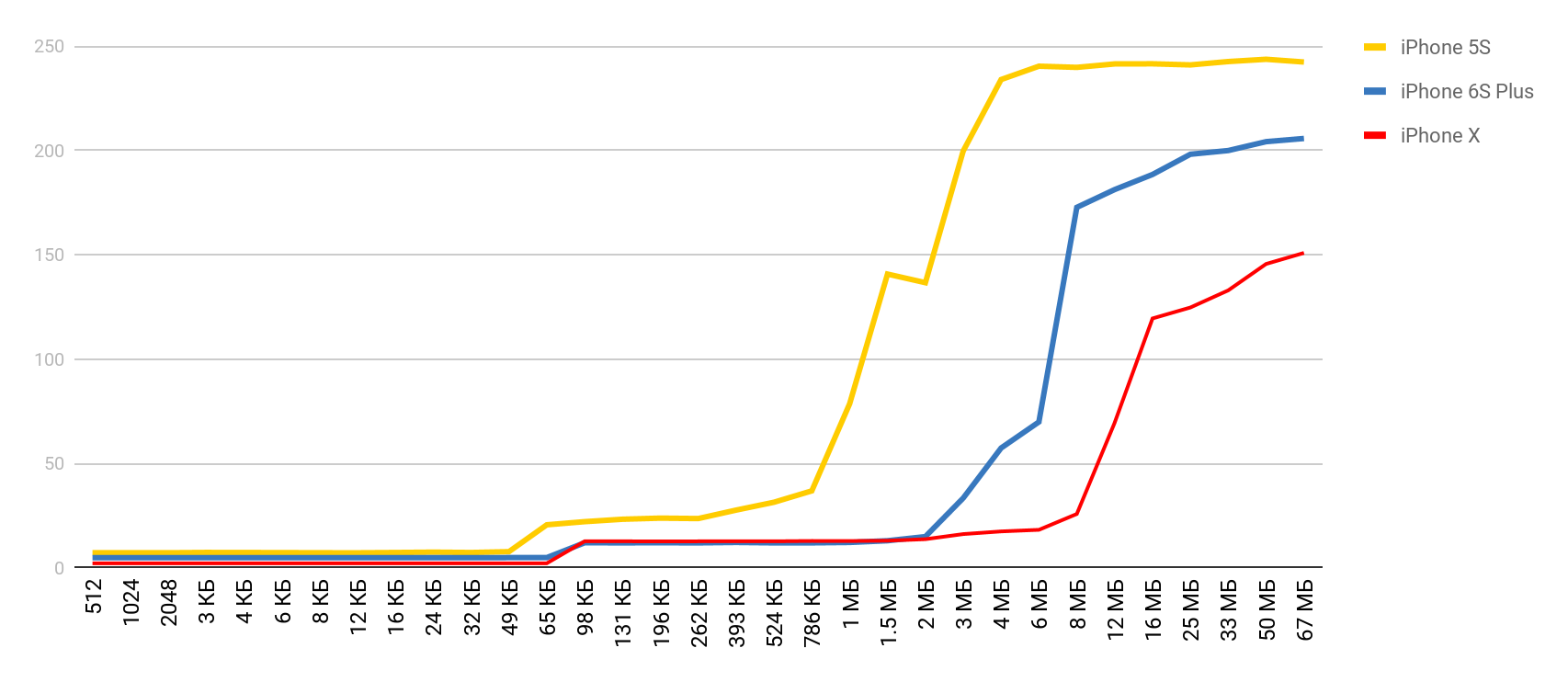
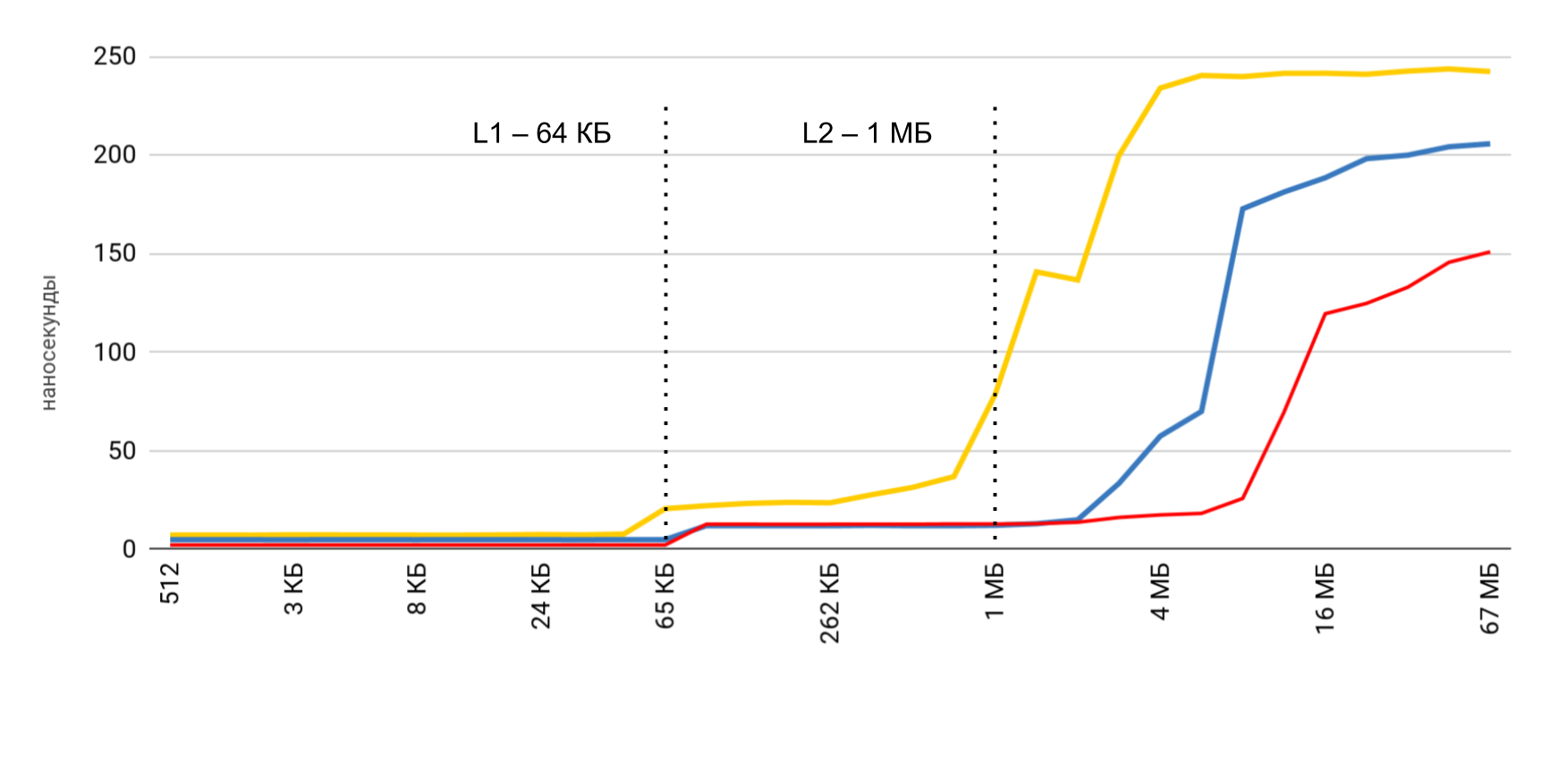
Anda sudah melihat hasil awal. Dalam kasus cache L1, itu kurang dari 10 nanodetik, untuk L2 itu adalah beberapa puluhan nanodetik, dan dalam kasus memori utama, waktu naik menjadi ratusan nanodetik.
Kecepatan baca dan tulis
Tiga operasi utama diukur:
- reading ( p [i] + ) - kita membaca elemen dan menambahkannya ke jumlah total;
- record ( p [i] = 1 ) - angka konstan ditulis di setiap elemen;
- membaca dan menulis ( p [i] = p [i] * 2 ) - kita mengambil elemen, mengubahnya dan menulis nilai baru kembali.
Ketika bekerja dengan buffer, 2 pendekatan digunakan: dalam kasus pertama, hanya setiap elemen keempat yang digunakan, dan yang kedua, semua elemen berurutan.
Kecepatan tertinggi diperoleh dengan ukuran buffer kecil, dan kemudian ada langkah-langkah yang jelas, sesuai dengan ukuran cache L1 dan L2. Yang paling menarik adalah ketika data dibaca berurutan, tidak ada pengurangan kecepatan. Namun dalam hal operan, langkah yang jelas terlihat.
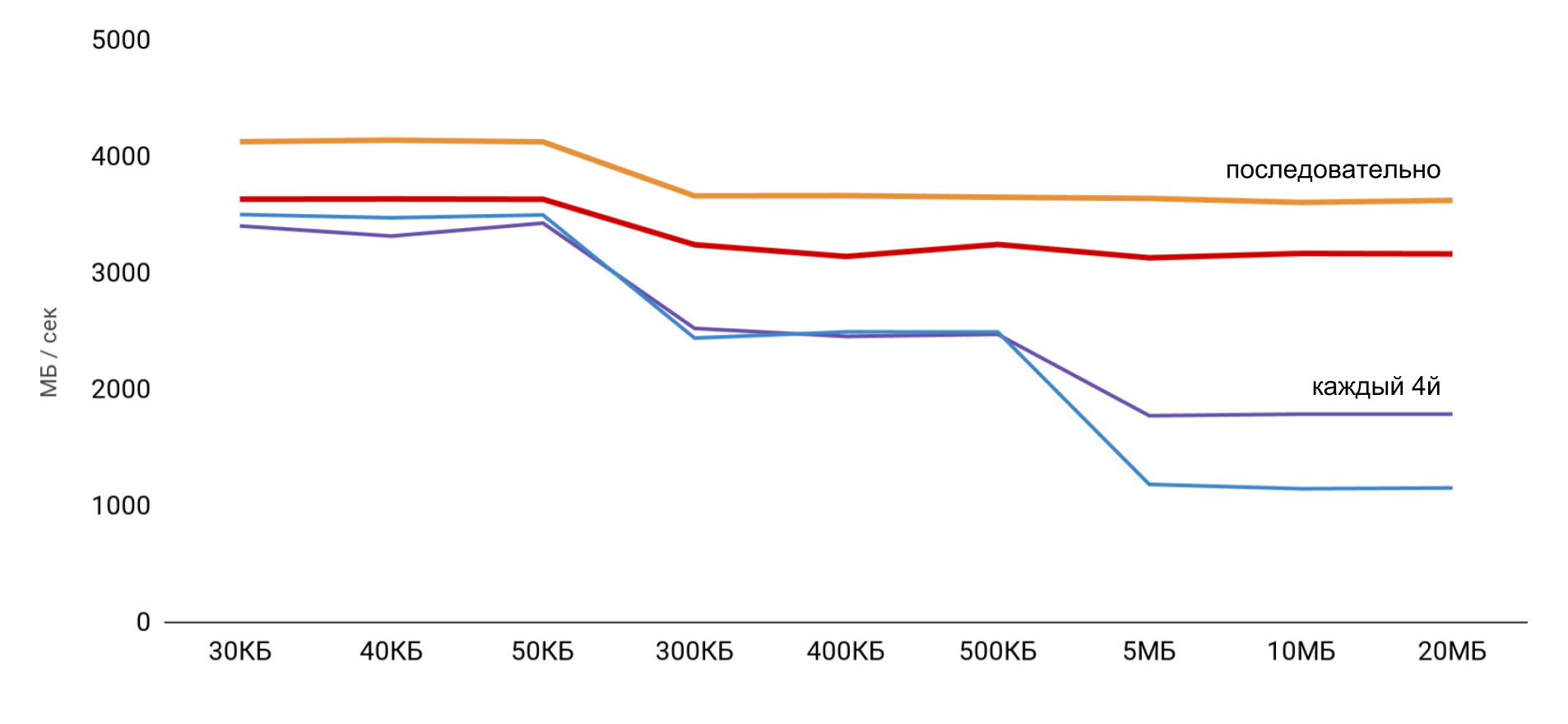
Selama pembacaan berurutan, OS mengatur untuk memuat data yang diperlukan ke dalam cache, jadi untuk ukuran buffer apa pun saya tidak perlu mengakses memori - semua data yang diperlukan diperoleh dari cache. Ini menjelaskan mengapa saya tidak melihat perbedaan waktu dalam tes dasar saya.
Hasil pengukuran operasi baca dan tulis menunjukkan bahwa dalam aplikasi normal cukup sulit untuk memperoleh estimasi percepatan 100 kali. Di satu sisi, sistem itu sendiri menyimpan data dengan cukup baik, dan bahkan dengan array besar kita sangat mungkin menemukan data dalam cache. Dan di sisi lain, bekerja dengan berbagai variabel dapat dengan mudah memerlukan akses ke memori dan hilangnya ratusan nanodetik yang dimenangkan.
| L1 | L2 | Memori |
| Nomor latensi | 1 ns | 7 ns | 100 ns |
| iPhone 5s | 7 ns | 30 ns | 240 ns |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns |
| iPhone X | 2 ns | 12 ns | 146 ns |
Biaya Threading
Selanjutnya, saya ingin mendapatkan data serupa untuk bekerja dengan utas untuk
memahami biaya penggunaan multithreading : berapa biaya untuk membuat utas dan beralih dari satu utas ke yang lain. Bagi kami, ini adalah operasi yang sering, dan saya ingin memahami kerugiannya.
Instrumen. Jejak sistem
System Trace banyak membantu untuk melacak pekerjaan utas dalam aplikasi. Alat ini dijelaskan secara rinci di
WWDC 2016 . Alat ini membantu untuk melihat transisi dengan kondisi aliran dan menyajikan data tentang aliran dalam tiga kategori utama: panggilan sistem, bekerja dengan memori dan kondisi aliran.
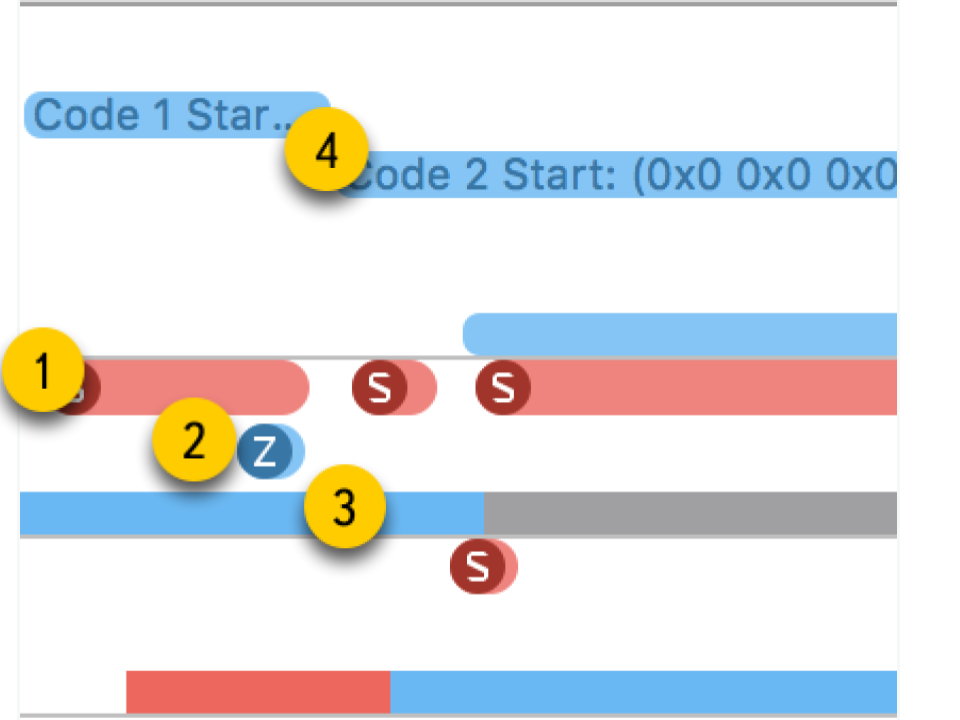
- Panggilan sistem Mereka disajikan dalam bentuk "sosis" merah. Ketika Anda mengarahkan mereka, Anda dapat melihat nama metode sistem dan durasi eksekusi. Seringkali dalam aplikasi aplikasi, panggilan sistem seperti itu tidak terjadi secara langsung: kami menggunakan sesuatu, yang pada gilirannya sudah memanggil metode sistem. Anda seharusnya tidak mengandalkan fakta bahwa di sini metode dari kode Anda akan terlihat.
- Operasi memori . Mereka disajikan dalam bentuk "sosis" biru. Ini termasuk operasi seperti alokasi memori, pembebasan, pengenolan, dll.
- Keadaan aliran . Warna biru - utas sedang berjalan, sebagian prosesor menjalankan kode dari utas ini. Abu-abu - utas diblokir karena alasan tertentu dan tidak dapat melanjutkan eksekusi. Merah - utas siap bekerja, tetapi saat ini tidak ada kernel gratis untuk mengeksekusi kodenya. Warna oranye - aliran terputus untuk pekerjaan dengan prioritas lebih tinggi.
- Tempat menarik . Ini adalah label khusus yang dapat diatur oleh kode dengan memanggil
kdebug_signpost . Label bisa tunggal (tempat tertentu dalam kode) atau sebagai rentang (untuk menyorot seluruh prosedur). Dengan menggunakan label semacam itu, jauh lebih mudah untuk menghubungkan mikrodetik dan panggilan sistem dengan aplikasi Anda.
Streaming biaya pembuatan
Tes pertama adalah
pelaksanaan tugas di utas baru . Kami membuat utas dengan prosedur tertentu dan menunggu untuk menyelesaikan pekerjaannya. Membandingkan total waktu dengan waktu untuk prosedur itu sendiri, kami mendapatkan total kerugian untuk memulai prosedur di utas baru.
Di System Trace Anda dapat dengan jelas melihat bagaimana semuanya benar-benar terjadi:
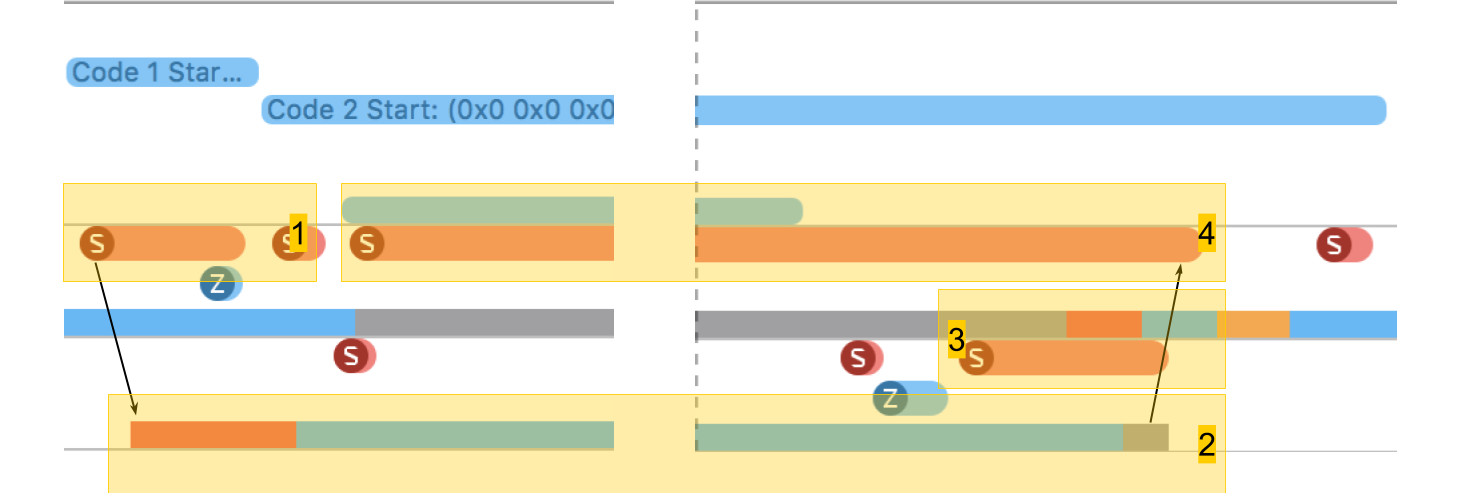
- Buat aliran.
- Utas baru tempat prosedur kami berjalan. Zona merah di awal mengatakan bahwa utas dibuat, tetapi untuk beberapa waktu tidak dapat dijalankan, karena tidak ada inti bebas.
- Selesainya aliran. Menariknya, prosedur penyelesaian utas itu sendiri bahkan lebih besar dari penciptaannya. Meskipun tampaknya menghapus selalu lebih cepat.
- Menunggu penyelesaian prosedur, yang berada dalam skema asli, dan berakhir setelah aliran berakhir - untuk sementara waktu metode ini menyadari hal ini dan, setelah itu, melaporkan. Waktu ini sedikit lebih lama dari penyelesaian aliran.
Akibatnya, membuat aliran memerlukan biaya yang cukup signifikan: iPhone 5S - 230 mikrodetik, 6S - 50 mikrodetik.
Penyelesaian aliran memakan waktu hampir 2 kali lebih banyak dari pada pembuatannya , bergabung juga membutuhkan waktu yang nyata. Ketika bekerja dengan memori, kami mendapat ratusan nanodetik, yang 100 kali lebih kecil dari puluhan mikrodetik.
| overhead | buat | akhir | bergabunglah |
| iPhone 5s | 230 μs | 40 μs | 70 μs | 30 μs |
| iPhone 6s Plus | 50 μs | 12 μs | 20 μs | 7 μs |
Semaphore switching time
Tes selanjutnya adalah
pengukuran pada karya semaphore . Kami memiliki 2 utas yang telah dibuat sebelumnya, dan untuk masing-masingnya ada semafor. Streaming secara bergantian menandakan semafor tetangga dan menunggu untuk mereka sendiri. Melewati sinyal satu sama lain, stream bermain ping-pong, saling menghidupkan kembali. Iterasi ganda ini memberikan waktu switching semafor ganda.
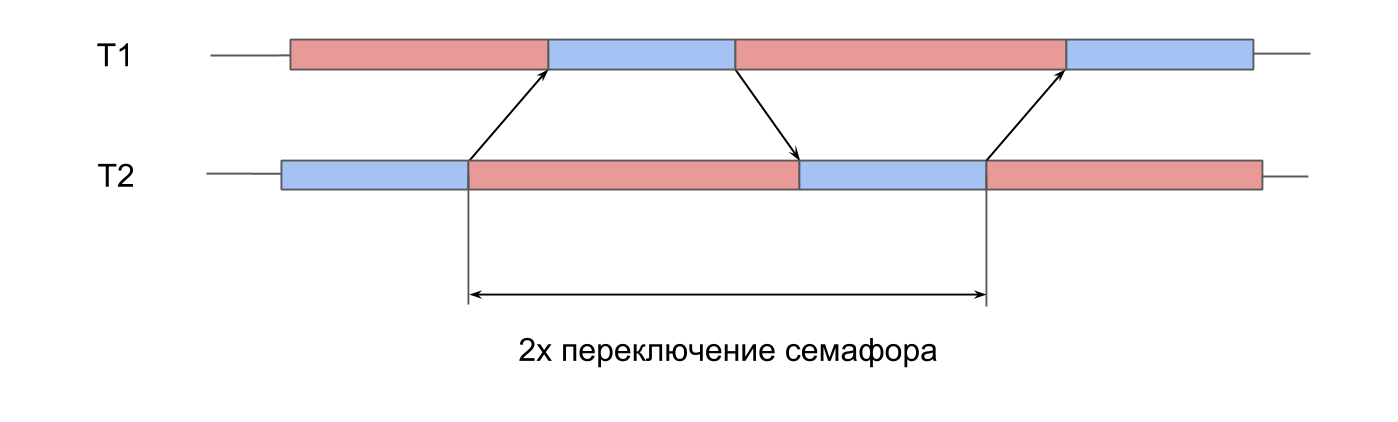
Di System Trace, semuanya terlihat mirip:
- Sinyal diberikan untuk semafor aliran kedua. Dapat dilihat bahwa operasi ini sangat singkat.
- Utas kedua tidak dikunci, menunggu di ujung semafornya.
- Sinyal diberikan untuk semafor aliran pertama.
- Utas pertama tidak diblokir, penantian di ujung semafornya.
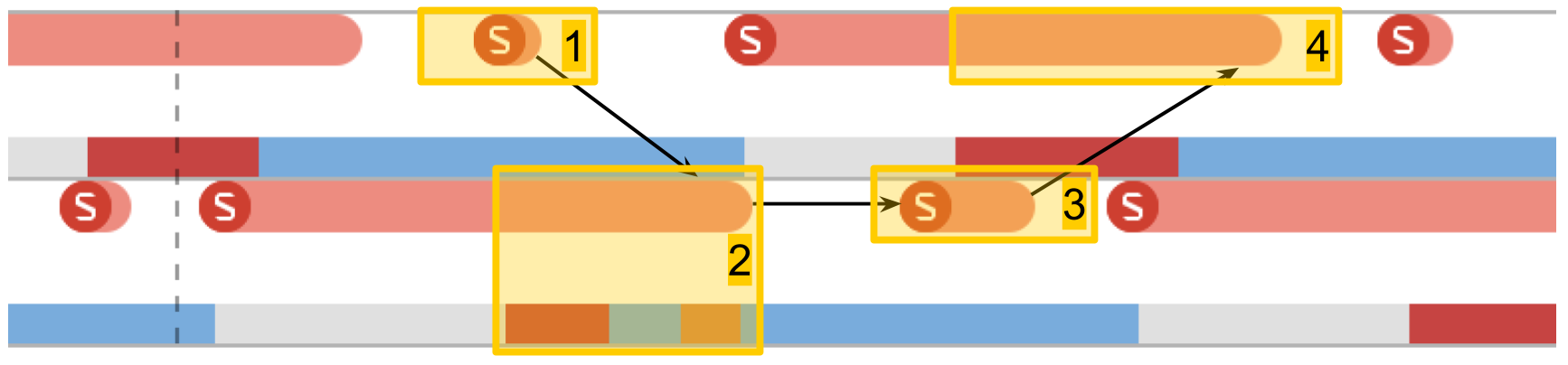
Waktu switching dalam 10 mikrodetik. Perbedaan dengan membuat utas sebanyak 50 kali persis alasan mengapa kumpulan utas dibuat, dan bukan utas baru untuk setiap prosedur.
Kerugian pada pengalihan konteks thread sistem
Dalam dua tes sebelumnya, transfer kontrol antara utas sepenuhnya dikontrol - kami memahami dengan jelas di mana dan di mana transisi harus terjadi. Namun, sering terjadi bahwa sistem itu sendiri berpindah dari satu utas ke utas lainnya. Ketika kami menjalankan lebih banyak tugas secara paralel dari inti pada perangkat, sistem operasi harus dapat beralih sendiri untuk memberikan waktu prosesor kepada semua orang.
Dalam tes ini, saya ingin mengukur hilangnya memulai terlalu banyak utas. Untuk melakukan ini, kumpulan 16 thread dibuat, masing-masing menunggu semaphore, dan, segera setelah menerima sinyal, melakukan prosedur tertentu dan memberi sinyal semaphore kembali. Utas utama memulai keseluruhan kumpulan, memberikan 16 sinyal, dan setelah itu menunggu 16 sinyal sebagai respons.
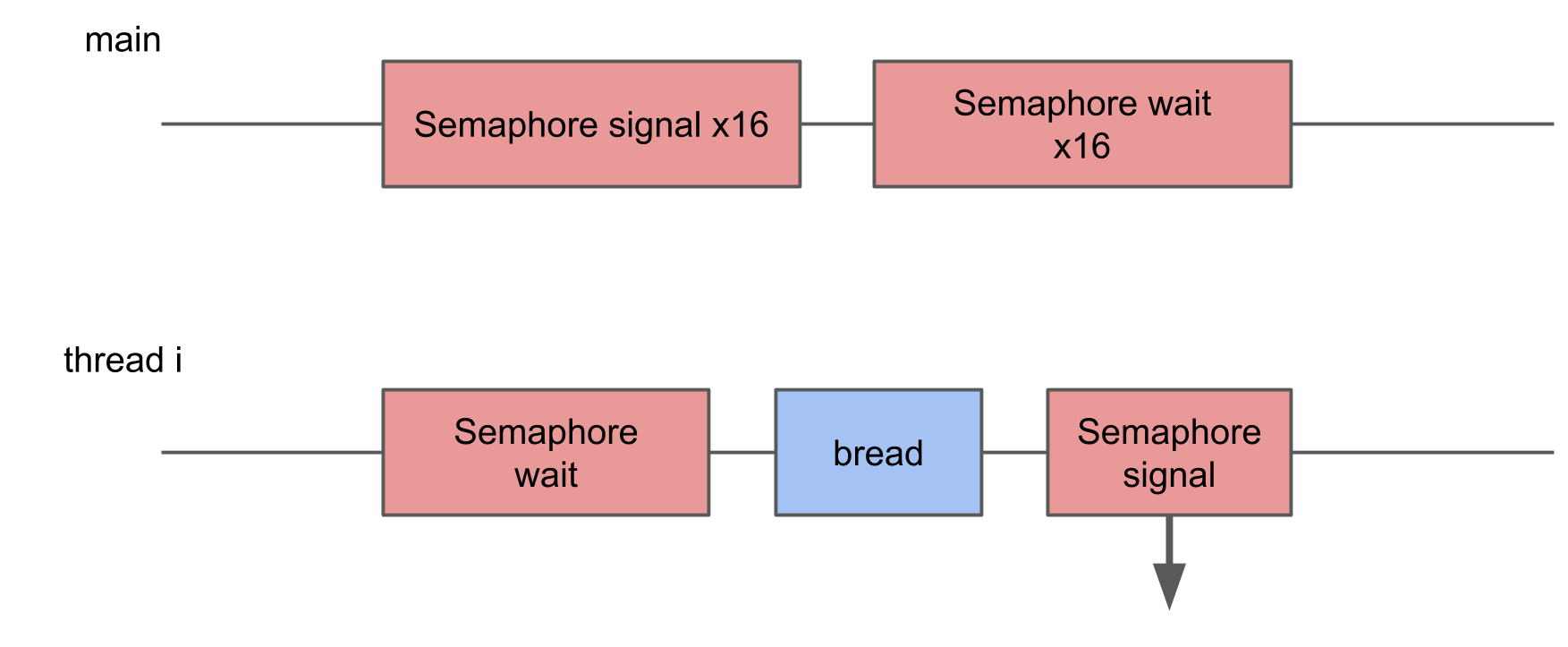
Dalam System Trace Anda dapat melihat bahwa blok tersebar secara acak, beberapa di antaranya jauh lebih lama daripada yang lain. Jika banyak peralihan menyebabkan peningkatan waktu eksekusi operasi, maka waktu eksekusi rata-rata akan meningkat sebagai hasilnya.
Namun, dengan peningkatan jumlah utas, waktu operasi rata-rata tidak meningkat.Secara teori, waktu rata-rata harus dijaga selama beban sesuai dengan kekuatan pemrosesan. Artinya, jumlah tugas sesuai dengan jumlah core.
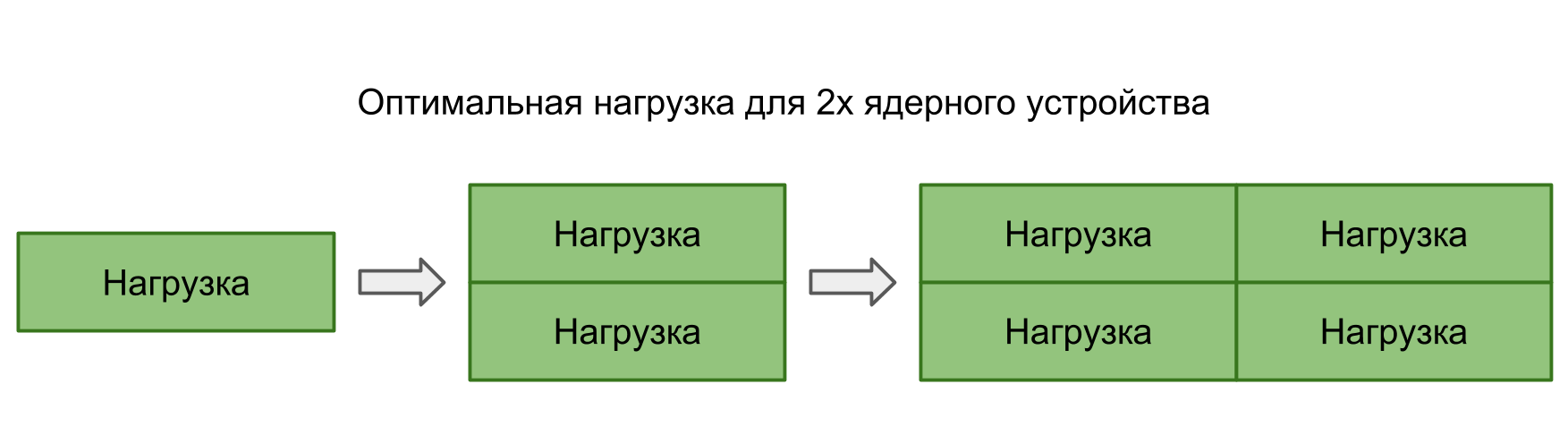
Jika Anda menjalankan banyak tugas secara paralel, maka OS, beralih dari satu tugas ke tugas lain, akan menimbulkan penundaan tambahan. Ini harus tercermin dalam hasilnya.
Dalam praktiknya, tidak hanya aplikasi kita berfungsi pada perangkat, tetapi masih memiliki banyak proses paralel dan sistem. Bahkan satu-satunya utas dalam aplikasi kita akan terpengaruh oleh peralihan, yang mengarah pada gangguan dan penundaan. Oleh karena itu, dalam semua situasi ada penundaan, dan tidak ada perbedaan apakah akan membangun tugas secara seri atau berjalan secara paralel.

Di bawah ini adalah tabel Nomor Latensi kami dengan data tentang arus dan semafor.
| L1 | L2 | Memori | Semaphore |
| Nomor latensi | 1 ns | 7 ns | 100 ns | 25 ns |
| iPhone 5s | 7 ns | 30 ns | 240 ns | 8 μs |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns | 5 μs |
| iPhone X | 2 ns | 12 ns | 146 ns | 3,2 μs |
Biaya File
Kami sudah memiliki memori dan utas - untuk kelengkapannya kami hanya perlu operasi sistem file.
Baca file
Tes pertama adalah
kecepatan membaca - berapa biaya untuk membaca file. Tes terdiri dari dua bagian. Yang pertama, kami
mengukur kecepatan membaca dengan mempertimbangkan pembukaan, pembacaan, dan penutupan file. Yang kedua, kita
mengasumsikan bahwa file itu selalu terbuka : kita menempatkan diri kita di suatu tempat dan membaca sebanyak yang kita inginkan.
Hasilnya dilihat dengan benar dari dua sudut pandang.
Ketika file kecil , ada beberapa waktu minimal untuk membaca data dari file. Hingga satu kilobyte adalah 5,3 mikrodetik - tidak masalah: 1 byte, 2 atau 1 KB - untuk semua 5,3 μs. Oleh karena itu, Anda dapat berbicara tentang kecepatan hanya dalam kasus file besar, ketika waktu tetap sudah dapat diabaikan. Operasi untuk membuka dan menutup file membutuhkan waktu yang hampir sama untuk ukuran file apa pun - dalam kasus 5S, sekitar 50 mikrodetik.
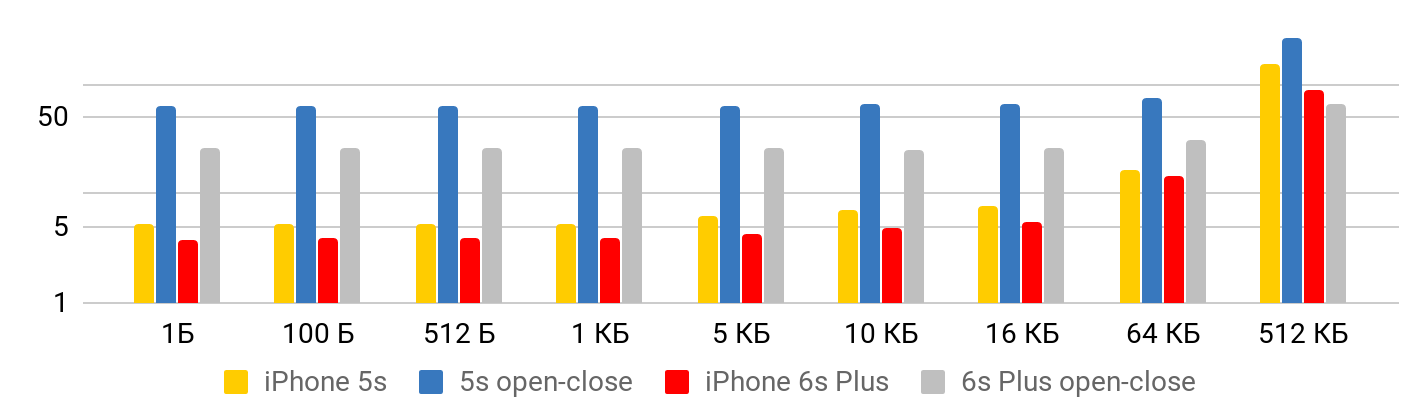
Untuk kecepatan membaca, grafik tersebut diperoleh.
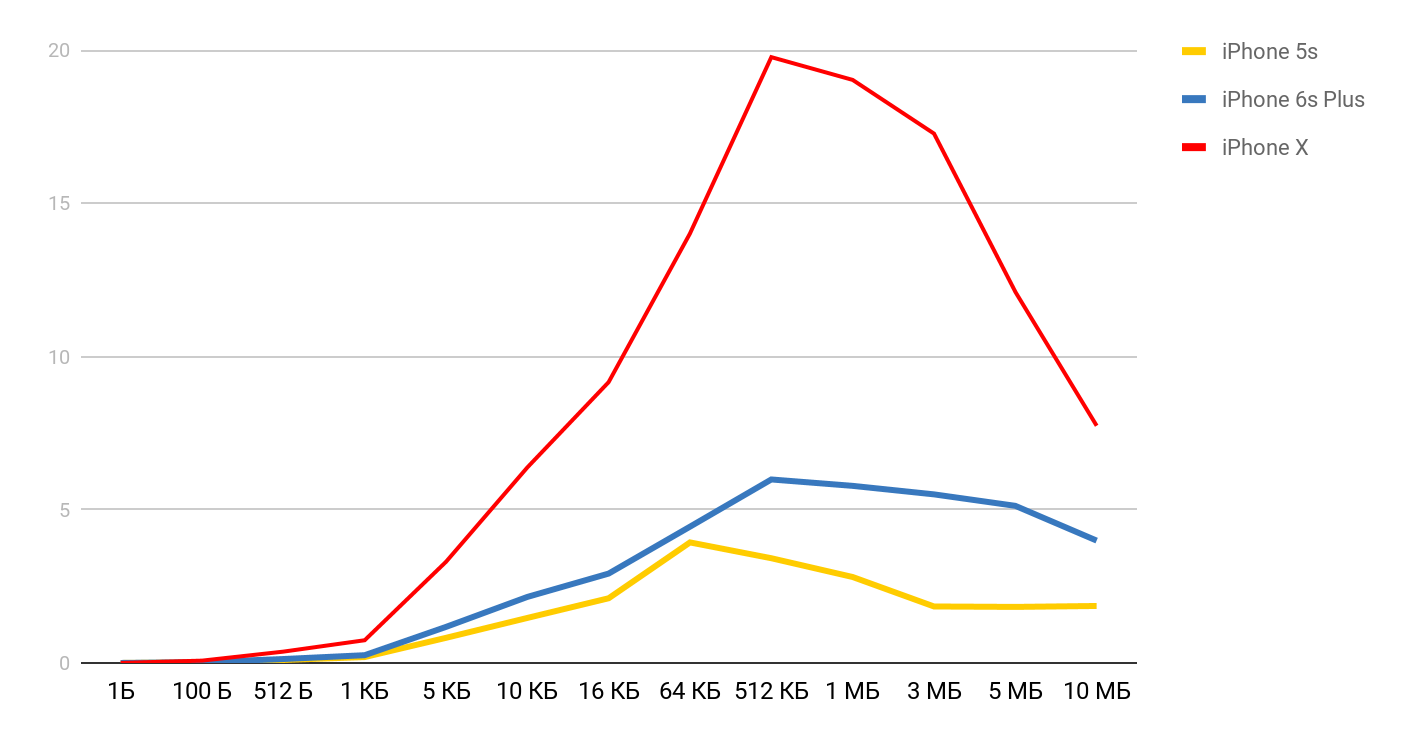
Untuk iPhone X dan file 1 MB, kecepatannya bisa mencapai 20 MB / s. Menariknya, membaca file 1 MB lebih efisien. Dengan ukuran file yang besar, ukuran cache sepertinya terpengaruh. Itulah sebabnya kecepatan turun lebih jauh dan merata di wilayah 10 Mb.
Buat dan hapus file
Tes terdiri dari langkah
membuat file dan menulis data , dan
menghapus file yang dibuat. Hasilnya adalah bertahap: pada ukuran kecil, waktunya stabil - sekitar 7 μs, dan terus berkembang. Skala tersebut adalah logaritmik.
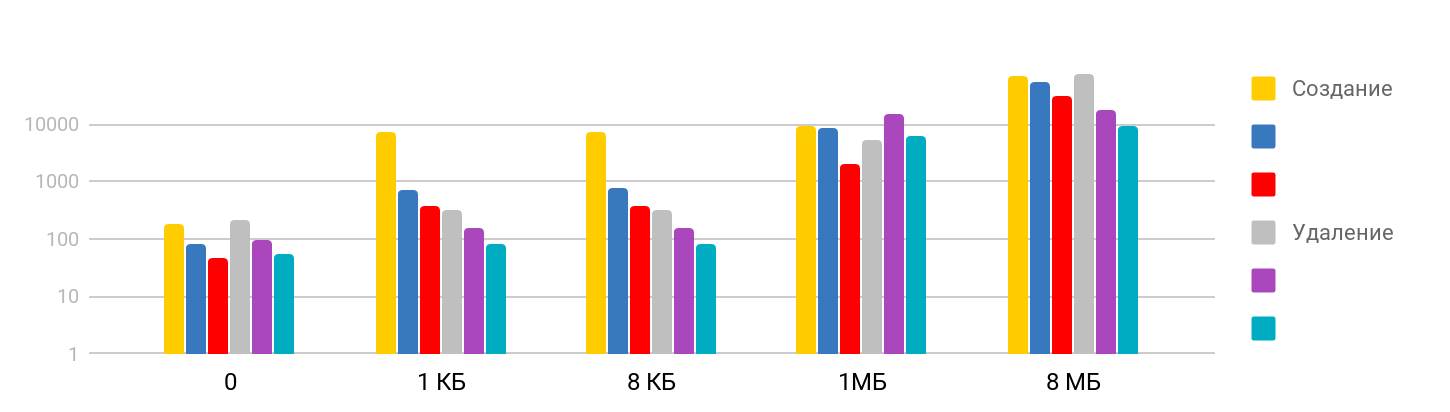
Saya terkejut bahwa waktu yang diperlukan untuk menghapus file besar sepadan dengan waktu yang dibutuhkan untuk membuat, karena saya berasumsi bahwa menghapus adalah operasi cepat. Ternyata tidak, untuk iPhone, menghapus waktu sebanding dengan membuat file. Tabel ringkasan terlihat seperti ini.
| L1 | L2 | Memori | Semaphore | Disk |
| Nomor latensi | 1 ns | 7 ns | 100 ns | 25 ns | 150 μs |
| iPhone 5s | 7 ns | 30 ns | 240 ns | 8 μs | 5 μs |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns | 5 μs | 4 μs |
| iPhone X | 2 ns | 12 ns | 146 ns | 3,2 μs | 1,3 μs |
Kesimpulan
Berdasarkan pengukuran ini, kami sekarang memiliki gagasan tentang berapa banyak waktu yang dibutuhkan operasi iOS dasar: mengakses memori adalah nanodetik, bekerja dengan file adalah mikrodetik, membuat aliran adalah puluhan mikrodetik, dan beralih hanya beberapa mikrodetik.
Untuk mendapatkan hang yang terlihat secara fisik dalam aplikasi, waktu pelaksanaan prosedur harus melebihi 15 milidetik (waktu yang dibutuhkan untuk memperbarui layar pada 60fps). Ini hampir seribu kali lebih besar dari kebanyakan pengukuran yang dilakukan dalam artikel. Pada skala seperti itu, satu milidetik cukup banyak, dan yang kedua sudah "selamanya."
Pengujian menunjukkan bahwa meskipun ada perbedaan besar dalam waktu akses ke memori dan cache, langsung menggunakan rasio ini cukup sulit. Sebelum mengkompilasi semua data Anda di bawah L1, Anda perlu memastikan bahwa dalam kasus Anda itu benar-benar akan memberikan hasil.
Menurut pengujian operasi dengan utas, kami dapat memastikan bahwa membuat dan menghancurkan utas membutuhkan banyak waktu, tetapi melakukan sejumlah besar operasi paralel tidak membawa biaya tambahan.
Kesimpulannya, saya ingin mengingatkan Anda aturan paling penting saat mengerjakan kinerja -
pengukuran pertama dan baru setelah itu optimasi !
Pembicara profil Dmitry Kurkin di
GitHub .
Konversi dan transformasi laporan AppsConf 2018 menjadi artikel sejalan dengan persiapan konferensi 2019 yang semuanya baru . Hanya ada 7 topik dalam daftar laporan yang diterima sejauh ini, tetapi daftar ini akan berkembang setiap saat sehingga konferensi keren untuk para pengembang ponsel berlangsung pada 22-23 April .
Ikuti publikasi, berlangganan saluran youtube dan buletin dan kali ini akan terbang dengan cepat.