Mobil tanpa awak tidak dapat melakukannya tanpa memahami apa yang ada di sekitar dan di mana tepatnya. Pada Desember tahun lalu, pengembang Viktor Otliga
vitonka membuat presentasi tentang deteksi objek 3D di
pohon Data-Christmas . Victor bekerja ke arah kendaraan tak berawak Yandex, dalam kelompok yang menangani situasi lalu lintas (dan juga mengajar di ShAD). Dia menjelaskan bagaimana kita memecahkan masalah mengenali pengguna jalan lain dalam awan titik tiga dimensi, bagaimana masalah ini berbeda dari mengenali objek dalam gambar, dan bagaimana mendapatkan manfaat dari berbagi berbagai jenis sensor.
- Halo semuanya! Nama saya Victor Otliga, saya bekerja di kantor Yandex di Minsk, dan saya mengembangkan kendaraan tanpa awak. Hari ini saya akan berbicara tentang tugas yang agak penting untuk drone - pengenalan objek 3D di sekitar kita.

Untuk mengendarai, Anda perlu memahami apa yang ada di sekitar. Secara singkat saya akan memberi tahu Anda sensor dan sensor mana yang digunakan pada kendaraan tak berawak dan yang kami gunakan. Saya akan memberi tahu Anda apa tugas mendeteksi objek 3D dan bagaimana mengukur kualitas deteksi. Lalu saya akan memberi tahu Anda apa kualitas ini dapat diukur. Dan kemudian saya akan membuat tinjauan singkat tentang algoritma modern yang baik, termasuk yang menjadi dasar solusi kami. Dan pada akhirnya - hasil kecil, perbandingan algoritma ini, termasuk kami.

Seperti itulah bentuk prototipe mobil tak berawak kami saat ini. Taksi semacam itu dapat disewa oleh siapa saja tanpa sopir di kota Innopolis di Rusia, serta di Skolkovo. Dan jika Anda melihat lebih dekat, ada dadu besar di atasnya. Apa yang ada di dalam?

Di dalam satu set sensor sederhana. Ada antena GNSS dan GSM untuk menentukan di mana mobil itu dan untuk berkomunikasi dengan dunia luar. Dimana tanpa sensor klasik seperti kamera. Tapi hari ini kita akan tertarik dengan sitar.


Lidar menghasilkan kira-kira awan titik di sekitarnya, yang memiliki tiga koordinat. Dan Anda harus bekerja dengan mereka. Saya akan memberi tahu Anda bagaimana, menggunakan gambar kamera dan awan lidar, untuk mengenali objek apa pun.
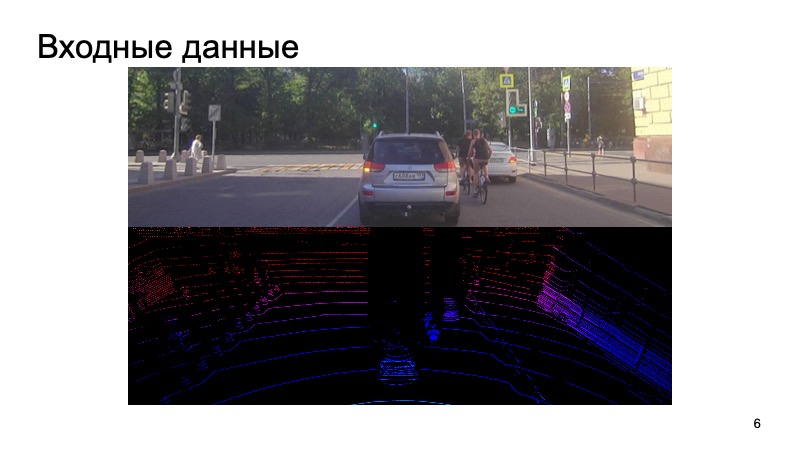
Apa tantangannya? Gambar dari kamera memasuki input, kamera disinkronkan dengan LIDAR. Akan aneh jika menggunakan gambar dari kamera sedetik yang lalu, mengambil awan lidar dari momen yang sama sekali berbeda dan mencoba mengenali objek di dalamnya.

Kami entah bagaimana menyinkronkan kamera dan penutup, ini adalah tugas sulit yang terpisah, tetapi kami berhasil mengatasinya. Data tersebut memasukkan input, dan pada akhirnya kami ingin mendapatkan kotak, kotak yang membatasi objek: pejalan kaki, pengendara sepeda, mobil dan pengguna jalan lainnya dan tidak hanya.
Tugas telah ditetapkan. Bagaimana kita akan mengevaluasinya?

Masalah pengenalan 2D objek dalam suatu gambar telah banyak dipelajari.
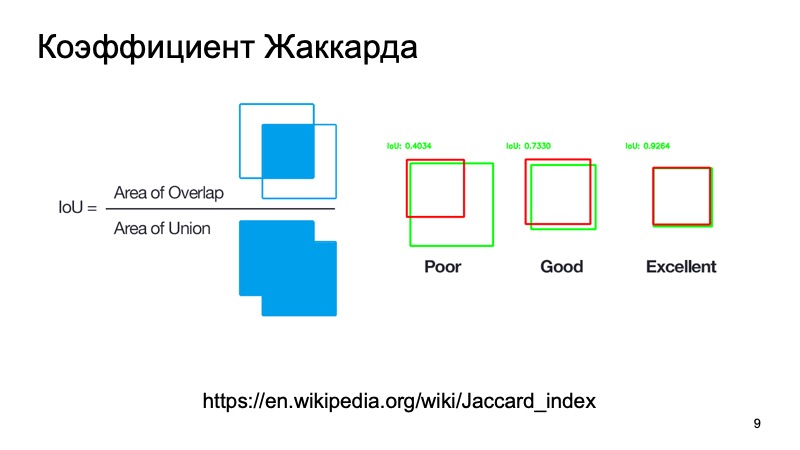
Anda dapat menggunakan metrik standar atau analognya. Ada koefisien Jacquard atau persimpangan atas penyatuan, koefisien yang luar biasa yang menunjukkan seberapa baik kami mendeteksi suatu objek. Kita dapat mengambil kotak di mana, seperti yang kita asumsikan, objek berada, dan kotak di mana ia sebenarnya berada. Hitung metrik ini. Ada ambang standar - katakanlah untuk mobil mereka sering mengambil ambang 0,7. Jika nilai ini lebih besar dari 0,7, kami percaya bahwa kami telah berhasil mendeteksi objek, bahwa objek itu ada di sana. Kami hebat, kami bisa melangkah lebih jauh.
Selain itu, untuk mendeteksi suatu objek dan memahami bahwa itu ada di suatu tempat, kami ingin mengambil semacam kepercayaan bahwa kami benar-benar melihat objek di sana, dan mengukurnya juga. Anda dapat mengukur sederhana, pertimbangkan akurasi rata-rata. Anda dapat mengambil kurva recall presisi dan area di bawahnya dan berkata: semakin besar, semakin baik.
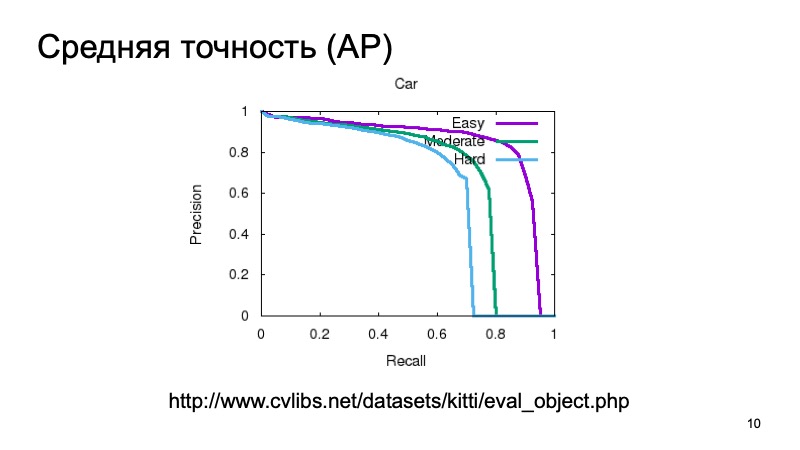
Biasanya, untuk mengukur kualitas deteksi 3D, mereka mengambil dataset dan membaginya menjadi beberapa bagian, karena objek bisa dekat atau lebih jauh, mereka dapat sebagian dikaburkan oleh sesuatu yang lain. Oleh karena itu, sampel validasi sering dibagi menjadi tiga bagian. Objek yang mudah dideteksi, dari kompleksitas sedang dan kompleks, jauh atau yang sangat dikaburkan. Dan mereka mengukur secara terpisah dalam tiga bagian. Dan dalam hasil perbandingan, kami juga akan mengambil partisi seperti itu.
Anda dapat mengukur kualitas seperti dalam 3D, analog persimpangan dengan gabungan, tetapi bukan rasio area, tetapi, misalnya, volume. Tetapi sebuah mobil tak berawak, sebagai suatu peraturan, tidak terlalu peduli dengan apa yang terjadi di koordinat Z. Kita dapat melihat dari atas dan mengambil semacam metrik, seolah-olah kita menonton semuanya dalam 2D. Manusia dinavigasi kurang lebih dalam 2D, dan kendaraan tak berawak adalah sama. Seberapa tinggi kotak itu tidak terlalu penting.

Apa yang diukur?

Mungkin setiap orang yang setidaknya menghadapi tugas mendeteksi dalam 3D oleh cloud Lidar mendengar tentang dataset seperti KITTI.

Di beberapa kota di Jerman, sebuah dataset dicatat, sebuah mobil yang dilengkapi dengan sensor pergi, ia memiliki sensor GPS, dan kamera, dan penutup. Kemudian ditandai sekitar 8000 adegan, dan dibagi menjadi dua bagian. Satu bagian adalah pelatihan, di mana setiap orang dapat berlatih, dan yang kedua adalah validasi, untuk mengukur hasil. Sampel validasi KITTI dianggap sebagai ukuran kualitas. Pertama, ada papan pimpinan di situs dataset KITTI, Anda dapat mengirim keputusan Anda di sana, hasil Anda pada dataset validasi, dan membandingkannya dengan keputusan pemain pasar atau peneliti lain. Tetapi juga set data ini tersedia untuk umum, Anda dapat mengunduh, tidak memberi tahu siapa pun, memeriksa sendiri, membandingkannya dengan pesaing, tetapi jangan mengunggah secara publik.

Kumpulan data eksternal baik, Anda tidak perlu menghabiskan waktu dan sumber daya untuk menggunakannya, tetapi sebagai suatu peraturan, mobil yang bepergian ke Jerman dapat dilengkapi dengan sensor yang sama sekali berbeda. Dan selalu baik untuk memiliki dataset internal Anda sendiri. Selain itu, lebih sulit untuk memperluas dataset eksternal dengan mengorbankan yang lain, tetapi lebih mudah untuk mengelola sendiri. Karena itu, kami menggunakan layanan Yandex.Tolok yang luar biasa.

Kami menyelesaikan sistem tugas khusus kami. Kepada pengguna yang ingin membantu markup dan mendapatkan hadiah untuk ini, kami memberikan gambar dari kamera, memberikan awan lidar yang dapat Anda putar, perbesar, perkecil, dan minta dia untuk meletakkan kotak yang membatasi kotak kami sehingga mobil atau pejalan kaki bisa masuk ke dalamnya , atau yang lainnya. Dengan demikian, kami mengumpulkan pengambilan sampel internal untuk penggunaan pribadi.
Misalkan kita telah memutuskan tugas mana yang akan kita selesaikan, bagaimana kita akan menganggap bahwa kita melakukan itu baik atau buruk. Kami mengambil suatu tempat data.
Apa saja algoritmanya? Mari kita mulai dengan 2D. Tugas deteksi 2D sangat terkenal dan dipelajari.
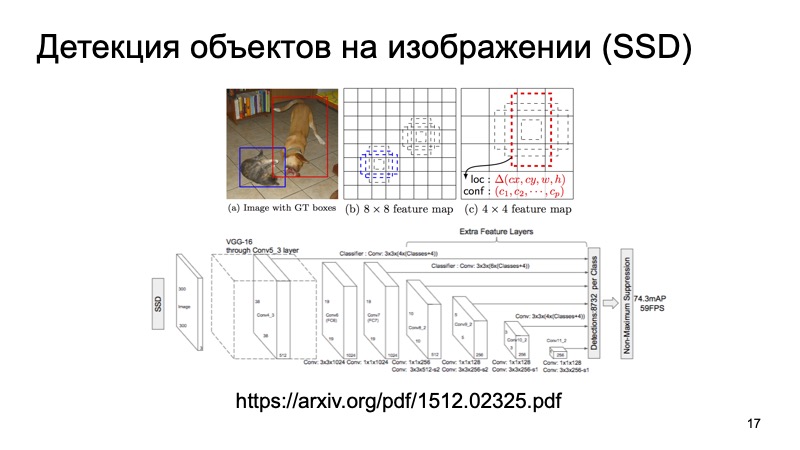
Tentunya, banyak orang tahu tentang algoritma SSD, yang merupakan salah satu metode canggih untuk mendeteksi objek 2D, dan pada prinsipnya, kita dapat mengasumsikan bahwa dalam beberapa hal masalah dalam mendeteksi objek dalam gambar sudah diselesaikan dengan cukup baik. Jika ada, kita dapat menggunakan hasil ini sebagai semacam informasi tambahan.
Tetapi awan lidar kami memiliki karakteristik sendiri yang sangat membedakannya dari gambar. Pertama, sangat jarang. Jika gambar adalah struktur padat, pikselnya dekat, semuanya padat, maka awannya sangat tipis, tidak ada begitu banyak titik, dan tidak memiliki struktur biasa. Secara fisik, ada lebih banyak poin di dekat sana daripada di kejauhan, dan semakin jauh Anda pergi, semakin sedikit poin, semakin sedikit akurasi, semakin sulit menentukan sesuatu.
Nah, poinnya, pada prinsipnya, dari awan datang dalam urutan yang tidak bisa dipahami. Tidak ada yang menjamin bahwa satu poin akan selalu lebih awal dari yang lain. Mereka datang dalam urutan yang relatif acak. Entah bagaimana Anda bisa setuju untuk mengurutkan atau menyusun ulang mereka di muka, dan hanya kemudian mengirimkan model ke input, tetapi ini akan sangat merepotkan, Anda perlu meluangkan waktu untuk mengubahnya, dan sebagainya.
Kami ingin datang dengan sistem yang akan berbeda dengan masalah kami, akan menyelesaikan semua masalah ini. Untungnya, tahun lalu CVPR menghadirkan sistem seperti itu. Ada arsitektur seperti itu - PointNet. Bagaimana cara kerjanya?

Awan n poin tiba di pintu masuk, masing-masing dengan tiga koordinat. Kemudian setiap titik entah bagaimana distandarisasi oleh transformasi kecil khusus. Lebih lanjut ia didorong melalui jaringan yang terhubung penuh untuk memperkaya titik-titik ini dengan tanda-tanda. Kemudian transformasi terjadi, dan pada akhirnya diperkaya juga. Pada titik tertentu, n poin diperoleh, tetapi masing-masing memiliki sekitar 1024 fitur, mereka entah bagaimana standar. Namun sejauh ini kami belum memecahkan masalah tentang invarian shift, belokan, dan sebagainya. Di sini diusulkan untuk melakukan max-pooling, mengambil maksimum di antara titik-titik di setiap saluran dan mendapatkan beberapa vektor 1024 tanda, yang akan menjadi beberapa deskriptor cloud kami, yang akan berisi informasi tentang seluruh cloud. Dan kemudian dengan deskriptor ini Anda dapat melakukan banyak hal berbeda.
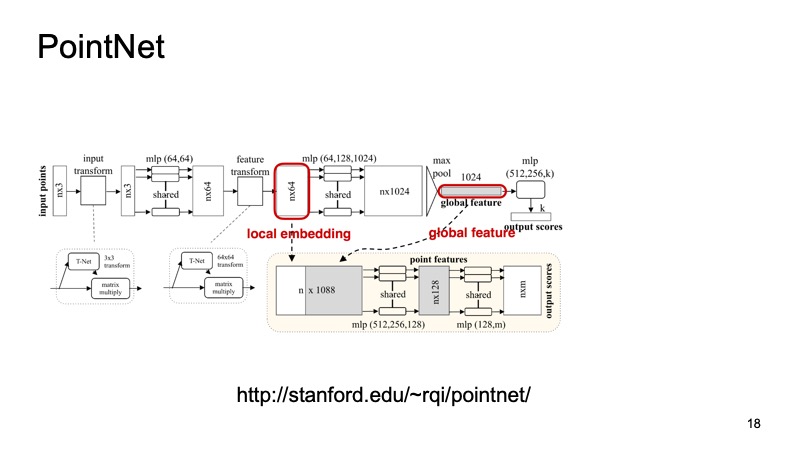
Misalnya, Anda dapat menempelkannya ke deskriptor poin individual dan menyelesaikan masalah segmentasi, untuk setiap poin untuk menentukan objek mana yang menjadi miliknya. Itu hanya jalan atau orang atau mobil. Dan inilah hasil dari artikel tersebut.

Anda mungkin memperhatikan bahwa algoritma ini melakukan pekerjaan yang sangat baik. Secara khusus, saya sangat menyukai meja kecil tempat beberapa data tentang meja dibuang, dan dia tetap menentukan di mana kakinya berada dan di mana meja itu berada. Dan algoritma ini, khususnya, dapat digunakan sebagai batu bata untuk membangun sistem lebih lanjut.
Salah satu pendekatan yang menggunakan ini adalah pendekatan Frustum PointNets atau pendekatan piramida terpotong. Idenya kira-kira seperti ini: mari kita kenali objek dalam 2D, kita pandai melakukan ini.
Kemudian, mengetahui cara kerja kamera, kita bisa memperkirakan di area mana objek yang menarik bagi kita, mesin, bisa berbohong. Untuk memproyeksikan, potong hanya area ini, dan sudah di atasnya menyelesaikan masalah menemukan objek yang menarik, misalnya, mesin. Ini jauh lebih mudah daripada mencari sejumlah mobil di awan. Mencari satu mobil persis di awan yang sama tampaknya jauh lebih jelas dan lebih efisien.
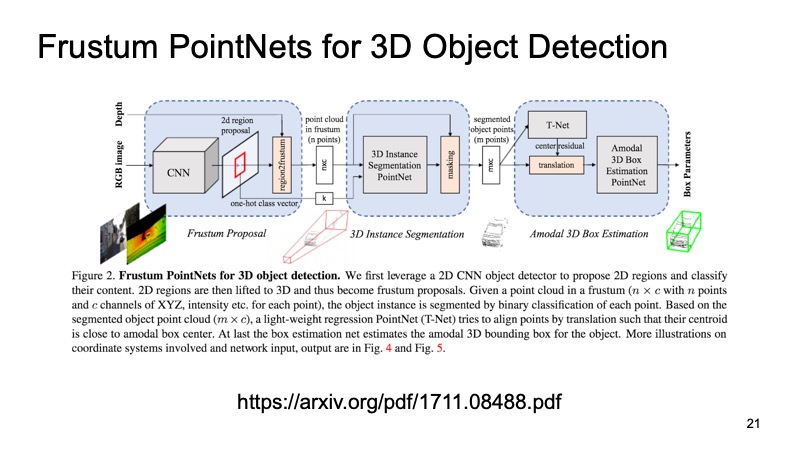
Arsitekturnya terlihat seperti ini. Pertama, entah bagaimana kami memilih daerah yang menarik bagi kami, di setiap wilayah kami melakukan segmentasi, dan kemudian kami memecahkan masalah menemukan kotak pembatas yang membatasi objek yang menarik bagi kami.

Pendekatannya telah membuktikan dirinya. Dalam gambar Anda dapat melihat bahwa itu bekerja dengan sangat baik, tetapi juga memiliki kekurangan. Pendekatannya dua tingkat, karena ini bisa lambat. Pertama-tama kita perlu menerapkan jaringan dan mengenali objek 2D, kemudian memotong, dan kemudian memecahkan masalah segmentasi dan alokasi kotak pembatas pada sepotong awan, sehingga ia bisa bekerja sedikit lambat.
Pendekatan lain. Mengapa kita tidak mengubah awan kita menjadi semacam struktur yang terlihat seperti gambar? Idenya adalah ini: mari kita lihat dari atas dan cicipi awan Lidar kita. Kami mendapat ruang kubus.
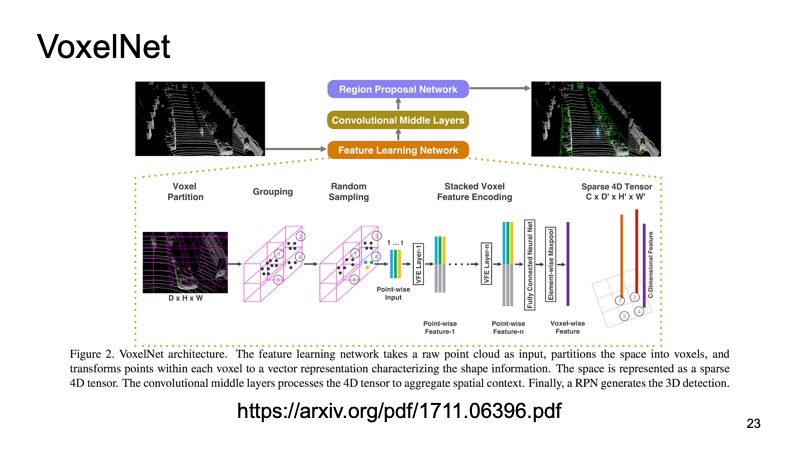
Di dalam setiap kubus kami mendapat beberapa poin. Kita dapat menghitung beberapa fitur di dalamnya, tetapi kita bisa menggunakan PointNet, yang untuk setiap bagian ruang akan menghitung beberapa jenis deskriptor. Kami akan mendapatkan voxel, masing-masing voxel memiliki deskripsi karakteristik, dan itu akan lebih mirip struktur padat, seperti gambar. Kita sudah dapat membuat arsitektur yang berbeda, misalnya, arsitektur mirip SSD untuk mendeteksi objek.
Pendekatan terakhir, yang merupakan salah satu pendekatan pertama untuk menggabungkan data dari berbagai sensor. Adalah dosa jika hanya menggunakan data lidar ketika kita juga memiliki data kamera. Salah satu pendekatan ini disebut Multi-View 3D Object Detection Network. Idenya adalah ini: memberi makan tiga saluran data input ke input jaringan besar.
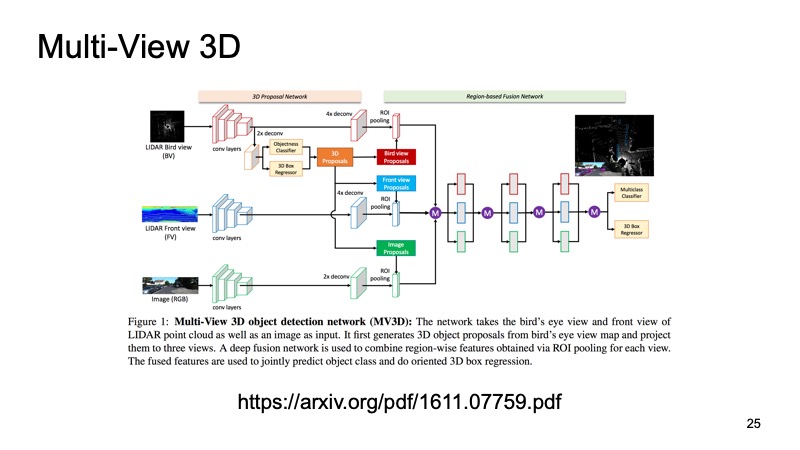
Ini adalah gambar dari kamera dan, dalam dua versi, awan lidar: dari atas, dengan pandangan mata burung, dan semacam tampilan depan, apa yang kita lihat di depan kita. Kami mengirimkan ini ke input neuron, dan itu akan mengkonfigurasi segala sesuatu di dalam dirinya sendiri, akan memberi kita hasil akhir - objek.
Saya ingin membandingkan model ini. Pada dataset KITTI, pada drive validasi, kualitas dievaluasi sebagai persentase dalam ketepatan rata-rata.
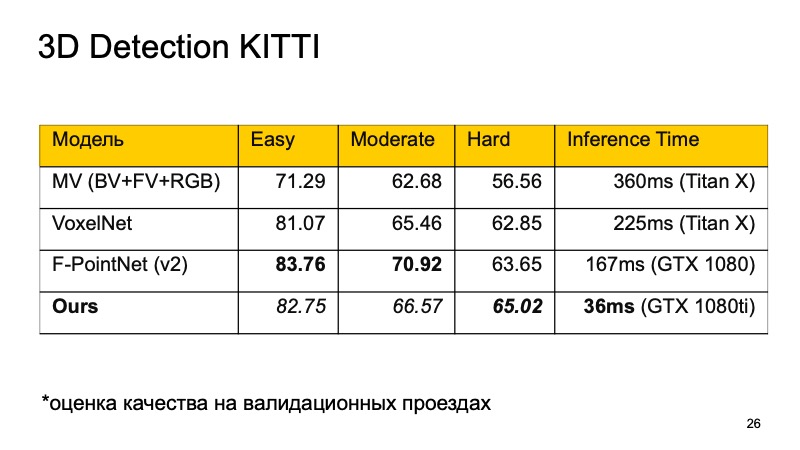
Anda mungkin memperhatikan bahwa F-PointNet bekerja dengan sangat baik dan cukup cepat, mengalahkan semua orang di area yang berbeda - setidaknya menurut penulis.
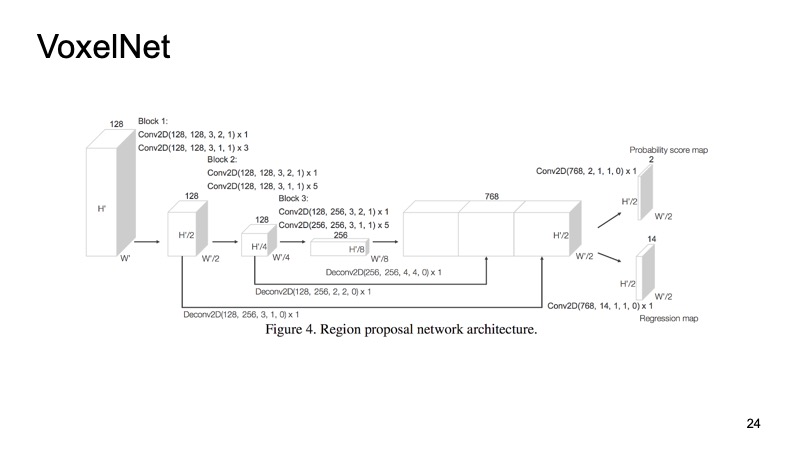
Pendekatan kami didasarkan pada kurang lebih semua ide yang telah saya daftarkan. Jika Anda membandingkan, Anda mendapatkan tentang gambar berikut. Jika kita tidak menempati tempat pertama, maka setidaknya yang kedua. Terlebih lagi, pada objek-objek yang sulit dideteksi, kita pecah menjadi pemimpin. Dan yang paling penting, pendekatan kami cukup cepat. Ini berarti sudah cukup baik untuk sistem waktu nyata, dan sangat penting bagi kendaraan tak berawak untuk memantau apa yang terjadi di jalan dan menyoroti semua objek ini.

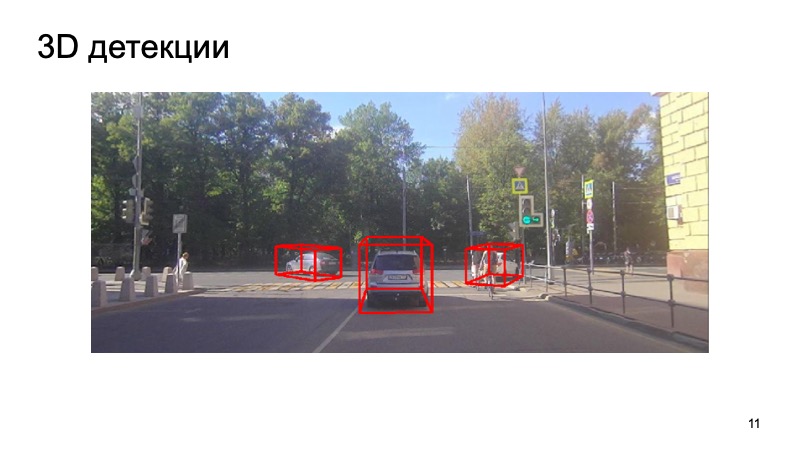
Kesimpulannya - contoh dari detektor kami:
Dapat dilihat bahwa situasinya rumit: beberapa objek ditutup, dan beberapa tidak terlihat oleh kamera. Pejalan kaki, pengendara sepeda. Tapi detektor itu berupaya dengan cukup baik. Terima kasih