Ini adalah artikel baru dari
diskusi tugas dari wawancara di Google . Ketika saya bekerja di sana, saya menawarkan para kandidat tugas semacam itu. Lalu ada kebocoran, dan mereka dilarang. Tetapi koin memiliki sisi lain: sekarang saya dapat dengan bebas menjelaskan solusinya.
Berita bagus untuk memulai: Saya keluar dari Google! Saya senang memberi tahu Anda bahwa saya sekarang bekerja sebagai manajer teknis Reddit di New York! Namun seri artikel ini masih akan dilanjutkan.
Penafian: Meskipun mewawancarai kandidat adalah salah satu tugas profesional saya, di blog ini saya berbagi pengamatan pribadi, cerita, dan pendapat pribadi. Harap jangan menganggap ini sebagai pernyataan resmi dari Google, Alfabet, Reddit, orang atau organisasi lain.Pertanyaan
Setelah
dua artikel terakhir tentang kemajuan kuda dalam memanggil nomor telepon, saya menerima kritik bahwa ini bukan masalah yang realistis. Mungkin berguna untuk mempelajari keterampilan berpikir kandidat, tetapi harus saya akui: tugasnya sedikit tidak realistis. Meskipun saya memiliki beberapa pemikiran tentang korelasi antara pertanyaan wawancara dan kenyataan, saya akan menyerahkannya kepada saya untuk saat ini. Pastikan, saya membaca komentar di mana-mana dan saya punya sesuatu untuk dijawab, tetapi tidak sekarang.
Tetapi ketika tugas mengoper kuda itu dilarang beberapa tahun yang lalu, saya mengambil hati kritik dan mencoba menggantinya dengan pertanyaan yang sedikit lebih relevan dengan ruang lingkup Google. Dan apa yang bisa lebih relevan untuk Google daripada mekanisme permintaan pencarian? Jadi saya menemukan pertanyaan ini dan menggunakannya untuk waktu yang lama sebelum juga dipublikasikan dan dilarang. Seperti sebelumnya, saya akan merumuskan pertanyaan, menyelami penjelasannya, dan kemudian saya akan mengatakan bagaimana saya menggunakannya dalam wawancara dan mengapa saya menyukainya.
Jadi pertanyaannya adalah.
Bayangkan Anda mengelola mesin pencari populer dan melihat dua permintaan di log: katakanlah, "peringkat persetujuan Obama" dan "tingkat popularitas Obama" (jika saya ingat dengan benar, ini adalah contoh nyata dari basis pertanyaan, meskipun sekarang sedikit ketinggalan jaman ...) . Kami melihat kueri yang berbeda, tetapi semua orang akan setuju: pengguna pada dasarnya mencari informasi yang sama, jadi kueri harus dianggap setara ketika menghitung jumlah kueri, menampilkan hasil, dll.
Bagaimana Anda menentukan apakah dua kueri itu sama?Mari memformalkan tugas. Misalkan ada dua set pasangan string: pasangan sinonim dan pasangan kueri.
Secara khusus, berikut adalah contoh input untuk menggambarkan:
SYNONYMS = [ ('rate', 'ratings'), ('approval', 'popularity'), ] QUERIES = [ ('obama approval rate', 'obama popularity ratings'), ('obama approval rates', 'obama popularity ratings'), ('obama approval rate', 'popularity ratings obama') ]
Hal ini diperlukan untuk menghasilkan daftar nilai-nilai logis: apakah permintaan di setiap pasangan identik.
Semua pertanyaan baru ...
Sepintas, ini adalah tugas sederhana. Tetapi semakin lama Anda berpikir, semakin sulit jadinya. Bisakah sebuah kata memiliki beberapa sinonim? Apakah urutan kata itu penting? Apakah hubungan sinonim transitif, yaitu, jika A identik dengan B dan B identik dengan C, apakah A sinonim untuk C? Dapatkah sinonim menjangkau beberapa kata, bagaimana "AS" menjadi sinonim untuk frasa "Amerika Serikat" atau "Amerika Serikat"?
Ambiguitas semacam itu segera memungkinkan untuk membuktikan diri kepada kandidat yang baik. Hal pertama yang dia lakukan adalah mencari ambiguitas seperti itu dan mencoba menyelesaikannya. Semua orang melakukan ini dengan cara yang berbeda: beberapa mendekati papan tulis dan mencoba menyelesaikan kasus-kasus tertentu secara manual, sementara yang lain melihat pertanyaan dan segera melihat celahnya. Bagaimanapun, mengidentifikasi masalah-masalah ini pada tahap awal sangat penting.
Fase "memahami masalah" sangat penting. Saya suka menyebut rekayasa perangkat lunak disiplin fraktal. Seperti halnya fraktal, aproksimasi mengungkapkan kompleksitas tambahan. Anda pikir Anda memahami masalahnya, kemudian melihat lebih dekat - dan Anda melihat bahwa Anda melewatkan beberapa kehalusan atau detail implementasi yang dapat ditingkatkan. Atau pendekatan yang berbeda untuk masalah tersebut.
 Set mandelbrotKaliber seorang insinyur sangat ditentukan oleh seberapa dalam dia bisa memahami masalahnya.
Set mandelbrotKaliber seorang insinyur sangat ditentukan oleh seberapa dalam dia bisa memahami masalahnya. Mengubah pernyataan masalah yang tidak jelas menjadi serangkaian persyaratan yang terperinci adalah langkah pertama dalam proses ini, dan pernyataan yang disengaja memungkinkan Anda untuk mengevaluasi seberapa baik kandidat tersebut cocok dengan situasi baru.
Kami mengesampingkan pertanyaan sepele, seperti "Apakah huruf besar penting?" Itu tidak mempengaruhi algoritma utama. Saya selalu memberikan jawaban paling sederhana untuk pertanyaan-pertanyaan ini (dalam hal ini, "Asumsikan bahwa semua huruf sudah diproses sebelumnya dan dikonversi ke huruf kecil")Bagian 1. (Tidak cukup) kasus sederhana
Jika kandidat mengajukan pertanyaan, saya selalu memulai dengan kasus paling sederhana: sebuah kata dapat memiliki beberapa sinonim, masalah urutan kata, sinonim tidak transitif. Ini memberikan fungsi mesin pencari sangat terbatas, tetapi memiliki cukup kehalusan untuk wawancara yang menarik.
Ikhtisar tingkat tinggi adalah sebagai berikut: pisahkan kueri menjadi kata-kata (misalnya, berdasarkan spasi) dan bandingkan pasangan yang sesuai untuk mencari kata dan sinonim yang identik. Secara visual, tampilannya seperti ini:
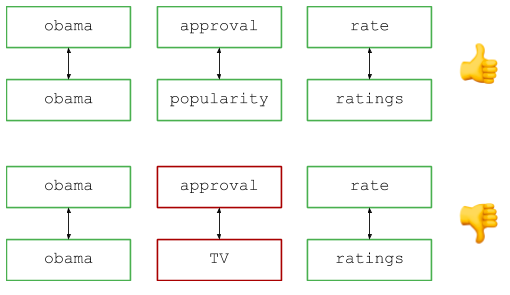
Dalam kode:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif words_are_synonyms(w1, w2): continue result = False break output.append(result) return output
Mudah kan? Secara algoritma, ini cukup sederhana. Tidak ada pemrograman dinamis, rekursi, struktur kompleks, dll. Manipulasi sederhana dari perpustakaan standar dan algoritma yang bekerja dalam waktu linier, bukan?
Tapi ada lebih banyak nuansa daripada yang terlihat pada pandangan pertama. Tentu saja, komponen yang paling sulit adalah perbandingan sinonim. Meskipun komponennya mudah dipahami dan dijelaskan, ada banyak cara untuk membuat kesalahan. Saya akan memberi tahu Anda tentang kesalahan paling umum.
Untuk kejelasan: tidak ada kesalahan akan mendiskualifikasi kandidat; jika itu, saya hanya menunjukkan kesalahan dalam implementasi, itu diperbaiki, dan kami melanjutkan. Namun, wawancara adalah, pertama-tama, perjuangan melawan waktu. Anda akan membuat, memperhatikan, dan memperbaiki kesalahan, tetapi butuh waktu yang dapat dihabiskan untuk yang lain, misalnya, untuk membuat solusi yang lebih optimal. Hampir semua orang membuat kesalahan, ini normal, tetapi kandidat yang membuatnya lebih kecil menunjukkan hasil yang lebih baik hanya karena mereka menghabiskan lebih sedikit waktu untuk memperbaikinya.
Itu sebabnya saya suka masalah ini. Jika langkah seorang ksatria membutuhkan wawasan ke dalam pemahaman algoritma, dan kemudian (saya harap) implementasi sederhana, maka solusinya di sini adalah banyak langkah ke arah yang benar. Setiap langkah mewakili rintangan kecil yang melaluinya sang kandidat dapat dengan anggun melompati atau tersandung dan bangkit. Berkat pengalaman dan intuisi, kandidat yang baik menghindari jebakan kecil ini - dan mendapatkan solusi yang lebih rinci dan benar, sementara yang lebih lemah menghabiskan waktu dan energi untuk kesalahan dan biasanya tetap dengan kode yang salah.
Pada setiap wawancara, saya melihat kombinasi keberhasilan dan kegagalan yang berbeda, ini adalah kesalahan yang paling umum.
Pembunuh Kinerja Acak
Pertama, beberapa kandidat telah menerapkan deteksi sinonim hanya dengan menelusuri daftar sinonim:
... elif (w1, w2) in synonym_words: continue ...
Sekilas, ini masuk akal. Tetapi setelah diperiksa lebih dekat, idenya sangat, sangat buruk. Bagi Anda yang tidak mengenal Python, kata kunci in adalah gula sintaksis untuk metode
berisi dan berfungsi pada semua kontainer Python standar. Ini adalah masalah karena
synonym_words adalah daftar yang mengimplementasikan kata kunci in menggunakan pencarian linear. Pengguna Python sangat sensitif terhadap kesalahan ini karena bahasa menyembunyikan tipe, tetapi pengguna C ++ dan Java juga terkadang membuat kesalahan serupa.
Sepanjang karier saya, saya hanya menulis beberapa kali dengan kode pencarian linier, dan masing-masing dalam daftar tidak lebih dari dua lusin elemen. Dan bahkan dalam kasus ini, ia menulis komentar panjang yang menjelaskan mengapa ia memilih pendekatan yang tampaknya kurang optimal. Saya menduga bahwa beberapa kandidat menggunakannya hanya karena mereka tidak tahu bagaimana kata kunci in bekerja dalam daftar di pustaka standar Python. Ini adalah kesalahan sederhana, tidak fatal, tetapi kenalan yang buruk dengan bahasa favorit Anda tidak terlalu baik.
Dalam praktiknya, kesalahan ini mudah dihindari. Pertama, jangan pernah lupa tipe objek Anda, bahkan jika Anda menggunakan bahasa yang tidak diketik seperti Python! Kedua, ingatlah bahwa ketika Anda menggunakan kata kunci
in dalam daftar, pencarian linear dimulai. Jika tidak ada jaminan bahwa daftar ini akan selalu sangat kecil, itu akan mematikan kinerja.
Agar kandidat sadar, biasanya cukup untuk mengingatkannya bahwa struktur input adalah daftar. Sangat penting untuk mengamati bagaimana kandidat merespons permintaan tersebut. Kandidat terbaik segera mencoba untuk entah bagaimana pra-proses sinonim, yang merupakan awal yang baik. Namun, pendekatan ini bukannya tanpa perangkap ...
Gunakan struktur data yang benar
Dari kode di atas, segera jelas bahwa untuk mengimplementasikan algoritma ini dalam waktu linier, perlu untuk segera menemukan sinonim. Dan ketika kita berbicara tentang pencarian cepat, selalu ada peta atau array hash.
Bagi saya tidak masalah apakah kandidat memilih peta atau array hash. Yang penting adalah bahwa ia akan meletakkannya di sana (omong-omong, jangan pernah menggunakan dict / hashmap dengan transisi ke
True atau
False ). Kebanyakan kandidat memilih semacam dict / hashmap. Kesalahan paling umum adalah asumsi bawah sadar bahwa setiap kata tidak memiliki lebih dari satu sinonim:
... synonyms = {} for w1, w2 in synonym_words: synonyms[w1] = w2 ... elif synonyms[w1] == w2: continue
Saya tidak menghukum kandidat karena kesalahan ini. Tugas ini dirumuskan secara khusus agar tidak berfokus pada kenyataan bahwa kata-kata dapat memiliki beberapa sinonim, dan beberapa kandidat tidak menghadapi situasi seperti itu. Paling cepat memperbaiki bug ketika saya menunjuk ke sana. Kandidat yang baik memperhatikannya pada tahap awal dan biasanya tidak menghabiskan banyak waktu.
Masalah yang sedikit lebih serius adalah kurangnya kesadaran bahwa hubungan sinonim menyebar ke dua arah. Perhatikan bahwa dalam kode di atas ini diperhitungkan. Tetapi ada implementasi dengan kesalahan:
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) synonyms[w2].append(w1) ... elif w2 in synonyms.get(w1, tuple()): continue
Mengapa dua menyisipkan dan menggunakan memori dua kali lebih banyak?
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) ... elif (w2 in synonyms.get(w1, tuple()) or w1 in synonyms.get(w2, tuple())): continue
Kesimpulan:
selalu pikirkan bagaimana mengoptimalkan kode ! Dalam retrospeksi, permutasi fungsi pencarian adalah optimasi yang jelas, jika tidak kita dapat menyimpulkan bahwa kandidat tidak memikirkan opsi optimasi. Sekali lagi, saya senang memberikan petunjuk, tetapi lebih baik menebaknya sendiri.
Sortir?
Beberapa kandidat cerdas ingin mengurutkan daftar sinonim dan kemudian menggunakan pencarian biner. Sebenarnya, pendekatan ini memiliki keuntungan penting: tidak memerlukan ruang tambahan, kecuali untuk daftar sinonim (asalkan daftar tersebut boleh diubah).
Sayangnya, kompleksitas waktu mengganggu: menyortir daftar sinonim membutuhkan waktu
Nlog(N) , dan kemudian
log(N) lain
log(N) untuk mencari setiap pasangan sinonim, sedangkan solusi preprocessing yang dijelaskan terjadi dalam waktu linier dan kemudian konstan. Selain itu, saya secara kategoris menentang memaksa kandidat untuk menerapkan pengurutan dan pencarian biner di papan tulis, karena: 1) algoritma pengurutan dikenal, oleh karena itu, sejauh yang saya tahu, kandidat dapat mengeluarkannya tanpa berpikir; 2) algoritma ini sangat sulit untuk diimplementasikan dengan benar, dan seringkali bahkan kandidat terbaik akan membuat kesalahan yang tidak mengatakan apa-apa tentang keterampilan pemrograman mereka.
Setiap kali seorang kandidat mengusulkan solusi seperti itu, saya tertarik pada waktu pelaksanaan program dan bertanya apakah ada opsi yang lebih baik. Sebagai informasi: jika pewawancara bertanya apakah ada opsi yang lebih baik, jawabannya hampir selalu ya. Jika saya pernah mengajukan pertanyaan ini kepada Anda, jawabannya pasti akan seperti itu.
Akhirnya solusi
Pada akhirnya, kandidat menawarkan sesuatu yang benar dan cukup optimal. Berikut ini adalah implementasi dalam waktu linear dan ruang linear untuk kondisi yang diberikan:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].add(w2) output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif ((w1 in synonyms and w2 in synonyms[w1]) or (w2 in synonyms and w1 in synonyms[w2])): continue result = False break output.append(result) return output
Beberapa catatan singkat:
- Perhatikan penggunaan
dict.get() . Anda bisa menerapkan pemeriksaan untuk melihat apakah kunci ada di dikt, dan kemudian mendapatkannya, tetapi ini adalah pendekatan yang rumit, meskipun dengan cara ini Anda akan menunjukkan pengetahuan Anda tentang perpustakaan standar. - Saya pribadi bukan penggemar kode dengan sering
continue , dan beberapa panduan gaya melarang atau tidak merekomendasikan mereka . Saya sendiri di edisi pertama kode ini lupa continue pernyataan setelah memeriksa panjang permintaan. Ini bukan pendekatan yang buruk, hanya tahu bahwa itu rawan kesalahan.
Bagian 2: Semakin keras!
Kandidat yang baik, setelah menyelesaikan masalah, masih memiliki sepuluh hingga lima belas menit waktu tersisa. Untungnya, ada banyak pertanyaan tambahan, meskipun tidak mungkin kita akan menulis banyak kode selama ini. Namun, ini tidak perlu. Saya ingin tahu dua hal tentang kandidat: apakah dia mampu mengembangkan algoritma dan apakah dia mampu membuat kode? Masalah dengan langkah ksatria pertama menjawab pertanyaan tentang pengembangan algoritma, dan kemudian memeriksa kodenya, dan di sini kita mendapatkan jawaban dalam urutan terbalik.
Pada saat kandidat menyelesaikan bagian pertama dari pertanyaan, ia telah menyelesaikan masalah dengan pengkodean (yang mengejutkan bukan-sepele). Pada tahap ini, saya yakin dapat berbicara tentang kemampuannya untuk mengembangkan algoritma yang belum sempurna dan menerjemahkan ide ke dalam kode, serta kenalannya dengan bahasa favorit dan perpustakaan standar. Sekarang percakapan menjadi jauh lebih menarik, karena persyaratan pemrograman bisa santai, dan kami akan menyelami algoritma.
Untuk tujuan ini, kita kembali ke postulat utama dari bagian pertama: urutan kata itu penting, sinonim adalah non-transitif, dan untuk setiap kata ada beberapa sinonim. Ketika wawancara berlangsung, saya mengubah masing-masing batasan ini, dan dalam fase baru ini, kandidat dan saya memiliki diskusi yang murni algoritmik. Di sini saya akan memberikan contoh kode untuk mengilustrasikan sudut pandang saya, tetapi dalam wawancara nyata kita hanya berbicara tentang algoritma.
Sebelum memulai, saya akan menjelaskan posisi saya: semua tindakan selanjutnya pada tahap wawancara ini terutama adalah "poin bonus". Pendekatan pribadi saya adalah mengidentifikasi kandidat yang benar-benar melalui tahap pertama dan cocok untuk bekerja. Tahap kedua diperlukan untuk menyoroti yang terbaik. Peringkat pertama sudah sangat kuat dan berarti bahwa kandidat cukup baik untuk perusahaan, dan peringkat kedua mengatakan bahwa kandidat sangat baik dan perekrutannya akan menjadi kemenangan besar bagi kami.
Transitivitas: Pendekatan Naif
Pertama, saya ingin menghapus batasan transitivitas, jadi jika pasangan A - B dan B - C adalah sinonim, maka kata - kata A dan C juga sinonim. Calon yang cerdas akan dengan cepat memahami bagaimana mengadaptasi solusi mereka sebelumnya, meskipun dengan penghapusan lebih lanjut dari pembatasan lain, logika dasar dari algoritma akan berhenti bekerja.
Namun, bagaimana cara mengadaptasinya? Salah satu pendekatan yang umum adalah mempertahankan satu set sinonim lengkap untuk setiap kata berdasarkan hubungan transitif. Setiap kali kami memasukkan kata ke dalam serangkaian sinonim, kami juga menambahkannya ke set yang sesuai untuk semua kata di set ini:
synonyms = defaultdict(set) for w1, w2 in synonym_words: for w in synonyms[w1]: synonyms[w].add(w2) synonyms[w1].add(w2) for w in synonyms[w2]: synonyms[w].add(w1) synonyms[w2].add(w1)
Harap perhatikan bahwa saat membuat kode, kami telah menyelidiki solusi ini.Solusi ini berfungsi, tetapi jauh dari optimal. Untuk memahami alasannya, kami memperkirakan kompleksitas spasial dari solusi ini. Setiap sinonim harus ditambahkan tidak hanya pada himpunan kata awal, tetapi juga pada himpunan semua sinonimnya. Jika ada satu sinonim, maka satu entri ditambahkan. Tetapi jika kami memiliki 50 sinonim, Anda harus menambahkan 50 entri. Pada gambar, terlihat seperti ini:
Perhatikan bahwa kami beralih dari tiga kunci dan enam catatan menjadi empat kunci dan dua belas catatan. Sebuah kata dengan 50 sinonim akan membutuhkan 50 kunci dan hampir 2500 entri. Ruang yang diperlukan untuk mewakili satu kata tumbuh secara kuadratik dengan peningkatan set sinonim, yang agak boros.
Ada solusi lain, tapi saya tidak akan terlalu dalam agar tidak mengembang artikel. Yang paling menarik dari mereka adalah penggunaan struktur data sinonim untuk membangun grafik yang diarahkan, dan kemudian pencarian pertama untuk menemukan jalur antara dua kata. Ini adalah solusi yang bagus, tetapi pencarian menjadi linier dalam ukuran set sinonim untuk kata tersebut. Karena kami melakukan pencarian ini untuk setiap permintaan beberapa kali, pendekatan ini tidak optimal.
Transitivitas: Menggunakan Set Terpisah
Ternyata mencari sinonim adalah mungkin untuk waktu (hampir) konstan berkat struktur data yang disebut set disjoint. Struktur ini menawarkan kemungkinan yang sedikit berbeda dari kumpulan data biasa.
Struktur pengaturan yang biasa (hashset, treeset) adalah wadah yang memungkinkan Anda untuk dengan cepat menentukan apakah suatu benda di dalam atau di luarnya. Disjoint set memecahkan masalah yang sama sekali berbeda: alih-alih mendefinisikan elemen tertentu, mereka memungkinkan Anda untuk menentukan
apakah dua elemen milik set yang sama . Selain itu, struktur melakukan ini untuk waktu yang sangat cepat
O(a(n)) , di mana
a(n) adalah fungsi Ackerman terbalik. Jika Anda belum mempelajari algoritme lanjutan, Anda mungkin tidak tahu fungsi ini, yang untuk semua input yang masuk akal sebenarnya dieksekusi dalam waktu yang konstan.
Pada level tinggi, algoritme berfungsi sebagai berikut. Set diwakili oleh pohon dengan orang tua untuk setiap elemen. Karena setiap pohon memiliki root (elemen yang merupakan induknya sendiri), kita dapat menentukan apakah dua elemen milik set yang sama dengan melacak orang tua mereka ke root. Jika dua elemen memiliki satu root, mereka milik satu set. Menggabungkan set juga mudah: cukup temukan elemen root dan jadikan salah satu dari mereka root dari yang lain.
Sejauh ini bagus, tapi sejauh ini tidak ada kecepatan menyilaukan yang terlihat. Jenius struktur ini adalah dalam prosedur yang disebut
kompresi . Misalkan Anda memiliki pohon berikut:
Bayangkan Anda ingin tahu apakah
cepat dan
tergesa -
gesa adalah sinonim. Telusuri setiap orang tua - dan temukan root
cepat yang sama. Sekarang anggaplah kita melakukan pemeriksaan serupa untuk kata-kata
cepat dan
cepat . Sekali lagi, kita naik ke root, dan dari
cepat kita pergi ke rute yang sama. Bisakah duplikasi pekerjaan dihindari?
Ternyata kamu bisa. Dalam arti tertentu, setiap elemen di pohon ini ditakdirkan untuk
berpuasa . Alih-alih melewati seluruh pohon setiap kali, mengapa tidak mengubah induk untuk semua keturunan
cepat untuk mempersingkat rute ke root? Proses ini disebut kompresi, dan dalam set yang terpisah ia tertanam dalam operasi pencarian root. Misalnya, setelah operasi pertama yang membandingkan
speedy dan
tergesa -
gesa, struktur akan memahami bahwa mereka adalah sinonim dan akan memampatkan pohon sebagai berikut:
Untuk semua kata antara cepat dan cepat, orangtua diperbarui, hal yang sama terjadi dengan tergesa-gesaSekarang semua panggilan berikutnya akan terjadi dalam waktu yang konstan, karena setiap node di pohon ini menunjuk ke
cepat . Sangat tidak mudah untuk mengevaluasi kompleksitas waktu operasi: pada kenyataannya, itu tidak konstan, karena itu tergantung pada kedalaman pohon, tetapi dekat dengan konstan, karena struktur cepat dioptimalkan. Untuk kesederhanaan, kami menganggap bahwa waktu adalah konstan.
Dengan konsep ini, kami menerapkan perangkat yang tidak terkait untuk masalah kami:
class DisjointSet(object): def __init__(self): self.parents = {} def get_root(self, w): words_traversed = [] while self.parents[w] != w: words_traversed.append(w) w = self.parents[w] for word in words_traversed: self.parents[word] = w return w def add_synonyms(self, w1, w2): if w1 not in self.parents: self.parents[w1] = w1 if w2 not in self.parents: self.parents[w2] = w2 w1_root = self.get_root(w1) w2_root = self.get_root(w2) if w1_root < w2_root: w1_root, w2_root = w2_root, w1_root self.parents[w2_root] = w1_root def are_synonymous(self, w1, w2): return self.get_root(w1) == self.get_root(w2)
Dengan menggunakan struktur ini, Anda dapat melakukan pra-proses sinonim dan menyelesaikan masalah dalam waktu linier.Peringkat dan catatan
Pada saat ini, kami telah mencapai batas yang dapat ditunjukkan oleh seorang kandidat dalam 40–45 menit wawancara. Kepada semua kandidat yang mengatasi bagian pengantar dan membuat kemajuan signifikan dalam menggambarkan (tidak menerapkan) set yang tidak terkait, saya memberikan peringkat "Sangat Direkomendasikan untuk Dipekerjakan" dan memungkinkan mereka untuk mengajukan pertanyaan. Saya belum pernah melihat seorang kandidat melangkah sejauh ini dan memiliki banyak waktu tersisa.Pada prinsipnya, masih ada varian masalah dengan transitivitas: misalnya, menghapus batasan pada urutan kata atau pada beberapa sinonim untuk sebuah kata. Setiap keputusan akan sulit dan menyenangkan, tetapi saya akan meninggalkannya untuk nanti.Kelebihan dari tugas ini adalah memungkinkan kandidat untuk melakukan kesalahan. Pengembangan perangkat lunak harian terdiri dari siklus analisis, eksekusi, dan penyempurnaan yang tiada akhir. Masalah ini memungkinkan bagi kandidat untuk menunjukkan kemampuan mereka di setiap tahap. Pertimbangkan keterampilan yang dibutuhkan untuk mendapatkan skor maksimum pada ini:- Menganalisis pernyataan masalah dan menentukan di mana tidak dirumuskan dengan jelas , kembangkan rumusan yang tidak ambigu. Terus lakukan ini saat Anda menyelesaikan dan muncul pertanyaan baru. Untuk efisiensi maksimum, lakukan operasi ini sedini mungkin, karena semakin jauh pekerjaan telah berjalan, semakin banyak waktu yang diperlukan untuk memperbaiki kesalahan.
- , . , .
- . , , .
- , . ,
continue , , .
- , : , , , . , , , .
- . — , . — .
Tak satu pun dari keterampilan ini dapat dipelajari dari buku teks (dengan kemungkinan pengecualian struktur data dan algoritma). Satu-satunya cara untuk memperoleh ini adalah praktik rutin dan ekstensif, yang sesuai dengan apa yang dibutuhkan majikan: kandidat berpengalaman yang mampu menerapkan pengetahuan mereka secara efektif. Maksud dari wawancara adalah menemukan orang-orang seperti itu, dan tugas dari artikel ini membantu saya dengan baik untuk waktu yang lama.Rencana masa depan
Seperti yang bisa Anda pahami, tugas itu akhirnya diketahui publik . Sejak itu, saya telah menggunakan beberapa pertanyaan lain, tergantung pada apa yang ditanyakan pewawancara sebelumnya dan pada suasana hati saya (menanyakan satu pertanyaan membosankan sepanjang waktu). Saya masih menggunakan beberapa pertanyaan, jadi saya akan merahasiakannya, tetapi ada yang tidak! Anda dapat menemukannya di artikel berikut.Dalam waktu dekat saya merencanakan dua artikel. Pertama, seperti yang dijanjikan di atas, saya akan menjelaskan solusi untuk dua masalah yang tersisa untuk tugas ini. Saya tidak pernah meminta mereka saat wawancara, tetapi mereka menarik dalam diri mereka sendiri. Selain itu, saya akan membagikan pemikiran dan pendapat pribadi saya tentang prosedur untuk menemukan karyawan di bidang TI, yang sangat menarik bagi saya sekarang, karena saya sedang mencari insinyur untuk tim saya di Reddit.Seperti biasa, jika Anda ingin tahu tentang rilis artikel baru, ikuti saya di Twitter atau di Medium . Jika Anda menyukai artikel ini, jangan lupa untuk memilih atau memberikan komentar.Terima kasih sudah membaca!PS: Anda dapat memeriksa kode semua artikel di dalam GitHub repositori atau bermain dengan mereka hidup berkat teman baik saya dari repl.it .