Pasar layanan cloud berkembang pesat baik di dunia maupun di Rusia. Semakin banyak perusahaan memindahkan aplikasi dan data mereka, termasuk yang penting untuk bisnis, ke cloud. Menurut pemasar, ini memungkinkan perusahaan untuk menggunakan solusi cloud inovatif paling canggih, mengurangi biaya modal (mengubah CAPEX ke OPEX), lebih cepat untuk membawa produk baru ke pasar dan meluncurkan layanan baru. Dan argumen seperti itu tidak membuat pelanggan potensial acuh tak acuh. Bukan kebetulan bahwa tingkat pertumbuhan pasar cloud Rusia secara signifikan di depan pertumbuhan pasar untuk infrastruktur TI klasik dan tradisional.
Lambat laun, keraguan tentang keandalan dan keamanan awan hilang. Seperti yang ditunjukkan oleh
studi iKS-Consulting baru
-baru ini , hampir 40% perusahaan Rusia yang disurvei melihat menggunakan cloud publik sebagai peluang untuk meningkatkan keamanan sistem TI mereka. Layanan cloud infrastruktur paling populer adalah penyewaan server virtual. Di tempat kedua dalam popularitas adalah layanan cadangan cloud (Backup-as-a-Service). Sekitar sepertiga responden menggunakan layanan cloud untuk menyimpan penyimpanan dan infrastruktur DR.
Sementara itu, dengan meningkatnya ketergantungan bisnis pada TI, persyaratan untuk keandalan layanan TI, termasuk layanan cloud, tumbuh. Dan seringkali ada kebutuhan untuk tidak hanya menyediakan keandalan perangkat keras, tetapi juga toleransi terhadap bencana.
Menurut penelitian , hampir tiga perempat organisasi di dunia tidak sepenuhnya yakin bahwa mereka akan dapat memulihkan sistem dan data mereka. Downtime yang tidak direncanakan dan kerugian biaya data organisasi di seluruh dunia setiap tahun lebih dari $ 1,7 miliar. Menurut
penelitian Acronis , di Rusia, hanya 2% dari perusahaan yang disurvei yang benar-benar yakin bahwa infrastruktur TI mereka akan tahan terhadap pengujian apa pun. Setengah dari spesialis Rusia mengharapkan gangguan lama dalam kerjanya jika terjadi bencana alam atau kecelakaan. Menurut statistik dunia, 93% perusahaan yang telah kehilangan pusat data mereka hanya dalam 10 hari bangkrut dalam setahun.
Dalam sistem yang kompleks secara teknis, kecelakaan tidak dapat dihindari, tetapi kecelakaan dapat dibuat tidak penting untuk bisnis. Untuk mencegah situasi seperti itu, diciptakan sistem cluster tahan bencana yang secara virtual menghilangkan downtime jika terjadi kecelakaan dan kegagalan.
Poin penting lain yang tidak boleh dilupakan ketika merancang infrastruktur TI yang tahan bencana adalah workstation pengguna. Penting untuk melanjutkan proses bisnis, dan tidak hanya beralih ke server cadangan atau meningkatkan database. Toleransi bencana dimulai di kantor pelanggan. Bahkan kantor cadangan dengan pekerjaan karyawan bukanlah pilihan terbaik. Virtual workstation (VDIs) atau bentuk lain dari tempat kerja di cloud dapat menjadi solusi yang baik. Akses ke stasiun kerja seperti itu di mesin virtual di pusat data mudah diatur dari komputer mana pun di jaringan cabang.
Inovasi cloud
Operator telekomunikasi Rusia
MasterTel dan Lenovo telah bersama-sama menyiapkan dan mengimplementasikan proyek cloud
tahan bencana yang disebut
Innovate Cloud Technology . Berdasarkan cloud ini, layanan IaaS yang sangat andal disediakan untuk berbagai pelanggan yang ingin menggunakan infrastruktur TI penting di cloud. Awan itu didasarkan pada cluster metro yang berjarak antara dua situs - DataPro dan pusat data IXCellerate di Moskow.
Memilih mitra untuk proyek ini, perusahaan MasterTel dibimbing, pertama-tama, oleh kemampuan vendor untuk segera memberikan solusi paling lengkap dengan harga yang wajar. Untuk mengimplementasikan cloud, diluncurkan pada Oktober 2018, sebuah tim spesialis Layanan Profesional Lenovo terlibat. MasterTel bertindak sebagai penyedia layanan cloud dan operator telekomunikasi yang mengatur saluran komunikasi yang aman dan menyediakan saluran serat optik langsung, bertanggung jawab atas pengoperasian cloud dan dukungannya.
Innovate Cloud Technology adalah cloud pribadi untuk klien korporat, menawarkan layanan cloud real-time yang sangat andal dan terukur IaaS, BaaS, DRaaS, VDS, dll. Apa yang disediakan oleh penggunaan layanan Teknologi Inovasi Cloud?
Keandalan tinggi
Saat ini, sebagian besar proyek cloud, pada kenyataannya, menyediakan kapasitas untuk disewa. Sebagai aturan, ini adalah pembuatan server virtual (layanan pusat data komersial paling umum di Rusia) dan akses ke kumpulan sumber daya yang sudah terbentuk. Dalam kasus Innovate Cloud Technology, pelanggan dapat membuat semua pengaturan online, sumber daya dialokasikan dan dibebaskan secara dinamis dan dibayar setelah fakta, khusus untuk sumber daya yang digunakan, sebagaimana layaknya layanan cloud klasik.
Tetapi mungkin fitur terpenting dari Innovate Cloud Technology adalah keandalannya yang tinggi. Pelanggan dapat memanfaatkan infrastruktur cloud ketersediaan tinggi dan menyimpan data yang sangat penting di pusat data DataPro dan IXcellelle yang tersebar secara geografis. Situs-situs ini sendiri menjamin keandalan dan tingkat keamanan fisik dan informasi yang tinggi. Saluran komunikasi berkecepatan tinggi yang andal dan akses ke kedua pusat data disediakan oleh MasterTel.
Innovate Cloud Technology adalah sumber daya cloud dengan ketersediaan SLA 99,99% dijamin. Namun, cloud ini tidak hanya dibedakan oleh keandalan yang tinggi, tetapi juga toleransi terhadap bencana, karena ini adalah cluster virtualisasi yang tersebar secara geografis di dua lokasi level Tier III.
Pusat Data DataPro
Pusat data ini Tingkat III di jalan. Aviamotornaya di Moskow adalah salah satu dari sedikit pusat data komersial Rusia yang telah menerima sertifikasi Desain dan Fasilitas Uptime. Semua teknologi dan solusi yang digunakan di pusat data disertifikasi, yang berarti toleransi kesalahan maksimum, ketersediaan sumber daya yang terjamin dan merupakan jaminan terhadap situasi yang tidak terduga.
Pusat Manajemen DataPro Pusat Data. Sertifikasi Internasional untuk Desain dan Fasilitas Uptime berarti bahwa ia dirancang dan dibangun sesuai dengan semua standar yang berlaku untuk kategori keandalan Tier III.
Keamanan bertanggung jawab atas keamanan pusat data itu sendiri dan area sekitarnya. Sistem keamanan mencakup lebih dari 350 kamera jaringan. Untuk catu daya yang tidak terputus dan terjamin, digunakan suplai daya tak terputus (UPS), genset diesel (DGU) digunakan yang mendukung operasi pusat data selama kecelakaan berkepanjangan di jaringan catu daya.
Di pusat data DataPro, ada dua input 10 kV independen dari gardu Mosenergo, dan kabel diletakkan di kolektor yang berbeda, memberikan daya listrik yang diperlukan ke fasilitas. Catu daya dari pusat data sebenarnya dicadangkan sesuai dengan skema 2N.
IXcellerate Moscow One
Pusat data Moscow One IXcellerate juga memegang sertifikasi Tier Uptime Institute III dalam kategori Desain. Fasilitas ini juga memenuhi tingkat keandalan Level 3 dalam kategori "proyek", "konstruksi" dan "operasi" sesuai dengan metodologi Sistem Keandalan Keandalan IBM. IXcellerate Moscow One secara teknis dilaksanakan dan dijamin pada tingkat SLA dengan indikator ketersediaan 99,999%. Total area pusat data IXcellerate Moscow One di Degunino adalah 15.741 meter persegi. m. Kapasitas desain fasilitas mencapai 13,7 MW. Pelanggan pusat data mencakup sekitar seratus perusahaan internasional dan Rusia.
Lulus tes sertifikasi dari Uptime Institute membuktikan bahwa kompleks komputasi IXcellerate dirancang sesuai dengan praktik dunia modern dalam pembangunan pusat data.
Toleransi bencana
Distribusi di dua situs memerlukan pengaturan saluran komunikasi yang berlebihan, replikasi data antar penyimpanan. Kami membutuhkan mekanisme sinkronisasi data untuk memastikan relevansinya jika terjadi kegagalan salah satu node dan untuk mendukung pengoperasian sistem informasi yang memerlukan sinkronisasi tersebut.
Seringkali di jantung pusat data yang tahan bencana adalah konfigurasi server cluster terdistribusi secara geografis dengan koneksi ke jaringan area penyimpanan umum (SAN). Node dari cluster spasi ini terletak di situs utama dan cadangan, membentuk sistem tunggal. Ini memastikan ketersediaan layanan tanpa gangguan bahkan jika terjadi kehilangan salah satu pusat data. Dengan bantuan pengelompokan, dimungkinkan untuk menyediakan pemindahan beban otomatis antara situs-situs pusat data yang terdistribusi jika terjadi kecelakaan.
Sistem penyimpanan data di situs-situs ini dapat saling menduplikasi satu sama lain, dan situs itu sendiri dihubungkan oleh saluran komunikasi berkecepatan tinggi yang berlebihan, yang memungkinkan Anda untuk mengimplementasikan proyek dengan persyaratan tertinggi untuk keandalan transfer data dan ketersediaannya, termasuk replikasi data yang sinkron.
Contoh Konfigurasi Metrocluster berbasis VMware vSphere. ini didasarkan pada duplikasi sistem penyimpanan di dua situs yang terpisah secara geografis dengan replikasi data dan kemungkinan load balancing di tingkat jaringan pusat data. Jika salah satu pusat data tidak tersedia, mesin virtual akan secara otomatis mulai pada platform kedua. Cluster metro hampir nol downtime, pekerjaan hanya terganggu selama startup mesin virtual ketika VMware High Availability (HA) me-restart VM di situs jarak jauh dengan penyimpanan yang terletak di cluster.
Jika Anda menggunakan mekanisme penyeimbangan beban DR (Global Server Load Balancing, GSLB), Anda dapat secara otomatis mengalihkan pengguna ke situs cadangan jika terjadi kegagalan primer. Untuk pengguna, proses ini akan transparan.
Tidak seperti DR dengan replikasi data, dalam kasus cluster metro, hanya jenis disk yang sama digunakan untuk mirroring, konfigurasi yang sama diperlukan di kedua situs.
Cloud Innovate Cloud Technology berbasis VMware dibangun dengan cara ini. Ini menyediakan operasi terus menerus dari aplikasi dan data penting di cloud. Semua elemen cluster virtualisasi digandakan di dua situs, berjarak satu sama lain sejauh hampir 30 km. Di antara mereka, mirroring data dikonfigurasikan pada tingkat sistem penyimpanan. Karena itu, data dan layanan akan tersedia jika terjadi kegagalan di salah satu lokasi: pemadaman listrik, kegagalan sebagian sistem penyimpanan, pengontrol, saluran komunikasi antara pusat data dan bahkan dalam hal ketidakberoperasian penuh dari salah satu lokasi.
Jika salah satu pusat data tidak tersedia, mesin virtual dimigrasikan ke situs cadangan. Memulai mesin virtual di situs cadangan (Recovery Time Objective, RTO) akan memakan waktu sekitar 3 menit.
Klien ditawari Perjanjian Tingkat Layanan terperinci (SLA). Indikator utamanya: ketersediaan layanan di level 99,99%; sederhana - tidak lebih dari 4,38 menit per bulan, parameter kinerja prosesor yang dijamin (MIPS / 1 vCPU), sistem disk (IOPS, GB / s), keterlambatan mengakses sistem penyimpanan. Untuk kepatuhan mereka, penyedia bertanggung jawab secara finansial.
Anatomi Cluster Metro
Awan dibangun sesuai dengan model arsitektur klasik, yang melibatkan pembelian seluruh kompleks perangkat keras dan perangkat lunak yang diperlukan: server dengan organisasi akses fisik dan logis, penyimpanan, komponen jaringan, perangkat lunak virtualisasi, solusi keamanan.
Dua pusat data di Moskow telah mendedikasikan zona tertutup untuk empat rak dengan komputasi dan node jaringan. Solusinya dibangun pada komponen yang diproduksi oleh Lenovo. Sebagai sistem komputasi perangkat keras, server 1U Lenovo ThinkSystem SR530 / SR570 / SR630 server dengan Emulex 16Gb Gen6 FC HBA port ganda adapter, digunakan, Lenovo Storage V3700 V2 XP array digunakan untuk penyimpanan data, dan switch rak 32-port 10-Gigabit digunakan untuk transfer data dengan Lenovo ThinkSystem NE1032 RackSwitch. Paket termasuk perangkat lunak VMware ESXi 6.5 yang diinstal pabrik pada server. Situs-situs tersebut terhubung oleh dua saluran FC 8 Gbit / s dan dua saluran Ethernet 10 Gbit / s.
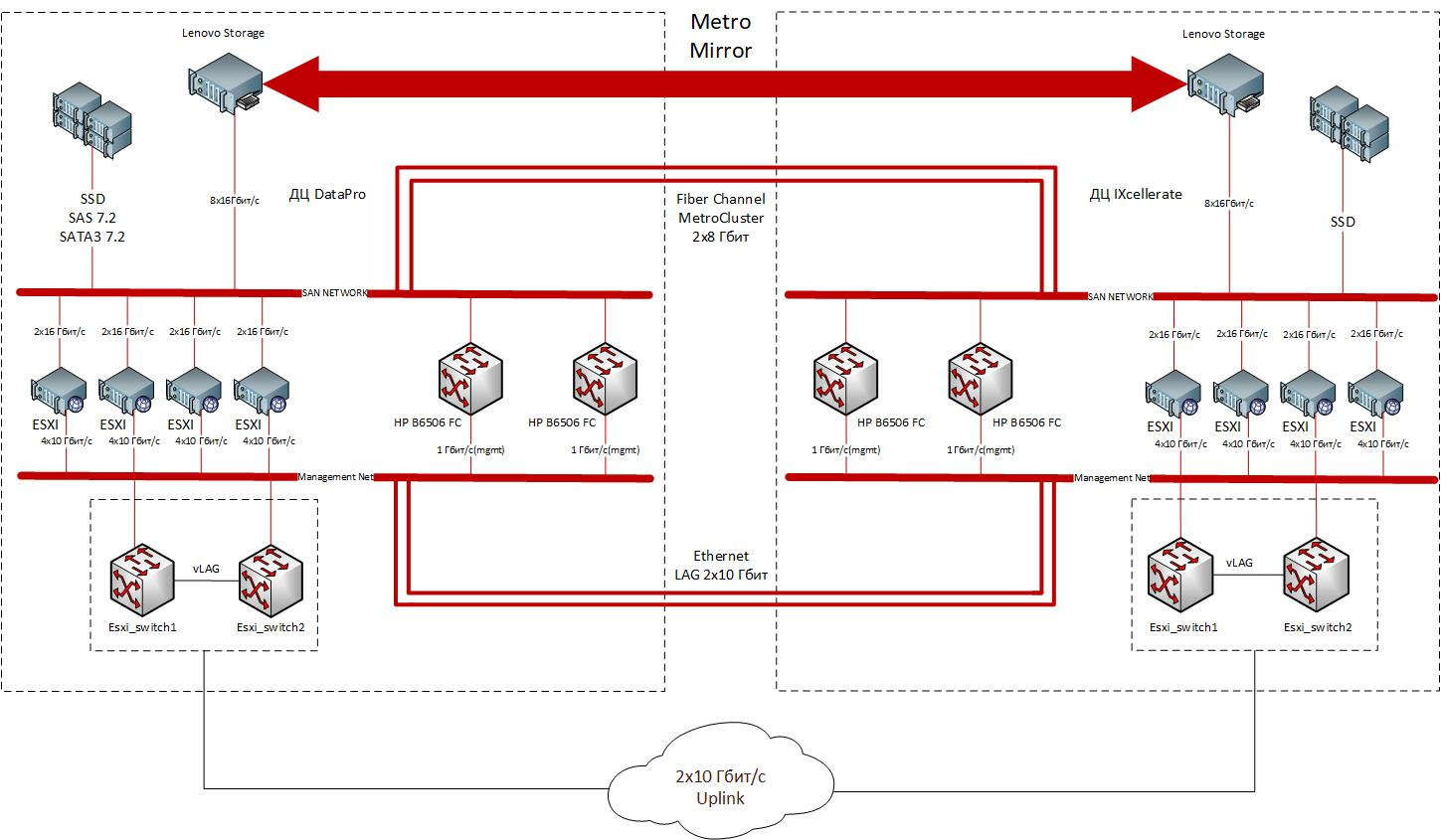
Struktur cluster yang didistribusikan secara geografis. Terletak di antara kedua situs, cluster metro memberikan toleransi bencana dan memungkinkan untuk menyediakan layanan IaaS yang dapat diandalkan untuk berbagai pelanggan. Situs-situs tersebut terhubung oleh saluran redundant Ethernet (2x10 Gbit / s) dan FC (2x8 Gbit / s).
Dengan memperoleh komponen infrastruktur dari satu pemasok, keandalan dan ketahanan seluruh kompleks meningkat, konflik antara elemen, standar, dan protokol dihilangkan.
Upaya bersama dari kedua tim melakukan pekerjaan pada pembuatan proyek, persiapan dan pengembangan spesifikasi teknis, pemasangan peralatan, commissioning, pengujian stres dan commissioning cluster metro.
Lenovo Metrocluster menyediakan cadangan penuh untuk semua elemennya: server, penyimpanan, pengontrol, adaptor FC, sakelar optik. Replikasi data sinkron tingkat penyimpanan menyediakan nol Recovery Point Objective (RPO).
Ketersediaan tinggi selalu dicapai dengan memastikan redundansi - ini juga berlaku dalam hal persiapan untuk situasi ekstrem, ketika seluruh pusat data harus dilindungi dari pemadaman listrik atau dari bencana alam. Jika salah satu situs gagal, gugus yang tersebar secara geografis secara otomatis dan tanpa mengganggu proses kerja beralih ke pusat data kedua. Bahkan, kluster metro adalah kluster lokal dengan sistem penyimpanan cermin, berjarak antara dua situs.
Cluster yang didistribusikan secara geografis tidak memiliki titik kritis kegagalan. Cluster metro mengimplementasikan replikasi data yang saling sinkron antara situs. Jika terjadi masalah, beralih ke situs lain sepenuhnya transparan dan tanpa campur tangan administrator. Otomatisasi proses ini memastikan operasi yang berkelanjutan dari semua aplikasi. Cluster Metro juga tidak perlu dihentikan untuk memperbarui perangkat keras atau lunaknya.
Misalnya, jika terjadi kegagalan seluruh server, tanggung jawabnya ditransfer ke server kedua yang terletak di situs yang sama dalam beberapa detik. Gangguan jangka pendek dari input-output data yang terjadi dalam kasus ini tidak akan mempengaruhi operasi aplikasi, karena data dicerminkan secara sinkron ke platform kedua. Jika ada masalah dalam pengoperasian sakelar, kabel atau HBA Kanal Serat, pengalihan cadangan ke pusat data kedua tidak diperlukan, dan pengguna akhir tidak akan mengalami penurunan kinerja aplikasi.
Dalam hal terjadi kegagalan seluruh node layanan, gangguan jangka pendek (beberapa detik) terjadi pada aliran I / O: layanan pertama-tama ditransfer ke node tetangga, dan kebutuhan untuk beralih ke node geografis terpencil muncul hanya jika situs benar-benar terganggu.
Dalam situasi ini, kluster yang tersebar secara geografis menggunakan redundansi di tingkat pusat data untuk mengatasi kegagalan, dan sistem yang terletak di situs kedua mengambil alih dukungan semua layanan. Dengan demikian, server aplikasi mempertahankan akses ke semua layanan, tetapi dengan kinerja terbatas.
Ketika situs di mana kegagalan terjadi akan kembali memasuki mode operasi, akan diperlukan untuk mentransfer hanya data yang telah diubah selama downtime, oleh karena itu, setelah menghilangkan masalah lokal, pusat data yang terpengaruh akan dapat kembali ke operasi normal dengan sangat cepat.
Dalam hal kehilangan host, VMware High Availability (HA) segera me-restart VM di situs jarak jauh. Jika salah satu sistem penyimpanan gagal, sistem penyimpanan di situs lain mengumumkan jalur disk ke host yang tersisa. VM yang hilang dihidupkan ulang pada mereka, semuanya terjadi secara otomatis.
Jika koneksi antar situs terputus, maka semuanya terus bekerja di tempatnya dan, segera setelah koneksi dipulihkan, proses sinkronisasi dimulai.
Komposisi Solusi
Delapan server Lenovo ThinkSystem SR630 dengan 2 prosesor Intel Xeon Gold 6132 14C 140W 2,6 GHz, memori 32 GB TruDDR4 2666 MHz (RDIMM), bay drive 10 2,5 ", drive drive M.2 32 GB SATA dan perangkat lunak VMware ESXi 6.5 yang diinstal pabrik.
| Server prosesor ganda dalam faktor bentuk 1U memiliki fleksibilitas dan kinerja karena dukungan hard drive dan solid-state drive (HDD dan SSD) dengan antarmuka SAS atau SATA (12 SFF atau 4 LFF). Dengan kemampuan untuk menghubungkan drive NVMe memberikan kecepatan baca dan tulis yang tinggi. Perangkat lunak Lenovo XClarity Administrator menyederhanakan manajemen dan pemeliharaan infrastruktur. Solusi desain ini difokuskan pada keseimbangan kinerja dan harga untuk mendukung berbagai beban kerja, yang dirancang untuk operasi berkelanjutan pada suhu 45 ° C.
|
Dua sistem penyimpanan Lenovo Storage V3700 V2 XP dengan 1,92 TB 2,5 "SAS SSD dan 1,2 TB 2,5" HDD 10K, dengan perangkat lunak Easy Tier, FlashCopy, dan Remote Mirroring.
| Satu set alat penyimpanan fungsional memungkinkan Anda untuk secara efisien menyelesaikan masalah dengan sejumlah besar data dan dengan akses multi-threaded ke sumber daya informasi. V3700 V2 XP menyediakan kemampuan untuk mengkonsolidasikan beban, mendukung pembentukan sistem penyimpanan yang mampu mendukung berbagai aplikasi yang menuntut. Sistem pada prosesor Intel ditandai dengan kinerja tinggi dan kecepatan pertukaran data melalui bus SAS, alat fungsional yang sebelumnya hanya tersedia di perangkat kelas atas. Storage menawarkan antarmuka berbasis web dengan fungsi manajemen terintegrasi, menyediakan pembentukan konfigurasi kerja yang fleksibel dan penyebarannya yang cepat menggunakan virtualisasi, aplikasi cadangan menggunakan FlashCopy. Ini mendukung penskalaan vertikal hingga 240 drive 2,5 inci atau 120 drive dalam faktor bentuk 3,5 inci. Anda dapat menggunakan sembilan unit ekspansi untuk menskala.
|
Penyimpanan untuk Lenovo V3700 V2 dengan 20 drive HDD 2 TB 2,5 "7,2K
| Sistem ini menyediakan seperangkat alat yang menyediakan virtualisasi, penskalaan, dan manajemen terpadu. Ini adalah solusi hybrid dengan kemampuan virtualisasi. Penyimpanan Lenovo Storage V3700 V2 memiliki dua pengontrol RAID, memungkinkan Anda untuk menggunakan format penyimpanan apa pun - baik hard drive 3,5 "form factor, dan HDD atau SSD form factor 2.5". SHD hadir standar dengan perangkat lunak sistem dengan fungsi Virtualisasi Penyimpanan Internal, Penyediaan Tipis, Migrasi Data Satu Arah, FlashCopy (64 salinan). Fitur tambahan - FlashCopy (2048 salinan), Easy Tier, Remote Mirroring.
|
32- Ethernet 10 / Lenovo ThinkSystem NE1032 SFP+ SR.
| 24 10GBase-T 8 SFP+ 10 / . Lenovo Cloud NOS, . NE1032 . L2/L3 IP-, BGP, , Lenovo XClarity.
|
Fibre Channel Lenovo B6505 FC SAN c 12 SFP 16 /.
| Fibre Channel 5- -. - 16 /.
|
