
Topik meningkatkan kinerja sistem operasi dan menemukan kemacetan semakin populer. Dalam artikel ini, kita akan berbicara tentang satu alat untuk menemukan tempat-tempat ini menggunakan contoh tumpukan blok di Linux dan satu kasus pemecahan masalah host.
Contoh 1. Tes
Tidak ada yang berhasil
Pengujian di departemen kami adalah sintetis pada perangkat keras produk, dan pengujian perangkat lunak aplikasi selanjutnya. Kami menerima drive Intel Optane untuk pengujian. Kami sudah menulis tentang pengujian drive Optane
di blog kami .
Disk dipasang di server standar yang dibangun untuk waktu yang relatif lama di bawah salah satu proyek cloud.
Selama pengujian, disk menunjukkan dirinya tidak dalam cara terbaik: selama pengujian dengan kedalaman antrian 1 permintaan per 1 aliran, dalam blok 4Kbytes sekitar ~ 70Kiops. Dan ini berarti waktu respons sangat besar: sekitar 13 mikrodetik per permintaan!
Aneh, karena
spesifikasinya menjanjikan "Latensi - Baca 10 µs", dan kami mendapat 30% lebih, perbedaannya cukup signifikan. Disk itu disusun ulang ke platform lain, perakitan yang lebih "segar" yang digunakan dalam proyek lain.
Mengapa ini berhasil?
Ini lucu, tetapi drive pada platform baru berfungsi sebagaimana mestinya. Performa meningkat, latensi menurun, CPU per rak, 1 aliran per permintaan, blok 4K byte, ~ 106Kiops pada ~ 9 mikrodetik per permintaan.
Dan kemudian saatnya
membandingkan pengaturan untuk mendapatkan
perf dari
kaki lebar. Bagaimanapun, kita bertanya-tanya mengapa demikian? Dengan
perf, Anda dapat:
- Ambil bacaan penghitung perangkat keras: jumlah panggilan instruksi, cache salah, cabang yang diprediksi salah, dll. (Acara PMU)
- Hapus informasi dari poin perdagangan statis, jumlah kejadian
- Melakukan penelusuran dinamis
Untuk verifikasi, kami menggunakan pengambilan sampel CPU.
Intinya adalah bahwa
perf dapat mengkompilasi seluruh jejak tumpukan program yang sedang berjalan. Secara alami, menjalankan
perf akan menyebabkan penundaan dalam pengoperasian seluruh sistem. Tetapi kita memiliki flag
-F # , di mana
# adalah frekuensi sampling, diukur dalam Hz.
Penting untuk dipahami bahwa semakin tinggi frekuensi pengambilan sampel, semakin besar kemungkinan untuk menangkap panggilan ke fungsi tertentu, tetapi semakin banyak rem yang dibawa profiler ke sistem. Semakin rendah frekuensinya, semakin besar kemungkinan kita tidak akan melihat bagian dari tumpukan.
Ketika memilih frekuensi, Anda perlu dipandu oleh akal sehat dan satu trik - cobalah untuk tidak mengatur frekuensi genap, agar tidak masuk ke situasi ketika beberapa pekerjaan yang berjalan pada timer dengan frekuensi ini masuk ke dalam sampel.
Poin lain yang awalnya menyesatkan - perangkat lunak harus dikompilasi dengan flag
-fno-omit-frame-pointer , jika ini, tentu saja, mungkin. Jika tidak, dalam penelusuran, alih-alih nama fungsi, kita akan melihat nilai yang
tidak diketahui . Untuk beberapa perangkat lunak, simbol debugging datang sebagai paket terpisah, misalnya,
someutil-dbg . Anda disarankan untuk menginstalnya sebelum menjalankan
perf .
Kami melakukan tindakan berikut:
- Diambil fio dari git: //git.kernel.dk/fio.git, tag fio-3.9
- Menambahkan opsi -fno-omit-frame-pointer ke CPPFLAGS di Makefile
- Diluncurkan make -j8
perf record -g ~/fio/fio --name=test --rw=randread --bs=4k --ioengine=pvsync2 --filename=/dev/nvme0n1 --direct=1 --hipri --filesize=1G
Opsi -g diperlukan untuk menangkap tumpukan jejak.
Anda dapat melihat hasilnya dengan perintah:
perf report -g fractal
Opsi
fraktal -g diperlukan sehingga persentase yang mencerminkan jumlah sampel dengan fungsi ini dan ditunjukkan oleh
perf relatif terhadap fungsi panggilan, jumlah panggilan yang diambil sebagai 100%.
Menjelang akhir tumpukan panggilan fio pada platform "fresh build", kita akan melihat:
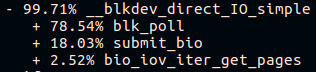
Dan pada platform "bangunan lama":

Hebat! Tapi saya ingin flamegraf cantik.
Membangun flamegrams
Untuk menjadi cantik, ada dua alat:
- Flamegraph yang relatif lebih statis
- Flamescope , yang memungkinkan untuk memilih periode waktu tertentu dari sampel yang dikumpulkan. Ini sangat berguna ketika kode pencarian memuat CPU dengan semburan pendek.
Utilitas ini menerima
skrip perf> hasil sebagai masukan.
Unduh
hasil dan kirim melalui pipa ke
svg :
FlameGraph/stackcollapse-perf.pl ./result | FlameGraph/flamegraph.pl > ./result.svg
Buka di browser dan nikmati gambar yang bisa diklik.
Anda dapat menggunakan metode lain:
- Tambahkan hasil ke flamescope / example /
- Jalankan python ./run.py
- Kami pergi melalui browser ke port 5000 host lokal
Apa yang kita lihat pada akhirnya?
Seorang fio yang baik menghabiskan banyak waktu dalam
pemungutan suara :
Orang jahat menghabiskan waktu di mana saja, tetapi tidak dalam pemungutan suara:
Pada pandangan pertama, tampaknya polling tidak berfungsi pada host lama, tetapi di mana-mana kernel 4,15 dari rakitan yang sama dan polling diaktifkan secara default pada disk NVMe. Periksa apakah polling diaktifkan di
sysfs :
Selama pengujian, panggilan ke
preadv2 dengan flag
RWF_HIPRI digunakan - kondisi yang diperlukan agar polling berfungsi. Dan, jika Anda mempelajari dengan hati-hati grafik nyala (atau tangkapan layar sebelumnya dari output
laporan perf ), Anda dapat menemukannya, tetapi itu membutuhkan waktu yang sangat sedikit.
Hal kedua yang terlihat adalah tumpukan panggilan yang berbeda untuk fungsi submit_bio () dan kurangnya panggilan io_schedule (). Mari kita lihat lebih dekat perbedaan di dalam submit_bio ().
Platform lambat "bangunan lama":
Platform cepat "segar":
Tampaknya pada platform lambat, permintaan berjalan jauh ke perangkat, pada saat yang sama masuk ke
scheduler Kyber . Anda dapat membaca lebih lanjut tentang penjadwal I / O di
artikel kami .
Setelah
kyber dimatikan, uji
fio yang sama menunjukkan latensi rata-rata sekitar 10 mikrodetik, seperti yang dinyatakan dalam spesifikasi. Hebat!
Tapi dari mana perbedaan mikrodetik lain berasal?
Dan jika sedikit lebih dalam?
Seperti yang telah disebutkan,
perf memungkinkan Anda mengumpulkan statistik dari penghitung perangkat keras. Mari kita coba melihat jumlah cache yang salah dan instruksi per siklus:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=10


Hal ini dapat dilihat dari hasil bahwa platform cepat mengeksekusi lebih banyak instruksi untuk siklus CPU dan memiliki persentase cache yang lebih rendah selama eksekusi. Tentu saja, kami tidak akan membahas operasi platform perangkat keras yang berbeda dalam kerangka artikel ini.
Contoh 2. Bahan makanan
Ada yang salah
Dalam pekerjaan sistem penyimpanan data terdistribusi, peningkatan beban pada CPU pada salah satu host diamati dengan peningkatan lalu lintas masuk. Host adalah teman sebaya, teman sebaya, dan memiliki perangkat keras dan perangkat lunak yang identik.
Mari kita lihat beban CPU:
~
Masalahnya muncul pada 09:23:46 dan kita melihat bahwa prosesnya bekerja di ruang kernel secara eksklusif untuk seluruh detik. Mari kita lihat apa yang terjadi di dalam.
Kenapa sangat lambat?
Dalam hal ini, kami mengambil sampel dari keseluruhan sistem:
perf record -a -g -- sleep 22 perf script > perf.results
Opsi
-a diperlukan di sini agar
perf dapat menghapus jejak dari semua CPU.
Buka
perf.hasil dengan
flamescope untuk melacak momen peningkatan beban CPU.
Di depan kita ada "peta panas", kedua sumbu (X dan Y) yang mewakili waktu.
Pada sumbu X, ruang dibagi menjadi detik, dan pada sumbu Y, menjadi segmen 20 milidetik dalam waktu X detik, Waktu berjalan dari bawah ke atas dan dari kiri ke kanan. Kotak paling terang memiliki jumlah sampel terbesar. Artinya, CPU saat ini bekerja paling aktif.
Sebenarnya, kami tertarik dengan titik merah di tengah. Pilih dengan mouse, klik dan lihat apa yang disembunyikannya:
Secara umum, sudah terlihat bahwa masalahnya adalah
tcp_recvmsg dan
skb_copy_datagram_iovec operasi lambat di dalamnya.
Untuk kejelasan, bandingkan dengan sampel host lain yang jumlah lalu lintasnya sama tidak menyebabkan masalah:
Berdasarkan fakta bahwa kami memiliki jumlah lalu lintas masuk yang sama, platform identik yang telah bekerja untuk waktu yang lama tanpa henti, kami dapat mengasumsikan bahwa masalah muncul di sisi besi. Fungsi
skb_copy_datagram_iovec menyalin data dari struktur kernel ke struktur di ruang pengguna untuk diteruskan ke aplikasi. Mungkin ada masalah dengan memori host. Pada saat yang sama, tidak ada kesalahan dalam log.
Kami me-restart platform. Saat memuat BIOS, kami melihat pesan tentang bilah memori yang rusak. Penggantian, host mulai dan masalah dengan CPU kelebihan beban tidak lagi direproduksi.
Catatan tambahan
Performa sistem dengan perf
Secara umum, pada sistem yang sibuk, menjalankan
perf dapat menyebabkan keterlambatan dalam memproses permintaan. Ukuran penundaan ini juga tergantung pada beban di server.
Mari kita coba cari penundaan ini:
~
Perbedaannya tidak terlalu mencolok, hanya sekitar ~ 8 nanodetik.
Mari kita lihat apa yang terjadi jika Anda menambah beban:
~
Di sini perbedaannya sudah menjadi nyata. Dapat dikatakan bahwa sistem melambat kurang dari 1%, tetapi pada dasarnya kehilangan sekitar 7Kiops pada sistem yang sarat muatan dapat menyebabkan masalah.
Jelas bahwa contoh ini adalah sintetis, namun sangat mengungkap.
Mari kita coba menjalankan tes sintetik lain yang menghitung bilangan prima -
sysbench :
~
Di sini Anda dapat melihat bahwa bahkan waktu pemrosesan minimum pun meningkat 270 mikrodetik.
Alih-alih sebuah kesimpulan
Perf adalah alat yang sangat kuat untuk menganalisis kinerja sistem dan debugging. Namun, seperti halnya alat lain, Anda perlu mengendalikan diri dan ingat bahwa sistem yang dimuat di bawah pengawasan ketat bekerja lebih buruk.
Tautan terkait: