Posting disiapkan oleh: Alexander Virilin xscrew - penulis, kepala layanan infrastruktur jaringan, Leonid Klyuyev - editor
Kami terus memperkenalkan Anda dengan struktur internal
Yandex.Cloud . Hari ini kita akan berbicara tentang jaringan - kami akan memberi tahu Anda bagaimana infrastruktur jaringan bekerja, mengapa menggunakan paradigma MPLS tidak populer untuk pusat data, keputusan rumit apa lagi yang harus kami buat dalam proses membangun jaringan cloud, bagaimana kami mengelolanya, dan jenis pemantauan yang kami gunakan.
Jaringan di Cloud terdiri dari tiga lapisan. Lapisan bawah adalah infrastruktur yang telah disebutkan. Ini adalah jaringan "besi" fisik di dalam pusat data, antara pusat data dan di tempat-tempat koneksi ke jaringan eksternal. Jaringan virtual dibangun di atas infrastruktur jaringan, dan layanan jaringan dibangun di atas jaringan virtual. Struktur ini bukan monolitik: lapisan berpotongan, jaringan virtual dan layanan jaringan berinteraksi langsung dengan infrastruktur jaringan. Karena jaringan virtual sering disebut overlay, kami biasanya menyebut underlay infrastruktur jaringan.

Sekarang infrastruktur Cloud berbasis di wilayah Tengah Rusia dan mencakup tiga zona akses - yaitu, tiga pusat data independen yang didistribusikan secara geografis. Independen - independen satu sama lain dalam konteks jaringan, teknik dan sistem kelistrikan, dll.
Tentang karakteristik. Geografi lokasi pusat data sedemikian rupa sehingga waktu pulang-pergi (RTT) waktu pulang-pergi di antara mereka selalu 6-7 ms. Total kapasitas saluran telah melebihi 10 terabit dan terus tumbuh, karena Yandex memiliki jaringan serat optik di antara zona. Karena kami tidak menyewakan saluran komunikasi, kami dapat dengan cepat meningkatkan kapasitas strip antara DC: masing-masing menggunakan peralatan multiplexing spektral.
Berikut adalah representasi zona yang paling skematis:
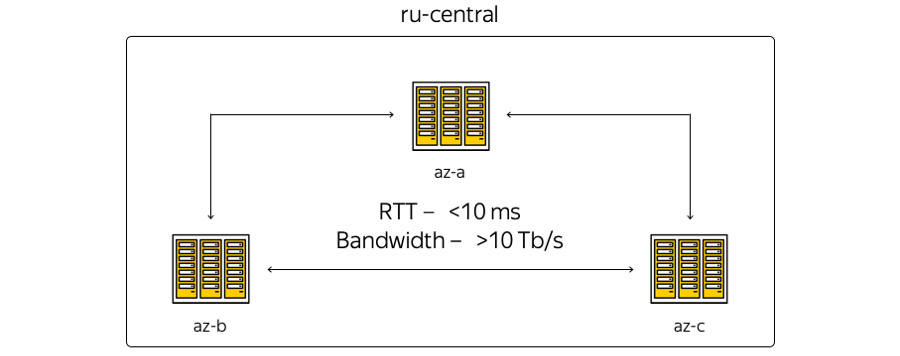
Kenyataannya, pada gilirannya, sedikit berbeda:
Berikut adalah jaringan tulang punggung Yandex saat ini di wilayah tersebut. Semua layanan Yandex bekerja di atasnya, bagian dari jaringan digunakan oleh Cloud. (Ini adalah gambar untuk penggunaan internal, oleh karena itu, informasi layanan sengaja disembunyikan. Namun demikian, dimungkinkan untuk memperkirakan jumlah node dan koneksi.) Keputusan untuk menggunakan jaringan backbone adalah logis: kami tidak dapat menemukan apa pun, tetapi menggunakan kembali infrastruktur saat ini - "menderita" selama bertahun-tahun pembangunan.
Apa perbedaan antara gambar pertama dan gambar kedua? Pertama-tama, zona akses tidak terkait langsung: situs teknis terletak di antara mereka. Situs tidak mengandung peralatan server - hanya perangkat jaringan untuk memastikan konektivitas ditempatkan pada mereka. Tempat kehadiran di mana Yandex dan Cloud terhubung dengan dunia luar terhubung ke situs teknis. Semua titik kehadiran berfungsi untuk seluruh wilayah. Ngomong-ngomong, penting untuk dicatat bahwa dari sudut pandang akses eksternal dari Internet, semua zona akses Cloud adalah setara. Dengan kata lain, mereka menyediakan konektivitas yang sama - yaitu, kecepatan dan throughput yang sama, serta latensi yang sama rendahnya.
Selain itu, ada peralatan di titik-titik kehadiran, yang - jika ada sumber daya di lokasi dan keinginan untuk memperluas infrastruktur lokal dengan fasilitas cloud - pelanggan dapat terhubung melalui saluran yang dijamin. Ini dapat dilakukan dengan bantuan mitra atau Anda sendiri.
Jaringan inti digunakan oleh Cloud sebagai transportasi MPLS.
MPLS
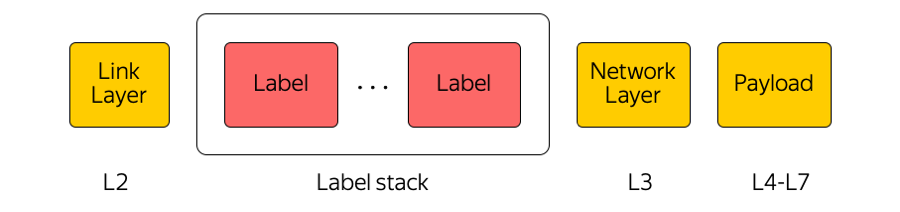
Multi-label label switching adalah teknologi yang banyak digunakan di industri kami. Misalnya, ketika sebuah paket ditransfer antara zona akses atau antara zona akses dan Internet, peralatan transit hanya memperhatikan label teratas, “tidak memikirkan” apa yang ada di bawahnya. Dengan cara ini, MPLS memungkinkan Anda untuk menyembunyikan kompleksitas Cloud dari lapisan transport. Secara umum, kami di Cloud sangat menyukai MPLS. Kami bahkan menjadikannya bagian dari level yang lebih rendah dan menggunakannya langsung di pabrik switching di pusat data:

(Sebenarnya, ada banyak tautan paralel antara sakelar Daun dan Duri.)
Mengapa MPLS?
Benar, MPLS sama sekali tidak sering ditemukan di jaringan pusat data. Seringkali teknologi yang benar-benar berbeda digunakan.
Kami menggunakan MPLS karena beberapa alasan. Pertama, kami merasa nyaman untuk menyatukan teknologi bidang kontrol dan bidang data. Artinya, alih-alih beberapa protokol di jaringan pusat data, protokol lain di jaringan inti dan persimpangan protokol ini - MPLS tunggal. Dengan demikian, kami menyatukan tumpukan teknologi dan mengurangi kompleksitas jaringan.
Kedua, di Cloud, kami menggunakan berbagai peralatan jaringan, seperti Cloud Gateway dan Network Load Balancer. Mereka perlu berkomunikasi satu sama lain, mengirim lalu lintas ke Internet dan sebaliknya. Peralatan jaringan ini dapat diskalakan secara horizontal dengan meningkatnya beban, dan karena Cloud dibangun sesuai dengan model hyperconvergence, mereka dapat diluncurkan secara mutlak di mana saja dari sudut pandang jaringan di pusat data, yaitu, di kumpulan sumber daya bersama.
Dengan demikian, peralatan ini dapat mulai di belakang port switch rak mana pun server berada, dan mulai berkomunikasi melalui MPLS dengan seluruh infrastruktur. Satu-satunya masalah dalam membangun arsitektur seperti itu adalah alarm.
Alarm
Tumpukan protokol MPLS klasik cukup kompleks. Omong-omong, ini adalah salah satu alasan non-proliferasi MPLS di jaringan pusat data.
Kami, pada gilirannya, tidak menggunakan IGP (Interior Gateway Protocol), atau LDP (Label Distribution Protocol), atau protokol distribusi label lainnya. Hanya BGP (Border Gateway Protocol) Label-Unicast yang digunakan. Setiap alat, yang beroperasi, misalnya, sebagai mesin virtual, membuat sesi BGP sebelum sakelar Leaf-mount rack.
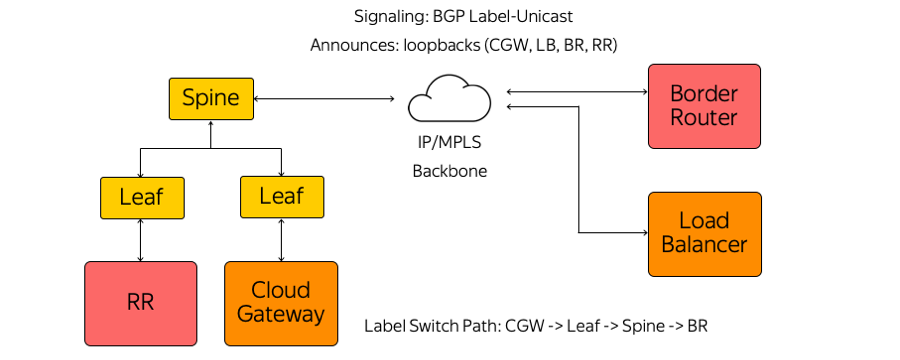
Sesi BGP dibuat di alamat yang sudah diketahui sebelumnya. Tidak perlu mengkonfigurasi sakelar untuk menjalankan setiap alat. Semua sakelar sudah dikonfigurasikan sebelumnya dan konsisten.
Dalam sesi BGP, setiap alat mengirimkan loopback sendiri dan menerima loopback sisa perangkat yang akan digunakan untuk bertukar lalu lintas. Contoh perangkat tersebut adalah beberapa jenis reflektor rute, router perbatasan dan peralatan lainnya. Akibatnya, informasi tentang cara menjangkau satu sama lain muncul di perangkat. Dari Cloud Gateway melalui sakelar Leaf, sakelar Spine dan jaringan ke router perbatasan, Label Switch Path dibuat. Switch adalah switch L3 yang berperilaku seperti Label Switch Router dan tidak tahu tentang kerumitan di sekitarnya.
MPLS di semua tingkatan jaringan kami, antara lain, telah memungkinkan kami untuk menggunakan konsep Eat your dogfood sendiri.
Makanlah makanan anjing Anda sendiri
Dari sudut pandang jaringan, konsep ini menyiratkan bahwa kita hidup dalam infrastruktur yang sama yang kami sediakan untuk pengguna. Berikut adalah diagram rak di area aksesibilitas:

Tuan rumah cloud mengambil beban dari pengguna, berisi mesin virtualnya. Dan secara harfiah, host tetangga di rak dapat membawa beban infrastruktur dari sudut pandang jaringan, termasuk reflektor rute, manajemen, server pemantauan, dll.
Mengapa ini dilakukan? Ada godaan untuk menjalankan reflektor rute dan semua elemen infrastruktur dalam segmen toleran-kesalahan yang terpisah. Kemudian, jika segmen pengguna rusak di suatu tempat di pusat data, server infrastruktur akan terus mengelola seluruh infrastruktur jaringan. Tetapi pendekatan ini tampak kejam bagi kami - jika kami tidak mempercayai infrastruktur kami sendiri, lalu bagaimana kami dapat menyediakannya untuk pelanggan kami? Lagi pula, benar-benar semua Cloud, semua jaringan virtual, pengguna, dan layanan cloud bekerja di atasnya.
Karenanya, kami meninggalkan segmen terpisah. Elemen infrastruktur kami berjalan dalam topologi jaringan dan konektivitas jaringan yang sama. Secara alami, mereka berjalan dalam tiga tingkat - sama seperti klien kami meluncurkan layanan mereka di Cloud.
Pabrik IP / MPLS
Berikut adalah diagram contoh dari salah satu zona ketersediaan:
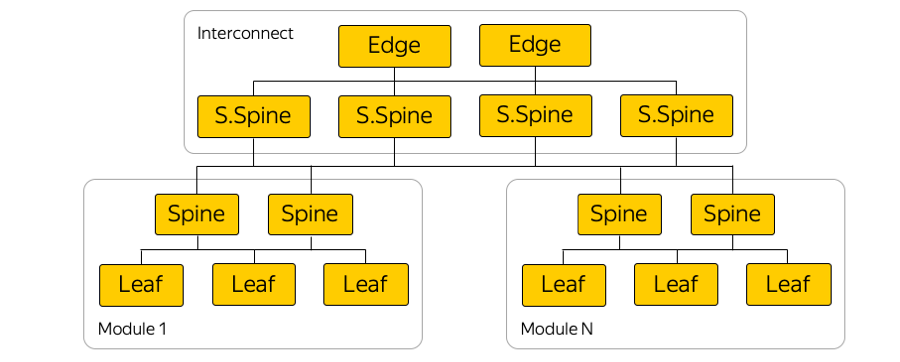
Di setiap zona ketersediaan ada sekitar lima modul, dan di setiap modul sekitar seratus rak. Sakelar yang dipasang di rak, terhubung ke modul mereka pada level Spine, dan konektivitas antar-modul disediakan melalui jaringan Interkoneksi. Ini adalah level berikutnya, yang mencakup apa yang disebut sakelar Super-Duri dan Tepi, yang sudah menghubungkan zona akses. Kami sengaja meninggalkan L2, kami hanya berbicara tentang konektivitas L3 IP / MPLS. BGP digunakan untuk mendistribusikan informasi routing.
Bahkan, ada banyak koneksi paralel daripada di gambar. Sejumlah besar koneksi ECMP (Equal-cost multi-path) memaksakan persyaratan pemantauan khusus. Selain itu, ada batas tak terduga, pada pandangan pertama, dalam peralatan - misalnya, jumlah kelompok ECMP.
Koneksi server
Karena investasi yang kuat, Yandex membangun layanan sedemikian rupa sehingga kegagalan satu server, rak server, modul atau bahkan seluruh pusat data tidak pernah mengarah pada penghentian layanan sepenuhnya. Jika kita memiliki masalah jaringan apa pun - misalkan sakelar pemasangan dilepas - pengguna eksternal tidak pernah melihat ini.
Yandex.Cloud adalah kasus khusus. Kami tidak dapat menentukan kepada klien bagaimana membangun layanannya sendiri, dan kami memutuskan untuk meratakan kemungkinan titik kegagalan ini. Oleh karena itu, semua server di Cloud terhubung ke dua sakelar pemasangan di rak.
Kami juga tidak menggunakan protokol redundansi di tingkat L2, tetapi segera mulai menggunakan hanya L3 dengan BGP - lagi, karena alasan penyatuan protokol. Koneksi ini memberikan setiap layanan dengan konektivitas IPv4 dan IPv6: beberapa layanan bekerja melalui IPv4, dan beberapa layanan melalui IPv6.
Secara fisik, setiap server terhubung oleh dua antarmuka 25-gigabit. Ini foto dari pusat data:

Di sini Anda melihat dua switch rack-mount dengan port 100-gigabit. Kabel breakout yang berbeda terlihat, membagi port 100-gigabit dari switch menjadi 4 port dengan 25 gigabit per server. Kami menyebutnya kabel ini "hydra".
Manajemen infrastruktur
Infrastruktur jaringan Cloud tidak mengandung solusi manajemen kepemilikan apa pun: semua sistem dapat berupa sumber terbuka dengan penyesuaian untuk Cloud, atau sepenuhnya ditulis sendiri.
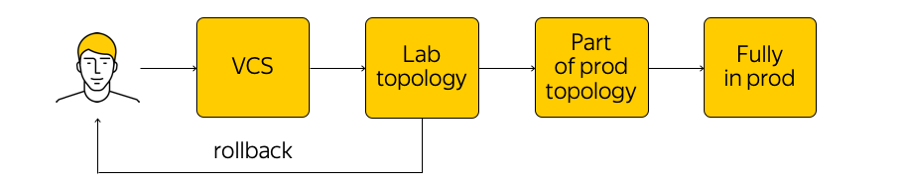
Bagaimana infrastruktur ini dikelola? Ini bukan yang terlarang di Cloud, tetapi sangat tidak disarankan untuk pergi ke perangkat jaringan dan melakukan penyesuaian apa pun. Ada keadaan sistem saat ini, dan kita perlu menerapkan perubahan: sampai pada keadaan target baru. “Jalankan skrip” melalui semua kelenjar, ubah sesuatu dalam konfigurasi - Anda sebaiknya tidak melakukan ini. Sebagai gantinya, kami membuat perubahan pada templat, ke satu sumber sistem kebenaran, dan melakukan perubahan pada sistem kontrol versi. Ini sangat mudah, karena Anda selalu dapat melakukan rollback, melihat sejarah, mencari tahu siapa yang bertanggung jawab atas komit, dll.
Ketika kami membuat perubahan, konfigurasi dibuat dan kami meluncurkannya ke topologi tes laboratorium. Dari perspektif jaringan, ini adalah awan kecil yang sepenuhnya mengulangi semua produksi yang ada. Kami akan segera melihat apakah perubahan yang diinginkan merusak sesuatu: pertama, dengan memonitor, dan kedua, dengan umpan balik dari pengguna internal kami.
Jika pemantauan mengatakan bahwa semuanya tenang, maka kami terus meluncurkan - tetapi menerapkan perubahan hanya pada bagian dari topologi (dua atau lebih aksesibilitas "tidak memiliki hak" untuk dipecahkan karena alasan yang sama). Selain itu, kami terus memantau dengan cermat. Ini adalah proses yang agak rumit, yang akan kita bicarakan di bawah ini.
Setelah memastikan semuanya baik-baik saja, kami menerapkan perubahan pada seluruh produksi. Kapan saja, Anda dapat memutar kembali dan kembali ke kondisi jaringan sebelumnya, dengan cepat melacak dan memperbaiki masalah.
Pemantauan
Kami membutuhkan pemantauan yang berbeda. Salah satu yang paling dicari adalah memonitor konektivitas end-to-end. Pada waktu tertentu, setiap server harus dapat berkomunikasi dengan server lain. Faktanya adalah jika ada masalah di suatu tempat, maka kami ingin mencari tahu di mana sedini mungkin (yaitu, server mana yang memiliki masalah mengakses satu sama lain). Memastikan konektivitas ujung ke ujung adalah perhatian utama kami.
Setiap server mendaftar satu set semua server yang dengannya ia dapat berkomunikasi pada waktu tertentu. Server mengambil subset acak dari set ini dan mengirimkan paket ICMP, TCP, dan UDP ke semua mesin yang dipilih. Ini memeriksa apakah ada kerugian pada jaringan, apakah penundaan telah meningkat, dll. Seluruh jaringan dipanggil dalam salah satu zona akses dan di antara mereka. Hasilnya dikirim ke sistem terpusat yang memvisualisasikannya untuk kami.
Beginilah hasilnya ketika semuanya tidak terlalu baik:
Di sini Anda dapat melihat segmen jaringan mana yang bermasalah antara (dalam hal ini, A dan B) dan di mana semuanya baik-baik saja (A dan D). Server tertentu, sakelar yang dipasang di rak, modul, dan seluruh zona ketersediaan dapat ditampilkan di sini. Jika salah satu di atas menjadi sumber masalah, kita akan melihatnya secara real time.
Selain itu, ada pemantauan acara. Kami memonitor dengan seksama semua koneksi, level sinyal pada transceiver, sesi BGP, dll. Misalkan tiga sesi BGP dibangun dari segmen jaringan, salah satunya terputus di malam hari. Jika kami mengatur pemantauan sehingga jatuhnya satu sesi BGP tidak penting bagi kami dan dapat menunggu sampai pagi, maka pemantauan tidak akan membangunkan insinyur jaringan. Tetapi jika sesi kedua dari tiga jatuh, seorang insinyur memanggil secara otomatis.
Selain pemantauan End-to-End dan acara, kami menggunakan koleksi log terpusat, analisis real-time dan analisis selanjutnya. Anda dapat melihat korelasinya, mengidentifikasi masalah dan mencari tahu apa yang terjadi pada peralatan jaringan.
Topik pemantauan cukup besar, ada ruang lingkup besar untuk perbaikan. Saya ingin membawa sistem ke otomatisasi yang lebih besar dan penyembuhan diri yang sejati.
Apa selanjutnya
Kami punya banyak rencana. Penting untuk meningkatkan sistem kontrol, pemantauan, pengalihan IP / pabrik MPLS dan banyak lagi.
Kami juga aktif mencari sakelar kotak putih. Ini adalah perangkat "besi" yang sudah jadi, sebuah sakelar tempat Anda dapat memutar perangkat lunak. Pertama, jika semuanya dilakukan dengan benar, akan mungkin untuk "memperlakukan" switch dengan cara yang sama seperti ke server, membangun proses CI / CD yang sangat nyaman, secara bertahap meluncurkan konfigurasi, dll.
Kedua, jika ada masalah, lebih baik membiarkan sekelompok insinyur dan pengembang yang akan memperbaiki masalah ini daripada menunggu waktu yang lama untuk perbaikan dari vendor.
Agar semuanya berjalan lancar, pekerjaan sedang berlangsung dalam dua arah:
- Kami secara signifikan mengurangi kompleksitas pabrik IP / MPLS. Di satu sisi, tingkat jaringan virtual dan alat otomatisasi dari ini, sebaliknya, menjadi sedikit lebih rumit. Di sisi lain, jaringan yang mendasari itu sendiri menjadi lebih mudah. Dengan kata lain, ada "jumlah" kompleksitas tertentu yang tidak dapat diselamatkan. Ini dapat "dilempar" dari satu level ke level lainnya - misalnya, antara level jaringan atau dari level jaringan ke level aplikasi. Dan Anda dapat mendistribusikan kompleksitas ini dengan benar, yang kami coba lakukan.
- Dan tentu saja, kami sedang menyelesaikan serangkaian alat kami untuk mengelola seluruh infrastruktur.
Ini semua yang ingin kami bicarakan tentang infrastruktur jaringan kami.
Berikut ini tautan ke saluran Cloud Telegram dengan berita dan kiat.