Artikel ini ditulis bersama dengan ananaskelly .
Pendahuluan
Halo semuanya, Habr! Bekerja di Pusat Teknologi Pidato di St. Petersburg, kami telah memperoleh sedikit pengalaman dalam memecahkan masalah klasifikasi dan deteksi peristiwa akustik dan memutuskan bahwa kami siap untuk membaginya dengan Anda. Tujuan artikel ini adalah untuk memperkenalkan Anda pada beberapa tugas dan berbicara tentang kontes pemrosesan suara otomatis DCASE 2018 . Memberitahu Anda tentang kontes, kami akan melakukannya tanpa formula dan definisi yang kompleks terkait dengan pembelajaran mesin, sehingga makna umum dari artikel tersebut akan dipahami oleh khalayak luas .
Bagi mereka yang tertarik dengan perakitan classifier , kami menyiapkan kode python kecil, dan dari tautan di github Anda dapat menemukan notebook di mana, dengan menggunakan lagu kedua dari kontes DCASE sebagai contoh, kami membuat jaringan konvolusional sederhana pada hard untuk mengklasifikasikan file audio. Di sana kami berbicara sedikit tentang jaringan dan fitur yang digunakan untuk pelatihan, dan bagaimana menggunakan arsitektur sederhana untuk mendapatkan hasil yang mendekati garis dasar ( MAP @ 3 = 0,6).
Selain itu, pendekatan dasar untuk memecahkan masalah (baseline) yang diusulkan oleh penyelenggara akan dijelaskan di sini. Juga di masa depan akan ada beberapa artikel di mana kita akan berbicara lebih terinci dan terinci baik tentang pengalaman kita dalam berpartisipasi dalam kompetisi dan tentang solusi yang diajukan oleh peserta lain dalam kompetisi. Tautan ke artikel-artikel ini secara bertahap akan muncul di sini.
Tentunya, banyak orang sama sekali tidak tahu tentang semacam "DCASE" , jadi mari kita cari tahu jenis buah apa itu dan dengan apa ia dimakan. Kompetisi " DCASE " diadakan setiap tahun, dan setiap tahun beberapa tugas dikhususkan untuk menyelesaikan masalah di bidang klasifikasi rekaman audio dan deteksi peristiwa akustik. Siapa pun dapat ikut serta dalam kompetisi, ini gratis, untuk ini cukup mendaftar di situs sebagai peserta. Sebagai hasil dari kompetisi, konferensi diadakan pada topik yang sama, tetapi, tidak seperti kompetisi itu sendiri, partisipasi di dalamnya sudah dibayar, dan kami tidak akan membicarakannya lagi. Hadiah untuk keputusan terbaik biasanya tidak diandalkan, tetapi ada pengecualian (misalnya, tugas ke-3 di 2018). Tahun ini, panitia mengusulkan 5 tugas berikut:
- Klasifikasi adegan akustik (dibagi menjadi 3 subtugas)
A. Pelatihan dan set data uji direkam pada perangkat yang sama
B. set pelatihan dan data uji direkam pada perangkat yang berbeda
C. Pelatihan diizinkan menggunakan data yang tidak disediakan oleh penyelenggara - Klasifikasi Acara Akustik
- Deteksi nyanyian burung
- Deteksi peristiwa akustik di rumah menggunakan set data yang berlabel lemah
- Klasifikasi aktivitas rumah tangga di ruangan menurut rekaman multi-channel
Tentang deteksi dan klasifikasi
Seperti yang dapat kita lihat, nama-nama semua tugas mengandung satu dari dua kata: "deteksi" atau "klasifikasi". Mari kita perjelas apa perbedaan antara konsep-konsep ini sehingga tidak ada kebingungan.
Bayangkan kita memiliki rekaman audio di mana seekor anjing menggonggong pada suatu saat, dan seekor kucing mengeong di waktu lain, dan tidak ada kejadian lain di sana. Maka jika kita ingin memahami dengan tepat kapan peristiwa ini terjadi, maka kita perlu menyelesaikan masalah pendeteksian peristiwa akustik. Artinya, kita perlu mengetahui waktu mulai dan berakhir untuk setiap acara. Setelah memecahkan masalah pendeteksian, kami mencari tahu kapan tepatnya peristiwa itu terjadi, tetapi kami tidak tahu siapa yang membuat bunyi ditemukan - maka kami perlu menyelesaikan masalah klasifikasi, yaitu, untuk menentukan apa yang sebenarnya terjadi dalam periode waktu tertentu.
Untuk memahami deskripsi tugas kompetisi, contoh-contoh ini akan cukup, yang berarti bahwa bagian pengantar selesai, dan kita dapat melanjutkan ke deskripsi rinci tentang tugas itu sendiri.
Track 1. Klasifikasi Adegan Akustik
Tugas pertama adalah menentukan lingkungan (adegan akustik) di mana audio direkam, misalnya, "Stasiun Metro", "Bandara" atau "Pedestrian Street". Solusi untuk masalah ini dapat bermanfaat dalam menilai lingkungan dengan sistem kecerdasan buatan, misalnya, pada mobil dengan autopilot.
Dalam tugas ini, TUT Urban Acoustic Scenes 2018 dan TUT Urban Acoustic Scenes 2018 Dataset seluler, yang disiapkan oleh Universitas Teknologi Tampere (Finlandia), disajikan untuk pelatihan. Deskripsi terperinci tentang persiapan dataset, serta solusi dasar, dijelaskan dalam artikel .
Secara total, 10 adegan akustik disajikan untuk kompetisi, yang harus diprediksi para peserta.
Subtask A
Seperti yang sudah kami katakan, tugas dibagi menjadi 3 subtugas, yang masing-masing berbeda dalam kualitas rekaman audio. Misalnya, dalam subtugas A, mikrofon khusus digunakan untuk merekam, yang terletak di telinga manusia. Dengan demikian, rekaman stereo dibuat lebih dekat dengan persepsi manusia tentang suara. Peserta diberi kesempatan untuk menggunakan pendekatan ini untuk merekam dalam rangka meningkatkan kualitas pengakuan adegan akustik.
Subtask B
Di subtask B, perangkat lain (misalnya, ponsel) juga digunakan untuk merekam. Data dari subtask A dikonversi ke format mono, frekuensi sampling dikurangi, tidak ada simulasi "audibilitas" suara oleh seseorang dalam kumpulan data untuk tugas ini, tetapi ada lebih banyak data untuk pelatihan.
Subtask C
Kumpulan data untuk subtugas C sama dengan subtugas A, tetapi dalam menyelesaikan masalah ini diizinkan menggunakan data eksternal apa pun yang dapat ditemukan peserta. Tujuan pemecahan masalah ini adalah untuk mengetahui apakah mungkin untuk meningkatkan hasil yang diperoleh dalam subtugas A dengan menggunakan data pihak ketiga.
Kualitas keputusan di trek ini dievaluasi oleh metrik Akurasi .
Dasar untuk tugas ini adalah jaringan saraf convolutional dua lapis yang belajar dari logaritma spektogram kecil dari data audio asli. Arsitektur yang diusulkan menggunakan teknik BatchNormalisasi dan Dropout standar. Kode pada GitHub dapat dilihat di sini .
Track 2. Klasifikasi Acara Akustik
Dalam tugas ini, diusulkan untuk membuat sistem yang mengklasifikasikan peristiwa akustik. Sistem semacam itu dapat menjadi tambahan bagi rumah pintar, meningkatkan keamanan di tempat-tempat ramai, atau membuat hidup lebih mudah bagi orang-orang dengan gangguan pendengaran.
Dataset untuk tugas ini terdiri dari file yang diambil dari dataset Freesound dan ditandai menggunakan tag dari AudioSet Google. Secara lebih rinci, proses mempersiapkan dataset dijelaskan oleh sebuah artikel yang disiapkan oleh penyelenggara kontes.
Mari kita kembali ke tugas itu sendiri, yang memiliki beberapa fitur.
Pertama, para peserta harus membuat model yang mampu mengidentifikasi perbedaan antara peristiwa akustik yang sangat berbeda. Kumpulan data dibagi menjadi kelas 41, menyajikan berbagai alat musik, suara yang dibuat oleh manusia, hewan, suara rumah tangga dan banyak lagi.
Kedua, selain markup data yang biasa, ada juga informasi tambahan tentang memeriksa label secara manual. Artinya, peserta tahu file mana dari kumpulan data yang diperiksa oleh orang tersebut untuk kepatuhan dengan label, dan mana yang tidak. Seperti yang telah ditunjukkan oleh praktik, para peserta yang entah bagaimana menggunakan informasi tambahan ini mengambil hadiah dalam menyelesaikan masalah ini.
Selain itu, harus dikatakan bahwa durasi catatan dalam kumpulan data sangat bervariasi: dari 0,3 detik hingga 30 detik. Dalam masalah ini, jumlah data per kelas, di mana model perlu dilatih, juga sangat bervariasi. Ini paling baik digambarkan sebagai histogram, kode untuk membangun yang diambil dari sini .
Seperti yang dapat Anda lihat dari histogram, markup manual untuk kelas yang disajikan juga tidak seimbang, yang menambah kesulitan jika Anda ingin menggunakan informasi ini saat melatih model.
Hasil di trek ini dievaluasi menggunakan metrik akurasi rata-rata (Mean Mean Precision, MAP @ 3), demonstrasi yang cukup sederhana untuk menghitung metrik ini dengan contoh dan kode dapat ditemukan di sini .
Track 3. Deteksi nyanyian burung
Lagu berikutnya adalah deteksi kicau burung. Masalah serupa muncul, misalnya, dalam berbagai sistem pemantauan otomatis satwa liar - ini adalah langkah pertama dalam memproses data sebelumnya, misalnya, klasifikasi. Sistem seperti itu sering membutuhkan penyetelan, tidak stabil pada kondisi akustik baru, sehingga tujuan trek ini adalah untuk memanggil kekuatan pembelajaran mesin untuk menyelesaikan masalah tersebut.
Lagu ini adalah versi lanjutan dari kontes “Bird Audio Detection challenge” yang diselenggarakan oleh St Mary's University of London pada 2017/2018. Bagi yang berminat , Anda dapat membaca artikel dari penulis kompetisi, yang memberikan rincian tentang pembentukan data, organisasi kompetisi itu sendiri dan analisis keputusan yang dibuat.
Namun, kembali ke tugas DCASE. Panitia menyediakan enam set data - tiga untuk pelatihan, tiga untuk pengujian - mereka semua sangat berbeda - direkam dalam kondisi akustik yang berbeda, menggunakan berbagai perangkat rekaman, dengan latar belakang ada berbagai suara. Dengan demikian, pesan utamanya adalah bahwa model tersebut tidak harus bergantung pada lingkungan atau mampu beradaptasi dengannya. Terlepas dari kenyataan bahwa namanya berarti "deteksi", tugasnya bukan untuk menentukan batas-batas acara, tetapi dalam klasifikasi sederhana - solusi terakhir adalah semacam classifier biner yang menerima entri audio pendek dan memutuskan apakah ada nyanyian burung di sana atau tidak. . Metrik AUC digunakan untuk mengevaluasi akurasi.
Sebagian besar peserta mencoba untuk mencapai generalisasi dan adaptasi melalui berbagai augmentasi data. Salah satu perintah menjelaskan penerapan berbagai teknik - mengubah resolusi frekuensi dalam fitur yang diekstraksi, pengurangan kebisingan awal, metode adaptasi berdasarkan penyelarasan statistik orde dua untuk set data yang berbeda. Namun, metode tersebut, serta berbagai jenis augmentasi, memberikan peningkatan yang sangat kecil atas solusi dasar, seperti dicatat oleh banyak peserta.
Sebagai solusi dasar, penulis menyiapkan modifikasi solusi paling sukses dari kompetisi “Bird Audio Detection challenge” yang asli. Kode, seperti biasa, tersedia di github .
Track 4. Deteksi kejadian akustik di rumah menggunakan set data yang berlabel lemah.
Di trek keempat, masalah deteksi sudah dipecahkan secara langsung. Para peserta diberikan dataset data tag yang relatif kecil - total 1578 rekaman audio masing-masing 10 detik, dengan hanya penandaan kelas: diketahui bahwa file tersebut berisi satu atau lebih peristiwa dari kelas-kelas ini, tetapi tidak ada markup sementara. Selain itu, dua set data besar dari data yang tidak terisi disediakan - 14412 file berisi target acara dari kelas yang sama seperti dalam pelatihan dan sampel uji, serta 39999 file berisi peristiwa sewenang-wenang yang tidak termasuk dalam target. Semua data adalah bagian dari dataset audio besar yang dikompilasi oleh google .
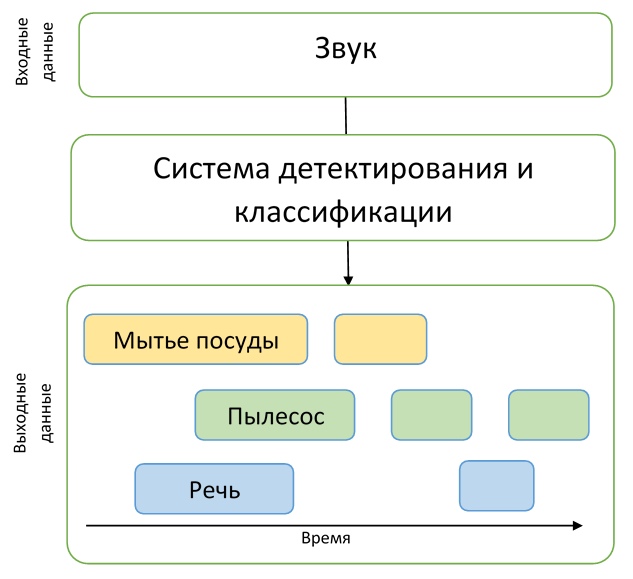
Dengan demikian, para peserta perlu membuat model yang mampu belajar dari data yang berlabel lemah untuk menemukan cap waktu awal dan akhir acara (acara dapat tumpang tindih), dan mencoba memperbaikinya dengan sejumlah besar data tambahan yang tidak ditandai. Selain itu, perlu dicatat bahwa metrik yang cukup kaku digunakan di trek ini - perlu diprediksi label waktu peristiwa dengan akurasi 200 ms. Secara umum, para peserta harus menyelesaikan tugas yang agak sulit untuk menciptakan model yang memadai, sementara secara praktis tidak memiliki data yang baik untuk pelatihan.
Sebagian besar solusi didasarkan pada jaringan perulangan konvolusional - arsitektur yang cukup populer di bidang pendeteksian peristiwa akustik baru-baru ini (contohnya dapat dibaca di sini ).
Solusi dasar dari penulis, juga pada jaringan rekursif konvolusional, didasarkan pada dua model. Model memiliki arsitektur yang hampir sama: tiga lapisan konvolusional dan satu rekursif. Satu-satunya perbedaan adalah jaringan output. Model pertama dilatih untuk menandai data yang tidak terisi untuk memperluas dataset asli - dengan demikian, pada output kami memiliki kelas hadir dalam file acara. Yang kedua adalah untuk memecahkan masalah deteksi secara langsung, yaitu, pada output kita mendapatkan penandaan sementara untuk file. Kode untuk tautan .
Track 5. Klasifikasi aktivitas rumah tangga di ruangan menurut rekaman multi-saluran.
Lagu terakhir berbeda dari yang lain terutama dalam hal para peserta ditawari rekaman multi-saluran. Tugas itu sendiri ada di klasifikasi: perlu untuk memprediksi kelas peristiwa yang terjadi pada catatan. Berbeda dengan trek sebelumnya, tugasnya agak sederhana - diketahui bahwa hanya ada satu peristiwa dalam catatan.
Dataset diwakili oleh sekitar 200 jam rekaman pada susunan mikrofon linier 4 mikrofon. Acara adalah semua jenis kegiatan sehari-hari - memasak, mencuci piring, kegiatan sosial (berbicara di telepon, mengunjungi dan percakapan pribadi), dll., Juga kelas ketidakhadiran acara apa pun yang disorot.
Para penulis trek menekankan bahwa kondisi tugas relatif sederhana sehingga para peserta fokus langsung pada penggunaan informasi spasial dari rekaman multichannel. Peserta juga diberi kesempatan untuk menggunakan data tambahan dan model pra-pelatihan. Kualitas dievaluasi sesuai dengan ukuran F1.
Sebagai solusi dasar, penulis trek mengusulkan jaringan konvolusional sederhana dengan dua lapisan konvolusional. Dalam solusi mereka, informasi spasial tidak digunakan - data dari empat mikrofon digunakan untuk pelatihan secara mandiri, dan prediksi dirata-rata selama pengujian. Deskripsi dan kode tersedia di tautan .
Kesimpulan
Dalam artikel tersebut, kami mencoba untuk secara singkat berbicara tentang pendeteksian peristiwa akustik dan tentang persaingan seperti DCASE. Mungkin mereka dapat menarik minat seseorang untuk berpartisipasi dalam 2019 - kompetisi dimulai pada bulan Maret.