Halo, Habr!
Pada bulan Desember, kolega kami dari Advanced Analytics, Leonid Sherstyuk, memenangkan tempat pertama dalam kompetensi Pembelajaran Mesin dan Data Besar dalam kejuaraan industri II DigitalSkills. Ini adalah cabang "digital" dari kontes profesional terkenal yang diselenggarakan oleh WorldSkills Rusia. Secara total, lebih dari 200 orang ambil bagian dalam kejuaraan, berkompetisi untuk kepemimpinan dalam 25 kompetensi digital - Perlindungan Korporat terhadap Ancaman Keamanan Internal, Pemasaran Internet, Pengembangan Game Komputer dan Aplikasi Multimedia, Teknologi Quantum, Internet of Things, Desain Industri, dll.

Sebagai kasus untuk Pembelajaran Mesin, tugas diusulkan untuk memantau dan mendeteksi cacat pada jaringan pipa pembangkit listrik tenaga nuklir, jaringan pipa minyak dan gas menggunakan sistem pengujian ultrasonik semi-otomatis.
Leonid akan menceritakan tentang apa yang ada di kompetisi dan bagaimana dia berhasil menang di bawah cut.
WorldSkills adalah organisasi internasional yang menyelenggarakan kontes keterampilan profesional di seluruh dunia. Secara tradisional, perwakilan dari perusahaan industri dan mahasiswa dari universitas terkait berpartisipasi dalam kompetisi ini, menunjukkan keahlian mereka dalam spesialisasi kerja. Baru-baru ini, nominasi digital telah mulai muncul di kompetisi, di mana spesialis muda bersaing dalam keterampilan robotika, pengembangan aplikasi, keamanan informasi, dan dalam profesi lain yang Anda bahkan tidak dapat memanggil pekerja. Dalam salah satu nominasi ini - untuk Pembelajaran Mesin dan bekerja dengan data besar - saya berkompetisi di Kazan di kontes DigitalSkills, yang diadakan di bawah naungan WS.
Karena kompetensi untuk kompetisi baru, sulit bagi saya untuk membayangkan apa yang diharapkan. Untuk berjaga-jaga, saya mengulangi semua yang saya tahu tentang bekerja dengan database dan komputasi terdistribusi, metrik dan algoritma pelatihan, kriteria statistik dan metode preprocessing. Menjadi terbiasa dengan perkiraan kriteria evaluasi, saya tidak mengerti bagaimana mungkin untuk menyesuaikan pekerjaan penuh dengan Hadoop dan membuat bot obrolan dalam 6 sesi singkat.
Seluruh kompetisi berlangsung 3 hari, lebih dari 6 sesi. Setiap sesi adalah 3 jam dengan istirahat, di mana Anda harus menyelesaikan beberapa tugas yang saling terkait secara bermakna. Pada awalnya, mungkin tampaknya waktu sudah cukup, tetapi pada kenyataannya butuh langkah panik untuk berhasil melakukan segala sesuatu yang dikandung.
Di kompetisi, diharapkan tidak diharapkan bekerja dengan data besar, dan seluruh kumpulan tugas dikurangi untuk menganalisis kumpulan data terbatas.
Bahkan, kami diminta mengulangi jalur dari salah satu penyelenggara, tempat pelanggan datang dengan masalah dan data mereka, dan dari siapa mereka mengharapkan penawaran komersial dalam beberapa minggu.
Kami bekerja dengan data PUZK (sistem kontrol ultrasonik semi-otomatis). Sistem ini dirancang untuk memeriksa sambungan dan kerusakan pada pipa. Instalasi itu sendiri berjalan di sepanjang rel yang dipasang pada pipa, dan pada setiap langkah melakukan 16 pengukuran. Dalam kondisi ideal dan tanpa cacat, beberapa sensor harus memberikan sinyal maksimum, yang lain - nol; pada kenyataannya, data sangat bising, dan menjawab pertanyaan apakah ada cacat di tempat tertentu menjadi tugas yang tidak sepele.
 Pemasangan sistem PUZK
Pemasangan sistem PUZKHari pertama dikhususkan untuk mengenal data, membersihkannya, menyusun statistik deskriptif. Kami diberi informasi latar belakang minimal tentang pemasangan dan jenis sensor yang dipasang pada perangkat. Selain preprocessing data, kami harus menetapkan jenis sensor apa dan bagaimana mereka berada pada perangkat.
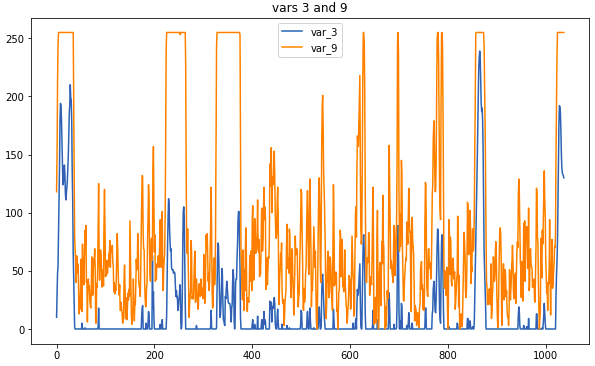 Sampel data: ini adalah bagaimana sensor terkait terlihat
Sampel data: ini adalah bagaimana sensor terkait terlihatOperasi pra-pemrosesan utama adalah mengganti pengukuran dengan rata-rata bergerak. Jika jendela terlalu besar, ada risiko kehilangan terlalu banyak informasi, tetapi korelasi yang membantu menentukan jenisnya akan lebih visual. Beberapa koneksi terlihat tanpa preprocessing; Namun, tidak ada waktu untuk memeriksa data mentah dengan hati-hati, sehingga penggunaan file korelasi sangat diperlukan.
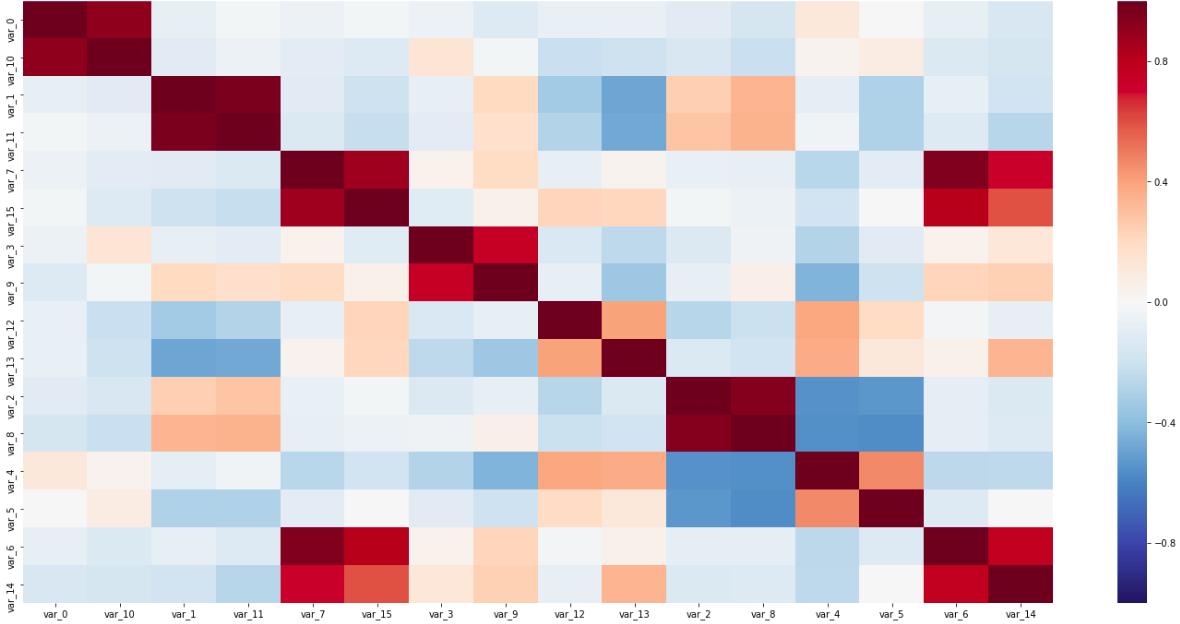 Matriks korelasi
Matriks korelasiPada matriks ini, kedua pasangan sensor sepanjang diagonal, saling berhubungan erat satu sama lain, dan variabel yang berkorelasi terbalik terlihat; Semua ini membantu menentukan jenis sensor.
Item wajib terakhir adalah untuk mengurangi sensor menjadi satu koordinat. Karena alat pengukur secara signifikan lebih dari satu langkah pengukuran, dan sensor ditempatkan di seluruh perangkat, ini merupakan langkah wajib sebelum menggunakan data lebih lanjut untuk pelatihan.
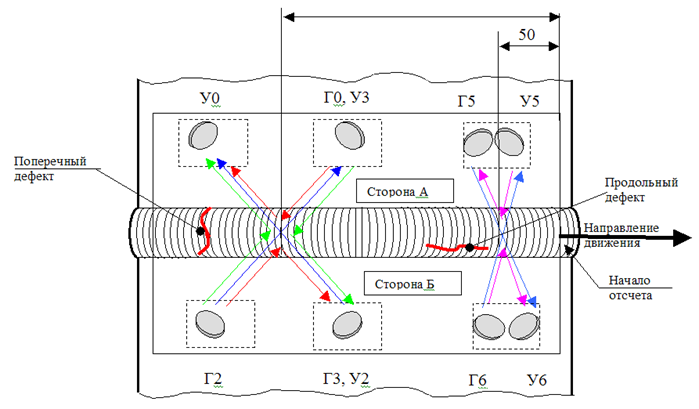
\
Pengaturan sensor pada instalasiDiagram pemasangan sensor pada perangkat menunjukkan bahwa kita perlu menemukan jarak antara ketiga kelompok sensor. Cara termudah dan tercepat di sini adalah menentukan segmen perangkat mana yang harus dihidupkan setiap sensor, dan kemudian mencari korelasi maksimum, menggeser bagian pengukuran dengan langkah.
Tahap ini diperumit oleh fakta bahwa asumsi saya tentang tipe sensor tidak dijamin, jadi saya harus melihat semua korelasi, tipe, skema, dan menghubungkan ini ke dalam satu sistem yang konsisten.
Untuk hari kedua, kami harus menyiapkan data untuk pelatihan dan melakukan pengelompokan pada poin, dan kemudian membangun classifier.
Selama persiapan data, saya menghapus pembacaan yang terlalu korelatif, dan sebagai fitur sintetis saya menambahkan moving average, turunan dan skor-z. Tidak diragukan lagi, sintesis variabel baru dapat dimainkan cukup luas, tetapi waktu memaksakan keterbatasannya.
Clustering dapat membantu memisahkan titik-titik cacat dari orang lain. Saya mencoba 3 metode: k-means, Birch dan DBScan, tetapi, sayangnya, tidak ada yang memberikan hasil yang baik.
Untuk algoritme prediktif, kami diberi kebebasan penuh; hanya format yang harus diperoleh pada output yang ditentukan. Algoritme seharusnya menyediakan tabel (atau data yang dapat direduksi ke dalamnya), di mana baris berhubungan dengan satu celah, dan ke kolom karakteristiknya (seperti panjang, lebar, jenis dan sisi). Bagi saya, itu pilihan paling sederhana, di mana kami membuat prediksi untuk setiap titik sampel uji, dan kemudian menggabungkan yang tetangga menjadi satu celah. Sebagai hasilnya, saya membuat 3 pengklasifikasi yang menjawab pertanyaan-pertanyaan berikut: di sisi mana jahitannya cacat, seberapa dalam kelanjutannya, dan tipe apa yang dimiliki (longitudinal atau transversal).
Di sini, kedalaman yang harus diprediksi oleh regresi sangat mencolok; Namun, dalam sampel yang ditandai, saya hanya menemukan 5 kedalaman unik, jadi saya menemukan penyederhanaan ini dapat diterima.
 Metrik Evaluasi Algoritma
Metrik Evaluasi AlgoritmaDari semua algoritma (saya berhasil mencoba regresi logistik, pohon yang menentukan, dan meningkatkan gradien), meningkatkan, seperti yang diharapkan, melakukan yang terbaik. Metrik tidak diragukan lagi sangat menyenangkan, tetapi agak sulit untuk mengevaluasi operasi algoritma tanpa hasil dalam set pengujian yang baru. Panitia tidak pernah kembali dengan metrik tertentu, membatasi diri pada komentar umum bahwa tidak ada yang melakukan tes serta pada sampel yang tertunda.
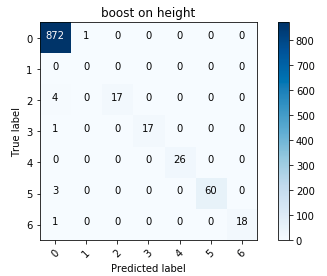 Matriks kesalahan untuk meningkatkan
Matriks kesalahan untuk meningkatkanSecara umum, saya senang dengan hasilnya; khususnya, mengurangi ketinggian menjadi variabel kategori terbayar.
Selama hari terakhir, kami harus membungkus algoritma terlatih dalam suatu produk yang dapat digunakan oleh pelanggan potensial, dan menyiapkan presentasi solusi siap-perusahaan kami.
Di sini, perfeksionisme membantu saya dalam menulis kode yang relatif bersih, yang tidak hilang bahkan dalam waktu yang terbatas. Dari potongan kode yang sudah jadi, prototipe berkembang dengan cepat, dan saya punya waktu untuk men-debug kesalahan. Berbeda dengan tahap sebelumnya, di sini kinerja solusi memainkan peran yang lebih penting, daripada memenuhi kriteria formal.
 Produk Jadi - CLI Utility
Produk Jadi - CLI UtilityMenjelang akhir sesi, saya mendapat utilitas CLI yang menerima folder sumber sebagai input dan mengembalikan tabel dengan hasil prediksi dalam bentuk yang nyaman bagi teknolog.
Pada tahap akhir, saya diberi kesempatan untuk berbicara tentang kesuksesan saya dan melihat apa yang peserta lain datangi. Bahkan di bawah kriteria ketat, keputusan kami sangat berbeda - seseorang berhasil berkerumun, yang lain terampil menggunakan metode linier. Selama presentasi, para kontestan menekankan kekuatan mereka - beberapa melakukan penjualan produk, yang lain lebih tenggelam dalam detail teknis; Ada grafis yang indah dan antarmuka solusi adaptif.
 Keuntungan utama dari solusi saya pas pada satu slide
Keuntungan utama dari solusi saya pas pada satu slideBagaimana dengan kompetisi secara umum?
Kompetisi jenis ini adalah peluang besar untuk mengetahui seberapa cepat Anda dapat melakukan tugas-tugas khas spesialisasi Anda. Kriteria dirancang sedemikian rupa sehingga orang yang mendapatkan hasil terbaik (seperti yang terjadi, misalnya, pada Kaggle) mendapat poin terbanyak, tetapi siapa yang paling mungkin melakukan operasi yang tipikal pekerjaan harian di industri. Menurut pendapat saya, partisipasi dan kemenangan dalam kompetisi semacam itu dapat memberi tahu calon pemberi kerja tidak kurang dari pengalaman di industri ini, di hackathons dan Kaggle.
Lenonid Sherstyuk,
Analis Data, Analisis Lanjut, SIBUR