Dalam proyek saya sebelumnya, kami dihadapkan dengan tugas melakukan geocoding
terbalik untuk banyak pasangan koordinat geografis. Reverse geocoding adalah prosedur yang cocok dengan pasangan garis lintang-bujur dengan alamat atau nama objek pada peta yang titik atau koordinatnya milik atau tutup. Yaitu, kita ambil koordinatnya, katakan ini: @ 55.7602485,37.6170409, dan kita mendapatkan hasilnya baik "Rusia, Distrik Federal Pusat, Moskow, Teater Square, rumah begini", atau misalnya, "Teater Bolshoi".
Jika alamat atau nama ada di input, dan koordinat ada di output, maka operasi ini adalah
geocoding langsung , kami berharap untuk membicarakannya nanti.
Sebagai input, kami memiliki sekitar 100 atau 200 ribu poin pada input yang terletak di cluster Hadoop sebagai tabel Hive. Ini untuk memperjelas skala tugas.
Spark akhirnya dipilih sebagai alat pemrosesan, meskipun dalam prosesnya kami mencoba MapReduce dan Apache Crunch. Tetapi ini adalah cerita yang terpisah, mungkin layak untuk posnya.
Solusi mudah dengan cara yang terjangkau
Untuk memulainya, kami mencoba untuk mendekati masalah, sehingga untuk berbicara. Sebagai alat, ada server ArcGIS yang menyediakan layanan REST geocoding terbalik. Menggunakannya cukup sederhana, untuk ini kami melakukan permintaan http GET dengan URL berikut:
http://-url/GeocodeServer/reverseGeocode?<>
Dari banyak parameter, itu cukup untuk mengatur lokasi = x, y (yang utama adalah tidak membingungkan yang mana dari mereka adalah garis lintang dan mana yang garis bujur;). Dan sekarang kita sudah memiliki JSON dengan hasil: negara, wilayah, kota, jalan, nomor rumah. Contoh dari dokumentasi:
{ "address": { "Match_addr": "Beeman's Redlands Pharmacy", "LongLabel": "Beeman's Redlands Pharmacy, 255 Terracina Blvd, Redlands, CA, 92373, USA", "ShortLabel": "Beeman's Redlands Pharmacy", "Addr_type": "POI", "Type": "Pharmacy", "PlaceName": "Beeman's Redlands Pharmacy", "AddNum": "255", "Address": "255 Terracina Blvd", "Block": "", "Sector": "", "Neighborhood": "South Redlands", "District": "", "City": "Redlands", "MetroArea": "Inland Empire", "Subregion": "San Bernardino County", "Region": "California", "Territory": "", "Postal": "92373", "PostalExt": "", "CountryCode": "USA" }, "location": { "x": -117.20558993392585, "y": 34.037880040538894, "spatialReference": { "wkid": 4326, "latestWkid": 4326 } } }
Anda juga dapat menunjukkan jenis jawaban apa yang kami inginkan - alamat pos, atau mengatakan POI (tempat tujuan, ini untuk mendapatkan jawaban seperti "Teater Bolshoi"), atau apakah kita memerlukan persimpangan jalan, misalnya. Anda juga dapat menentukan radius di mana objek bernama akan dicari dari titik yang ditentukan.
Untuk memeriksa kualitas respons dengan cepat, Anda dapat memperkirakan jarak antara titik awal dalam parameter permintaan dan lokasi titik yang diterima dalam respons layanan.
Tampaknya sekarang semuanya akan baik-baik saja. Tapi itu dia. Contoh ArcGIS kami sangat lambat, server dialokasikan 4 core, dan sekitar 8 gigabytes RAM. Sebagai hasilnya, tugas pada cluster dapat membaca 200 ribu poin kami dengan sangat cepat, tetapi bertumpu pada kinerja REST dan ArcGIS. Dan geocoding semua poin butuh berjam-jam. Pada saat yang sama, kami mengalokasikan hanya sekitar 8 core pada Hadoop, dan sedikit memori, tetapi karena memuat server ArcGIS hampir mencapai 100% selama berjam-jam, sumber daya tambahan di cluster tidak memberi kami apa pun.
ArcGIS tidak tahu bagaimana melakukan operasi geocoding batch terbalik, sehingga permintaan dieksekusi sekali untuk setiap titik. Dan omong-omong, jika layanan tidak merespons, maka kami jatuh karena batas waktu atau dengan kesalahan, dan apa yang harus dilakukan dengan itu adalah masalah dengan jawaban yang tidak jelas. Mungkin mencoba lagi, atau menyelesaikan seluruh proses, dan kemudian ulangi untuk poin mentah.
Perkiraan kedua, kami memperkenalkan cache
Untuk memulainya, kami menemukan bahwa banyak titik di set kami memiliki koordinat berulang. Alasannya sederhana - jelas, akurasi GPS tidak cukup baik untuk koordinat titik yang terletak dua meter dari satu sama lain untuk berbeda pada output, atau koordinat yang diperoleh bukan dari GPS, tetapi dari pangkalan lain, cukup dimasukkan ke dalam basis data sumber. Secara umum, tidak masalah mengapa demikian, yang utama adalah bahwa ini adalah situasi yang sangat khas, sehingga cache hasil yang diterima dari layanan akan memungkinkan Anda untuk melakukan geocode setiap pasangan koordinat hanya sekali. Dan kita bisa membeli memori untuk cache.
Sebenarnya, modifikasi pertama dari algoritma dibuat sepele - semua hasil yang diperoleh dari REST ditambahkan ke cache, dan untuk semua poin, pencarian pertama kali dilakukan untuk koordinat di dalamnya. Kami bahkan tidak mulai membuat cache umum untuk semua proses percikan - pada setiap node cluster yang dimilikinya.
Sedemikian sederhananya, kami dapat memperoleh akselerasi hingga sekitar 10 kali, yang secara kasar sesuai dengan jumlah pengulangan koordinat dalam set aslinya. Sudah bisa diterima, tetapi masih sangat lambat.
Nah, pelanggan kami memberi tahu kami saat ini, jika kami tidak dapat mengetahui alamat dengan lebih cepat, dapatkah kami dengan cepat mengidentifikasi setidaknya sebuah kota? Dan kami mengambil ...
Solusi yang disederhanakan, mengimplementasikan Geomerty API
Apa yang harus kita definisikan sebagai kota? Kami memiliki geometri wilayah Rusia, divisi administrasi-teritorial, yang kira-kira akurat untuk distrik-distrik kota.
Anda dapat mengambil data ini misalnya di
sini . Ada apa disana Ini adalah basis data batas administratif Federasi Rusia, untuk level dari 2 (negara) hingga 9 (distrik perkotaan). Formatnya adalah geojson atau CSV (sedangkan geometri itu sendiri dalam format wkt). Secara total, database sekitar 20 ribu catatan.
Solusi baru yang disederhanakan untuk masalah tampak seperti ini:
- Mengunggah data ADT ke Hive.
- Untuk setiap titik dengan koordinat, kita lihat di tabel pembagian wilayah untuk poligon tempat titik ini masuk.
- Urutkan poligon yang ditemukan berdasarkan level.
Sebagai hasilnya, kita mendapatkan sesuatu seperti: Rusia, Distrik Federal Pusat, Moskow, distrik administratif ini dan itu, area ini dan itu, yaitu, daftar wilayah di mana titik kami berada.
Pemuatan ADT
Untuk mengunduh CSV lebih mudah, kami menggunakan
layang-layang . Alat ini dapat dengan baik membangun skema untuk Hive berdasarkan header kolom di CSV. Bahkan, impor turun menjadi tiga perintah (salah satunya diulang untuk setiap file level):
kite-tools csv-schema admin_level_2.csv --class al --delimiter \; >adminLevel.avrs kite-tools create dataset:hive:/default/levelswkt -s adminLevel.avrs kite-tools csv-import admin_level_2.csv dataset:hive:/default/levelswkt --delimiter \; ... kite-tools csv-import admin_level_10.csv dataset:hive:/default/levelswkt --delimiter \;
Apa yang sudah kita lakukan di sini? Tim pertama membuatkan skema Avro untuk csv, yang kami tentukan beberapa parameter skema (kelas, dalam hal ini), dan pemisah bidang untuk CSV. Selanjutnya, ada baiknya melihat diagram yang diperoleh dengan mata Anda, dan dimungkinkan untuk melakukan beberapa perbaikan, karena Kite tidak melihat semua baris file kami, tetapi hanya pada beberapa sampel, sehingga terkadang dapat membuat asumsi yang salah tentang tipe data (saya melihat tiga angka - saya memutuskan bahwa kolom angka, dan kemudian pergi baris).
Nah, kemudian berdasarkan skema, kami membuat dataset (ini adalah istilah umum Layang-layang, menggeneralisasi tabel di Hive, tabel di HBase, dan yang lainnya). Dalam hal ini, default adalah database (untuk Hive itu sama dengan skema), dan levelswkt adalah nama tabel kami.
Nah, perintah terbaru mengunggah file CSV ke dataset kami. Setelah unduhan selesai dengan sukses, Anda sudah dapat menyelesaikan permintaan:
select * from levelswkt;
suatu tempat di rona.
Bekerja dengan geometri
Untuk bekerja dengan geometri di Jawa, kami memilih Esri
Java Geometry API (pengembang ArcGIS). Pada prinsipnya, dimungkinkan untuk mengambil kerangka kerja lain, ada beberapa pilihan Open Source, misalnya,
Suite Topologi JTS yang dikenal luas, atau
Geotools .
Tugas pertama memungkinkan kita untuk mengatasi kerangka kerja lain dari perusahaan Esri yang sama, yang disebut
Kerangka Tata Ruang untuk Hadoop , dan berdasarkan yang pertama. Sebenarnya, kita memerlukan SerDe dari itu, modul serialisasi-deserialisasi untuk Hive, yang memungkinkan kita untuk menyajikan banyak file geojson sebagai tabel di Hive, kolom yang diambil dari atribut geojson. Dan geometri itu sendiri menjadi kolom lain (dengan data biner). Sebagai hasilnya, kami memiliki tabel, salah satu kolom di antaranya adalah geometri wilayah tertentu, dan sisanya adalah atributnya (nama, level dalam ADT, dll.). Tabel ini tersedia untuk aplikasi Spark.
Jika kita memuat basis data dalam format CSV, maka kita memiliki kolom di mana geometri berada dalam bentuk teks, dalam format
WKT . Dalam hal ini, Spark dapat membuat objek geometri saat runtime menggunakan API Geometri.
Kami memilih format CSV (dan WKT), karena satu alasan sederhana - seperti yang diketahui semua orang, Rusia menempati peta area dengan koordinat Chukotka di luar 180 meridian. Format geojson memiliki batasan - semua poligon di dalamnya harus dibatasi hingga 180 derajat, dan yang melintasi meridian 180 harus dipotong menjadi dua bagian di sepanjang itu. Akibatnya, saat mengimpor geometri ke API Geometri, kami mendapatkan objek yang API Geometri salah mendefinisikan Kotak Bounding (melampirkan persegi panjang) untuk perbatasan Rusia. Ternyata jawabannya adalah -180.180 dalam bujur. Yang tentu saja tidak benar - pada kenyataannya, Rusia membutuhkan sekitar 20 hingga -170 derajat. Ini adalah masalah API Geometri; hari ini mungkin sudah diperbaiki, tetapi kami harus mengatasinya.
WKT tidak memiliki masalah seperti itu. Anda mungkin bertanya, mengapa kita membutuhkan Bounding Box? Maka saya akan memberitahu;)
Masih untuk memecahkan apa yang disebut masalah PIP, tunjuk poligon. Java Geometry API dapat melakukannya lagi, bagi kami itu sederhana, satu geometri tipe Point, poligon kedua (Multipoligon) untuk wilayah tersebut, dan satu berisi metode.
Akibatnya, solusi kedua, dan juga di dahi, tampak seperti ini: Aplikasi Spark memuat ADT, termasuk geometri. Sesuatu seperti Map name-> geometry dibangun dari mereka (sebenarnya sedikit lebih rumit, karena ADT bersarang di dalam satu sama lain, dan kami hanya perlu mencari di level yang lebih rendah yang termasuk dalam yang sudah ditemukan. Akibatnya, ada semacam pohon geometri yang menurut sumbernya data masih perlu dibangun). Dan kemudian kita membangun Spark Dataset dengan poin kita, dan untuk setiap titik kita menerapkan UDF kita sendiri, yang memeriksa entri titik ke semua geometri (di pohon).
Menulis versi baru membutuhkan waktu sekitar satu hari kerja, karena Kerangka Spasial untuk bundel Hadoop menyertakan contoh-contoh bagus secara langsung untuk menyelesaikan tugas PIP (walaupun, menggunakan beberapa cara lain).
Kami mulai, dan ... oh, horor, sesuatu tidak menjadi lebih cepat. Tonton lagi. Sudah waktunya untuk berpikir tentang optimasi.
Solusi yang Efisien, QuadTree
Alasan rem cukup jelas - katakanlah, geometri Rusia, mis. batas eksternal, ini adalah megabyte geojson, poligon besar, dan bukan satu. Jika Anda ingat bagaimana masalah PIP diselesaikan, maka salah satu metode yang terkenal adalah membangun sinar dari suatu titik, mengatakan di suatu tempat hingga tak terhingga, dan menentukan berapa banyak titik yang memotong poligon. Jika jumlah titiknya genap, titiknya di luar poligon, jika ganjil, ia ada di dalam.
Berikut deskripsi
dari wiki .

Jelas bahwa untuk poligon besar, solusi untuk masalah persimpangan rumit sebanyak yang ada garis lurus dalam poligon kami. Oleh karena itu, diinginkan untuk entah bagaimana membuang poligon-poligon yang tidak dapat dimasuki titik tersebut. Dan sebagai peretas tambahan, dimungkinkan untuk menjatuhkan cek untuk masuk ke perbatasan Rusia (jika kita tahu bahwa semua koordinat jelas termasuk di dalamnya).
Untuk ini,
pohon kuadran cocok untuk kita. Untungnya, implementasinya semuanya dalam API Geometri yang sama (dan banyak lagi).

Solusi berbasis pohon terlihat seperti ini:
- Memuat ATD Geometri
- Untuk masing-masing geometri kita mendefinisikan sebuah persegi panjang terlampir
- Kami memasukkannya ke QuadTree, kami mendapatkan indeks sebagai respons
- indeks diingat
Selanjutnya, saat memproses poin:
- Kami bertanya QuadTree mana dari geometri yang diketahuinya mungkin termasuk titik
- Dapatkan indeks geometri
- Hanya untuk mereka, kami memeriksa kejadian dengan memecahkan masalah PIP
Ini semua membutuhkan empat jam untuk berkembang. Kami mulai lagi, dan kami melihat bahwa tugas itu selesai dengan sangat cepat. Kami memeriksa - semuanya baik-baik saja, solusinya diterima. Dan itu semua dalam beberapa menit. QuadTree memberi kami beberapa kali akselerasi besar.
Ringkasan
Jadi apa yang akhirnya kita lakukan? Kami mendapat mekanisme geocoding terbalik yang secara paralel melakukan paralel pada Hadoop cluster, dan yang memecahkan masalah awal kami dengan 200 ribu poin dalam sekitar satu menit. Yaitu kita dapat dengan mudah menerapkan solusi ini ke jutaan poin.
Apa keterbatasan dari solusi ini? Pertama, yang jelas - ini didasarkan pada data ADT yang tersedia bagi kami, yang a) mungkin tidak relevan b) terbatas hanya untuk Rusia.
Dan yang kedua - kita tidak dapat menyelesaikan masalah geocoding terbalik untuk objek selain poligon tertutup. Dan itu berarti - untuk jalanan juga.
Pengembangan
Apa yang bisa dilakukan dengan ini?
Untuk memiliki geometri ADT saat ini, hal yang paling sederhana adalah mendapatkannya dari OpenStreetMap. Tentu saja, mereka harus bekerja sedikit, tetapi ini adalah tugas yang sepenuhnya dapat dipecahkan. Jika ada minat, saya akan berbicara tentang tugas memuat data OpenStreetMap ke cluster Hadoop lain kali.
Apa yang bisa dilakukan untuk jalanan dan rumah? Pada prinsipnya, jalanan di OSM yang sama. Tapi ini bukan struktur tertutup, tetapi garis. Untuk menentukan bahwa titik tersebut "dekat" dengan jalan tertentu, Anda harus membuat poligon untuk jalan dari titik yang sama jauhnya dari itu, dan memeriksa apakah itu masuk ke dalamnya. Akibatnya, semacam sosis ternyata ... terlihat seperti ini:
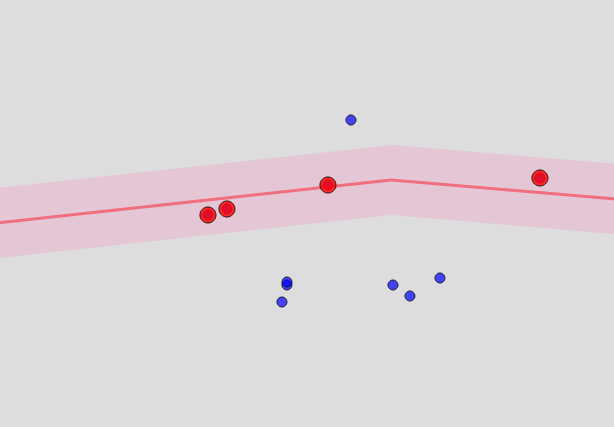
Seberapa dekat intinya? Ini adalah parameter, dan kira-kira sesuai dengan radius di mana ArcGIS mencari objek, yang saya sebutkan di awal.
Jadi kita menemukan jalan yang jaraknya dari titik kurang dari batas tertentu (katakanlah, 100 meter). Dan semakin kecil batas ini, semakin cepat algoritma bekerja, tetapi semakin besar kemungkinan Anda tidak akan menemukan kecocokan tunggal.
Masalah yang jelas adalah bahwa tidak mungkin untuk menghitung buffer yang disebut sebelumnya - ukurannya adalah parameter layanan. Mereka perlu dibangun dengan cepat, setelah kami mengidentifikasi area kota yang diinginkan, dan memilih dari pangkalan OSM jalan-jalan yang melewati area ini. Jalan-jalan, bagaimanapun, dapat dipilih terlebih dahulu.
Rumah-rumah yang ada di daerah yang ditemukan juga tidak bergerak ke mana-mana, sehingga daftar mereka dapat dibangun di muka - tetapi masuk ke mereka masih harus dipertimbangkan dengan cepat.
Artinya, Anda harus terlebih dahulu membangun indeks dari bentuk "distrik kota" -> daftar rumah dengan tautan ke geometri, dan yang serupa untuk daftar jalan.
Dan segera setelah kami mengidentifikasi daerah tersebut, kami mendapatkan daftar rumah dan jalan, kami membangun di sepanjang jalan-jalan perbatasan, dan hanya untuk mereka kami menyelesaikan masalah PIP (mungkin menggunakan optimasi yang sama seperti untuk perbatasan daerah). Pohon kuadran untuk rumah dalam hal ini, jelas, juga dapat dibangun di muka, dan disimpan di suatu tempat.
Tujuan utama kami adalah untuk meminimalkan jumlah perhitungan, sambil memaksimalkan dan mempertahankan semua yang dapat dihitung dan disimpan terlebih dahulu. Dalam hal ini, proses akan terdiri dari tahap lambat membangun indeks, dan tahap kedua perhitungan, yang sudah akan berlangsung cepat, dekat dengan versi online.