Di artikel sebelumnya, mereka sudah menulis tentang cara kerja teknologi pengenalan teks kami:
Hingga 2018, pengenalan karakter Jepang dan Cina diatur dengan cara yang sama: terutama menggunakan pengklasifikasi raster dan fitur. Tetapi dengan pengakuan hieroglif ada kesulitan:
- Sejumlah besar kelas yang perlu dibedakan.
- Karakter perangkat yang lebih kompleks secara keseluruhan.

Sama sulitnya untuk mengatakan dengan pasti berapa banyak karakter yang ditulis dalam alfabet China, sebagaimana akurat untuk menghitung berapa banyak kata dalam bahasa Rusia. Tetapi paling sering dalam tulisan China ~ 10.000 karakter digunakan. Dengan mereka, kami membatasi jumlah kelas yang digunakan dalam pengakuan.
Kedua masalah yang dijelaskan di atas juga mengarah pada fakta bahwa untuk mencapai kualitas tinggi Anda harus menggunakan sejumlah besar fitur dan fitur-fitur ini sendiri dihitung pada gambar karakter lebih lama.
Agar masalah ini tidak menyebabkan perlambatan parah di seluruh sistem pengenalan, saya harus menggunakan banyak heuristik, terutama bertujuan untuk dengan cepat memotong sejumlah besar hieroglif, yang tidak terlihat seperti gambar ini. Masih tidak membantu sampai akhir, tetapi kami ingin membawa teknologi kami ke tingkat yang sama sekali baru.
Kami mulai mempelajari penerapan jaringan saraf convolutional untuk meningkatkan kualitas dan kecepatan pengakuan hieroglif. Saya ingin mengganti seluruh unit karena mengenali satu karakter untuk bahasa-bahasa ini dengan bantuan jaringan saraf. Dalam artikel ini, kami akan menjelaskan bagaimana kami akhirnya berhasil.
Pendekatan sederhana: satu jaringan konvolusi untuk mengenali semua hieroglif
Secara umum, penggunaan jaringan konvolusional untuk pengenalan karakter bukanlah ide baru sama sekali.
Secara historis, mereka digunakan untuk
pertama kalinya tepatnya untuk tugas ini pada tahun 1998. Benar, maka ini bukan karakter yang dicetak, tetapi huruf dan angka bahasa Inggris tulisan tangan.
Lebih dari 20 tahun, teknologi di bidang pembelajaran yang dalam, tentu saja, telah melompat maju. Termasuk arsitektur yang lebih maju dan pendekatan baru untuk belajar.
Arsitektur yang disajikan dalam diagram di atas (LeNet), pada kenyataannya, dan hari ini sangat cocok untuk tugas-tugas sederhana seperti pengenalan teks cetak. "Sederhana" Saya menyebutnya dibandingkan dengan tugas-tugas lain dari visi komputer seperti pencarian dan pengenalan wajah.
Tampaknya solusinya tidak ada yang lebih sederhana. Kami mengambil jaringan saraf, contoh hieroglif berlabel dan melatihnya untuk masalah klasifikasi. Sayangnya, ternyata semuanya tidak begitu sederhana. Semua kemungkinan modifikasi LeNet untuk tugas mengklasifikasikan 10.000 hieroglif tidak memberikan kualitas yang memadai (setidaknya sebanding dengan sistem pengakuan yang sudah kita miliki).
Untuk mencapai kualitas yang diperlukan, kami harus mempertimbangkan arsitektur yang lebih dalam dan lebih kompleks: WideResNet, SqueezeNet, dll. Dengan bantuan mereka, dimungkinkan untuk mencapai tingkat kualitas yang diperlukan, tetapi mereka memberikan penurunan kecepatan yang kuat - 3-5 kali dibandingkan dengan algoritma dasar pada CPU.
Seseorang mungkin bertanya: "Apa gunanya mengukur kecepatan jaringan pada CPU, jika bekerja lebih cepat pada prosesor grafis (GPU)"? Di sini perlu dibuat komentar mengenai fakta bahwa kecepatan algoritma pada CPU terutama penting bagi kita. Kami sedang mengembangkan teknologi untuk lini besar produk pengenalan ABBYY. Dalam sejumlah skenario terbesar, pengakuan dilakukan di sisi klien, dan kita tidak bisa tahu bahwa itu memiliki GPU.
Jadi, pada akhirnya, kami sampai pada masalah berikut: satu jaringan saraf untuk mengenali semua karakter tergantung pada pilihan karya arsitektur yang terlalu buruk atau terlalu lambat.
Model pengenalan hieroglif jaringan saraf dua tingkat
Saya harus mencari cara lain. Pada saat yang sama, saya tidak ingin meninggalkan jaringan saraf. Tampaknya masalah terbesar adalah sejumlah besar kelas, karena itu diperlukan untuk membangun jaringan arsitektur yang kompleks. Oleh karena itu, kami memutuskan bahwa kami tidak akan melatih jaringan untuk sejumlah besar kelas, yaitu untuk seluruh alfabet, tetapi sebaliknya kami akan melatih banyak jaringan untuk sejumlah kecil kelas (himpunan bagian dari alfabet).
Secara umum, sistem yang ideal disajikan sebagai berikut: alfabet dibagi menjadi kelompok-kelompok dengan karakter yang sama. Jaringan tingkat pertama mengklasifikasikan grup karakter mana yang diberikan gambar. Untuk setiap kelompok, pada gilirannya, jaringan tingkat kedua dilatih, yang menghasilkan klasifikasi akhir dalam setiap kelompok.
Gambar yang dapat diklik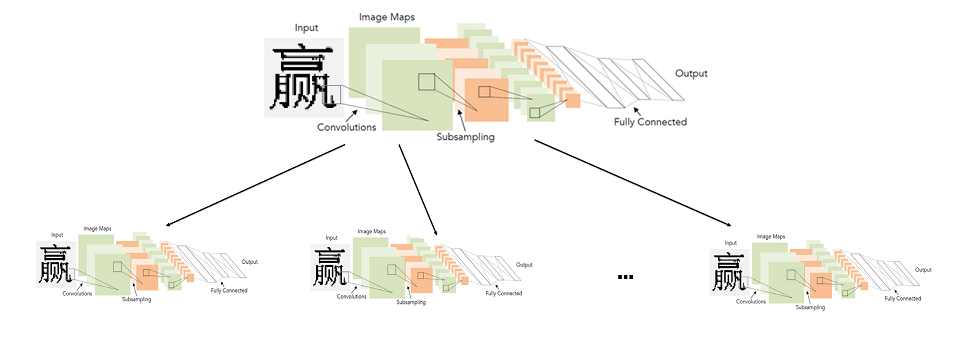
Jadi, kami membuat klasifikasi akhir dengan meluncurkan dua jaringan: yang pertama menentukan jaringan tingkat kedua mana yang akan diluncurkan, dan yang kedua sudah membuat klasifikasi akhir.
Sebenarnya, poin mendasar di sini adalah bagaimana membagi karakter ke dalam kelompok-kelompok sehingga jaringan tingkat pertama dapat dibuat akurat dan cepat.
Membangun classifier tingkat pertama
Untuk memahami simbol jaringan mana yang lebih mudah dibedakan dan mana yang lebih sulit, paling mudah untuk melihat tanda apa yang menonjol untuk simbol tertentu. Untuk melakukan ini, kami mengambil jaringan classifier dilatih untuk membedakan semua karakter alfabet dengan kualitas yang baik dan melihat statistik aktivasi lapisan kedua dari belakang jaringan ini - kami mulai melihat representasi fitur akhir yang diterima jaringan untuk semua karakter.
Pada saat yang sama, kami tahu bahwa gambar harus ada sesuatu seperti berikut ini:
Ini adalah contoh sederhana untuk kasus pengelompokan pilihan digit tulisan tangan (MNIST) ke dalam 10 kelas. Pada lapisan tersembunyi kedua dari belakang, yang berjalan sebelum klasifikasi, hanya ada 2 neuron, yang membuat statistik aktivasi mereka mudah untuk ditampilkan di pesawat. Setiap titik pada grafik sesuai dengan beberapa contoh dari sampel uji. Warna titik sesuai dengan kelas tertentu.
Dalam kasus kami, dimensi ruang fitur lebih besar dari 128 dalam contoh. Kami menjalankan sekelompok gambar dari sampel uji dan menerima vektor fitur untuk setiap gambar. Setelah itu, mereka dinormalisasi (dibagi panjangnya). Dari gambar di atas jelas mengapa ini layak dilakukan. Kami mengelompokkan vektor yang dinormalisasi dengan metode KMeans. Kami mendapat pengelompokan sampel ke dalam kelompok gambar yang serupa (dari sudut pandang jaringan).
Tetapi pada akhirnya, kami perlu membuat partisi alfabet ke dalam kelompok, dan bukan partisi dari sampel uji. Tetapi yang pertama dari yang kedua tidak sulit diperoleh: cukup untuk menetapkan setiap label kelas ke kluster yang berisi sebagian besar gambar kelas ini. Dalam kebanyakan situasi, tentu saja, seluruh kelas bahkan akan berakhir di dalam satu cluster.
Yah, itu saja, kami mendapat partisi dari seluruh alfabet menjadi kelompok-kelompok karakter yang sama. Maka tetaplah memilih arsitektur yang sederhana dan melatih classifier untuk membedakan antara kelompok-kelompok ini.
Berikut ini adalah contoh dari 6 grup acak yang diperoleh dengan membagi seluruh alfabet sumber menjadi 500 cluster:
Konstruksi pengklasifikasi tingkat kedua
Selanjutnya, Anda perlu memutuskan karakter target mana yang akan dipelajari oleh pengklasifikasi tingkat kedua. Jawabannya tampaknya jelas - ini harus berupa kelompok karakter yang diperoleh pada langkah sebelumnya. Ini akan berhasil, tetapi tidak selalu dengan kualitas yang baik.
Faktanya adalah bahwa pengklasifikasi tingkat pertama membuat kesalahan dalam hal apa pun dan mereka dapat diimbangi sebagian oleh konstruksi set tingkat kedua sebagai berikut:
- Kami memperbaiki sampel gambar simbol tertentu yang terpisah (tidak berpartisipasi baik dalam pelatihan atau dalam pengujian);
- Kami menjalankan sampel ini melalui classifier tingkat pertama yang terlatih, menandai setiap gambar dengan label classifier ini (label grup);
- Untuk setiap simbol, kami mempertimbangkan semua grup yang memungkinkan yang menjadi pengelompokan tingkat pertama milik gambar simbol ini;
- Tambahkan simbol ini ke semua grup hingga tingkat cakupan yang diperlukan T_acc tercapai;
- Kami menganggap kelompok simbol terakhir sebagai kelompok sasaran tingkat kedua, yang akan dilatihkan oleh pengklasifikasi.
Sebagai contoh, gambar simbol "A" ditugaskan oleh classifier tingkat pertama 980 kali ke grup 5, 19 kali ke grup 2 dan 1 kali ke grup 6. Secara total kami memiliki 1000 gambar simbol ini.
Kemudian kita bisa menambahkan simbol "A" ke grup ke-5 dan mendapatkan cakupan 98% dari simbol ini. Kami dapat mengaitkannya dengan grup 5 dan 2 dan mendapatkan cakupan 99,9%. Dan kita dapat langsung mengaitkannya dengan grup (5, 2, 6) dan mendapatkan cakupan 100%.
Intinya, T_acc mengatur keseimbangan antara kecepatan dan kualitas. Semakin tinggi, semakin tinggi kualitas akhir dari klasifikasi, tetapi semakin besar akan menjadi set target level kedua dan semakin sulit klasifikasi di level kedua.
Praktek menunjukkan bahwa bahkan dengan T_acc = 1, peningkatan ukuran set sebagai akibat dari prosedur pengisian ulang yang dijelaskan di atas tidak begitu signifikan - rata-rata, sekitar 2 kali. Jelas, ini akan secara langsung tergantung pada kualitas classifier tingkat pertama yang terlatih.
Berikut adalah contoh bagaimana penyelesaian ini bekerja untuk salah satu set dari partisi yang sama menjadi 500 grup, yang lebih tinggi:
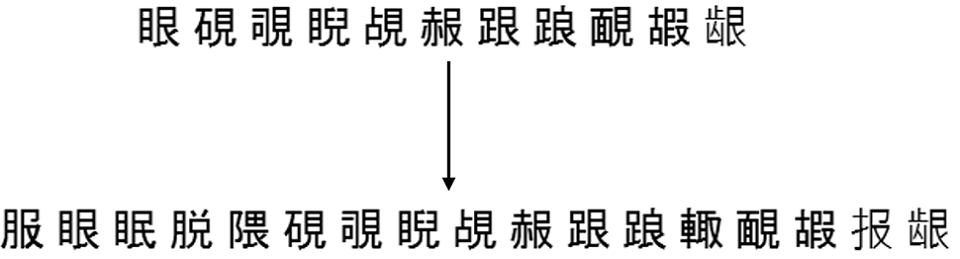
Hasil embed model
Model dua tingkat yang terlatih akhirnya bekerja lebih cepat dan lebih baik daripada pengklasifikasi yang digunakan sebelumnya. Sebenarnya, tidak mudah untuk "berteman" dengan grafik pembagian linier yang sama (GLD). Untuk melakukan ini, kami harus secara terpisah mengajarkan model untuk membedakan karakter dari kesalahan apriori dan segmentasi garis (mengembalikan kepercayaan rendah dalam situasi ini).
Hasil akhir dari penyisipan ke dalam algoritma pengenalan dokumen lengkap di bawah ini (diperoleh pada kumpulan dokumen Cina dan Jepang), kecepatan ditunjukkan untuk algoritme lengkap:
Kami meningkatkan kualitas dan mempercepat baik dalam mode normal dan cepat, sambil mentransfer semua pengenalan karakter ke jaringan saraf.
Sedikit tentang pengakuan ujung ke ujung
Sampai saat ini, sebagian besar sistem OCR yang diketahui secara publik (Tesseract yang sama dari Google) menggunakan arsitektur jaringan saraf End-to-End untuk mengenali string atau fragmen mereka secara keseluruhan. Tapi di sini kami menggunakan jaringan saraf justru sebagai pengganti modul pengenalan karakter tunggal. Ini bukan kecelakaan.
Faktanya adalah bahwa segmentasi string menjadi karakter dalam cetak Cina dan Jepang bukan masalah besar karena pencetakan
monospace . Dalam hal ini, penggunaan pengenalan End-to-End untuk bahasa-bahasa ini tidak banyak meningkatkan kualitas, tetapi jauh lebih lambat (setidaknya pada CPU). Secara umum, tidak jelas bagaimana menggunakan pendekatan dua tingkat yang diusulkan dalam konteks End-to-End.
Sebaliknya, ada bahasa yang pembagian linier menjadi karakter adalah masalah utama. Contoh-contoh eksplisit adalah bahasa Arab, Hindi. Untuk bahasa Arab, misalnya, solusi End-to-End sudah dipelajari secara aktif bersama kami. Tetapi ini adalah kisah yang sangat berbeda.
Alexey Zhuravlev, Kepala Grup Teknologi Baru OCR