
Jaringan sosial adalah salah satu produk Internet paling populer saat ini dan salah satu sumber data utama untuk dianalisis. Di dalam jejaring sosial itu sendiri, tugas yang paling sulit dan menarik di bidang ilmu data dianggap sebagai pembentukan feed berita. Memang, untuk memenuhi meningkatnya permintaan pengguna akan kualitas dan relevansi konten, perlu untuk belajar bagaimana mengumpulkan informasi dari banyak sumber, menghitung perkiraan reaksi pengguna dan menyeimbangkan antara puluhan metrik yang bersaing dalam tes A / B. Dan sejumlah besar data, beban kerja tinggi, dan persyaratan ketat untuk kecepatan respons membuat tugas ini semakin menarik.
Tampaknya hari ini tugas pemeringkatan telah dipelajari terus menerus, tetapi jika Anda perhatikan dengan seksama, itu tidak begitu sederhana. Konten dalam umpan sangat heterogen - ini adalah foto teman, dan memo, video viral, bacaan panjang, dan pop ilmiah. Untuk menggabungkan semuanya, Anda membutuhkan pengetahuan dari berbagai bidang: visi komputer, bekerja dengan teks, sistem rekomendasi, dan, tanpa gagal, penyimpanan modern dan alat pemrosesan data. Menemukan satu orang dengan semua keterampilan sangat sulit hari ini, jadi menyortir rekaman itu benar-benar tugas tim.
Odnoklassniki mulai bereksperimen dengan berbagai algoritma peringkat pita pada tahun 2012, dan pada tahun 2014, pembelajaran mesin juga bergabung dengan proses ini. Ini dimungkinkan, pertama-tama, berkat kemajuan di bidang teknologi untuk bekerja dengan aliran data. Baru saja mulai mengumpulkan tampilan objek dan atributnya di
Kafka dan mengumpulkan log menggunakan
Samza , kami dapat membangun dataset untuk model pelatihan dan
menghitung fitur yang paling "menarik" : Klik Through Rate objek dan prakiraan sistem rekomendasi "berdasarkan"
karya rekan-rekan dari LinkedIn .

Dengan cepat menjadi jelas bahwa pekerja keras dari regresi logistik tidak dapat mengambil rekaman itu sendiri, karena pengguna dapat memiliki reaksi yang sangat beragam: kelas, komentar, klik, bersembunyi, dll, dan isinya bisa sangat berbeda - foto seorang teman, sebuah posting grup, atau sebuah vidosik yang ditulis oleh seorang teman. Setiap reaksi untuk setiap jenis konten memiliki kekhususan dan nilai bisnisnya sendiri. Akibatnya, kami sampai pada konsep "
matriks regresi logistik ": model terpisah dibangun untuk setiap jenis konten dan setiap reaksi, dan kemudian ramalan mereka dikalikan dengan matriks bobot yang dibentuk oleh tangan berdasarkan prioritas bisnis saat ini.
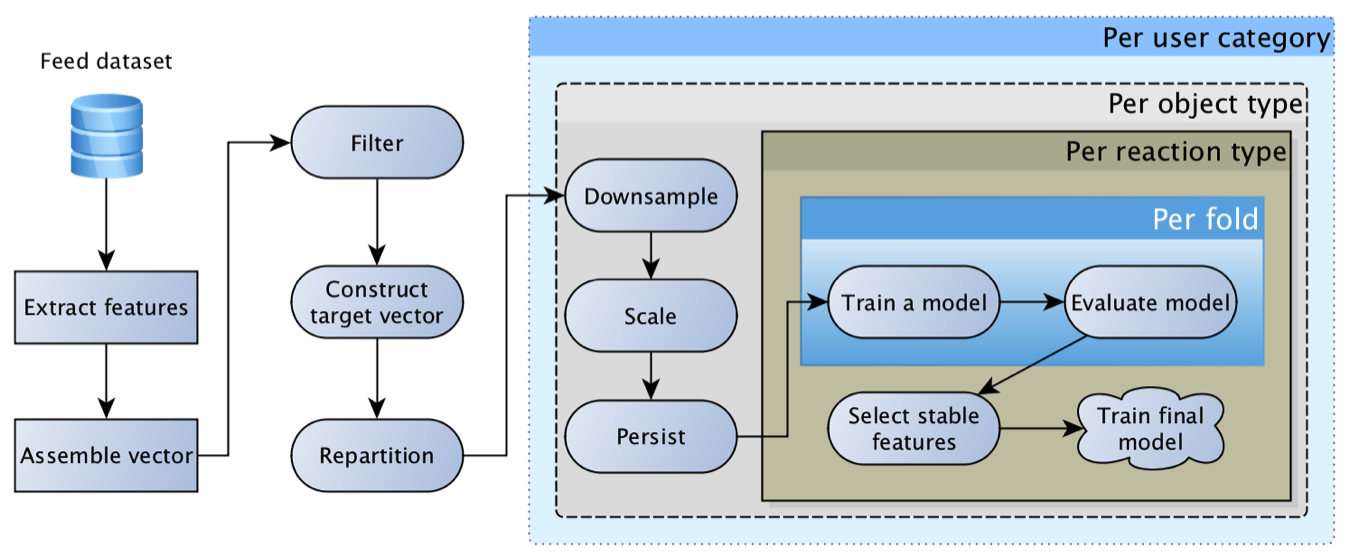
Model ini sangat layak dan untuk waktu yang lama adalah yang utama. Seiring waktu, itu memperoleh fitur yang lebih dan lebih menarik: untuk objek, untuk pengguna, untuk penulis, untuk hubungan pengguna dengan penulis, bagi mereka yang berinteraksi dengan objek, dll. Akibatnya, upaya pertama untuk mengganti regresi dengan jaringan saraf berakhir dengan "fitur yang kita miliki terlalu jelek, mesh tidak memberikan dorongan."
Dalam hal ini, sering kali dorongan paling nyata dari sudut pandang aktivitas pengguna diberikan oleh peningkatan teknis daripada algoritmik: ambil lebih banyak kandidat untuk pemeringkatan, lebih akurat melacak fakta-fakta dari pertunjukan, mengoptimalkan kecepatan respons algoritma, memperdalam riwayat penelusuran. Perbaikan semacam itu sering menghasilkan unit, dan kadang-kadang bahkan peningkatan aktivitas puluhan persen, sementara memperbarui model dan menambahkan fitur sering kali memberikan persepuluh peningkatan persen.

Kesulitan terpisah dalam percobaan dengan memperbarui model adalah menciptakan penyeimbangan kembali konten - distribusi prakiraan model "baru" sering berbeda secara signifikan dari pendahulunya, yang menyebabkan redistribusi lalu lintas dan umpan balik. Akibatnya, sulit untuk menilai kualitas model baru, karena pertama-tama Anda perlu mengkalibrasi keseimbangan konten (ulangi proses pengaturan bobot matriks untuk tujuan bisnis). Setelah mempelajari
pengalaman rekan-rekan dari Facebook , kami menyadari bahwa model
perlu dikalibrasi , dan regresi isotonik ditambahkan di atas regresi logistik :).
Seringkali dalam proses mempersiapkan atribut konten baru, kami mengalami frustrasi - model sederhana menggunakan teknik kolaboratif dasar dapat memberikan 80%, atau bahkan 90% dari hasilnya, sementara jaringan saraf yang modis, dilatih selama seminggu pada GPU super mahal, dengan sempurna mendeteksi kucing dan mobil, tetapi memberikan peningkatan metrik hanya di digit ketiga. Efek serupa sering terlihat ketika menerapkan model tematik, fastText, dan embeddings lainnya. Kami berhasil mengatasi frustrasi dengan melihat validasi dari sudut kanan: kinerja algoritma kolaboratif meningkat secara signifikan ketika informasi tentang objek terakumulasi, sedangkan untuk objek "segar" atribut konten memberikan dorongan nyata.
Tetapi, tentu saja, suatu hari nanti hasil dari regresi logistik harus ditingkatkan, dan kemajuan dicapai dengan menerapkan
XGBoost-Spark yang baru dirilis. Integrasi
itu tidak mudah , tetapi pada akhirnya, model akhirnya menjadi modis dan awet muda, dan metrik tumbuh dengan persen.
Tentunya, jauh lebih banyak pengetahuan dapat diekstraksi dari data dan peringkat rekaman itu dapat dibawa ke ketinggian baru - dan hari ini setiap orang memiliki kesempatan untuk mencoba tangan mereka pada tugas non-sepele ini di kompetisi
SNA Hackathon 2019 . Kompetisi berlangsung dalam dua tahap: dari 7 Februari hingga 15 Maret, unduh solusinya ke salah satu dari tiga tugas. Setelah 15 Maret, hasil antara akan disimpulkan, dan 15 orang dari papan peringkat teratas untuk setiap tugas akan menerima undangan ke tahap kedua, yang akan diadakan mulai 30 Maret hingga 1 April di kantor Moskwa Group Mail.ru di Moskow. Selain itu, undangan ke tahap kedua akan menerima tiga orang yang memimpin peringkat pada akhir 23 Februari.
Mengapa ada tiga tugas? Sebagai bagian dari fase online, kami menawarkan tiga set data, yang masing-masing hanya menyajikan satu aspek: gambar, teks, atau informasi tentang berbagai atribut kolaboratif. Dan hanya pada tahap kedua, ketika para pakar di berbagai bidang berkumpul, barulah dataset umum akan terungkap, memungkinkan Anda menemukan poin untuk sinergi berbagai metode.
Tertarik pada suatu tugas? Bergabunglah dengan
SNA Hackathon :)