Bill Kennedy mengatakan dalam sebuah kuliah tentang
program pemrograman Ultimate Go yang luar biasa:
Banyak pengembang berusaha untuk mengoptimalkan kode mereka. Mereka mengambil garis dan menulis ulang, mengatakan bahwa ini akan menjadi lebih cepat. Perlu berhenti. Mengatakan bahwa kode ini atau itu lebih cepat hanya mungkin setelah diprofilkan dan dibuat tolok ukur. Bercerita bukanlah pendekatan yang tepat untuk menulis kode.
Saya sudah lama ingin menunjukkan dengan contoh praktis bagaimana ini bisa berhasil. Dan beberapa hari yang lalu, perhatian saya tertuju pada kode berikut, yang bisa digunakan sebagai contoh:
builds := store.Instance.GetBuildsFromNumberToNumber(stageBuild.BuildNumber, lastBuild.BuildNumber) tempList := model.BuildsList{} for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchURLs = b.ReversePatchURLs b.ExtractedSize = b.RPatchExtractedSize tempList = append(tempList, b) }
Di sini, di semua elemen slice
build yang dikembalikan dari database,
PatchURL digantikan oleh
ReversePatchURLs ,
ExtractedSize oleh
RPatchExtractedSize dan membalikkan dilakukan - urutan elemen diubah sehingga elemen terakhir menjadi yang pertama dan yang terakhir terakhir.
Menurut pendapat saya, kode sumber agak rumit untuk dibaca dan dapat dioptimalkan. Kode ini melakukan algoritma sederhana yang terdiri dari dua bagian logis: mengubah elemen slice dan menyortir. Tetapi bagi programmer untuk mengisolasi dua komponen ini, itu akan memakan waktu.
Terlepas dari kenyataan bahwa kedua bagian itu penting, kode terbalik tidak ditekankan seperti yang kita inginkan. Ini tersebar di sepanjang tiga garis yang terkoyak: menginisialisasi irisan baru, mengiris irisan yang ada dalam urutan terbalik, menambahkan elemen ke ujung irisan baru. Namun demikian, seseorang tidak dapat mengabaikan keuntungan yang tidak diragukan dari kode ini: kode ini berfungsi dan diuji, dan berbicara secara objektif, itu cukup memadai. Persepsi subyektif dari kode oleh pengembang individu tidak bisa menjadi alasan untuk menulis ulang. Sayangnya atau untungnya, kami tidak menulis ulang kode hanya karena kami tidak menyukainya (atau, seperti yang sering terjadi, hanya karena itu bukan milik kami, lihat
cacat fatal ).
Tetapi bagaimana jika kita berhasil tidak hanya meningkatkan persepsi kode, tetapi juga mempercepatnya secara signifikan? Ini masalah yang sangat berbeda. Anda dapat menawarkan beberapa algoritma alternatif yang menjalankan fungsi yang tertanam dalam kode.
Opsi pertama: iterasi semua elemen dalam
rentang lingkaran; Untuk membalikkan irisan asli di setiap iterasi, tambahkan elemen ke awal array akhir. Jadi kita bisa menghilangkan kerumitan
untuk , variabel
i , gunakan fungsi
len , sulit untuk merasakan iterasi pada elemen dari akhir, dan juga mengurangi jumlah kode dengan dua baris (dari tujuh baris menjadi lima), dan semakin kecil kode, semakin kecil kemungkinan untuk memperbolehkannya sebuah kesalahan.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*store.Build{build}, tempList...) }
Setelah menghapus enumerasi slice dari akhir, kami dengan jelas membedakan antara operasi elemen yang berubah (baris ketiga) dan membalikkan array asli (baris keempat).
Gagasan utama dari opsi kedua adalah untuk lebih lanjut meledakkan variasi elemen dan penyortiran. Pertama, kita memilah-milah elemen dan mengubahnya, dan kemudian mengurutkan irisan dengan operasi terpisah. Metode ini akan membutuhkan implementasi tambahan antarmuka pengurutan untuk slice, tetapi akan meningkatkan keterbacaan dan benar-benar memisahkan dan mengisolasi balik dari perubahan elemen, dan metode
Balik pasti akan menunjukkan kepada pembaca hasil yang diinginkan.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(sort.IntSlice(keys)))
Opsi ketiga hampir merupakan pengulangan dari yang kedua, tetapi
sort. Iris digunakan untuk menyortir, yang meningkatkan jumlah kode per satu baris, tetapi menghindari implementasi tambahan dari antarmuka penyortiran.
for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id })
Sekilas, dalam hal kompleksitas internal, jumlah iterasi, fungsi yang diterapkan, kode awal dan algoritma pertama sudah dekat; opsi kedua dan ketiga mungkin tampak lebih sulit, tetapi tidak mungkin untuk mengatakan dengan tegas mana dari empat opsi yang optimal.
Jadi, kami melarang diri untuk mengambil keputusan berdasarkan asumsi yang tidak didukung oleh bukti, tetapi jelas bahwa yang paling menarik di sini adalah bagaimana fungsi append berperilaku ketika menambahkan elemen ke akhir dan ke awal irisan. Lagi pula, sebenarnya, fungsi ini tidak sesederhana kelihatannya.
Tambah berfungsi
sebagai berikut : ia menambahkan elemen baru ke irisan yang ada jika kapasitasnya lebih besar dari total panjang, atau cadangan dalam memori tempat untuk irisan baru, menyalin data dari irisan pertama ke dalamnya, menambahkan data yang kedua dan mengembalikan yang baru sebagai hasilnya mengiris.
Nuansa yang paling menarik dalam karya fungsi ini adalah algoritma yang digunakan untuk menyimpan memori untuk array baru. Karena operasi yang paling mahal adalah mengalokasikan memori baru, pengembang Go membuat sedikit trik untuk membuat operasi
penambahan lebih murah. Pada awalnya, agar tidak cadangan memori baru setiap kali elemen ditambahkan, jumlah memori dialokasikan dengan margin tertentu - dua kali lipat aslinya, tetapi setelah sejumlah elemen ukuran bagian memori yang baru dicadangkan menjadi tidak lebih dari dua kali, tetapi sebesar 25%.
Dengan adanya pemahaman baru tentang fungsi
append, jawaban atas pertanyaan: "Apa yang akan lebih cepat: tambahkan satu elemen ke akhir slice yang ada atau tambahkan slice yang ada ke slice dari satu elemen?" - sudah lebih transparan. Dapat diasumsikan bahwa dalam kasus kedua, dibandingkan dengan yang pertama, akan ada lebih banyak alokasi memori, yang secara langsung akan mempengaruhi kecepatan kerja.
Jadi kami dengan lancar mendekati tolok ukur. Dengan bantuan benchmark, Anda dapat mengevaluasi beban algoritme pada sumber daya paling kritis, seperti runtime dan RAM.
Mari kita menulis tolok ukur untuk mengevaluasi keempat algoritma kami, pada saat yang sama kami akan mengevaluasi pertumbuhan apa yang dapat memberi kami penolakan penyortiran (untuk memahami berapa banyak waktu total yang dihabiskan untuk menyortirnya). Kode Benchmark:
package services import ( "testing" "sort" ) type Build struct { Id int ExtractedSize int64 PatchUrls string ReversePatchUrls string RPatchExtractedSize int64 } type Builds []*Build func (a Builds) Len() int { return len(a) } func (a Builds) Swap(i, j int) { a[i], a[j] = a[j], a[i] } func (a Builds) Less(i, j int) bool { return a[i].Id < a[j].Id } func prepare() Builds { var builds Builds for i := 0; i < 100000; i++ { builds = append(builds, &Build{Id: i}) } return builds } func BenchmarkF1(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchUrls, b.ExtractedSize = b.ReversePatchUrls, b.RPatchExtractedSize tempList = append(tempList, b) } } } func BenchmarkF2(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*Build{build}, tempList...) } } } func BenchmarkF3(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(builds)) } } func BenchmarkF4(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id }) } } func BenchmarkF5(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } } }
Luncurkan benchmark dengan perintah
go test -bench =. -benchmem .
Hasil perhitungan untuk irisan 10, 100, 1000, 10 000 dan 100 000 elemen disajikan dalam grafik di bawah ini, di mana F1 adalah algoritma awal, F2 adalah penambahan elemen ke awal array, F3 adalah penggunaan
sort. Kembali ke sortir, F4 adalah penggunaan
sort. , F5 - penolakan penyortiran.
Waktu operasi Jumlah alokasi memori
Jumlah alokasi memori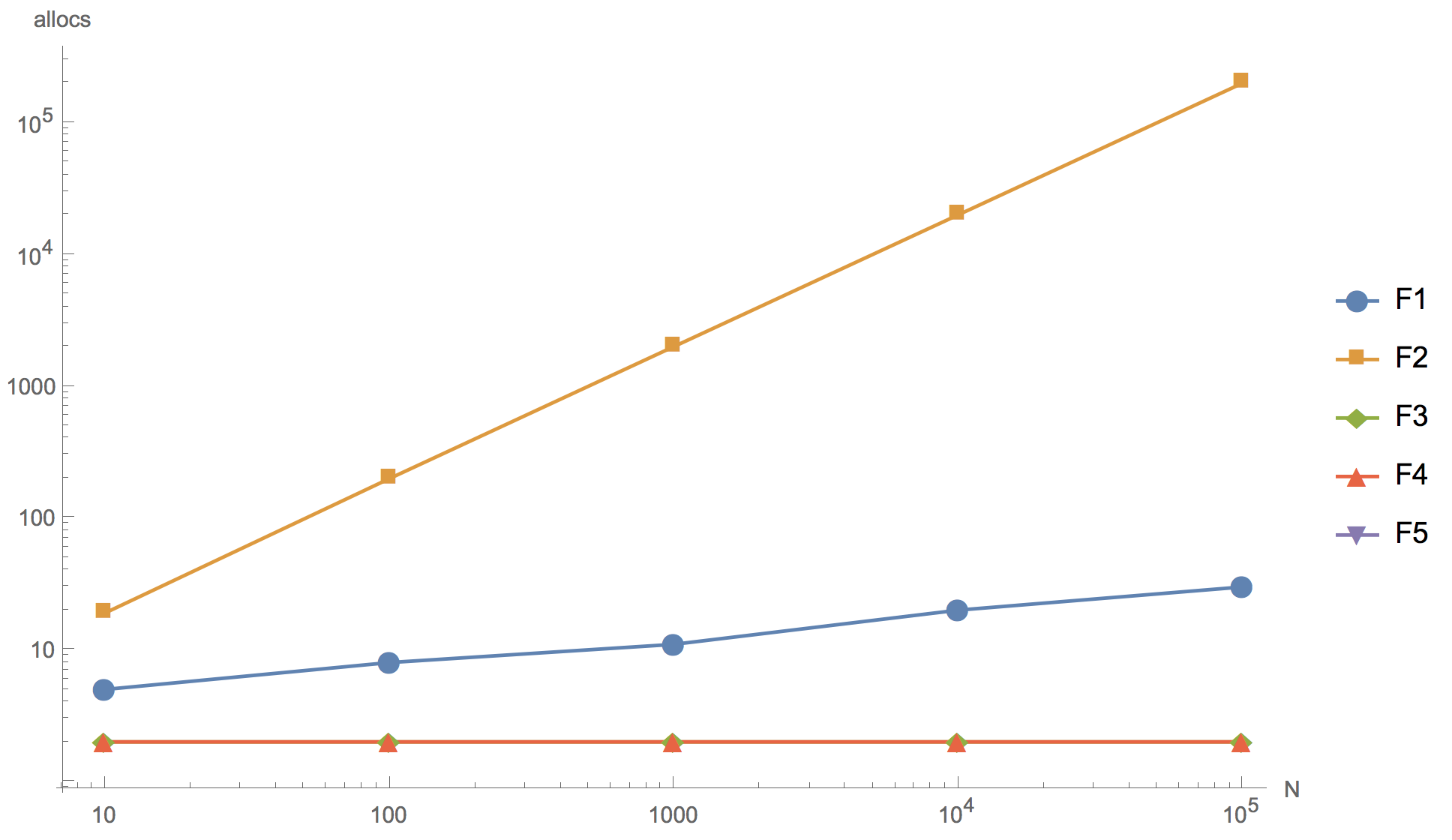
Seperti yang dapat Anda lihat dari grafik, Anda dapat meningkatkan array, tetapi hasil akhirnya pada prinsipnya dapat dibedakan pada sepotong 10 elemen.
Tak satu pun dari algoritma alternatif yang diusulkan (F2, F3, F4) dapat melebihi algoritma asli (F1) dalam kecepatan. Meskipun fakta bahwa semua kecuali F2 memiliki alokasi memori lebih sedikit daripada yang asli. Algoritma pertama (F2) dengan penambahan elemen pada awal irisan ternyata menjadi yang paling tidak efisien: seperti yang diharapkan, ia memiliki alokasi memori terlalu banyak, sehingga sangat mustahil untuk menggunakannya dalam pengembangan produk. Algoritma yang menggunakan fungsi sortir terbalik bawaan (F3) secara signifikan lebih lambat dari yang asli. Dan hanya sorting.
Algoritma sortasi
kutu sebanding dalam kecepatan dengan algoritma asli, tetapi sedikit lebih rendah dari itu.
Anda juga dapat melihat bahwa menolak sorting (F5) memberikan akselerasi yang signifikan. Oleh karena itu, jika Anda benar-benar ingin menulis ulang kode, Anda bisa menuju ke arah ini, misalnya, meningkatkan potongan
build awal dari database, gunakan pengurutan berdasarkan id DESC daripada ASC dalam permintaan. Tetapi pada saat yang sama, kami dipaksa untuk melampaui batas-batas bagian kode yang dianggap, yang berisiko menimbulkan banyak perubahan.
Kesimpulan
Tulis tolok ukur.
Tidak masuk akal untuk menghabiskan waktu Anda memikirkan apakah suatu kode tertentu akan lebih cepat. Informasi dari Internet, penilaian kolega dan orang lain, tidak peduli seberapa otoritatif mereka, dapat berfungsi sebagai argumen tambahan, tetapi peran hakim kepala, memutuskan apakah akan menjadi algoritma baru atau tidak, harus tetap dengan tolok ukur.
Sekilas, Go adalah bahasa yang cukup sederhana. Aturan 80⁄20 yang komprehensif berlaku di sini. 20% ini mewakili seluk-beluk struktur internal bahasa, pengetahuan yang membedakan pemula dari pengembang berpengalaman. Praktik menulis tolok ukur untuk menyelesaikan pertanyaan Anda adalah salah satu cara termurah dan paling efektif untuk mendapatkan jawaban maupun pemahaman yang lebih mendalam tentang struktur internal dan prinsip-prinsip bahasa Go.