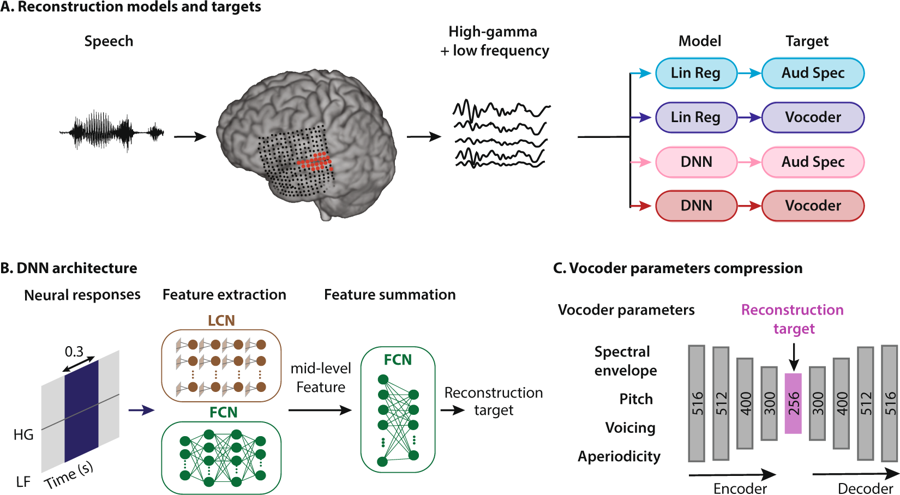
 Skema metode rekonstruksi ucapan. Seseorang mendengarkan kata-kata, sebagai akibatnya, neuron dari korteks pendengarannya diaktifkan. Data ditafsirkan dalam empat cara: dengan menggabungkan dua jenis model regresi dan dua jenis representasi ucapan, kemudian mereka memasuki sistem jaringan saraf untuk mengekstraksi fitur yang selanjutnya digunakan untuk mengkonfigurasi parameter vocoder.
Skema metode rekonstruksi ucapan. Seseorang mendengarkan kata-kata, sebagai akibatnya, neuron dari korteks pendengarannya diaktifkan. Data ditafsirkan dalam empat cara: dengan menggabungkan dua jenis model regresi dan dua jenis representasi ucapan, kemudian mereka memasuki sistem jaringan saraf untuk mengekstraksi fitur yang selanjutnya digunakan untuk mengkonfigurasi parameter vocoder.Neuroengineers di Universitas Columbia (AS) adalah yang pertama di dunia yang
menciptakan sistem yang menerjemahkan pikiran manusia menjadi ucapan yang dapat dimengerti dan dapat dibedakan, di sini adalah
rekaman suara kata-kata (mp3) yang disintesis oleh aktivitas otak.
Dengan mengamati aktivitas di korteks pendengaran, sistem mengembalikan kata-kata yang didengar seseorang dengan kejelasan yang belum pernah terjadi sebelumnya. Tentu saja, ini bukan penilaian pemikiran dalam arti kata sebenarnya, tetapi langkah penting telah diambil ke arah ini. Memang, pola aktivitas otak yang serupa terjadi di korteks serebral ketika seseorang membayangkan bahwa dia mendengarkan pembicaraan, atau ketika dia secara mental mengucapkan kata-kata.
Terobosan ilmiah ini menggunakan teknologi kecerdasan buatan membawa kita lebih dekat ke penciptaan antarmuka saraf yang efektif yang menghubungkan komputer secara langsung ke otak. Ini juga akan membantu orang yang tidak dapat berbicara dan mereka yang pulih dari stroke atau karena alasan lain yang sementara atau terus-menerus tidak dapat berbicara kata-kata untuk berkomunikasi.
Beberapa dekade penelitian telah membuktikan bahwa, dalam proses berbicara atau bahkan kata-kata yang berbicara secara mental, pola kontrol aktivitas muncul di otak. Selain itu, pola sinyal yang berbeda (dan dapat dikenali) muncul ketika kita mendengarkan seseorang atau membayangkan bahwa kita sedang mendengarkan. Para ahli telah lama mencoba merekam dan menguraikan pola-pola ini untuk "membebaskan" pikiran seseorang dari tengkorak - dan secara otomatis menerjemahkannya ke dalam bentuk lisan.
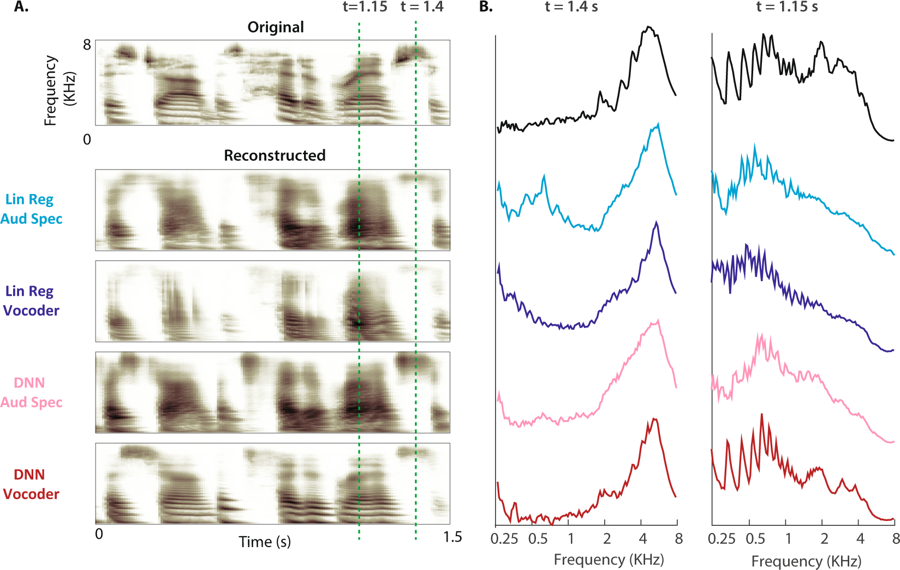 (A) Spektogram asli dari sampel pidato ditunjukkan di atas. Spektogram pendengaran direkonstruksi dari empat model ditunjukkan di bawah ini. (B) Kekuatan besarnya pita frekuensi selama tidak bersuara (t = 1,4 dtk) dan suara bersuara (t = 1,15 dt: kesenjangan ditunjukkan oleh garis putus-putus untuk spektogram asli dan empat rekonstruksi)
(A) Spektogram asli dari sampel pidato ditunjukkan di atas. Spektogram pendengaran direkonstruksi dari empat model ditunjukkan di bawah ini. (B) Kekuatan besarnya pita frekuensi selama tidak bersuara (t = 1,4 dtk) dan suara bersuara (t = 1,15 dt: kesenjangan ditunjukkan oleh garis putus-putus untuk spektogram asli dan empat rekonstruksi)"Ini adalah teknologi yang sama yang digunakan Amazon Echo dan Apple Siri untuk menjawab pertanyaan kami secara lisan,"
jelas Dr. Nima Mesgarani, pemimpin penulis makalah ini. Untuk mengajarkan vocoder untuk menafsirkan aktivitas otak, para ahli menemukan lima pasien dengan epilepsi yang sudah menjalani operasi otak. Mereka diminta mendengarkan kalimat yang dibuat oleh orang yang berbeda, sementara elektroda mengukur aktivitas otak, yang diproses oleh empat model. Pola-pola saraf ini mengajarkan vocoder. Para peneliti kemudian meminta pasien yang sama untuk mendengarkan bagaimana pengeras suara mengucapkan angka dari 0 hingga 9, merekam sinyal otak yang dapat dilewatkan melalui vocoder. Suara yang dihasilkan oleh vocoder sebagai respons terhadap sinyal-sinyal ini dianalisis dan dibersihkan oleh beberapa jaringan saraf.
Sebagai hasil dari pemrosesan pada output jaringan saraf, suara robot diterima, mengucapkan urutan angka. Untuk menguji ketepatan pengenalan, orang diberikan untuk mendengarkan suara yang disintesis oleh aktivitas otak mereka sendiri: "Kami menemukan bahwa orang dapat memahami dan mengulangi suara dalam 75% kasus, yang jauh lebih tinggi dan melebihi upaya sebelumnya," kata Dr. Mesgarani.
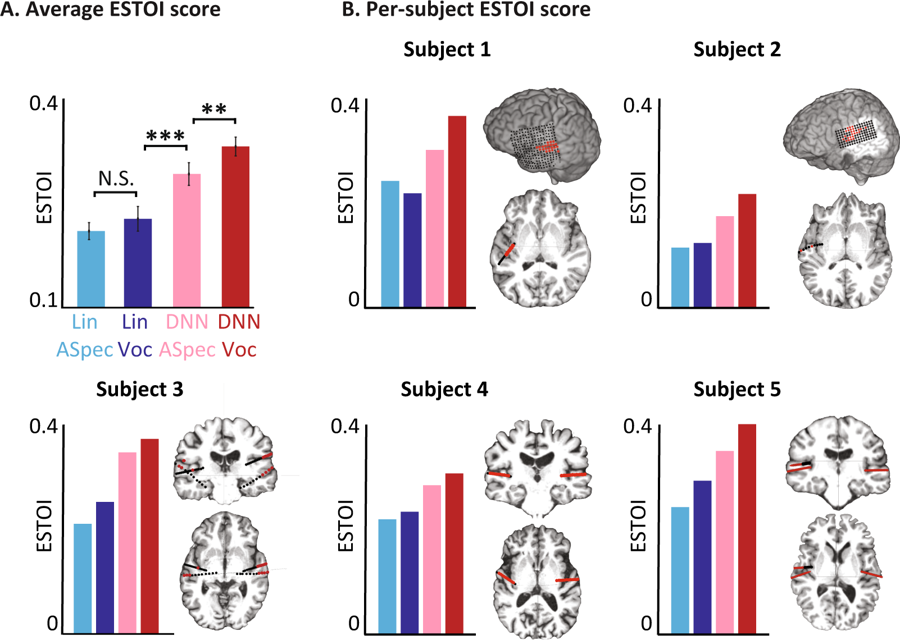 Peringkat obyektif untuk model yang berbeda. (A) Rata - rata skor ESTOI untuk semua mata pelajaran untuk empat model. B) Cakupan dan lokasi elektroda dan skor ESTOI untuk masing-masing dari lima orang. Setiap orang memiliki skor ESTOI yang lebih tinggi untuk vocoder DNN daripada model lain.
Peringkat obyektif untuk model yang berbeda. (A) Rata - rata skor ESTOI untuk semua mata pelajaran untuk empat model. B) Cakupan dan lokasi elektroda dan skor ESTOI untuk masing-masing dari lima orang. Setiap orang memiliki skor ESTOI yang lebih tinggi untuk vocoder DNN daripada model lain.Sekarang para ilmuwan berencana untuk mengulang percobaan dengan kata-kata dan kalimat yang lebih kompleks. Selain itu, tes yang sama akan berjalan untuk sinyal otak ketika seseorang membayangkan apa yang dia katakan. Pada akhirnya, mereka berharap sistem akan menjadi bagian dari implan, yang menerjemahkan pikiran pemakainya secara langsung menjadi kata-kata.
Artikel ilmiah ini
diterbitkan pada 29 Januari 2019 di domain publik dalam jurnal
Scientific Reports (doi: 10.1038 / s41598-018-37359-z).
Kode program untuk melakukan analisis fonemik, menghitung amplitudo frekuensi tinggi dan merekonstruksi spektogram pendengaran telah
tersedia untuk umum .