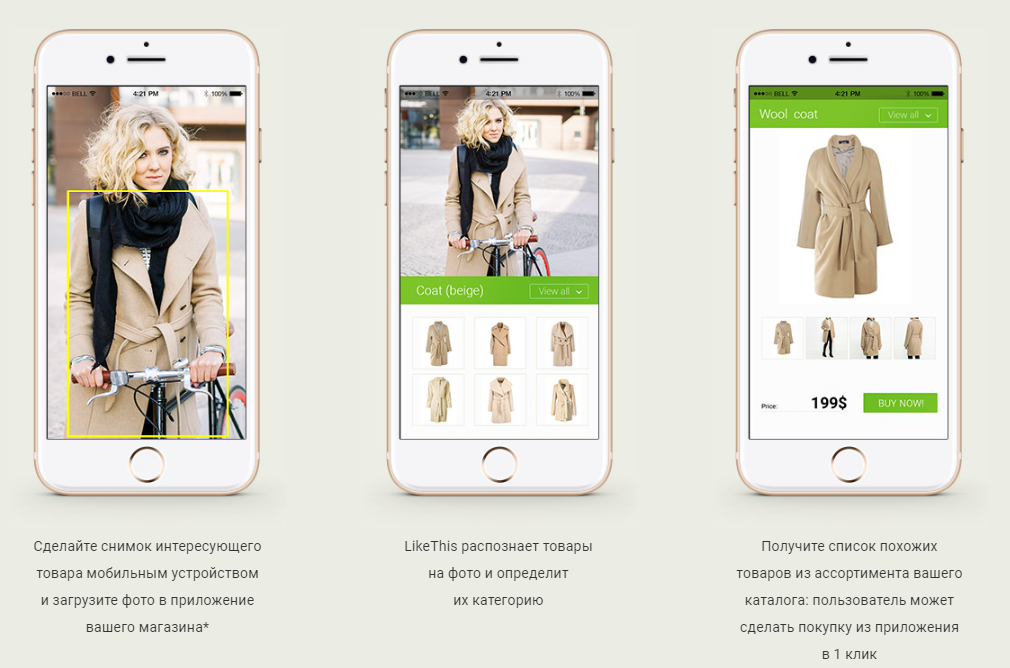
Pada artikel ini saya ingin berbicara tentang bagaimana kami menciptakan sistem pencarian untuk pakaian yang serupa (lebih tepatnya pakaian, sepatu dan tas) dari foto. Artinya, dalam istilah bisnis, layanan rekomendasi berdasarkan pada jaringan saraf.
Seperti kebanyakan solusi TI modern, kami dapat membandingkan pengembangan sistem kami dengan perakitan konstruktor Lego, ketika kami mengambil banyak detail kecil, instruksi, dan membuat model siap pakai dari ini. Berikut ini adalah instruksi seperti itu: detail apa yang harus diambil dan bagaimana menerapkannya agar GPU Anda dapat memilih produk serupa dari sebuah foto, Anda akan temukan di artikel ini.
Bagian mana dari sistem kami dibangun:
- detektor dan pengelompokan pakaian, sepatu dan tas pada gambar;
- crawler, pengindeks atau modul untuk bekerja dengan katalog elektronik toko;
- modul pencarian gambar serupa;
- JSON-API untuk interaksi yang nyaman dengan perangkat dan layanan apa pun;
- antarmuka web atau aplikasi seluler untuk melihat hasilnya.
Di akhir artikel, kami akan menjelaskan semua "garu" yang kami injak selama pengembangan dan rekomendasi tentang cara menetralisirnya.
Pernyataan masalah dan pembuatan rubrikator
Tugas dan kasus penggunaan utama dari sistem terdengar cukup sederhana dan jelas:
- pengguna mengirimkan ke pintu masuk (misalnya, melalui aplikasi seluler) foto di mana ada artikel pakaian dan / atau tas dan / atau sepatu;
- sistem menentukan (mendeteksi) semua objek ini;
- menemukan masing-masing produk yang paling mirip (relevan) di toko online nyata;
- memberi pengguna produk dengan kemampuan untuk pergi ke halaman produk tertentu untuk pembelian.
Sederhananya, tujuan dari sistem kami adalah untuk menjawab pertanyaan terkenal: "Dan Anda tidak memiliki hal yang sama, hanya dengan tombol ibu-mutiara?"
Sebelum masuk ke kumpulan kode, markup, dan pelatihan jaringan saraf, Anda perlu menentukan dengan jelas kategori yang akan ada di dalam sistem Anda, yaitu kategori yang akan dideteksi oleh jaringan saraf. Penting untuk dipahami bahwa daftar kategori yang lebih luas dan lebih rinci, semakin universal, karena sejumlah besar kategori kecil yang sempit seperti mini-dress, midi-dress, maxi-dress selalu dapat digabungkan dengan satu sentuhan menjadi satu kategori dalam satu jenis gaun TAPI TIDAK sebaliknya. Dengan kata lain, rubrikator perlu dipikirkan dan disusun pada awal proyek, sehingga tidak mengulangi pekerjaan yang sama 3 kali kemudian. Kami menyusun rubrikator, mengambil sebagai dasar beberapa toko besar, seperti Lamoda.ru, Amazon.com, dan mencoba membuatnya selebar mungkin di satu sisi, dan di sisi lain mungkin, di lain sisi, sehingga akan lebih mudah untuk mengaitkan kategori detektor dengan berbagai kategori di masa mendatang. toko online (Saya akan memberi tahu Anda lebih lanjut tentang cara membuat banyak ini di bagian crawler dan pengindeks). Ini adalah contoh dari apa yang terjadi.
 Kategori contoh
Kategori contohDalam katalog kami saat ini hanya ada 205 kategori: pakaian wanita, pakaian pria, sepatu wanita, sepatu pria, tas, pakaian untuk bayi yang baru lahir. Versi lengkap dari classifier kami tersedia
di tautan .
Pengindeks atau modul untuk bekerja dengan katalog elektronik toko
Untuk mencari produk serupa di masa mendatang, kita perlu membuat basis luas dari apa yang akan kita cari. Dalam pengalaman kami, kualitas pencarian untuk gambar yang serupa secara langsung tergantung pada ukuran basis pencarian, yang harus melebihi setidaknya 100 ribu gambar, dan lebih disukai 1 juta gambar. Jika Anda menambahkan 1-2 toko online kecil ke dalam basis data, kemungkinan besar Anda tidak akan mendapatkan hasil yang mengesankan hanya karena dalam 80% kasus tidak ada yang benar-benar mirip dengan barang yang diinginkan dalam katalog Anda.
Jadi, untuk membuat basis data besar gambar yang Anda butuhkan untuk memproses katalog berbagai toko online, inilah yang termasuk dalam proses ini:
- Pertama, Anda perlu menemukan umpan XML dari toko online, biasanya Anda dapat menemukannya secara bebas di Internet, atau dengan meminta dari toko itu sendiri, atau dalam berbagai agregator seperti Admitad;
- umpan diproses (diuraikan) oleh program khusus - perayap, yang mengunduh semua gambar dari umpan, menempatkannya di hard drive (lebih tepatnya, pada penyimpanan jaringan yang terhubung ke server Anda), menulis semua meta-informasi tentang barang dalam database;
- kemudian proses lain diluncurkan - pengindeks, yang menghitung vektor fitur 128-dimensi biner untuk setiap gambar. Anda dapat menggabungkan crawler dan pengindeks ke dalam satu modul atau program, tetapi kami secara historis mengembangkan bahwa ini adalah proses yang berbeda. Hal ini terutama disebabkan oleh fakta bahwa pada awalnya kami menghitung deskriptor (hashes) untuk setiap gambar yang didistribusikan pada armada besar mesin, karena ini adalah proses yang sangat intensif sumber daya. Jika Anda hanya bekerja dengan jaringan saraf, mesin pertama dengan GPU sudah cukup untuk Anda;
- vektor biner ditulis ke basis data, semua proses selesai dan voila - basis data produk Anda siap untuk pencarian lebih lanjut;
- tetapi satu trik kecil masih ada: karena semua toko memiliki katalog yang berbeda dengan kategori yang berbeda di dalamnya, maka Anda perlu membandingkan kategori semua feed yang terkandung dalam database Anda dengan kategori detektor (lebih tepatnya, penggolong) barang, kami menyebutnya proses pemetaan. Ini adalah rutin manual, tetapi pekerjaan yang sangat berguna, di mana operator, secara manual mengedit file XML biasa, membandingkan kategori feed dalam database dengan kategori detektor. Inilah hasilnya:
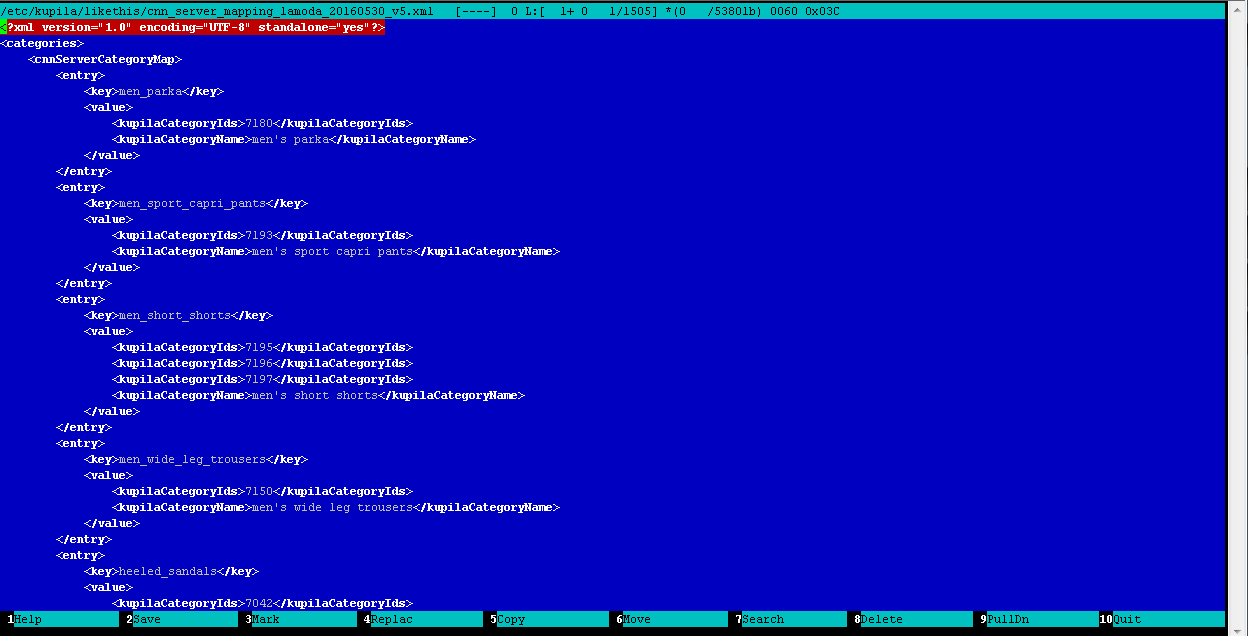 Contoh file pemetaan kategori: katalog-klasifikasi
Contoh file pemetaan kategori: katalog-klasifikasiDeteksi dan klasifikasi
Untuk menemukan sesuatu yang mirip dengan apa yang ditemukan mata kita di foto, kita perlu mendeteksi "sesuatu" ini terlebih dahulu (yaitu, untuk melokalisasi dan memilih objek). Kami telah melangkah jauh dalam menciptakan detektor, mulai dari melatih kaskade OpenCV yang sama sekali tidak bekerja pada tugas ini, dan berakhir dengan teknologi modern untuk mendeteksi dan mengklasifikasikan
R-FCN dan pengklasifikasi berdasarkan jaringan saraf
ResNet .
Sebagai data yang digunakan untuk pelatihan dan pengujian (yang disebut pelatihan dan sampel uji), kami mengambil semua jenis gambar dari Internet:
- mencari gambar Google / Yandex;
- set data yang ditandai oleh pihak ketiga;
- jejaring sosial;
- situs majalah mode;
- Toko-toko internet pakaian, sepatu, tas.
Markup dilakukan menggunakan alat samopisny, hasil markup adalah set gambar dan file * .seg kepada mereka, yang menyimpan koordinat objek dan label kelas untuk mereka. Rata-rata, dari 100 hingga 200 gambar diberi label untuk setiap kategori, jumlah total gambar di 205 kelas adalah 65.000.
Setelah pelatihan dan sampel uji siap, kami melakukan pemeriksaan ulang markup, memberikan semua gambar ke operator lain. Ini memungkinkan kami untuk menyaring sejumlah besar kesalahan yang sangat mempengaruhi kualitas pelatihan jaringan saraf, yaitu, detektor dan penggolong. Kemudian kami mulai melatih jaringan saraf menggunakan alat standar dan "melepas" snapshot berikutnya dari jaringan saraf "dalam panas hari" dalam beberapa hari. Rata-rata, waktu pelatihan detektor dan pengelompokan volume data 65.000 gambar pada GPU Titan X adalah sekitar 3 hari.
Suatu jaringan saraf yang sudah jadi harus entah bagaimana harus diperiksa untuk kualitas, yaitu untuk mengevaluasi apakah versi jaringan saat ini telah menjadi lebih baik dari yang sebelumnya dan seberapa banyak. Bagaimana kami melakukannya:
- sampel uji terdiri dari 12.000 gambar dan ditata persis seperti pelatihan;
- kami menulis alat kecil yang menjalankan seluruh sampel uji melalui detektor dan menyusun tabel semacam ini (versi lengkap dari tabel tersedia di sini );
- tabel ini ditambahkan ke Excel pada tab baru dan dibandingkan dengan yang sebelumnya secara manual atau menggunakan rumus Excel bawaan;
- pada keluaran kami mendapatkan indikator umum dari detektor dan klasifikasi TPR / FPR di seluruh sistem di dan untuk setiap kategori secara terpisah.
 Contoh tabel laporan tentang kualitas detektor dan klasifikasi
Contoh tabel laporan tentang kualitas detektor dan klasifikasiModul Pencarian Gambar Serupa
Setelah kami mendeteksi barang-barang pakaian dalam foto, kami memulai mesin pencari untuk gambar yang serupa, berikut cara kerjanya:
- untuk semua potongan gambar (barang yang terdeteksi), vektor fitur biner 128-bit jaringan saraf dihitung dalam bentuk dan warna (dari mana mereka berasal, lihat di bawah);
- vektor yang sama dihitung sebelumnya pada tahap pengindeksan untuk semua gambar barang yang disimpan dalam database sudah dimuat ke dalam RAM komputer (karena untuk mencari yang serupa akan diperlukan untuk membuat sejumlah besar pencarian dan perbandingan berpasangan, kami segera memuat seluruh database ke dalam memori, yang memungkinkan kami untuk meningkatkan kecepatan pencarian puluhan kali, sedangkan basis sekitar 100 ribu produk cocok dengan tidak lebih dari 2-3 GB RAM);
- koefisien pencarian untuk kategori ini berasal dari antarmuka atau dari properti hardcode, misalnya, dalam kategori "pakaian", kami mencari lebih banyak dalam warna daripada dalam bentuk (misalnya, pencarian bentuk-warna 8-ke-2), dan dalam kategori "sepatu hak tinggi" kami melihat 1-ke-1 bentuk-warna karena bentuk dan warna sama pentingnya di sini;
- Selanjutnya, vektor untuk pemotongan (fragmen) dari gambar input dibandingkan berpasangan dengan gambar dari database, dengan mempertimbangkan koefisien (jarak Hamming antara vektor dibandingkan);
- sebagai hasilnya, berbagai produk serupa dari database dibentuk untuk setiap fragmen produk-potong, dan bobot diberikan untuk setiap produk (sesuai dengan rumus sederhana, dengan mempertimbangkan normalisasi akun, sehingga semua bobot berada dalam kisaran dari 0 hingga 1) untuk kemungkinan menghasilkan ke antarmuka, serta untuk selanjutnya menyortir;
- berbagai produk serupa ditampilkan di antarmuka melalui web-JSON-API.
Jaringan saraf untuk pembentukan vektor jaringan saraf dalam bentuk dan warna dilatih sebagai berikut.
- Untuk melatih jaringan saraf dalam bentuk, kami mengambil semua gambar yang ditandai, memotong fragmen sesuai markup dan mendistribusikannya ke folder sesuai dengan kelas: yaitu, semua sweater dalam satu folder, semua T-shirt di folder lain, dan semua sepatu hak tinggi di ketiga, dll. d. Selanjutnya, kami melatih penggolong biasa berdasarkan sampel ini. Jadi, kita semacam "menjelaskan" ke jaringan saraf pemahaman kita tentang bentuk objek.
- Untuk melatih jaringan saraf dalam warna, kami mengambil semua gambar mark-up, memotong fragmen sesuai markup dan mendistribusikannya ke dalam folder sesuai dengan warna: yaitu, memasukkan semua T-shirt, sepatu, tas, dll ke dalam folder "hijau". warna hijau (sebagai hasilnya, setiap objek warna hijau umumnya terakumulasi dalam satu folder), dalam folder "stripped" kita meletakkan semua hal dalam strip, dan dalam folder "merah putih" semua hal merah putih. Selanjutnya, kami melatih classifier terpisah untuk kelas-kelas ini, seolah-olah "menjelaskan" ke jaringan saraf pemahaman tentang warna suatu benda.
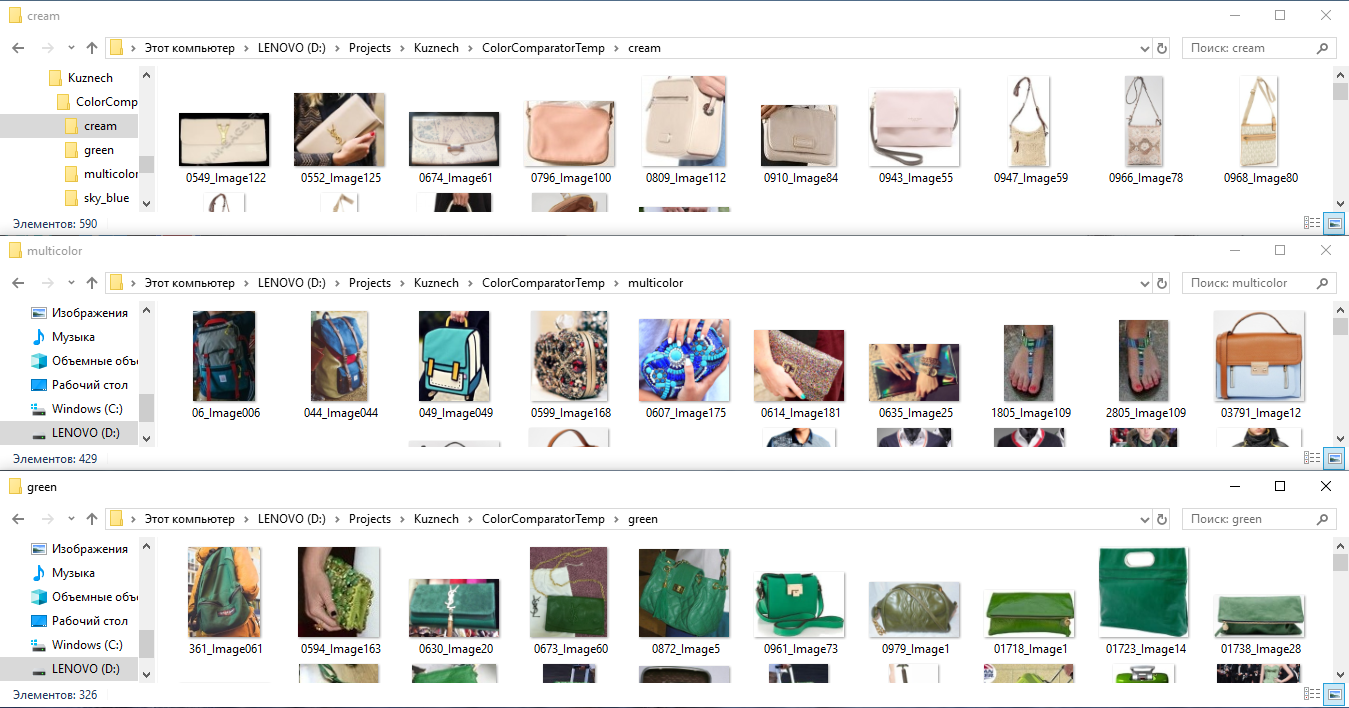 Contoh menandai gambar dengan warna untuk mendapatkan vektor tanda-tanda jaringan dengan warna.
Contoh menandai gambar dengan warna untuk mendapatkan vektor tanda-tanda jaringan dengan warna.Menariknya, teknologi semacam itu bekerja dengan baik bahkan pada latar belakang yang kompleks, yaitu, ketika potongan-potongan benda tidak dipotong dengan jelas di sepanjang kontur (topeng), tetapi di sepanjang bingkai persegi panjang, yang telah ditentukan oleh marker.
Pencarian untuk yang serupa didasarkan pada ekstraksi vektor fitur biner dari jaringan saraf dengan cara ini: output dari lapisan kedua dari belakang diambil, kompres, normalkan dan binarize. Dalam pekerjaan kami, kami mengompresi menjadi 128-bit vektor. Anda dapat melakukannya sedikit berbeda, misalnya, seperti yang dijelaskan dalam artikel Yahoo "
Pembelajaran Mendalam Kode Biner Hash untuk Pengambilan Gambar Cepat ", tetapi esensi dari semua algoritma adalah hampir sama - gambar yang mirip dengan gambar dicari dengan membandingkan properti yang dioperasikan oleh jaringan saraf dalam lapisan.
Awalnya, sebagai teknologi untuk mencari gambar yang serupa, kami menggunakan hash atau deskriptor gambar berdasarkan (lebih tepatnya dihitung) pada algoritma matematika tertentu, seperti operator Sobel (atau hash kontur), algoritma SIFT (atau titik tunggal), merencanakan histogram, atau membandingkan jumlah sudut dalam gambar . Teknologi ini bekerja dan memberikan hasil yang lebih atau kurang waras, tetapi hash tidak sebanding dengan teknologi mencari gambar yang serupa berdasarkan properti yang dialokasikan oleh jaringan saraf. Jika Anda mencoba menjelaskan perbedaan dalam 2 kata, maka algoritma perbandingan gambar berbasis hash adalah "kalkulator" yang dikonfigurasi untuk membandingkan gambar menggunakan beberapa rumus dan itu bekerja terus menerus. Perbandingan menggunakan fitur dari jaringan saraf adalah "kecerdasan buatan", dilatih oleh seseorang untuk memecahkan masalah tertentu dengan cara tertentu. Anda dapat memberikan contoh kasar: jika Anda mencari sweater hash dalam garis-garis hitam dan putih, maka Anda cenderung menemukan semua hal hitam dan putih sebagai yang serupa. Dan jika Anda mencari menggunakan jaringan saraf, maka:
- di tempat pertama Anda akan menemukan semua sweater dengan garis-garis hitam dan putih,
- maka semua sweater hitam dan putih
- dan kemudian semua sweater bergaris.
JSON-API untuk interaksi yang nyaman dengan perangkat dan layanan apa pun
Kami telah menciptakan WEB-JSON-API yang sederhana dan nyaman untuk mengkomunikasikan sistem kami dengan perangkat dan sistem apa pun, yang, tentu saja, bukan inovasi apa pun, melainkan standar pengembangan yang kuat dan bagus.
Antarmuka web atau aplikasi seluler untuk melihat hasil
Untuk memeriksa hasilnya secara visual, serta untuk menunjukkan sistem kepada pelanggan, kami telah mengembangkan antarmuka sederhana:
Kesalahan yang dilakukan dalam proyek
- Awalnya, perlu untuk mendefinisikan tugas dengan lebih jelas, dan berdasarkan tugas, untuk memilih foto untuk tata letak. Jika Anda perlu mencari foto UGC (Konten Buatan Pengguna) - ini adalah satu kasus dan contoh untuk tata letak. Jika Anda memerlukan pencarian foto dari majalah mengkilap, ini adalah kasus yang berbeda, dan jika Anda memerlukan pencarian foto di mana satu objek besar terletak di latar belakang putih, ini adalah cerita yang terpisah dan sampel yang sama sekali berbeda. Kami mencampur semuanya dalam satu tumpukan, yang memengaruhi kualitas detektor dan penggolong.
- Dalam foto, Anda harus selalu menandai SEMUA objek, setidaknya dari kenyataan bahwa setidaknya entah bagaimana sesuai dengan tugas Anda, misalnya, ketika memilih pilihan pakaian yang serupa, Anda harus segera menandai semua aksesori (manik-manik, kacamata, gelang, dll.), Kepala topi, dll. Karena sekarang kita memiliki set pelatihan yang sangat besar, untuk menambahkan kategori lain kita perlu mendistribusikan kembali SEMUA foto, dan ini adalah pekerjaan yang sangat produktif.
- Deteksi kemungkinan besar dilakukan dengan jaringan mask, transisi ke Mask-CNN dan solusi berbasis Detectron modern adalah salah satu bidang pengembangan sistem.
- Akan lebih baik untuk segera memutuskan bagaimana Anda akan menentukan kualitas pemilihan gambar yang sama - ada 2 metode: "dengan mata" dan ini adalah metode yang paling sederhana dan termurah dan metode 2 - "ilmiah", ketika Anda mengumpulkan data dari "ahli" (orang, yang sedang saya uji algoritma pencarian yang serupa) dan berdasarkan data ini, bentuk sampel uji dan katalog khusus untuk mencari gambar yang serupa. Metode ini baik secara teori dan terlihat cukup meyakinkan (untuk diri sendiri dan untuk pelanggan), tetapi dalam praktiknya, implementasinya sulit dan cukup mahal.
Kesimpulan dan rencana pengembangan selanjutnya
Teknologi ini cukup siap dan cocok untuk digunakan, sekarang ini beroperasi di salah satu pelanggan kami di toko online sebagai layanan rekomendasi. Juga, baru-baru ini, kami mulai mengembangkan sistem serupa di industri lain (yaitu, kami sekarang bekerja dengan jenis barang lain).
Dari rencana langsung: transfer jaringan ke Mask-CNN, serta penandaan ulang dan penandaan ulang gambar untuk meningkatkan kualitas detektor dan penggolong.
Sebagai kesimpulan, saya ingin mengatakan bahwa menurut perasaan kita, teknologi yang sama dan pada umumnya jaringan saraf mampu menyelesaikan hingga 80% dari tugas kompleks dan sangat intelektual yang dipenuhi oleh otak kita setiap hari. Satu-satunya pertanyaan adalah siapa yang pertama menerapkan teknologi seperti itu dan mengeluarkan seseorang dari pekerjaan rutin, membebaskannya ruang untuk kreativitas dan pengembangan, yang, menurut pendapat kami, adalah tujuan tertinggi manusia!
Referensi