
Hari yang baik
Dalam praktik nyata, Anda sering menghadapi tugas yang jauh dari algoritma ML kompleks, tetapi pada saat yang sama tidak kalah penting dan mendesak untuk bisnis.
Mari kita bicara tentang salah satunya.
Tugas bermuara pada mendistribusikan (menggergaji, rasplitovat - jargon bisnis tidak habis-habisnya) data dari beberapa tabel target dengan agregat (nilai agregat) pada tabel rincian lebih rinci.
Misalnya, departemen komersial perlu memecah rencana tahunan yang disepakati di tingkat merek - secara rinci, ke produk, bagi pemasar untuk memecah anggaran pemasaran tahunan menurut negara, departemen perencanaan dan ekonomi untuk memecah biaya bisnis umum oleh pusat pertanggungjawaban keuangan, dll. dll.
Jika Anda merasa bahwa tugas-tugas seperti ini sudah menjulang di depan Anda di cakrawala atau sudah merawat mereka yang terkena tugas-tugas tersebut, maka saya meminta kucing.
Pertimbangkan contoh nyata:
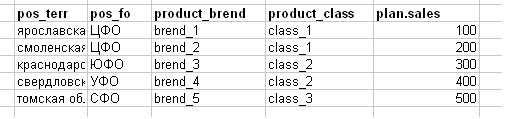
Mereka menurunkan rencana penjualan sebagai tugas seperti pada gambar di bawah ini (saya sengaja membuat contoh disederhanakan, pada kenyataannya - spanduk excel 100-200 mb).
Penjelasan judul:
- pos_terr-wilayah (wilayah) outlet
- pos_fo - distrik federal dari outlet (misalnya, Central Federal District-Central Federal District)
- product_brend - merek produk
- product_class - kelas produk
- plan.sales adalah rencana penjualan untuk apa pun.
Dan mereka meminta, misalnya, untuk memecahkan tabel besar mereka (dalam kerangka contoh anak-anak kita, tentu saja lebih sederhana) - ke saluran penjualan. Untuk pertanyaan - sesuai dengan logika apa yang harus dipecah, saya mendapatkan jawabannya: "tetapi ambil statistik penjualan aktual untuk kuartal ke-4 tahun ini dan itu, dapatkan bagian aktual dari saluran dalam% untuk setiap baris rencana dan uraikan bagian-bagian dari garis rencana".
Sebenarnya, ini adalah jawaban paling sering dalam tugas-tugas seperti itu ...
Sejauh ini, semuanya tampak cukup sederhana.
Saya mendapatkan fakta ini (lihat gambar di bawah):
- pos_channell - saluran penjualan (atribut target untuk paket tersebut)
- fact.sales - penjualan aktual sesuatu.
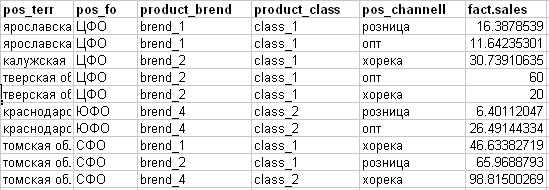
Berdasarkan pendekatan yang diperoleh untuk "menggergaji" pada contoh baris pertama dari rencana, kami akan memecahnya berdasarkan fakta seperti ini:

Namun, jika kita membandingkan fakta dengan rencana untuk seluruh pelat untuk memahami apakah semua garis rencana dapat “dipotong” secara memadai, kita mendapatkan gambar berikut: (hijau - semua atribut dari garis rencana bertepatan dengan fakta, sel kuning tidak cocok).
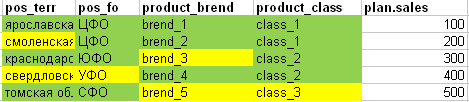
- Pada baris pertama rencana, semua bidang ditemukan sepenuhnya dalam fakta.
- Pada baris kedua dari rencana, wilayah yang sesuai tidak ditemukan dalam kenyataan
- Garis ke-3 dari rencana itu tidak cukup dalam fakta merek
- Baris ke-4 dari rencana itu tidak cukup dalam kenyataan wilayah dan distrik federal
- Garis kelima dari rencana tersebut sebenarnya tidak memiliki merek dan kelas.
Seperti Panikovsky berkata: "Melihat Syura, melihat - mereka adalah emas ..."

Saya pergi ke pelanggan bisnis dan mengklarifikasi contoh baris ke-2, pendekatan apa yang dia lihat untuk situasi seperti itu?
Saya mendapatkan jawabannya: "untuk kasus-kasus ketika tidak mungkin untuk menghitung pangsa saluran untuk merek No. 2 di wilayah Smolensk (dengan mempertimbangkan fakta bahwa kami memiliki wilayah Smolensk di Distrik Federal Tengah - Distrik Federal Tengah) - kemudian pecahkan garis ini sesuai dengan struktur saluran di seluruh Distrik Federal Pusat!"
Yaitu, untuk {wilayah Smolensk + brand_2} kami mengumpulkan fakta di tingkat Distrik Federal Pusat dan memecah sesuatu di wilayah Smolensk seperti ini:

Kembali dan mencerna apa yang saya dengar, saya mencoba untuk menggeneralisasi ke heuristik yang lebih universal:
Jika tidak ada data di tingkat detail tabel fakta saat ini, maka sebelum menghitung saham untuk bidang target (saluran penjualan), kami menggabungkan tabel fakta hingga atribut hierarki di atas.
Artinya, jika bukan untuk wilayah tersebut, maka kami mengumpulkan fakta ke tingkat hierarki yang lebih tinggi - berbagi untuk Distrik Federal Pusat yang sama seperti dalam rencana. Jika tidak untuk merek, maka dalam hierarki di atas ada kelas produk - sesuai dengan itu kami menceritakan kembali saham untuk kelas yang sama dan seterusnya.
Yaitu kami menggabungkan rencana dan fakta pada bidang kopling yang kami pertimbangkan bagiannya dalam fakta dan pada setiap iterasi sesuai dengan rencana yang tidak didistribusikan yang tersisa, kami berturut-turut mengurangi komposisi bidang kopling.
Pola distribusi data tertentu sudah muncul di sini:
- Kami mendistribusikan rencana sebenarnya berdasarkan pada kebetulan yang lengkap dari bidang yang sesuai
- Kami mendapatkan paket yang rusak (kami mengakumulasikannya di hasil antara) dan rencana yang tidak terputus (tidak semua lini cocok)
- Kami mengambil rencana yang tidak terputus dan membaginya sebenarnya ke tingkat hierarki yang lebih tinggi (mis., Kami mengabaikan bidang penggandaan 2 tabel ini dan menggabungkan fakta tanpa bidang ini untuk menghitung bagian)
- Kami mendapatkan paket yang rusak (kami menambahkannya ke hasil antara) dan paket yang tidak terputus (tidak semua baris cocok)
- Dan kami mengulangi langkah yang sama sampai tidak ada rencana yang "tidak terpecahkan".
Secara umum, tidak ada yang mewajibkan kami untuk secara konsisten menghapus bidang halangan hanya dalam hierarki. Misalnya, kami telah menghapus merek dan wilayah dari bidang halangan dan mendistribusikan rencana yang tersisa dengan: product_class (hierarki di atas merek) + Fed.krug (hierarki di atas wilayah). Dan masih punya keseimbangan rencana yang belum teralokasi.
Selanjutnya, kami dapat menghapus dari bidang kopling baik kelas produk atau distrik federal, seperti mereka tidak lagi tertanam dalam hierarki masing-masing.
Mempertimbangkan bahwa ada lusinan bidang dalam tabel tersebut - hingga satu juta melakukan manipulasi dengan tangan Anda - tugasnya bukanlah yang paling menyenangkan.
Dan mengingat bahwa tugas-tugas semacam ini datang kepada saya secara teratur pada akhir setiap tahun (menyetujui anggaran untuk tahun berikutnya di dewan direksi), Anda harus menerjemahkan proses ini ke dalam beberapa jenis templat universal yang fleksibel.
Dan karena sebagian besar waktu saya bekerja dengan data melalui R - implementasinya juga sama.
Pertama, kita perlu menulis fungsi sulap universal yang akan mengambil tabel dasar (basetab) dengan data untuk perincian (dalam contoh kita, rencana) dan tabel untuk menghitung pembagian (sharetab) berdasarkan di mana kita akan "melihat" data (dalam contoh kita, fakta). Tetapi fungsi tersebut juga harus memahami apa yang perlu dilakukan dengan objek-objek ini, sehingga fungsi tersebut masih akan menerima vektor nama bidang dari kopling (merge.vrs) - yaitu. bidang-bidang yang secara identik diberi nama di kedua tabel dan akan memungkinkan kami untuk menghubungkan satu tabel dengan yang lain dengan bidang-bidang ini tempat kerjanya (mis., gabung dengan benar). Juga, fungsi tersebut harus memahami kolom tabel dasar mana yang harus dimasukkan ke dalam distribusi (basetab.value) dan berdasarkan pada bidang mana untuk menghitung share (sharetab.value). Nah, dan yang paling penting - apa yang harus diambil untuk bidang yang dihasilkan (sharetab.targetvars), dalam kasus kami, kami ingin merinci rencana melalui saluran penjualan dari fakta.
Omong-omong, variabel sharetab.targetvars ini tidak acak dalam jamak saya - ini mungkin bukan satu bidang tetapi vektor nama bidang, untuk kasus-kasus ketika Anda perlu menambahkan bukan satu bidang ke tabel dasar dari tabel bagikan tetapi beberapa sekaligus (misalnya, berdasarkan fakta, Anda tidak dapat membagi rencana hanya melalui saluran penjualan tetapi juga dengan nama produk yang termasuk dalam merek).
Ya, dan satu lagi syarat :) fungsi saya harus sebagai lokalistis dan mudah dibaca, tanpa bangunan bertingkat di 2 layar (saya benar-benar tidak suka fungsi besar).
Dalam kondisi terakhir, paket dplyr populer cocok senyaman mungkin, dan mempertimbangkan bahwa operator pipeline harus memahami nama tekstual dari bidang yang telah diturunkan ke fungsi,
evaluasi Standart bukan tanpa.
Ini bayi ini (tidak termasuk komentar internal):
fn_distr <- function(sharetab, sharetab.value, sharetab.targetvars, basetab, basetab.value, merge.vrs,level.txt=NA) { # sharetab - = # sharetab.value - - # sharetab.targetvars - - # basetab - = # basetab.value - # merge.vrs - 2- # level.txt - . ( merge.vrs) require(dplyr) sharetab.value <- as.name(sharetab.value) basetab.value <- as.name(basetab.value) if(is.na(level.txt )){level.txt <- paste0(merge.vrs,collapse = ",")} result <- sharetab %>% group_by(.dots = c(merge.vrs, sharetab.targetvars)) %>% summarise(sharetab.sum = sum(!!sharetab.value)) %>% ungroup %>% group_by(.dots = merge.vrs) %>% mutate(sharetab.share = sharetab.sum / sum(sharetab.sum)) %>% ungroup %>% right_join(y = basetab, by = merge.vrs) %>% mutate(distributed.result = !!basetab.value * sharetab.share, level = level.txt) %>% select(-sharetab.sum,-sharetab.share) return(result) }
Pada output, fungsi harus mengembalikan data.rangka penyatuan dua tabel dengan garis-garis rencana + fakta di mana dimungkinkan untuk membagi rencana pada versi saat ini dari bidang kopling, dan dengan garis asli rencana (dan fakta kosong) di garis di mana rencana tidak dapat dibagi pada iterasi saat ini.
Artinya, hasil yang dikembalikan oleh fungsi setelah iterasi pertama (melanggar garis pertama rencana untuk wilayah Yaroslavl) akan terlihat seperti ini:
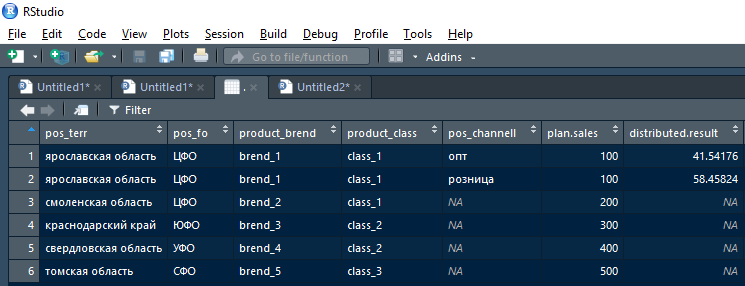
Selanjutnya, hasil ini dapat diambil dengan didistribusikan non-kosong. Hasil ke dalam hasil kumulatif dan dengan kosong (NA) didistribusikan. Hasil - kirim ke iterasi khas berikutnya, tetapi dipecah oleh saham pada tingkat hierarki yang lebih tinggi.
Semua pesona dan semua kemudahan adalah bahwa pekerjaan berjalan dengan jenis blok yang sama dan satu fungsi universal, semua yang diperlukan pada setiap langkah (iterasi) adalah untuk memperbaiki penggabungan vektor.

Ya, saya hampir lupa nuansa kecil: jika terjadi kesalahan dan pada akhirnya kami mendapatkan rencana yang rusak yang secara total tidak akan sama dengan rencana sebelum kerusakan - akan sulit untuk melacak di mana iterasi semuanya berjalan salah.
Oleh karena itu, kami menyediakan setiap iterasi dengan checksum:
(_)-(___ )-(___.)=0
Sekarang mari kita coba jalankan contoh kita melalui template distribusi dan lihat apa yang kita dapatkan di output.
Pertama, dapatkan data sumber:
library(dplyr) plan <- data_frame(pos_terr = c(" ", " ", " ", " ", " "), pos_fo = c("", "", "", "", ""), product_brend = c("brend_1", "brend_2", "brend_3", "brend_4", "brend_5"), product_class = c("class_1", "class_1", "class_2", "class_2", "class_3"), plan.sales = c(100, 200, 300, 400, 500)) fact <- data_frame(pos_terr = c(" ", " ", " ", " ", " "," ", " ", " ", " ", " "), pos_fo = c("", "","","", "", "", "", "", "", ""), product_brend = c("brend_1", "brend_1", "brend_2", "brend_2","brend_2", "brend_4", "brend_4", "brend_1", "brend_2", "brend_4"), product_class = c("class_1", "class_1", "class_1","class_1","class_1", "class_2", "class_2", "class_1", "class_1", "class_2"), pos_channell = c("", "", "","", "", "", "", "", "", ""), fact.sales = c(16.38, 11.64, 30.73,60, 20, 6.40, 26.49, 46.63, 65.96, 98.81)) </soure> ( ) . <source> plan.remain <- plan result.total <- data_frame()
1. Kami mendistribusikan oleh Terr, FD (distrik federal), merek, kelas merge.fields <- c("pos_terr","pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) # - plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) # = cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 2. Kami mendistribusikan berdasarkan pho, merek, kelas (yaitu, kami meninggalkan wilayah sebenarnya)
2. Kami mendistribusikan berdasarkan pho, merek, kelas (yaitu, kami meninggalkan wilayah sebenarnya)Satu-satunya perbedaan dari blok pertama adalah mereka sedikit menyingkat merge.fields dengan menghapus pos_terr di dalamnya
merge.fields <- c("pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
3. Bagikan berdasarkan pho, kelas merge.fields <- c("pos_fo", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
4. Bagikan berdasarkan kelas merge.fields <- c( "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 5. Mendistribusikan oleh FD
5. Mendistribusikan oleh FD merge.fields <- c( "pos_fo") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
Seperti yang Anda lihat, tidak ada rencana "tidak-gergajian" yang tersisa dan aritmatika dari rencana yang didistribusikan sama dengan yang asli.

Dan inilah hasilnya dengan saluran penjualan (di kolom kanan, fungsinya menampilkan bidang untuk penggandaan / agregasi apa, sehingga nantinya kita bisa memahami dari mana asal distribusi ini):

Itu saja. Artikel itu tidak terlalu kecil, tetapi ada lebih banyak teks penjelasan daripada kode itu sendiri.
Saya harap pendekatan yang fleksibel ini akan menghemat waktu dan saraf bukan hanya untuk saya :-)
Terima kasih atas perhatian anda