Halo, Habr!
Setelah banyak mencari panduan berkualitas tinggi tentang pohon keputusan dan algoritma ensemble (boosting, decision forest, dll.) Dengan implementasi langsung mereka dalam bahasa pemrograman, dan tanpa menemukan apa pun (siapa pun yang menemukan - tulis di komentar, mungkin saya akan belajar sesuatu yang baru), Saya memutuskan untuk membuat kepemimpinan saya sendiri, karena saya ingin melihatnya. Tugas dalam kata-kata itu sederhana, tetapi, seperti yang Anda tahu, iblis ada dalam hal-hal kecil, di mana ada banyak algoritma dengan pohon.
Karena topiknya cukup luas, akan sangat sulit untuk memasukkan semuanya ke dalam satu artikel, sehingga akan ada dua publikasi: yang pertama dikhususkan untuk pohon, dan bagian kedua akan dikhususkan untuk implementasi algoritma peningkatan gradien. Semua materi yang disajikan di sini disusun dan dirancang berdasarkan sumber terbuka, kode saya, kode kolega dan teman. Saya memperingatkan Anda segera, akan ada banyak kode.
Jadi apa yang perlu Anda ketahui dan dapat belajar bagaimana menulis algoritma ensemble Anda sendiri dengan pohon keputusan dari awal? Karena ensemble algoritme tidak lebih dari komposisi "algoritme lemah", menulis ensembel yang baik membutuhkan "algoritme lemah" yang baik, kami akan menganalisisnya secara terperinci dalam artikel ini. Seperti namanya, ini adalah pohon yang penting, dan bergerak dari yang sederhana ke yang kompleks, kita akan belajar bagaimana menulisnya. Dalam hal ini, penekanan akan ditempatkan langsung pada implementasi, keseluruhan teori akan disajikan dalam minimum, pada dasarnya saya akan memberikan tautan ke materi untuk studi independen.
Untuk mempelajari materi, Anda perlu memahami seberapa baik atau buruk algoritma kami. Kami akan memahami dengan sangat sederhana - kami akan memperbaiki beberapa set data tertentu dan kami akan membandingkan algoritma kami dengan algoritma pohon dari Sklearn (well, apa yang akan terjadi tanpa perpustakaan ini). Kami akan membandingkan banyak hal: kompleksitas algoritme, metrik data, waktu aktif, dll.
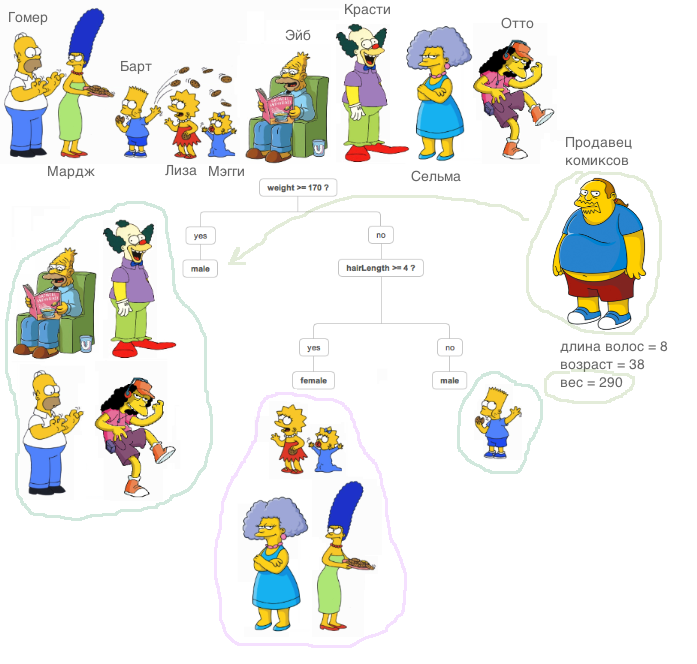
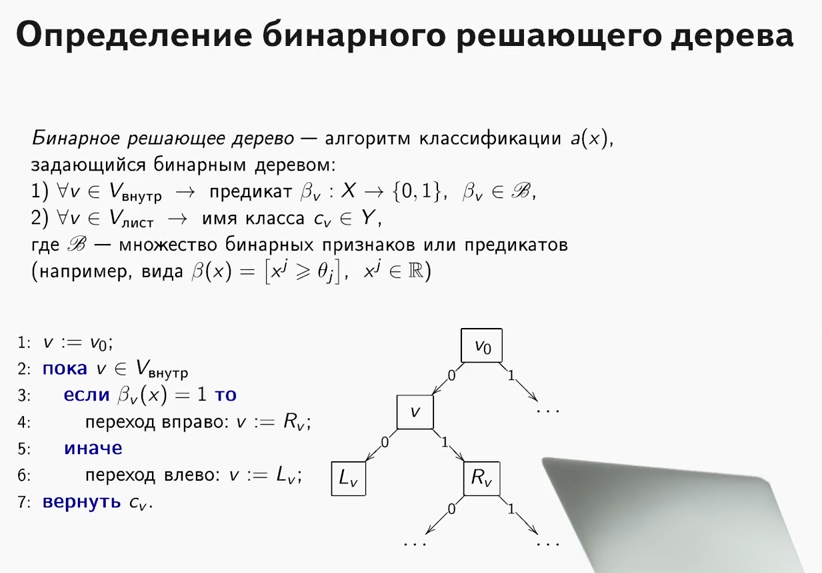
Apa itu pohon yang menentukan? Bahan yang sangat bagus, yang menjelaskan prinsip pohon keputusan, terkandung
dalam kursus ODS (omong-omong, kursus keren, saya merekomendasikannya kepada mereka yang memulai perkenalan mereka dengan ML).
Penjelasan yang sangat penting: dalam semua kasus yang dijelaskan di bawah ini, semua tanda akan nyata, kami tidak akan melakukan transformasi khusus dengan data di luar algoritme (kami membandingkan algoritme, bukan kumpulan data).
Sekarang mari kita belajar bagaimana menyelesaikan masalah regresi menggunakan pohon keputusan. Kami akan menggunakan metrik
MSE sebagai entropi.
Kami menerapkan kelas
RegressionTree sangat sederhana, yang didasarkan pada pendekatan rekursif. Secara sengaja, kita mulai dengan implementasi yang sangat tidak efektif, tetapi mudah untuk memahami kelas tersebut agar dapat meningkatkannya di masa depan.
1. kelas RegressionTree ()
class RegressionTree(): ''' RegressionTree . , . ''' def __init__(self, max_depth=3, n_epoch=10, min_size=8): ''' . ''' self.max_depth = max_depth
Saya akan menjelaskan secara singkat apa yang dilakukan masing-masing metode di sini.
Metode
fit , sesuai namanya, mengajarkan model. Sampel pelatihan diterapkan pada input dan prosedur pelatihan pohon dilakukan. Mengurutkan tanda-tanda, kami mencari partisi pohon terbaik dalam hal mengurangi entropi, dalam hal ini
mse . Untuk menentukan bahwa itu mungkin untuk menemukan perpecahan yang baik adalah sangat sederhana, itu sudah cukup untuk memenuhi dua syarat. Kami tidak ingin beberapa objek jatuh ke partisi (perlindungan terhadap pelatihan ulang), dan kesalahan rata-rata untuk
mse harus lebih kecil daripada kesalahan yang sekarang ada di pohon - kami mencari keuntungan yang sama dalam
perolehan informasi . Setelah melalui semua tanda dan semua nilai unik sedemikian rupa, kita akan melalui semua opsi dan memilih partisi terbaik. Dan kemudian kami melakukan panggilan rekursif pada partisi yang diterima sampai kondisi untuk keluar rekursi terpenuhi.
Metode
__predict , seperti namanya, membuat predikat. Setelah menerima objek sebagai input, ia akan melewati node-node dari pohon yang dihasilkan - di setiap node nomor atribut dan nilai ditetapkan padanya, dan tergantung pada nilai apa yang digunakan metode masuk objek untuk atribut ini, kita pergi ke turunan kanan atau ke kiri, sampai kita sampai pada lembar, di mana akan ada jawaban untuk objek ini.
Metode
predict melakukan hal yang sama dengan metode sebelumnya, hanya untuk sekelompok objek.
Kami mengimpor kumpulan data rumah California yang terkenal. Ini adalah dataset reguler dengan data dan target untuk menyelesaikan masalah regresi.
data = datasets.fetch_california_housing() X = np.array(data.data) y = np.array(data.target)
Baiklah, mari kita mulai perbandingan! Pertama, mari kita lihat seberapa cepat algoritma belajar. Kami menetapkan di Sklearn dan kami satu-satunya parameter
max_depth , biarkan sama dengan 2.
%%time A = RegressionTree(2)
from sklearn.tree import DecisionTreeRegressor %%time model = DecisionTreeRegressor(max_depth=2)
Berikut ini akan ditampilkan:
- Untuk algoritma kami - waktu CPU: pengguna 4 menit 47, sistem: 8,25 ms, total: 4 menit 47s
Waktu dinding: 4 menit 47-an - Untuk Sklearn - waktu CPU: pengguna 53,5 ms, sys: 0 ns, total: 53,5 ms
Waktu dinding: 53,4 ms
Seperti yang Anda lihat, algoritme belajar ribuan kali lebih lambat. Apa alasannya Mari kita perbaiki.
Ingat bagaimana prosedur untuk menemukan partisi terbaik diatur. Seperti yang Anda tahu, dalam kasus umum, dengan ukuran objek
N dan dengan jumlah tanda
d , kesulitan menemukan split terbaik adalah
O(N∗logN∗d) .
Dari mana datangnya kompleksitas ini?
Pertama, untuk menghitung ulang kesalahan secara efektif, perlu menyortir semua kolom untuk pindah dari yang terkecil ke yang terbesar sebelum melewati atribut. Saat kami melakukan ini untuk setiap sifat, ini menciptakan kompleksitas yang sesuai. Seperti yang Anda lihat, kami mengurutkan tanda-tanda, tetapi masalahnya terletak pada menghitung ulang kesalahan - setiap kali kami mengarahkan data ke metode
mse , yang bekerja untuk baris. Ini membuat kesalahan penghitungan ulang jadi tidak efisien! Setelah semua, maka kesulitan menemukan perpecahan meningkat menjadi
O(N2∗d) untuk yang besar
N sangat memperlambat algoritma. Karena itu, kami melanjutkan dengan lancar ke item berikutnya.
2. Kelas RegressionTree () dengan penghitungan kesalahan cepat
Apa yang perlu dilakukan untuk dengan cepat menceritakan kesalahan? Ambil pena dan kertas, dan cat bagaimana kita harus mengubah formula.
Misalkan pada beberapa langkah sudah ada kesalahan dihitung
N benda. Ini memiliki rumus berikut:
sumni=1(yi− frac sumNi=1yiN)2 . Di sini perlu untuk membagi dengan
N tetapi untuk sekarang mari kita hilangkan itu. Kami ingin cepat mendapatkan kesalahan ini -
sumN−1i=1(yi− frac sumN−1i=1yiN−1)2 , yaitu, membuang kesalahan yang elemen perkenalkan
yi ke bagian lain.
Karena kita melempar objek, kesalahan harus diceritakan di dua tempat - di sisi kanan (tidak termasuk objek ini) dan di sisi kiri (memperhitungkan objek ini). Tetapi tanpa kehilangan keumuman kami akan menyimpulkan hanya satu formula, karena mereka akan serupa.
Karena kami bekerja dengan
mse , kami kurang beruntung: agak sulit untuk mendapatkan penghitungan ulang kesalahan yang cepat, tetapi ketika bekerja dengan metrik lain (misalnya, kriteria Gini, jika kami menyelesaikan masalah klasifikasi), penghitungan ulang cepat jauh lebih mudah.
Baiklah, mari kita mulai membuat formula!
sumNi=1(yi− frac sumNi=1yiN)2= sumN−1i=1(yi− frac sumNi=1yiN)2+(yN− frac sumNi=1yiN)2
Kami akan menulis anggota pertama:
sumN−1i=1(yi− frac sumNi=1yiN)2= sumN−1i=1(yi− frac sumN−1i=1yi+yNN)2= sumN−1i=1( fracNyi− sumN−1i=1yiN− fracyNN)2= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN− fracyN−yiN)2= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN)2−2( frac(N−1)yi− sumN−1i=1yiN) fracyN−yiN+( fracyN−yiN)2= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN)2− sumN−1i=1(2( frac(N−1)yi− sumN−1i=1yiN) fracyN−yiN−( fracyN−yiN)2)= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN−1)2∗( fracN−1N)2− sumN−1i=1(2( frac(N−1)yi− sumN−1i=1yiN) fracyN−yiN−−( fracyN−yiN)2)
Ugh, hanya tersisa sedikit. Tetap hanya untuk menyatakan jumlah yang diperlukan.
sumNi=1(yi− frac sumNi=1yiN)2= sumN−1i=1( frac(N−1)yi− sumN−1i=1yiN−1)2∗( fracN−1N)2− sumN−1i=1(2( frac(N−1)yi− sumN−1i=1yiN)( fracyN−yiN)−( fracyN−yiN)2)+(yN− sumNi=1 fracyiN)2
Dan kemudian jelas bagaimana mengekspresikan jumlah yang diinginkan. Untuk menghitung ulang kesalahan, kita hanya perlu menyimpan jumlah elemen di kanan dan kiri, serta elemen baru itu sendiri, yang sampai pada input. Sekarang kesalahan dihitung ulang untuk
O(1) .
Baiklah, mari kita terapkan ini dalam kode.
class RegressionTreeFastMse(): ''' RegressionTree . O(1). '''
Mari kita ukur waktu yang sekarang dihabiskan untuk pelatihan, dan bandingkan dengan analog dari Sklearn.
%%time A = RegressionTreeFastMse(4, min_size=5) A.fit(X,y) test_mytree = A.predict(X) test_mytree
%%time model = DecisionTreeRegressor(max_depth=4) model.fit(X,y) test_sklearn = model.predict(X)
- Untuk algoritme kami, kami dapatkan - waktu CPU: pengguna 3,11 s, sys: 2,7 ms, total: 3,11 s
Waktu dinding: 3,11 dtk. - Untuk algoritma dari Sklearn - waktu CPU: pengguna 45,9 ms, sys: 1,09 ms, total: 47 ms
Waktu dinding: 45,7 ms.
Hasilnya sudah lebih menyenangkan. Baiklah, mari kita lebih lanjut meningkatkan algoritma.
3. RegressionTree () kelas dengan kombinasi fitur linear
Sekarang, dalam algoritma kami, hubungan antara atribut tidak digunakan dengan cara apa pun. Kami memperbaiki satu fitur dan hanya melihat partisi ruang orthogonal. Bagaimana cara belajar menggunakan hubungan linear antar atribut? Artinya, untuk mencari partisi terbaik tidak suka
afeat<x , dan
sumKi=1bi∗ai<x dimana
K - Apakah angka lebih kecil dari dimensi ruang kita?
Ada banyak pilihan, saya akan menyoroti dua yang paling menarik dari sudut pandang saya. Kedua pendekatan ini dijelaskan dalam
buku Friedman (ia menemukan pohon-pohon ini).
Saya akan memberikan gambar sehingga jelas apa yang dimaksud:

Pertama, Anda dapat mencoba menemukan partisi linear ini secara algoritmik. Jelaslah bahwa mustahil untuk memilah-milah semua kombinasi linier, karena ada jumlah tak terhingga dari kombinasi, sehingga algoritma semacam itu harus serakah, yaitu, pada setiap iterasi, meningkatkan hasil iterasi sebelumnya. Gagasan utama dari algoritma ini dapat dibaca dalam buku ini, saya juga akan meninggalkan tautan di sini ke
repositori teman dan kolega saya dengan penerapan algoritma ini.
Kedua, jika kita tidak jauh dari ide menemukan partisi ortogonal terbaik, lalu bagaimana kita memodifikasi dataset sehingga informasi tentang hubungan fitur digunakan dan pencarian didasarkan pada partisi ortogonal? Itu benar, untuk membuat semacam transformasi fitur asli menjadi yang baru. Misalnya, Anda dapat mengambil jumlah dari beberapa kombinasi fitur dan mencari partisi dengan mereka. Metode seperti itu lebih cocok dengan konsep algoritmik, tetapi melakukan tugasnya - ia mencari partisi ortogonal yang sudah ada dalam semacam interkoneksi atribut.
Baiklah, mari kita implementasikan - kita akan menambahkan sebagai fitur baru, misalnya, semua jenis kombinasi jumlah fitur
i,j dimana
I<j . Saya perhatikan bahwa kompleksitas algoritma dalam hal ini akan meningkat, sudah jelas berapa kali. Nah, agar bisa dianggap lebih cepat, kita akan menggunakan cython.
%load_ext Cython %%cython -a import itertools import numpy as np cimport numpy as np from itertools import * cdef class RegressionTreeCython: cdef public int max_depth cdef public int feature_idx cdef public int min_size cdef public int averages cdef public np.float64_t feature_threshold cdef public np.float64_t value cpdef RegressionTreeCython left cpdef RegressionTreeCython right def __init__(self, max_depth=3, min_size=4, averages=1): self.max_depth = max_depth self.min_size = min_size self.value = 0 self.averages = averages self.feature_idx = -1 self.feature_threshold = 0 self.left = None self.right = None def data_transform(self, np.ndarray[np.float64_t, ndim=2] X, list index_tuples):
4. Perbandingan hasil
Baiklah, mari kita bandingkan hasilnya. Kami akan membandingkan tiga algoritma dengan parameter yang sama - pohon dari Sklearn, pohon biasa dan pohon kami dengan fitur baru. Kami akan membagi set data kami menjadi beberapa set pelatihan dan tes, dan menghitung kesalahan.
from sklearn.model_selection import KFold def get_metrics(X,y,n_folds=2, model=None): kf = KFold(n_splits=n_folds, shuffle=True) kf.get_n_splits(X) er_list = [] for train_index, test_index in kf.split(X): X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] model.fit(X_train,y_train) predict = model.predict(X_test) er_list.append(mse(y_test, predict)) return er_list
Sekarang mari kita jalankan semua algoritma.
import matplotlib.pyplot as plt data = datasets.fetch_california_housing() X = np.array(data.data) y = np.array(data.target) er_sklearn_tree = get_metrics(X,y,30,DecisionTreeRegressor(max_depth=4, min_samples_leaf=10)) er_fast_mse_tree = get_metrics(X,y,30,RegressionTreeFastMse(4, min_size=10)) er_averages_tree = get_metrics(X,y,30,RegressionTreeCython(4, min_size=10)) %matplotlib inline data = [er_sklearn_tree, er_fast_mse_tree, er_averages_tree] fig7, ax7 = plt.subplots() ax7.set_title('') ax7.boxplot(data, labels=['Sklearn Tree', 'Fast Mse Tree', 'Averages Tree']) plt.grid() plt.show()
Hasil:

Pohon reguler kami hilang dari Sklearn (yang bisa dimengerti: Sklearn dioptimalkan dengan baik, dan secara default masih ada banyak parameter di pohon yang tidak kami perhitungkan), tetapi ketika menambahkan jumlah, hasilnya menjadi lebih menyenangkan.
Untuk meringkas: kami belajar bagaimana menulis pohon yang menentukan dari awal, belajar bagaimana meningkatkan kinerja mereka dan menguji efektivitasnya pada dataset nyata dengan membandingkannya dengan algoritma dari Sklearn. Namun, metode yang disajikan di sini tidak membatasi peningkatan algoritma, jadi perlu diingat bahwa kode yang diusulkan dapat dibuat lebih baik. Pada artikel selanjutnya, kami akan menulis peningkatan berdasarkan algoritma ini.
Semua sukses!