Layanan harus ditulis agar fungsi minimal selalu dipertahankan - bahkan jika komponen penting gagal. Ilya Sidorov, kepala salah satu tim pengembangan produk backend Yandex.Taxi, menjelaskan dalam laporannya bagaimana kami membiarkan pengguna memesan mobil ketika bagian-bagian tertentu dari sistem tidak berfungsi, dan dengan logika apa kami mengaktifkan versi layanan yang disederhanakan.
Penting untuk menulis tidak hanya layanan yang bekerja dengan baik, tetapi juga layanan yang berhasil dengan baik.
"Aku sangat senang melihat kalian semua." Hari ini saya akan berbicara tentang degradasi yang anggun. Jika Anda mencarinya di Yandex, kemungkinan besar Anda akan belajar cara membuat situs Anda berfungsi tanpa JS. Saya akan ceritakan sedikit tentang hal lain. Tentang degradasi anggun dalam kaitannya dengan backend.

Mari kita mulai dengan definisi. Seperti apa kenyataannya?
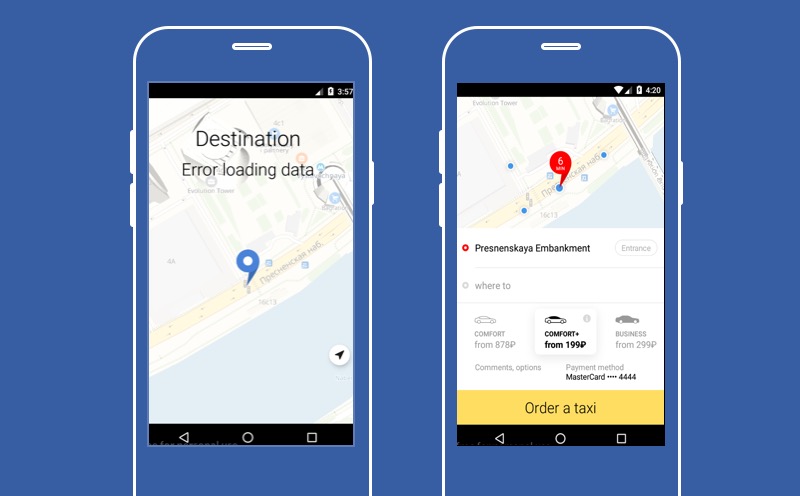
Di sinilah aplikasi Yandex.Taxi kami disajikan jika salah satu layanan tidak berfungsi - layanan untuk memilih tujuan di mana pengemudi harus membawa Anda. Seperti yang Anda lihat, pada layar ini tidak ada tombol besar "Pesan taksi", yang berarti bahwa pengguna tidak akan dapat menggunakan layanan ini. Tetapi Anda dapat mencoba menurunkan dan memungkinkan pengguna untuk tidak memilih titik B.
Maka dia tidak akan dapat mengetahui harga pasti dari perjalanan, kita tidak akan dapat membangun rute, tetapi pengguna akan memiliki tombol "Pesan taksi" dan dia akan dapat menggunakan layanan kami. Fungsi utama aplikasi kita akan tersedia. Itulah yang ingin saya bicarakan hari ini. Tentang cara mendegradasi dengan benar dan apa yang dapat dilakukan dengan layanan yang rusak.
Rencana kinerja. Saya akan memberi tahu Anda cara menurunkan apa yang harus dilakukan dengan layanan. Anda dapat mematikannya, dan juga menggunakan perilaku yang berbeda. Maka saya akan memberi tahu Anda cara memahami kapan saatnya mematikan layanan kami. Dan pada akhirnya saya akan berbicara tentang beberapa nuansa yang harus kami hadapi ketika kami membuat sistem degradasi otomatis untuk Yandex.Taxi.
Apa yang bisa dilakukan dengan layanan yang rusak? Anda dapat mematikan fungsionalitas. Jika layanan untuk memprediksi tujuan individu tidak berfungsi, maka Anda mematikan layanan ini. Jika obrolan antara pengemudi dan penumpang tidak berfungsi, maka Anda mematikan obrolan. Jika Anda tidak dapat memesan mobil, maka Anda mematikan tombol "Pesan mobil" - oh, tidak, itu tidak berfungsi. Tidak semua fungsi dapat dimatikan. Dan jika Anda tidak dapat mematikan sesuatu, maka Anda perlu menggunakan pendekatan yang berbeda. Misalnya, Anda dapat mencoba membuat tata letak atau fungsionalitas yang disederhanakan. Kami menyebut perilaku yang disederhanakan di Yandex sebagai labu - kami mengatakan bahwa layanan tersebut telah berubah menjadi labu.
Mari kita pertimbangkan solusi ini secara lebih rinci.
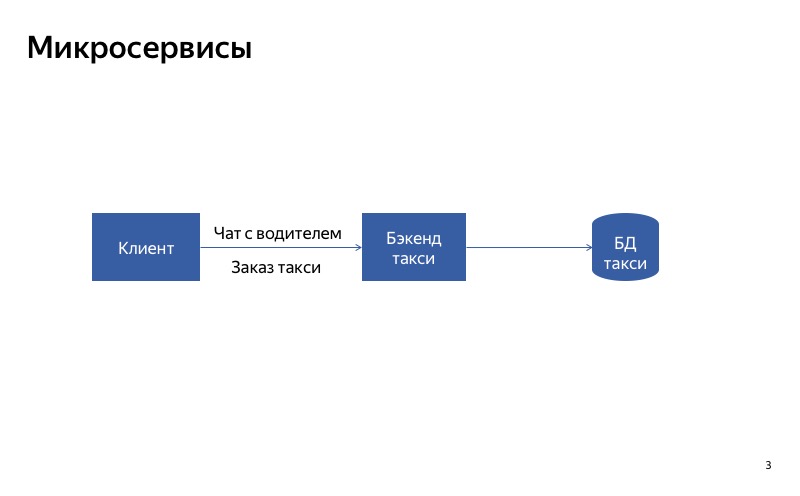
Bagaimana cara menonaktifkan layanan? Anda mungkin dapat membuat arsitektur yang tepat. Misalkan kita memiliki satu layanan monolitik. Jika salah satu bagiannya gagal, maka seluruh layanan rusak. Tetapi jika kita membagi layanan menjadi beberapa bagian sehingga pelanggan menggunakan layanan yang berbeda untuk permintaan yang berbeda, itu akan menjadi jauh lebih baik.
Bagaimana ini akan bekerja pada contoh? Ada layanan Yandex.Taxi, di mana ada dua fungsi utama: memesan taksi dan mengobrol dengan pengemudi. Selama kita memiliki satu backend monolitik, jika obrolan dengan pengemudi gagal, fungsi dasar memesan taksi akan terpengaruh.
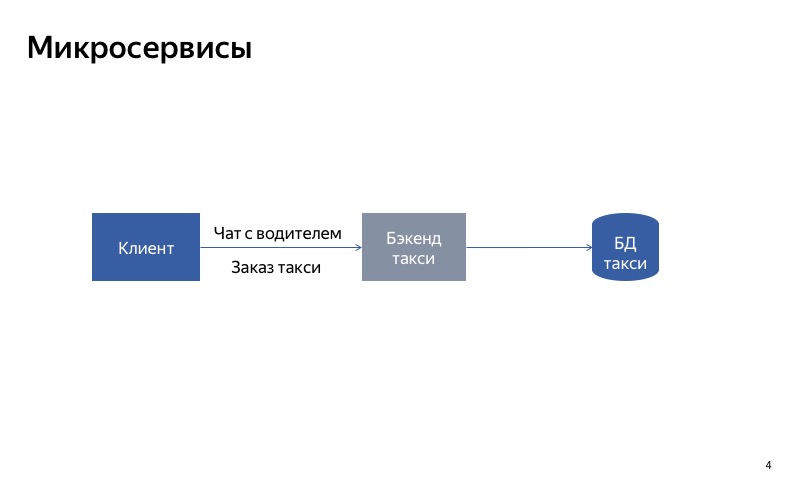
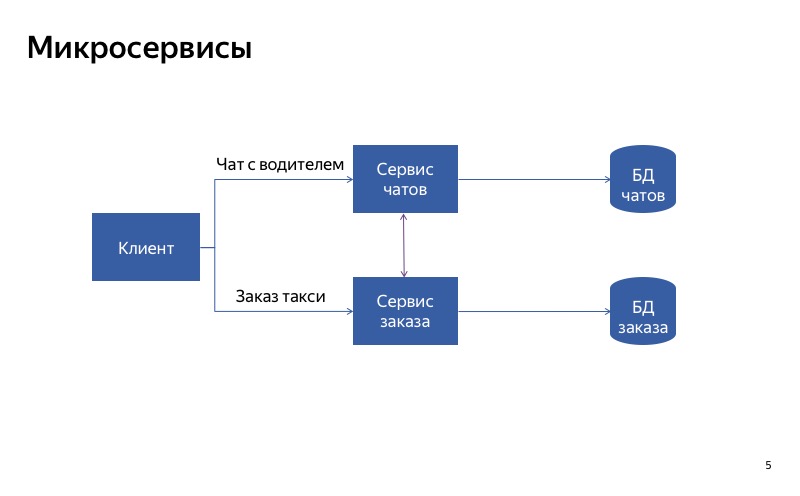
Apa yang bisa Anda coba lakukan? Bagilah layanan monolitik menjadi dua bagian. Satu bagian akan bertanggung jawab untuk memesan taksi, dan yang lainnya - untuk komunikasi dengan pengemudi.
Sekarang semuanya terlihat jauh lebih baik. Jika obrolan dengan sopir rusak, maka semua yang lain terus berfungsi dengan benar.
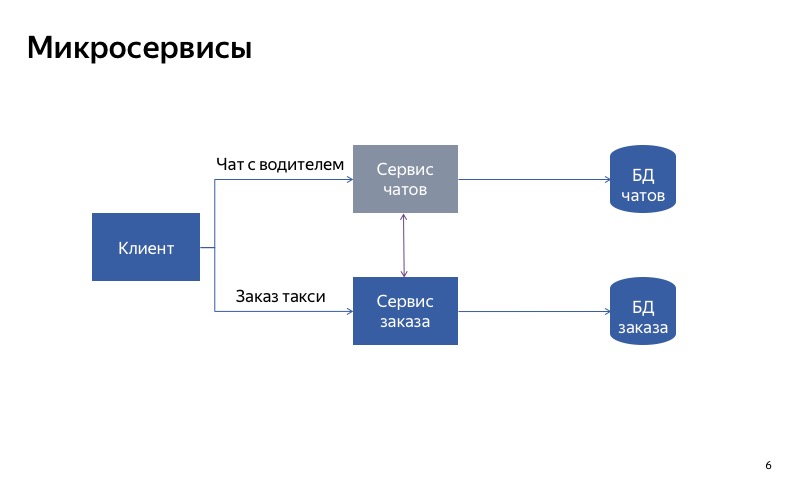
Seperti yang Anda lihat, klien menggunakan API yang berbeda, permintaan yang berbeda untuk melakukan pemesanan dan berkomunikasi dengan pengemudi.
Tetapi pada kenyataannya, tampaknya sekarang semuanya tidak begitu baik, karena ada koneksi palsu antara layanan obrolan dan layanan pesanan. Dan mungkin ternyata layanan pesanan menggunakan layanan obrolan kosong. Dalam hal ini, fungsi utama tidak akan berfungsi.
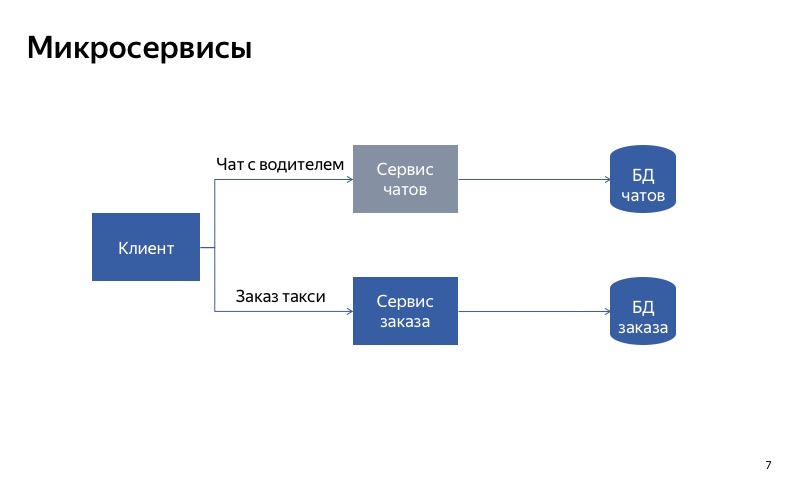
Dan dalam hal ini, semuanya jauh lebih baik. Komunikasi palsu telah menghilang, dan sekarang layanan kami benar-benar independen satu sama lain. Jadi, jika layanan obrolan mogok, Anda masih bisa naik taksi.
Kesimpulan dari ini adalah sebagai berikut: jika Anda ingin menurunkan menggunakan pemisahan layanan, sangat penting untuk membuat layanan independen satu sama lain. Ini berarti bahwa mereka harus memiliki titik masuk yang berbeda, titik akhir yang berbeda. Mereka harus memiliki runtimes yang berbeda. Dan tentu saja, mereka harus menggunakan basis data yang berbeda. Jika tidak, satu layanan rusak dapat menghancurkan semua layanan lainnya di sepanjang rantai.
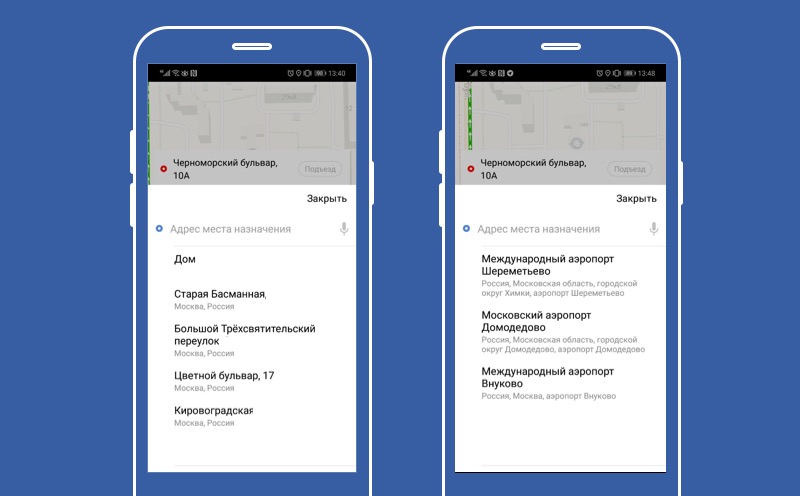
Yah, kami telah menemukan cara menonaktifkan fungsionalitas. Sekarang mari kita lihat bagaimana membuat fungsionalitas default, cara membuat labu. Di layar ini, layanan prediksi tujuan kami. Layanan ini menggunakan AI pintar untuk memprediksi pengguna tujuan terbaik baginya saat ini. Dan jika AI sudah lelah, maka kami menggunakan perilaku default dan menawarkan pengguna untuk meninggalkan Moskow.
Mari kita lihat bagaimana ini bekerja dalam praktiknya.

Kami memiliki klien, ia menghubungi layanan tujuan dan mendapatkan kesalahan.
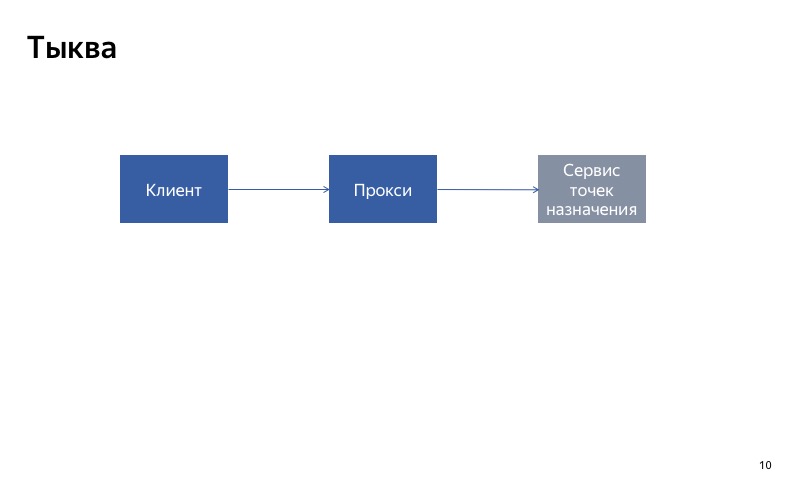
Sekarang ada dua situasi yang mungkin. Situasi pertama, jika kegagalan itu tunggal, hanya satu permintaan yang gagal. Dalam hal ini, kami hanya melakukan kesalahan kepada klien, ia akan membuat permintaan ulang dan mendapatkan tujuan favoritnya.
Tetapi jika kegagalannya masif, kami menghidupkan labu dan pengguna mendapatkan perilaku default.

Tapi perilaku keras seperti itu jauh lebih mudah untuk diterapkan, dan labu ini sangat andal, sehingga memungkinkan kita untuk bekerja bahkan ketika AI gagal. Jika kita tahu bahwa pengguna sering melakukan perjalanan ke bandara, maka kita tidak akan melihat penurunan signifikan dalam kehidupan pengguna.
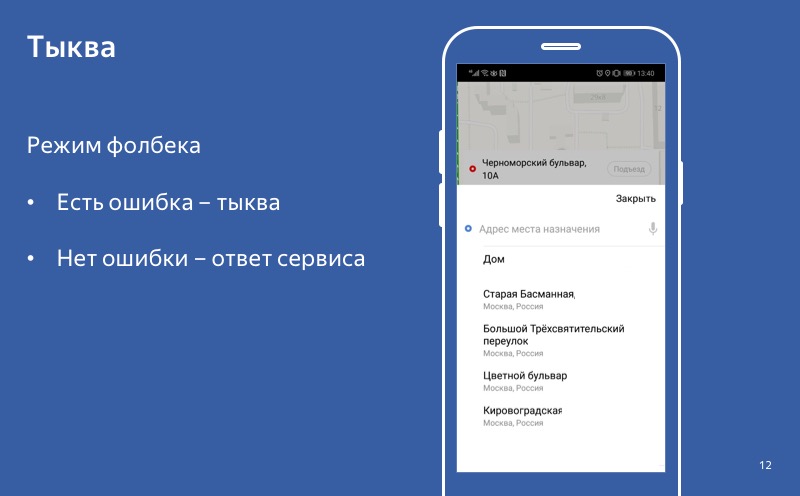
Sekalipun mode degradasi dihidupkan, labu dihidupkan, tetapi pengguna menghubungi layanan dan menerima respons yang berhasil, maka kami menggunakan jawaban ini, bukan labu. Dan perilaku ini - ketika dalam kasus jawaban kita menggunakannya, dan dalam kasus kesalahan kita menggunakan labu - kita sebut mode fallback.
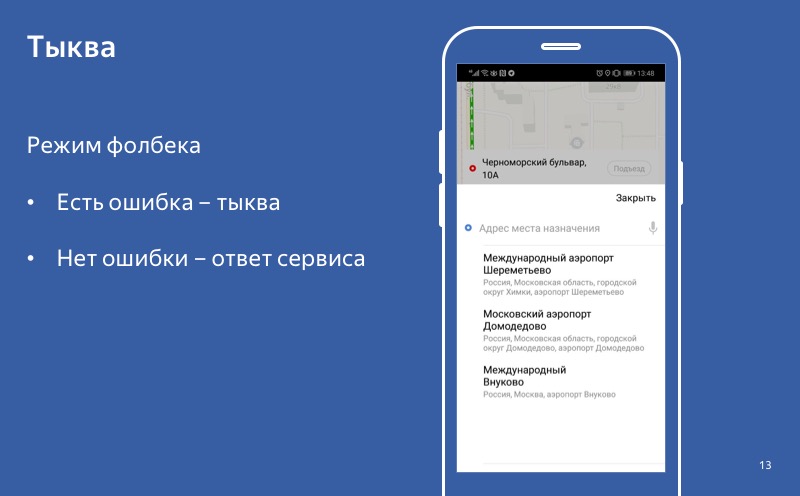
Tidak ada kesalahan - respons yang berhasil. Ada kesalahan - labu. Kami mengatakan bahwa mundur telah dihidupkan.
Saya memilah apa yang bisa dilakukan dengan layanan yang rusak. Anda dapat mematikannya, atau menghidupkan labu. Sekarang mari kita beralih ke bagian kedua dan melihat bagaimana cara mendiagnosis.
Kami memiliki dua pertanyaan besar yang perlu dijawab. Yang pertama adalah ketika Anda harus mematikan layanan dan menyalakan labu. Yang kedua adalah ketika Anda harus mematikan labu dan menyalakan layanan kembali. Sebelum kita dapat menjawab pertanyaan-pertanyaan ini, kita perlu mengklarifikasi satu hal.
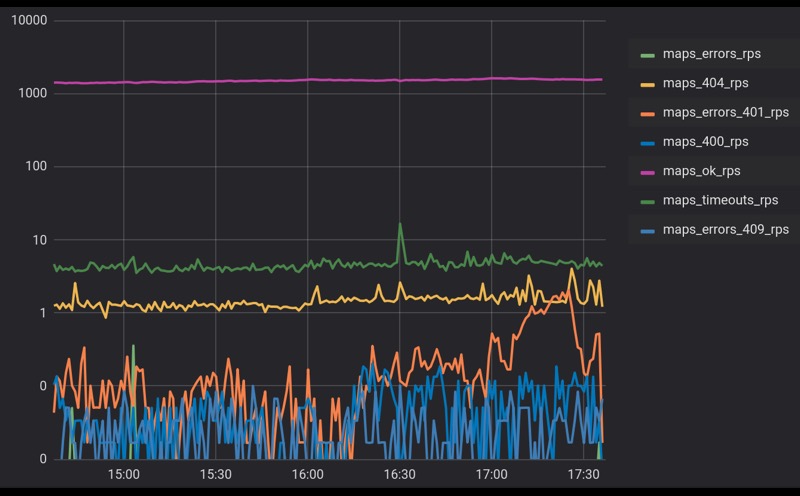
Dalam sistem kompleks yang berinteraksi dengan sejumlah besar agen, selalu ada beberapa latar belakang kesalahan. Pada slide ini kita melihat jadwal panggilan nyata ke salah satu layanan kami. Beberapa ribu RPS melakukannya, kami mendapatkan sedikit kesalahan kurang dari 1%. Ini adalah skala logaritmik.
Kesalahan bisa disebabkan oleh berbagai hal. Mungkin ini adalah semacam proses internal, memperbarui semacam database atau hanya proses latar belakang. Mungkin pelanggan pergi dengan permintaan yang salah, tetapi faktanya tetap: kami akan selalu memiliki latar belakang kesalahan. Mari kita ambil dan lanjutkan.
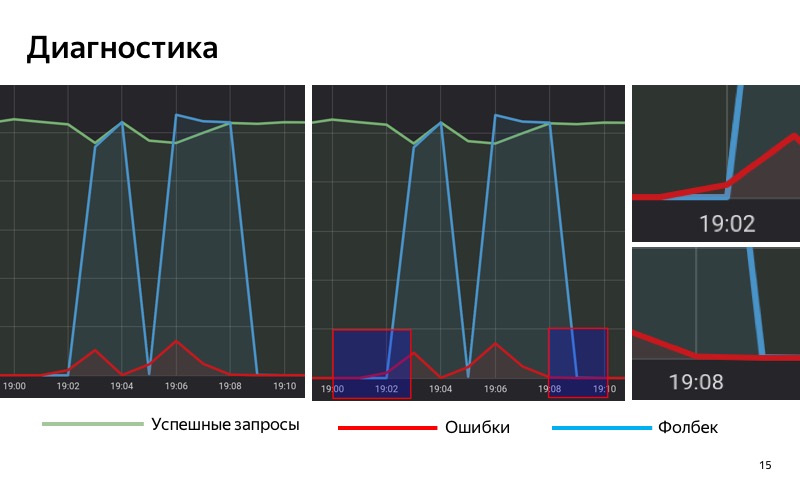
Jadi, kami menggunakan solusi berdasarkan statistik. Kami memiliki basis data khusus tempat kami menyimpan statistik, menyimpan jumlah kueri yang berhasil, jumlah kueri dengan kesalahan, dan kueri yang menyertakan fallback. Kami mengambil dan mengumpulkan statistik pada layanan kami selama periode waktu tertentu dengan jendela geser. Ketika proporsi permintaan dengan kesalahan di jendela geser ini melebihi ambang tertentu, kami mengaktifkan fallback. Dan ketika jumlah kesalahan menjadi kurang dari ambang, maka kita matikan.
Perhatikan area yang dipilih. Pada 19:01 kesalahan pertama mulai muncul, tetapi sejauh ini bagian mereka cukup kecil, dan sampai 19:02 kami tidak termasuk fallback. Pada pukul 19:02 ambang batas terlampaui, kami mengaktifkan fallback. Pada 19:08 proses sebaliknya: kesalahan berakhir, tetapi untuk beberapa waktu kami telah mundur diaktifkan, karena ambang batas masih terlampaui di jendela geser kami. Pada 19:09 kami mematikan fallback.
Kami tahu kapan harus mematikan layanan. Penting untuk menjawab pertanyaan kedua: kapan harus menyalakannya. Sederhana: kami menggunakan solusi yang sama berdasarkan statistik.
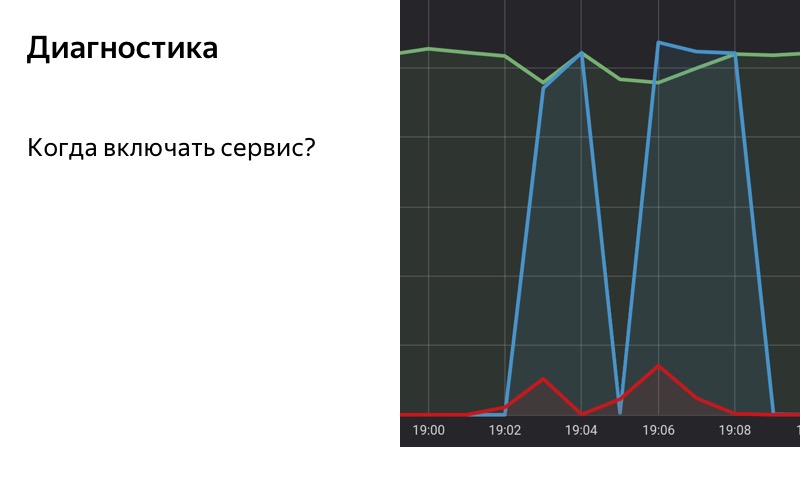
Penting bahwa kita tidak menghapus beban dari layanan, bahkan jika kita mengaktifkan mode degradasi. Inilah yang memungkinkan kami untuk terus menerima statistik bahkan jika kami menunjukkan kepada pengguna labu. Dengan demikian, kita dapat menentukan bahwa kesalahan sudah selesai, layanan diperbaiki. Jadi, Anda dapat mengaktifkannya kembali hingga penuh.
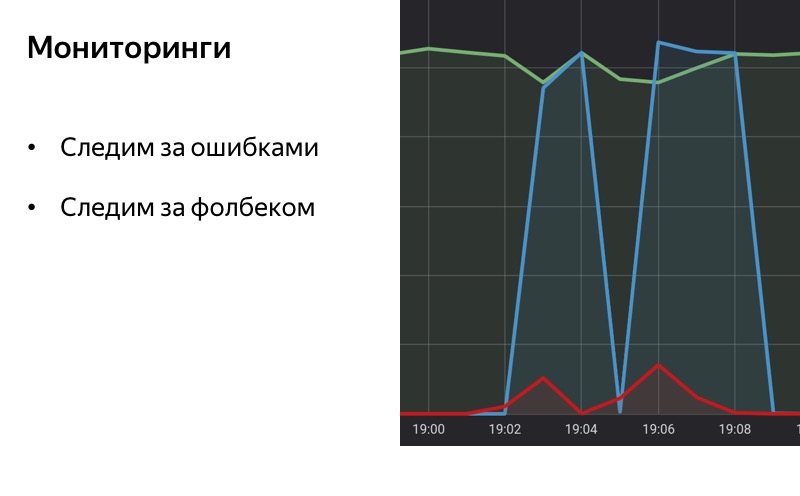
Ketika kita berbicara tentang degradasi, kita tidak bisa mengatakan tentang pemantauan. Pemantauan yang baik adalah separuh keberhasilan, separuh jalan ke shutdown otomatis atau degradasi otomatis. Penting bagi kita untuk memahami masalah apa yang terjadi dengan layanan kita, apa sifat kesalahan itu dan seberapa sering mereka terjadi. Dan mungkin pada tahap pertama kita bahkan tidak memerlukan pemutus sirkuit. Sederhananya, jika lampu pemantauan menyala, kita dapat menghidupkan dan mematikan layanan secara manual. Ketika lampu pemantauan padam, kami menghidupkan layanan.
Jika kita melakukan degradasi otomatis, saklar otomatis, maka penting untuk melakukan pemantauan pada fallback itu sendiri. Jika sistem degradasi bekerja dengan cukup baik, maka pengguna, pada kenyataannya, mungkin tidak memperhatikan sama sekali bahwa ada sesuatu yang rusak di dalam kita. Kita sendiri dapat, jika tidak ada pengawasan, tidak menyadarinya. Penting untuk memantau fallback, penting untuk memahami kapan dihidupkan, ketika dimatikan, sehingga statistik tersedia dan kita dapat memahami berapa lama fungsi tidak bekerja, apakah backend kita semakin buruk atau lebih baik dari waktu ke waktu, tergantung pada berapa banyak waktu kita berpikir fallback .
Semuanya dengan bagian utama.
Pada akhirnya, saya ingin memberi tahu Anda beberapa nuansa yang harus kami hadapi ketika kami mengembangkan sistem degradasi otomatis di Yandex.Taxi.
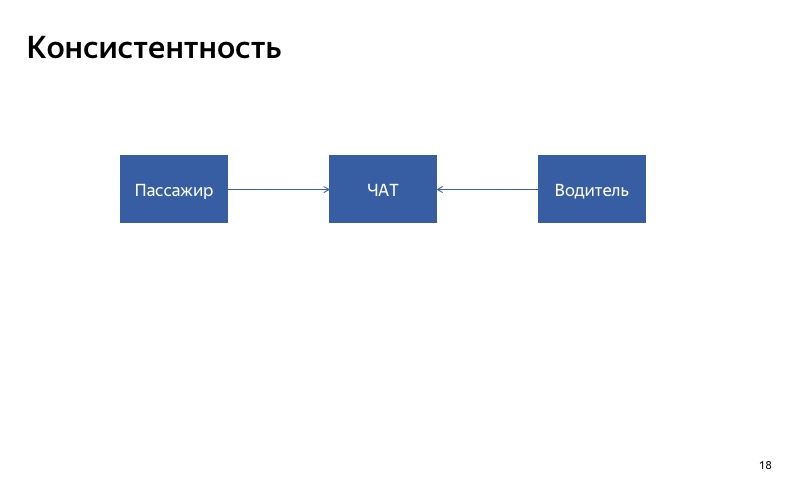
Hal pertama yang harus Anda perhatikan adalah konsistensi. Jika Anda melakukan degradasi otomatis untuk layanan tertentu, penting bahwa layanan merespons secara konsisten untuk semua pelanggannya. Jika Anda memiliki dua klien yang menggunakan layanan ini, penting bahwa jawaban untuk dua klien ini jika terjadi degradasi konsisten. Dan jika Anda memiliki layanan yang terlibat dalam beberapa proses panjang, Anda perlu memahami: mungkin pada awal dan akhir proses layanan akan bekerja dengan benar, dan di suatu tempat di mundur tengah akan diaktifkan.
Kedengarannya rumit, tapi mari kita coba jelaskan dengan sebuah contoh. Mungkin itu akan menjadi lebih jelas.
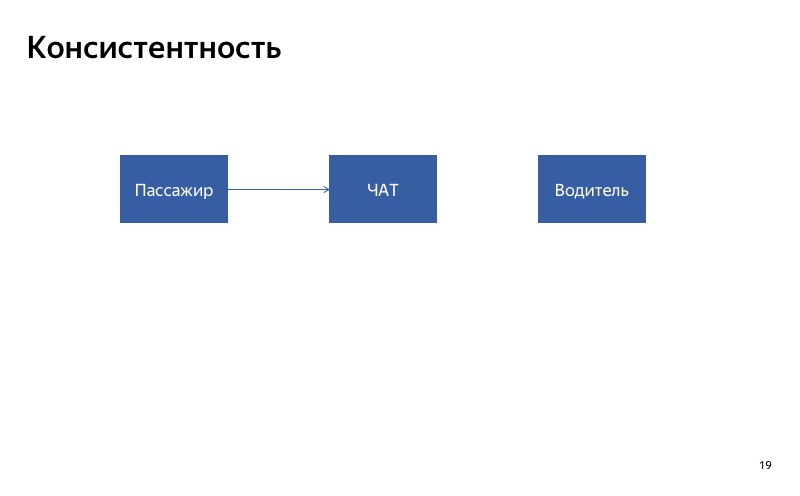
Inilah obrolan kami antara pengemudi dan penumpang. Cara termudah untuk menurunkannya adalah dengan menonaktifkannya. Bayangkan saja obrolan untuk pengemudi rusak. Apa yang akan terjadi Klien akan menulis ke obrolan, tetapi pengemudi tidak akan melihat pesan. Mereka mungkin akan sangat tidak bahagia, akan bersumpah pada aplikasi kita ketika mereka bertemu satu sama lain. Dalam hal ini, penting bahwa obrolan dihidupkan pada saat yang sama atau dimatikan pada saat yang sama untuk semua peserta dalam obrolan. Inilah yang saya sebut konsistensi.

Nuansa kedua menyangkut fakta bahwa aplikasi Yandex.Taxi kami didistribusikan secara geografis: taksi dapat dipesan di Moskow, Krasnoyarsk, atau Helsinki. Ini harus diperhitungkan bahkan ketika mengembangkan sistem degradasi. Bayangkan kami memiliki banyak permintaan yang berhasil dan sangat sedikit permintaan dengan kesalahan. Tampaknya ini adalah situasi normal, latar belakang kesalahan selalu ada. Tetapi Anda dapat melihat gambar yang sama secara berbeda.
Anda dapat melihat bahwa layanan ini tidak berfungsi di Mytishchi dan Anda harus mengaktifkan cadangan untuk pengguna ini. Kesimpulannya adalah: Anda perlu membangun statistik yang tepat. Bagi kami, sebagai layanan yang didistribusikan secara geografis, ini juga berarti bahwa kami perlu membuat statistik berdasarkan kota. Jika kami membuat statistik dengan benar, kami akan segera melihat bahwa sebagian besar permintaan dari Mytishchi terputus, dan mengaktifkan fallback khusus untuk pengguna dari Mytishchi. Dan untuk semua pengguna lain, kami akan terus bekerja dalam mode normal, karena bagi mereka layanan bekerja dengan benar.

Mungkin untuk layanan lain akan ada kondisi dan nuansa lain yang berbeda.
Layanan kami menjadi lebih kompleks. Seringkali mereka bergantung pada dunia luar, yang tidak dapat kita prediksi. Oleh karena itu, penting untuk menulis tidak hanya layanan yang berfungsi dengan baik, tetapi juga layanan yang sangat baik. Jika Anda mempelajari sesuatu yang baru, maka beri tahu kolega, bagikan. Suka, bagikan, kirim ulang. Degradasi dengan benar.