Pengantar liris
Suatu malam, meletakkan barang-barang di lemari dinding, saya menemukan sebuah kotak kardus besar. Dia selamat dari dua relokasi dan tidak membuka selama bertahun-tahun sehingga saya benar-benar lupa apa yang disimpan di dalamnya. Ternyata ada foto - di album, dalam amplop dari toko, dan ada yang seperti itu.
Banyak foto diambil lebih dari tujuh puluh tahun yang lalu. Salah satunya adalah seorang kakek - di tahun-tahun muridnya, masih muda dan tampan, dalam kacamata yang benar-benar
merusak . "Wow, kakekku mengenakan pakaian hipster bahkan sebelum itu menjadi arus utama," pikirku, dan tanpa sadar tersenyum. Saya langsung mengenalinya, tetapi kemudian pergi foto-foto orang yang saya tidak ingat. Dalam fitur wajah, samar-samar Anda bisa menebak hubungan - dan hanya itu.

Ketika saya berusia lima belas tahun, nenek saya berulang kali menunjukkan kartu-kartu ini dan berbicara tentang orang-orang yang tergambar di sana. Sayangnya, nilai cerita semacam itu hanya dipahami ketika tidak ada seorang pun yang mau menceritakannya. Pada waktu itu, benar-benar tidak menarik bagi saya untuk kesepuluh kalinya untuk mendengarkan beberapa kisah berlumut tentang tahun-tahun sebelum perang, saya melambaikan tangan mereka dan melewati telinga. Sekarang, tiba-tiba, sepenuhnya menyadari bahwa bagian dari sejarah keluarga saya hilang, saya mendapat ide untuk mensistematisasikan dan melestarikan apa yang tersisa.
Solusi ideal untuk menyimpan data keluarga bagi saya adalah hibrida dari mesin wiki dan album foto. Tidak ada solusi yang sesuai yang sudah jadi, jadi saya harus menulis sendiri. Ini disebut
Bonsai dan open source di bawah lisensi MIT. Lalu akan ada cerita tentang bagaimana itu dibangun dan bagaimana menggunakannya, serta kisah perkembangannya dan sedikit
DRAMA .

Sepeda lain?
Saat ini, ada banyak alat yang memungkinkan Anda membuat pohon keluarga dan katalog informasi tentang kerabat. Mereka secara kondisional dibagi menjadi dua kategori besar - layanan online dan aplikasi desktop.
Dalam kasus aplikasi desktop, database biasanya disimpan sebagai file pada disk. Anda membuka aplikasi dan mengisinya dalam mode pengguna tunggal. Jika perlu, data dapat diekspor untuk cadangan atau transfer ke sistem lain (misalnya, dalam format
GEDCOM ). Dari yang saya tonton, yang paling menyenangkan untuk digunakan adalah
Gramps (gratis) dan
Life Tree domestik (membutuhkan pembelian satu kali).
Sisi berlawanan dari spektrum adalah layanan web. Mereka menyimpan data Anda di server jarak jauh dan membebankan biaya penggunaan berkala. Karena ini adalah produk komersial dengan basis terpusat dan monetisasi yang baik, layanan dari rencana ini memberi Anda kesempatan, misalnya, untuk mencari kerabat yang hilang melalui tes DNA atau catatan arsip.
Pro dan kontra dari kedua opsi tersebut cukup jelas. Dalam kasus pertama, Anda menyimpan basis data secara lokal dan sepenuhnya mengontrol akses ke sana dan membuat cadangan. Jika aplikasi ini open source, jika perlu, Anda bahkan dapat menambahkan fungsionalitas tambahan untuk itu. Namun, bekerja dengan database seperti itu bersama-sama atau melihat data dari perangkat lain akan sulit. Yang kedua, sebaliknya, akses berasal dari perangkat apa pun, tetapi Anda memberikan data Anda kepada pihak ketiga dan berharap kesopanannya. Namun, dalam sejarah keluarga saya, tidak ada kompromi dan rahasia yang mengerikan, namun, saya masih menganggap informasi ini sepenuhnya bersifat pribadi dan, pada prinsipnya, saya tidak ingin orang lain menyimpan atau menganalisisnya.
Mengingat kekurangan dari kedua pendekatan ini, kami dapat merumuskan daftar persyaratan untuk mesin "ideal":
- Aplikasi web di-host di server Anda sendiri
- Membuat artikel tentang orang, hewan peliharaan, tempat, acara, dll. seperti wiki
- Unduh Media
- Tanda orang di foto dan video
- Bangunan pohon keluarga otomatis
- Kalender dengan semua tanggal penting.
- Alat untuk mengedit bersama dan mengisi
Dalam keadilan, saya berhasil menemukan beberapa proyek dengan implementasi yang di-host-sendiri, tetapi mereka dalam keadaan menyedihkan: penampilan membeku di tingkat pertengahan 2000-an, tidak ada set lengkap fungsionalitas yang diperlukan, dan saya tidak ingin menggali skrip warisan dalam PHP. Selain itu, proyek hewan peliharaan sebelumnya sudah selesai dan ada keinginan untuk mengambil sesuatu yang baru.
Aturan emas mengatakan:
jika Anda ingin melakukannya dengan baik - lakukan sendiri!Teknologi yang digunakan dipilih berdasarkan tiga kriteria: pengalaman saya dengan mereka, popularitas dan bebas keterbukaan. Inilah hasilnya:
- Rantime : .NET Core 2.1
- Backend : ASP.NET Core MVC
- Basis Data : PostgreSQL
- Frontend logic : sebagian Vue, sebagian jQuery.
- Frontend Styles : Bootstrap + Sass
Peran pendukung termasuk Elasticsearch untuk pencarian teks lengkap dan ffmpeg untuk mengambil screenshot dari video.
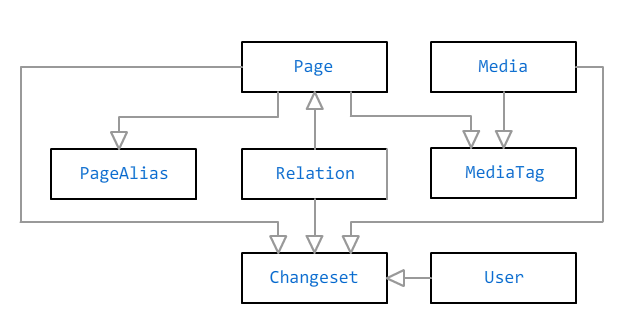
Skema data
Objek utama dalam database Bonsai adalah
halaman dan
file media . Mereka terhubung oleh hubungan banyak-ke-banyak melalui
tanda . Tag dapat memiliki judul tanpa tautan - misalnya, jika Anda perlu memberi tag seseorang di foto, tetapi tidak ada informasi di halaman penuh tentang hal itu.
Selain teks gratis, halaman mungkin berisi
fakta yang dimasukkan dalam bidang khusus di panel admin. Fakta tambahan dihitung berdasarkan fakta: misalnya, jika Anda menunjukkan tanggal lahir orang tersebut, itu akan ditandai pada kalender, dan halamannya akan menunjukkan usia saat ini (atau harapan hidup, jika tanggal kematian juga diindikasikan), jenis kelamin dapat digunakan untuk menentukan nama hubungan yang benar (“ayah "Atau" ibu "bukannya" orang tua "yang umum), dan sebagainya. Fakta-fakta disimpan dalam database sebagai dokumen JSON.
Ada lima jenis halaman untuk dipilih: orang, hewan peliharaan, acara, tempat, dan sebagainya. Daftar fakta yang tersedia tergantung pada jenis halaman: misalnya, "pendidikan" hanya relevan untuk seseorang, "tanggal lahir" adalah untuk seseorang dan hewan, dan "alamat" hanya untuk tempat.
Halaman saling berhubungan oleh
hubungan : "orang tua", "pasangan", "teman", "pemilik", "penduduk" dan banyak lainnya. Beberapa hubungan mungkin terbatas dalam waktu (pasangan, pemilik, penduduk), yang lain dianggap permanen.
Ketika Anda menyimpan halaman atau hubungan apa pun, model yang dihasilkan diperiksa untuk konsistensi. Misalnya,
tahun-tahun kehidupan pasangan harus tumpang tindih , seseorang tidak dapat memiliki lebih dari satu orang tua biologis dari setiap jenis kelamin, dan Anda juga tidak bisa
menjadi ayah Anda sendiri . Namun, pernikahan sesama jenis diperbolehkan.
Mengedit halaman, file media atau hubungan menyimpan
perubahan ke database. Ini memungkinkan Anda untuk menyimpan riwayat pengeditan dan mengembalikannya jika perlu.
Hubungan
Kekerabatan adalah salah satu konsep tertua di masyarakat. Sudah dalam bahasa
pra-Indo-Eropa, ada banyak nama untuk mereka, yang, dalam bentuk yang sedikit dimodifikasi, bermigrasi ke bahasa modern dari berbagai kelompok: kata "ibu" akan dipahami oleh Rusia, Inggris, dan Cina.
Ada banyak pilihan untuk hubungan kekerabatan, tetapi yang dasar ada tiga:
orang tua ,
anak dan
pasangan . Mereka memungkinkan Anda untuk membuat grafik yang diarahkan dari keluarga di mana hubungan ini adalah ujung dan orang-orang adalah simpul. Pada kolom ini, Anda dapat mengekspresikan hubungan lain, mengetahui jalur antara peserta dan jenis kelamin mereka: misalnya, untuk mengidentifikasi kakek seseorang, Anda harus terlebih dahulu menemukan orang tuanya (jenis kelamin apa pun), dan kemudian orang tua dari orang tua ini (laki-laki), dan seterusnya.
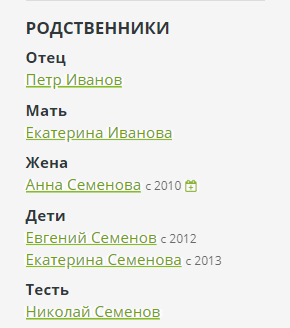
Di panel admin Bonsai, Anda dapat memasukkan relasi ketiga tipe dasar ini. Yang sebaliknya akan dibuat secara otomatis untuk setiap hubungan - orang tua untuk anak, pasangan untuk pasangan, pemilik untuk hewan peliharaan. Semua hubungan tambahan dihitung oleh mesin dan ditampilkan di bilah sisi pada halaman:
Untuk menghitung hubungan, digunakan traversal grafik elementer, dan nama hubungan diatur dalam bentuk DSL khusus:
public static RelationDefinition[] ParentRelations = { new RelationDefinition("Parent:m", ""), new RelationDefinition("Parent:f", ""), new RelationDefinition("Parent Child:m", "", ""), new RelationDefinition("Parent Child:f", "", ""), new RelationDefinition("Parent Parent:m", "", ""), new RelationDefinition("Parent Parent:f", "", "") };
Bahkan seseorang dapat memiliki
banyak saudara langsung. Bonsai membagi tautan menjadi beberapa kelompok berikut:
- Hubungan darah terdekat adalah keluarga tempat orang tersebut tumbuh: ibu dan ayah, kakek nenek, saudara lelaki dan perempuan. Jika Anda melihat grafik, maka ini adalah jalan 1-2 langkah ke atas dan 1 ke samping.
- Keluarga sendiri : satu kelompok untuk setiap pasangan dan anak-anak darinya. Ini juga termasuk kerabat pasangannya - ibu mertua, saudara ipar dan sejenisnya.
- Lainnya : kerabat yang lebih jauh (cucu, paman, bibi) dan ikatan non-kekerabatan (teman, kolega).
Terkadang satu cara untuk menentukan keanggotaan grup tidak cukup. Data mungkin tidak lengkap, tetapi masih perlu ditampilkan secukup mungkin. Pertimbangkan grafik saudara berikut:
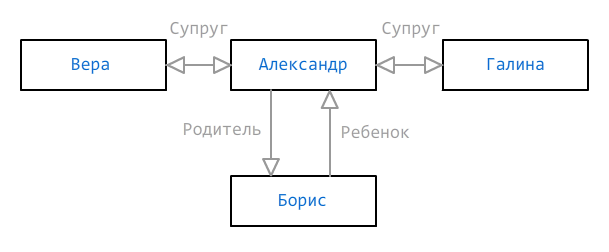
Seperti yang kita lihat, dua istri (Vera dan Galina) dan seorang putra (Boris) diindikasikan untuk Alexander, tetapi kita tidak tahu istri mana yang merupakan ibu dari anak itu - mungkin ini semacam wanita ketiga, tetapi dia belum ditambahkan. Untuk kasus seperti itu, beberapa jalur dapat diindikasikan yang seharusnya ada atau tidak ada, dan mereka ditandai dengan tanda
+ dan
- masing-masing:
new RelationDefinition("Spouse Child+Child", "||", "") new RelationDefinition("Spouse Child-Child:m", "") new RelationDefinition("Spouse Child-Child:f", "")
Pohon keluarga
Mesin silsilah yang layak harus dapat membangun silsilah keluarga. Ini adalah cara paling visual untuk menunjukkan informasi umum tentang orang dan hubungan keluarga mereka. Data disimpan dalam database dalam bentuk grafik terarah dan, secara teori, itu harus mudah divisualisasikan. Dalam praktiknya, dengan tampilan pohon itulah sebagian besar kesulitan muncul.
Berikut adalah beberapa contoh pohon keluarga yang akan terlihat:

Pohon keluarga Targaryenov. Sangat kompak, karena dibuat dengan tangan. Menghasilkan pohon seperti itu dari data acak akan sangat sulit secara otomatis.
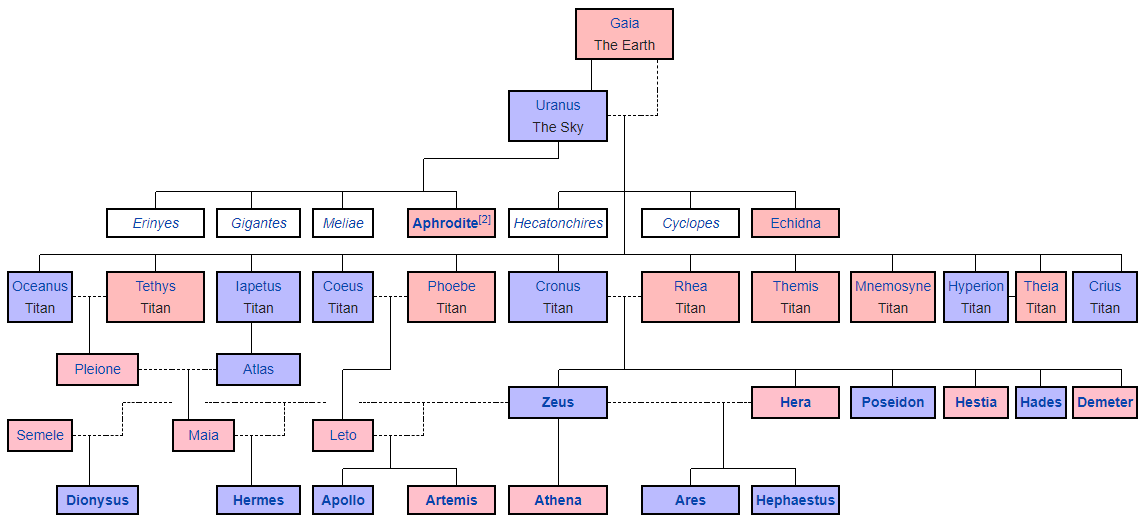
Dewa-dewa Yunani. Representasi grafis dihasilkan dari
sintaks penurunan harga khusus , di mana Anda masih perlu mengatur semua blok secara manual dan menggambar tautan di antara mereka. Agak seperti ASCII-art.

Penyajian pohon dalam bentuk diagram setengah lingkaran. Mudah dihasilkan secara otomatis, tetapi hanya memperhitungkan leluhur langsung.
Saya melihat melalui banyak opsi. Yang paling menyenangkan adalah di situs web MyHeritage:
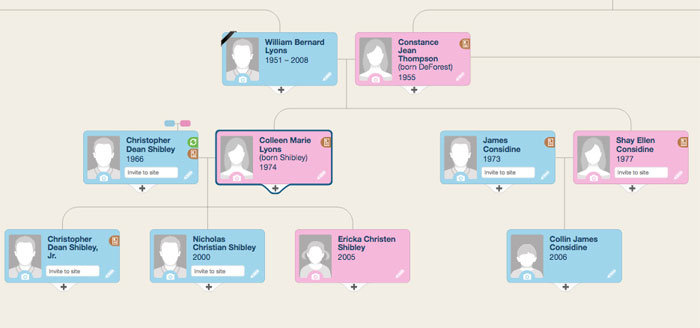
Render pohon seperti itu dapat dibagi menjadi tiga langkah bersyarat: memperoleh data dari database, mengatur blok / jalur penghubung, dan langsung menampilkannya di halaman. Jika semuanya sepele dengan langkah pertama dan ketiga, maka di langkah kedua aku tersandung.
Upaya untuk melempar solusi buatan sendiri dengan tergesa-gesa berakhir dengan kegagalan total. Susunan elemen grafik yang kompeten adalah area yang sedemikian kompleks sehingga
disertasi ditulis di atasnya, dan
komponen yang sudah selesai seperti apartemen di Moskow. Oke, Anda tidak akan bisa menulis sendiri, tetapi pasti ada solusi gratis yang layak?
Sebagian besar harapan saya ada di
perpustakaan D3.js. Mungkin ini adalah hal pertama yang terlintas dalam pikiran jika Anda perlu menggambar grafik atau bagan di halaman web. Sayangnya, di antara lebih dari tiga ratus (!) Contoh di wiki, tidak ada satu lebih atau kurang mirip dengan pohon dengan MyHeritage.
Langkah selanjutnya adalah menyelami perpustakaan yang tidak terlibat dalam rendering, tetapi dalam menghitung pengaturan optimal elemen dalam grafik. Sebagian besar dari mereka menawarkan apa yang disebut
tata letak Angkatan . Ini adalah pendekatan yang sangat sederhana, yang didasarkan pada rumus fisik: simpul grafik diwakili oleh benda-benda elastis, dan garis penghubung diwakili oleh pegas. Ia dapat dengan mudah dikenali oleh animasinya yang khas - grafiknya tampaknya “meluruskan” saat dalam perjalanan, dan ini bukan fitur tambahan, tetapi konsekuensi yang tak terhindarkan dari sifat simulasi dari algoritma. Pendekatan force-layout bagus untuk memvisualisasikan data tanpa hierarki yang jelas (misalnya, koneksi di jejaring sosial), tetapi silsilah keluarga dalam formulir ini terlihat cacat.
Pilihan lain yang dipertimbangkan adalah perpustakaan
Graphviz . Hasil karyanya dapat dengan mudah dikenali oleh karakteristik panah. Bahasa
DOT khusus digunakan untuk menggambarkan grafik. Test case terlihat lebih atau kurang, tetapi masalah muncul dengan data nyata: panah "pecah" dan terhubung pada sudut yang aneh, grafik merayap naik, dan Anda tidak dapat menyesuaikannya dan Anda tidak akan bisa mengelilinginya.
Setelah tidak menemukan solusi yang cocok pada saya sendiri, saya memutuskan untuk memesannya secara freelance, dan kemudian
DRAMA dimulai.
Perintah itu ditempatkan pada pagi hari 22 Oktober, dan dalam satu jam ia menerima beberapa tanggapan. Salah satu responden bernama Vladislav; dia mengirim contoh solusi serupa dan berjanji untuk menyelesaikan tugas dalam
satu hari . Kecepatan ini tampak mencurigakan bagi saya, tetapi saya berharap untuk pengalamannya dan pada diri saya sendiri memberikan kesalahan kepada orang itu seminggu. Beberapa hari pertama, Vladislav mengajukan pertanyaan tambahan, tidak pernah berhenti mengejutkan saya dengan pencelupan yang mendalam dalam proyek dan sikap penuh perhatian terhadap detail, dan kemudian dia menghilang. Dia bangun pada tanggal 1 November, meminta maaf atas penghilangan paksa karena alasan keluarga dan mengirim tautan dengan versi beta yang terlihat sangat mirip dengan apa yang dia inginkan jika bukan karena simpul di jalur penghubung di tengah:
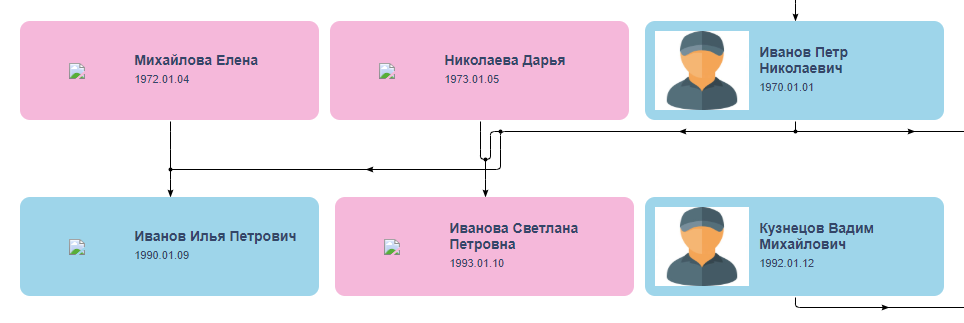
Hilangnya pemain selalu merupakan panggilan bangun, tetapi Anda tidak pernah tahu, sesuatu terjadi, karena dia melakukan sesuatu. Biarkan dia melanjutkan! Saya mengirim prabayar dan mulai menunggu perbaikan. Setelah beberapa hari, Vladislav menulis bahwa ia tidak dapat memperbaiki masalahnya, dan kemudian menghilang lagi - kali ini selama tiga minggu. Selama masa ini, ia tidak melakukan apa pun dan menolak mengembalikan uang muka, karena "tugas itu sebenarnya dilakukan oleh seorang
mantan teman bodoh yang mengecewakannya dan tidak mengembalikan uang." Setelah beberapa pertanyaan klarifikasi, delegasi yang malang itu berhenti berusaha memaafkan dirinya sendiri dan hanya diam. Jadi sekarang kita hidup - secara berkala saya mengingatkannya pada utang itu, dan sebagai tanggapan dia mengirim tangkapan layar dari aplikasi perbankan - mereka berkata, "tidak ada uang, tetapi begitu - segera saja." Saya berharap Vladislav sukses dalam bisnis dan menjadi kaya lebih cepat!
Lemparkan anak itu - minus karma terus!Kehilangan uang tidak terlalu menyebalkan, tetapi satu bulan berlalu, dan tugas itu tidak bergerak, dan sekarang tidak ada tempat untuk menunggu bantuan. Pertama-tama, saya marah pada diri sendiri: Saya mengambil jalan yang paling sedikit perlawanan, melanggar
aturan emas - dan inilah hasilnya. Dipenuhi dengan kemarahan yang saleh, saya kembali duduk untuk mempelajari perpustakaan untuk menggambar grafik dan - lihatlah! - Tiba-tiba menemukan apa yang Anda butuhkan.
Perpustakaan itu disebut
Eclipse Layout Kernel , disingkat ELK. Seperti yang Anda duga, ini digunakan untuk menampilkan diagram dalam Eclipse IDE, tetapi juga dapat digunakan secara mandiri. Secara umum, ini ditulis dalam Java, tetapi ada versi yang disiarkan di JS. Ya, kodenya adalah
mimpi buruk dan beratnya satu setengah megabyte, tetapi kekurangan ini dapat dimaafkan karena fakta bahwa itu
hanya berfungsi dan melakukan hal yang tepat. Antarmuka adalah dasar: node, tepi dan pengaturan dikirimkan ke input, dan pada output kita mendapatkan koordinat. Anda dapat menggambar pohon menggunakan mereka dengan cara yang mudah: Saya memilih SVG untuk menghubungkan garis dan div dengan posisi absolut untuk blok.
Integrasi perpustakaan dan pemilihan pengaturan optimal membutuhkan waktu dua malam. Ini, tentu saja, bukan "satu hari", seperti yang dijanjikan freelancer sial dan arogan saya, tetapi cukup dekat. Akibatnya, Bonsai dapat menampilkan pohon dalam kira-kira bentuk ini:
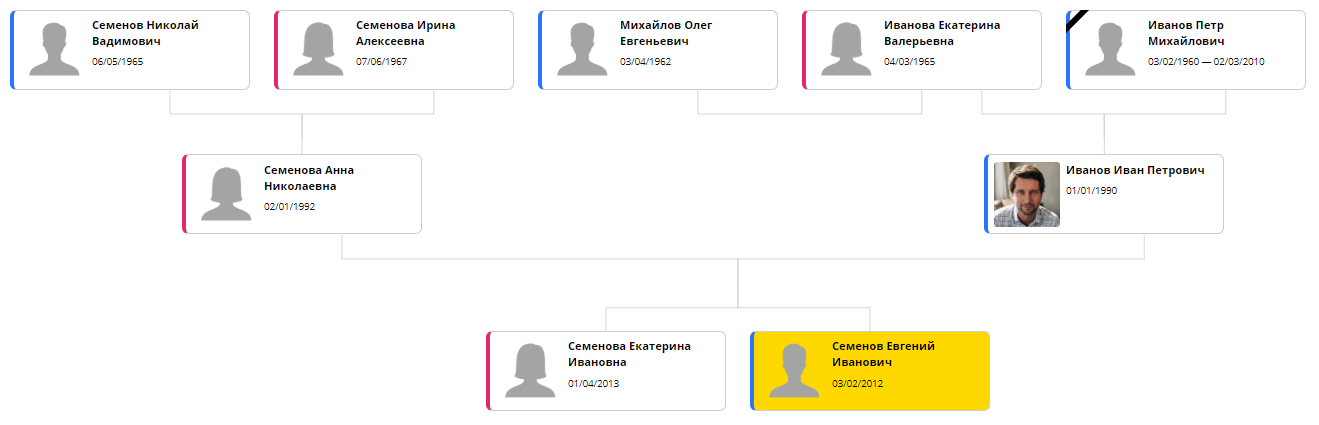
Sekarang satu-satunya masalah yang tersisa adalah waktu pemrosesan. ELK menggunakan algoritme berulang: Anda bisa lebih dekat ke penempatan optimal dengan menghabiskan waktu ekstra. Pada pohon berisi 20-30 elemen, hasil yang baik membutuhkan sekitar 5 detik. Karena itu, halaman dengan pohon terbuka setiap waktu untuk waktu yang lama, dan itu dengan cepat mulai mengganggu. Oleh versi berikutnya, perhitungan akan ditransfer ke backend sehingga dapat dilakukan sekali saat mengubah halaman dan caching.
Pencarian Teks Lengkap
Sistem untuk menyimpan informasi tekstual tidak akan berguna tanpa pencarian teks lengkap yang nyaman. Bonsai menggunakan database PostgreSQL, jadi hal pertama yang saya putuskan adalah memeriksa apa yang bisa ditawarkan di luar kotak. Kekecewaan lain:
tsvector berupaya dengan kata-kata biasa, tetapi menolak untuk mencari hal yang paling penting - nama dan nama keluarga:
SELECT to_tsvector('') @@ to_tsquery(''),
Trigram juga tidak memberikan sesuatu yang baik. Pada akhirnya, saya memilih opsi yang agak diharapkan: ElasticSearch +
Russian Morphology . Ternyata sangat tidak nyaman untuk bekerja dengannya dari. NET, namun, ia berupaya mencari lima solid dengan nama lengkapnya.
Ketidaksempurnaan Sadar
Ketika mengerjakan suatu proyek, situasi secara teratur terjadi ketika seorang
perfeksionis internal sangat marah dengan solusi yang dipilih. Area subjek agak non-standar dan "perilaku baik" yang diterima secara umum tidak selalu berhasil.
Misalnya, apa yang terjadi ketika kita membuka halaman?
- Teks halaman dikompilasi dari Penurunan harga ke HTML. Jika teks berisi tautan ke halaman lain dan file media, Anda harus pergi ke database untuk informasi lebih lanjut.
- Fakta-fakta yang deserialized dari JSON di mana mereka disimpan dalam database, dalam model tampilan.
- Hubungan ditentukan. Untuk melakukan ini, dari database lama, perlu untuk mendapatkan seluruh grafik koneksi dan menemukan node di dalamnya sesuai dengan daftar jalur yang diketahui sebelumnya.
Sepintas ini tampak seperti operasi yang sangat sulit, tetapi pada kenyataannya ini bukan karena jumlah data yang relatif kecil. Berapa banyak kerabat yang dapat Anda ingat dan ingin tuliskan? Cobalah untuk menceritakannya kembali demi minat dan temukan bahwa akan sangat sulit untuk memanggil setidaknya seratus. Dan berapa banyak orang yang ingin memberikan akses? Bahkan jumlah yang sangat besar untuk sebuah keluarga adalah seribu orang! - Dengan standar database modern, itu tetap konyol.
Tentu saja, model tampilan halaman yang dikompilasi masih di-cache saat pertama kali dibuka dan digunakan kembali pada yang berikutnya, terutama karena itu sangat mudah diimplementasikan. Aturan pembatalan cache untuk perubahan di panel admin juga diambil sesederhana mungkin: jika kita hanya mengubah teks dan beberapa fakta
lokal (daftar bahasa, golongan darah, warna rambut, dll.), Maka cukup setel ulang halaman khusus ini. Dengan perubahan lainnya - nama halaman, tanggal lahir atau jenis kelamin, menambah atau mengubah koneksi apa pun - cache
sepenuhnya disetel ulang. Ya, ini bukan cara paling cerdas untuk membersihkan. Ya, pasti, Anda bisa menulis algoritma yang kompleks yang hanya akan mengatur ulang apa yang Anda butuhkan - tetapi untuk proyek ini tidak akan membenarkan biaya.
Proyek ini tidak mendukung lokalisasi dan perubahan tampilan, otorisasi berfungsi pada OAuth di Facebook \ Google, dan panel admin dibuat pada formulir yang biasa, dan bukan kerangka kerja SPA berdasarkan mode terbaru. Semua ini
dapat direalisasikan atau ditingkatkan, tetapi tidak akan menyelesaikan masalah, dan karena itu waktu akan terbuang sia-sia.
Menantikan masa depan
Alasan lain mengapa tidak masuk akal untuk berinvestasi dalam kompleksitas perangkat mesin adalah sifat implementasi yang sementara dibandingkan dengan data yang disimpannya. Pikirkan sejenak: web dalam bentuk saat ini telah ada selama hampir dua puluh tahun, dan sejarah keluarga telah ada
selama berabad-abad . Belum ada yang memecahkan masalah ini hanya karena industri teknologi informasi itu sendiri ada jauh lebih sedikit. Apa yang bisa dilakukan?
Mesin harus ditulis ulang secara teratur dari awal - seperti selama ribuan tahun, para bhikkhu sulit menyalin teks-teks dari buku-buku bobrok ke yang baru. Satu-satunya perbedaan adalah bahwa buku itu bisa berbohong seratus tahun dengan penanganan yang tepat, dan aplikasi - pada kekuatan 15-20 tahun. Saya berharap bahwa dalam dua puluh tahun saya masih bisa melakukannya sendiri, tetapi dalam dua puluh tahun lagi anak-anak atau cucu-cucu saya harus melakukannya. Saya ingin meninggalkan mereka sumber yang sederhana, dapat dimengerti dan didokumentasikan.
Pada tahap pertama desain, saya ingin menanamkan bahasa seperti SQL tertentu ke dalam mesin, dengan bantuan yang saya bisa mendapatkan jawaban untuk pertanyaan spesifik: "berapa persentase leluhur saya dengan mata biru", "ketika Ivan membeli mobil pertama" dan seterusnya. Gagasan ini harus ditinggalkan karena akan membutuhkan alih-alih teks biasa untuk memasukkan semua informasi dalam bentuk formal tertentu, dan hanya deskripsi jenis ini yang akan memakan waktu bertahun-tahun. Di sisi lain, Pemahaman Bahasa Alami memperoleh momentum. Saya tidak akan terkejut jika dalam sepuluh atau dua tahun akan mungkin untuk meminta Siri untuk membaca teks untuk Anda, ikuti tautannya dan, sebagai hasilnya, menyajikan kutipan dari fakta. Kawan, dorong!
Bagaimana cara mencoba?
Sayangnya, saya tidak dapat memberikan tautan ke demo yang sudah selesai: tidak ada server yang dapat menahan efek habra. Tetapi ada beberapa tangkapan layar visual (gambar dapat diklik).

Jika Bonsai tampak bermanfaat bagi Anda dan Anda ingin menjalankannya sendiri, kode sumbernya dapat diunduh dari Github:
https://github.com/impworks/bonsaiPetunjuk pemasangan terperinci disediakan di Readme. Anda akan membutuhkan ini:
- .NET Core 2.1+
- PostgreSQL 10+
- ElasticSearch 5.x dan plugin Morfologi Rusia
- Facebook atau aplikasi Google untuk otorisasi oAuth
Setelah peluncuran pertama, beberapa halaman pengujian dan foto dibuat dalam database. Untuk produksi, perilaku ini tidak diperlukan dan dinonaktifkan oleh bendera di pengaturan.
Hanya sebulan yang lalu, saya meluncurkan contoh saya sendiri dan mulai menjalankannya, mendapatkan data nyata. Beberapa kekasaran ditemui, tetapi sebaliknya saya benar-benar puas dengan hasilnya. Sekarang proyek akan secara bertahap dikembangkan dan diselesaikan. Tugas utama adalah untuk mempercepat tampilan pohon, memungkinkan mengunduh dokumen dalam bentuk PDF dan menambahkan penyesuaian hak akses. Akan lebih baik untuk meningkatkan kegunaan panel admin di beberapa tempat atau untuk secara otomatis mengenali wajah di foto -
tetapi ini tidak akurat .