
Pada artikel sebelumnya, kita berbicara tentang masalah pembelajaran mesin seperti contoh permusuhan dan beberapa jenis serangan yang memungkinkan mereka dihasilkan. Artikel ini akan fokus pada algoritma perlindungan dari efek semacam ini dan rekomendasi untuk model pengujian.
Perlindungan
Pertama-tama, mari kita jelaskan satu hal - tidak mungkin untuk sepenuhnya mempertahankan diri dari efek seperti itu, dan ini sangat wajar. Memang, jika kita menyelesaikan masalah contoh permusuhan sepenuhnya, maka kita akan secara bersamaan memecahkan masalah membangun hyperplane yang ideal, yang, tentu saja, tidak dapat dilakukan tanpa kumpulan data umum.
Ada dua tahap untuk mempertahankan model pembelajaran mesin:
Belajar - Kami mengajarkan algoritme kami untuk merespons dengan benar contoh-contoh permusuhan
Operasi - kami mencoba mendeteksi contoh permusuhan selama fase operasi model.
Layak disebutkan bahwa Anda dapat bekerja dengan metode perlindungan yang disajikan dalam artikel ini menggunakan Adversarial Robustness Toolbox dari IBM.
Pelatihan permusuhan

Jika Anda bertanya kepada seseorang yang baru saja mengenal masalah permusuhan dengan contoh-contoh, pertanyaan: "Bagaimana melindungi diri Anda dari efek ini?" Pendekatan ini segera diusulkan dalam artikel yang sifatnya menarik dari jaringan saraf kembali pada tahun 2013. Di artikel inilah masalah ini pertama kali dijelaskan dan serangan L-BFGS, yang memungkinkan menerima contoh-contoh permusuhan.
Metode ini sangat sederhana. Kami membuat contoh Adversarial menggunakan berbagai jenis serangan dan menambahkannya ke pelatihan yang ditetapkan pada setiap iterasi, sehingga meningkatkan "resistensi" model Adversarial terhadap contoh-contoh.
Kerugian dari metode ini cukup jelas: pada setiap iterasi pelatihan, untuk masing-masing contoh, kita dapat menghasilkan sejumlah besar contoh, masing-masing, dan waktu untuk memodelkan pelatihan meningkat berkali-kali.
Anda dapat menerapkan metode ini menggunakan perpustakaan ART-IBM sebagai berikut.
from art.defences.adversarial_trainer import AdversarialTrainer trainer = AdversarialTrainer(model, attacks) trainer.fit(x_train, y_train)
Augmentasi Data Gaussian
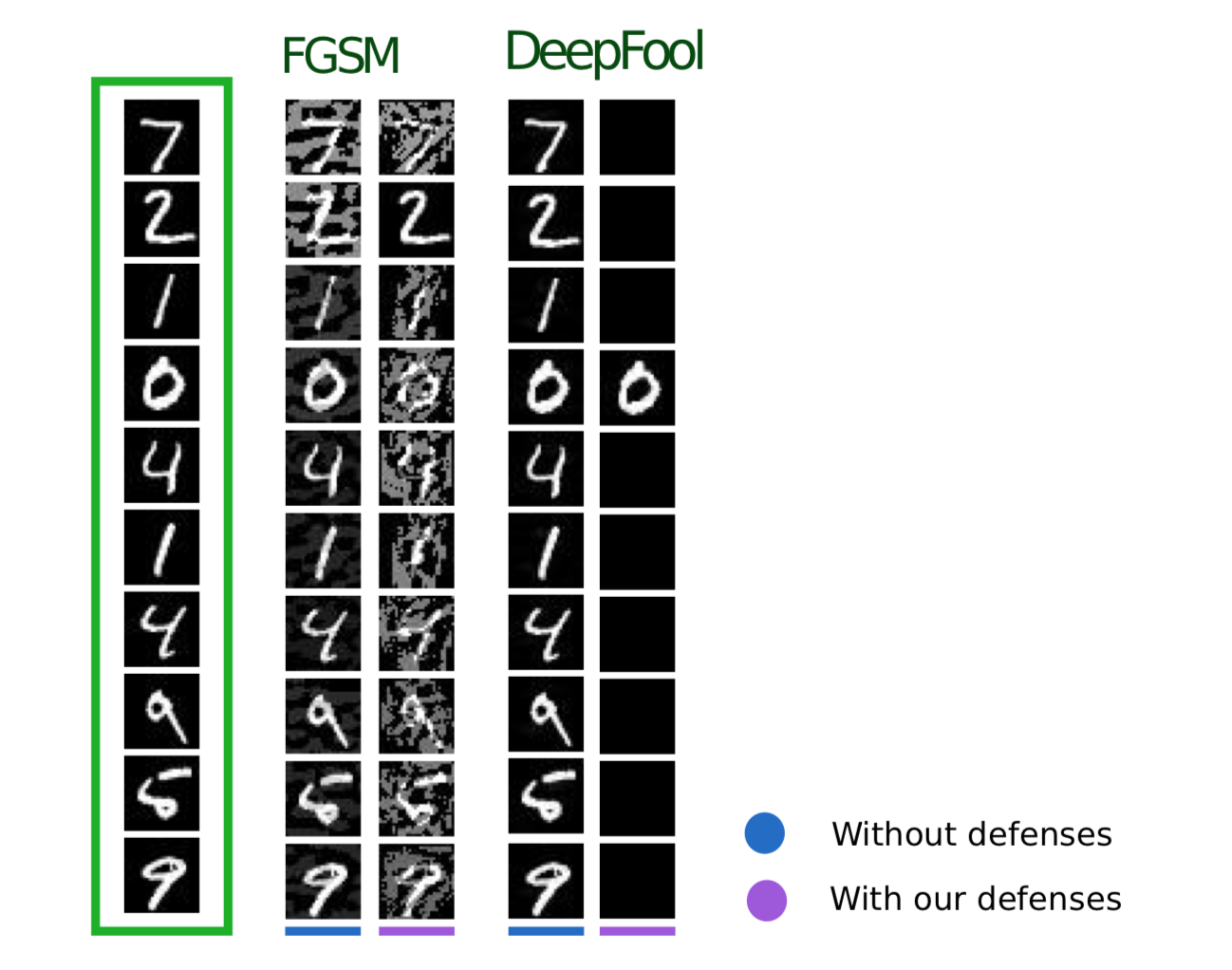
Metode berikut, yang dijelaskan dalam artikel Efisien Pertahanan Terhadap Serangan Adversarial , menggunakan logika yang serupa: ia juga menyarankan menambahkan objek tambahan ke set pelatihan, tetapi tidak seperti Pelatihan Adversarial, objek ini bukan contoh Adversarial, tetapi objek set latihan yang sedikit bising (Gaussian digunakan sebagai noise kebisingan, maka nama metode ini). Dan, memang, ini tampak sangat logis, karena masalah utama dari model justru kekebalannya yang buruk.
Metode ini menunjukkan hasil yang mirip dengan Pelatihan Adversarial, sambil menghabiskan lebih sedikit waktu untuk menghasilkan objek untuk pelatihan.
Anda dapat menerapkan metode ini menggunakan kelas GaussianAugmentation di ART-IBM
from art.defences.gaussian_augmentation import GaussianAugmentation GDA = GaussianAugmentation() new_x = GDA(x_train)
Label smoothing
Metode Label Smoothing sangat sederhana untuk diimplementasikan, namun demikian membawa banyak arti probabilistik. Kami tidak akan membahas perincian interpretasi probabilistik dari metode ini, Anda dapat menemukannya di artikel asli Memikirkan Kembali Arsitektur Inception for Computer Vision . Namun, untuk membuatnya lebih singkat, Label Smoothing adalah jenis tambahan regularisasi model dalam masalah klasifikasi, yang membuatnya lebih tahan terhadap kebisingan.
Bahkan, metode ini menghaluskan label kelas. Membuatnya, katakanlah, bukan 1, tetapi 0,9. Dengan demikian, model pelatihan didenda karena "kepercayaan" yang jauh lebih besar pada label untuk objek tertentu.
Aplikasi metode ini dalam Python dapat dilihat di bawah ini.
from art.defences.label_smoothing import LabelSmoothing LS = LabelSmoothing() new_x, new_y = LS(train_x, train_y)
Relu terikat
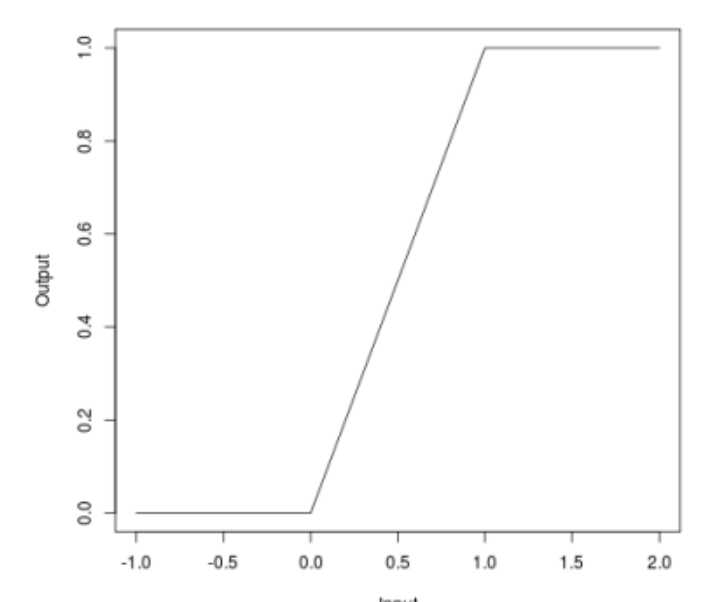
Ketika kita berbicara tentang serangan, banyak yang dapat memperhatikan bahwa beberapa serangan (JSMA, OnePixel) bergantung pada seberapa kuat gradien pada satu titik atau lainnya pada gambar input. Metode sederhana dan "murah" (dalam hal biaya komputasi dan waktu) dari Bounded ReLU sedang mencoba untuk mengatasi masalah ini.
Inti dari metode ini adalah sebagai berikut. Mari kita ganti fungsi aktivasi ReLU di jaringan saraf dengan yang sama, yang dibatasi tidak hanya dari bawah, tetapi juga dari atas, sehingga memuluskan peta gradien, dan pada titik-titik tertentu tidak akan mungkin untuk mendapatkan percikan, yang tidak akan memungkinkan Anda membodohi algoritma dengan mengubah satu piksel gambar.
\ begin {persamaan *} f (x) =
\ begin {cases}
0, x <0
\\
x, 0 \ leq x \ leq t
\\
t, x> t
\ end {cases}
\ end {persamaan *}
Metode ini juga telah dijelaskan dalam artikel Pertahanan Efisien Terhadap Serangan Musuh
Ensembles Model Bangunan
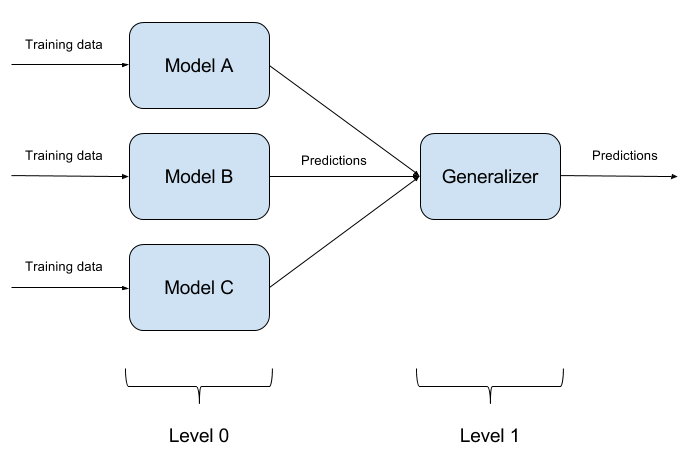
Tidak sulit untuk menipu satu model yang terlatih. Untuk menipu dua model sekaligus dengan satu objek bahkan lebih sulit. Dan jika ada N model seperti itu? Di sinilah metode ensemble model didasarkan. Kami hanya membangun N model yang berbeda dan menggabungkan hasilnya menjadi satu jawaban. Jika model juga diwakili oleh algoritma yang berbeda, maka sangat sulit untuk menipu sistem seperti itu, tetapi sangat sulit!
Sangat wajar bahwa implementasi ansambel model adalah pendekatan arsitektur murni, mengajukan banyak pertanyaan (Model dasar apa yang harus diambil? Bagaimana cara mengagregasi output model dasar? Apakah ada hubungan antara model? Dan seterusnya). Karena alasan ini, pendekatan ini tidak diterapkan dalam ART-IBM
Meremas fitur
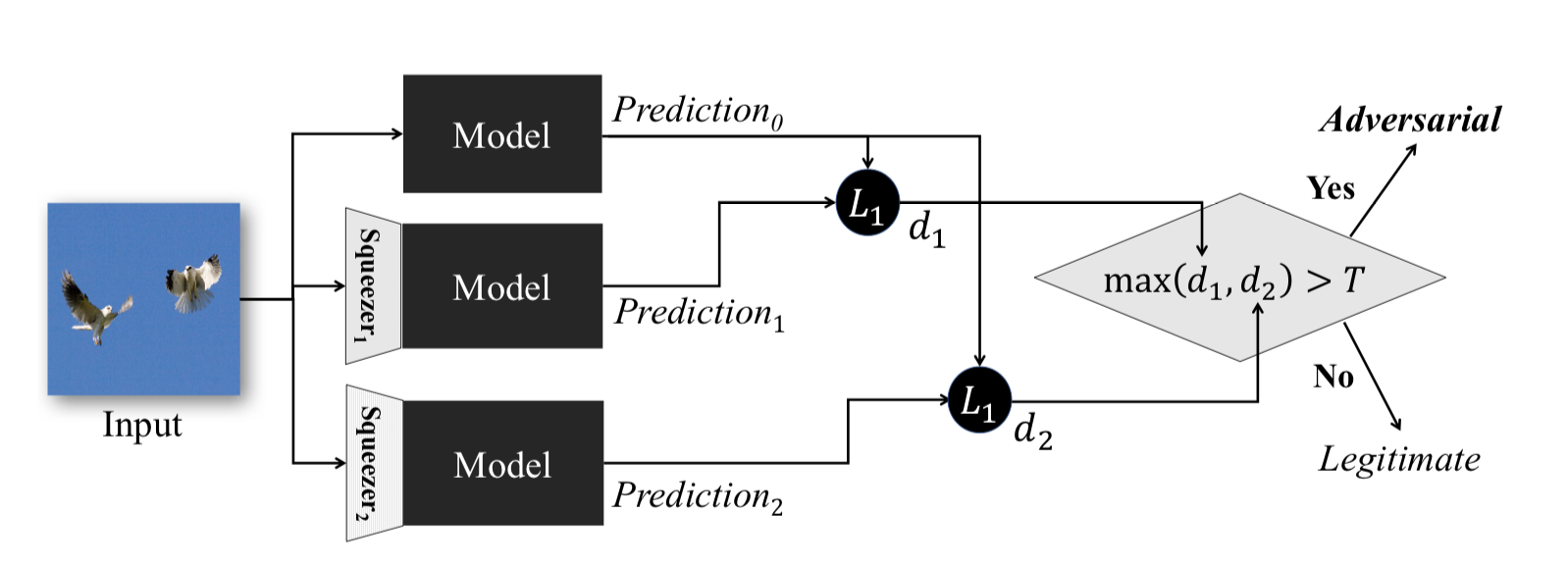
Metode ini, dijelaskan dalam Pemerasan Fitur: Mendeteksi Contoh Adversarial di Deep Neural Networks , bekerja selama fase operasional model. Ini memungkinkan Anda untuk mendeteksi contoh permusuhan.
Gagasan di balik metode ini adalah sebagai berikut: jika Anda melatih model pada data yang sama, tetapi dengan rasio kompresi yang berbeda, hasil pekerjaan mereka akan tetap serupa. Pada saat yang sama, contoh Adversarial, yang berfungsi pada jaringan sumber, kemungkinan besar akan gagal pada jaringan tambahan. Dengan demikian, setelah mempertimbangkan perbedaan berpasangan antara output dari jaringan saraf awal dan yang tambahan, memilih maksimum dari mereka dan membandingkannya dengan ambang yang dipilih sebelumnya, kita dapat menyatakan bahwa objek input adalah Adversarial atau benar-benar valid.
Berikut ini adalah metode untuk mendapatkan objek yang dikompresi menggunakan ART-IBM
from art.defences.feature_squeezing import FeatureSqueezing FS = FeatureSqueezing() new_x = FS(train_x)
Kami akan mengakhiri dengan metode perlindungan. Tetapi akan salah untuk tidak memahami satu poin penting. Jika penyerang tidak memiliki akses ke input dan output model, ia tidak akan mengerti bagaimana data mentah diproses di dalam sistem Anda sebelum memasukkan model. Kemudian dan hanya kemudian semua serangannya akan dikurangi menjadi secara acak menyortir nilai input, yang secara alami tidak mungkin mengarah pada hasil yang diinginkan.
Pengujian
Sekarang mari kita bicara tentang algoritma pengujian untuk melawan contoh permusuhan. Di sini, pertama-tama, perlu dipahami bagaimana kita akan menguji model kita. Jika kami berasumsi bahwa penyerang dapat memperoleh akses penuh ke seluruh model, maka perlu untuk menguji model kami menggunakan metode serangan WhiteBox.
Dalam kasus lain, kami berasumsi bahwa penyerang tidak akan pernah mendapatkan akses ke "bagian dalam" model kami, namun, ia akan dapat, meskipun secara tidak langsung, untuk mempengaruhi data input dan melihat hasil dari model. Maka Anda harus menerapkan metode serangan BlackBox.
Algoritma pengujian umum dapat dijelaskan dengan contoh berikut:
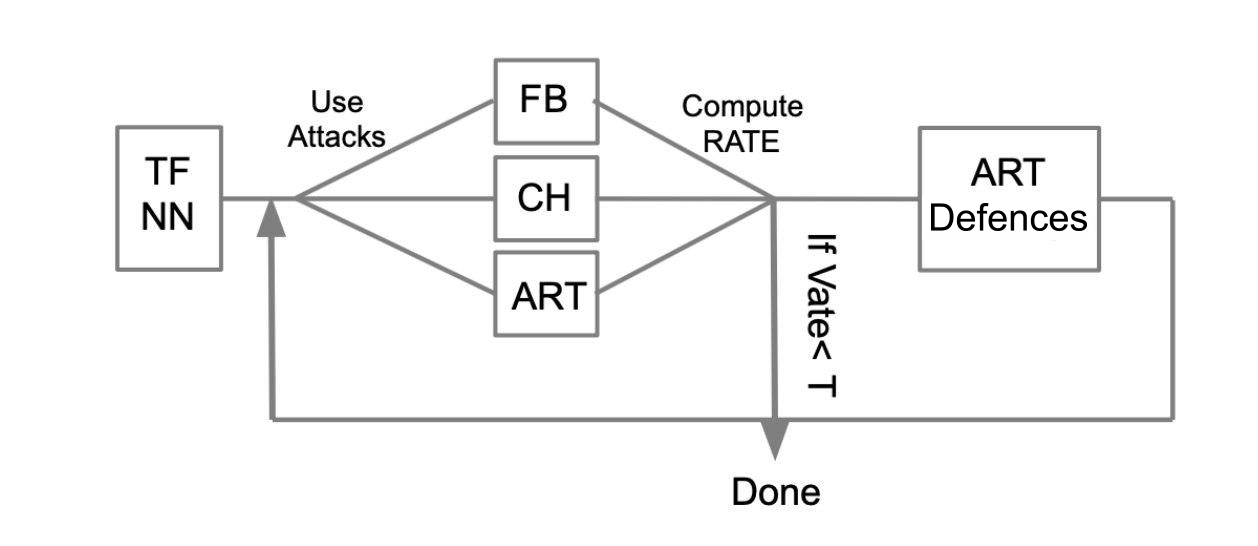
Biarkan ada jaringan saraf terlatih yang ditulis dalam TensorFlow (TF NN). Kami dengan ahli mengklaim bahwa jaringan kami dapat jatuh ke tangan penyerang dengan menembus sistem di mana model berada. Dalam hal ini, kita perlu melakukan serangan WhiteBox. Untuk melakukan ini, kami mendefinisikan kumpulan serangan dan kerangka kerja (FoolBox - FB, CleverHans - CH, Adboxer robustness toolbox - ART) yang memungkinkan serangan ini diimplementasikan. Kemudian, dengan menghitung berapa banyak serangan yang berhasil, kami menghitung Tingkat Succes (SR). Jika SR cocok untuk kita, kita menyelesaikan pengujian, jika tidak kita menggunakan salah satu metode perlindungan, misalnya, diterapkan dalam ART-IBM. Kemudian kami melakukan serangan dan mempertimbangkan SR. Kami melakukan operasi ini secara siklis, sampai SR cocok untuk kami.
Kesimpulan
Saya ingin mengakhiri di sini dengan informasi umum tentang serangan, pertahanan, dan model pembelajaran mesin pengujian. Merangkum dua artikel, kita dapat menyimpulkan yang berikut:
- Jangan percaya pembelajaran mesin sebagai semacam keajaiban yang bisa menyelesaikan semua masalah Anda.
- Saat menerapkan algoritme pembelajaran mesin dalam tugas Anda, pikirkan tentang seberapa tahan algoritma ini terhadap ancaman seperti contoh Adversarial.
- Anda dapat melindungi algoritma baik dari sisi pembelajaran mesin, dan dari sisi sistem di mana model ini dioperasikan.
- Uji model Anda, terutama dalam kasus di mana hasil model secara langsung mempengaruhi keputusan
- Perpustakaan seperti FoolBox, CleverHans, ART-IBM menyediakan antarmuka yang nyaman untuk menyerang dan mempertahankan model pembelajaran mesin.
Juga dalam artikel ini saya ingin merangkum karya dengan perpustakaan FoolBox, CleverHans dan ART-IBM:
FoolBox adalah perpustakaan sederhana dan dapat dipahami untuk menyerang jaringan saraf, mendukung banyak kerangka kerja yang berbeda.
CleverHans adalah pustaka yang memungkinkan Anda untuk melakukan serangan dengan mengubah banyak parameter serangan, sedikit lebih rumit dari FoolBox, mendukung lebih sedikit kerangka kerja.
ART-IBM adalah satu-satunya perpustakaan di atas yang memungkinkan Anda untuk bekerja dengan metode keamanan, sejauh ini hanya mendukung TensorFlow dan Keras, tetapi sedang berkembang lebih cepat daripada yang lain.
Di sini patut dikatakan bahwa ada perpustakaan lain untuk bekerja dengan contoh-contoh permusuhan dari Baidu, tetapi, sayangnya, hanya cocok untuk orang-orang yang berbicara bahasa Cina.
Pada artikel selanjutnya tentang topik ini, kami akan menganalisis bagian dari tugas yang diusulkan untuk diselesaikan selama ZeroNights HackQuest 2018 dengan menipu jaringan saraf tipikal menggunakan perpustakaan FoolBox.