
Pengembangan perangkat lunak yang cepat dan efisien saat ini tidak terpikirkan tanpa alur kerja yang terasah dengan baik: setiap komponen ditransfer ke perakitan pada saat pemasangan, produk tidak akan diam. Dua tahun lalu, bersama-sama dengan M.Video, kami mulai memperkenalkan pendekatan semacam itu ke dalam proses pengembangan di pengecer dan hari ini kami terus mengembangkannya. Apa subtotalnya? Hasilnya sepenuhnya terbayar: berkat perubahan yang diterapkan, dimungkinkan untuk mempercepat rilis rilis sebesar 20-30%. Mau beberapa detail? Welcom di belakang panggung kami.
Dari Scrum ke Kanban
Pertama-tama, perubahan dalam metodologi dilaksanakan - transisi dari Scrum, yaitu, model sprint, ke Kanban. Sebelumnya, proses pengembangan terlihat seperti ini:

Ada cabang pengembangan, ada sprint untuk lima tim. Mereka membuat kode di cabang pengembangan mereka sendiri, sprint berakhir pada hari yang sama, dan semua tim menggabungkan hasil pekerjaan mereka dengan cabang utama pada hari yang sama. Setelah itu, uji regresi dijalankan selama lima hari, kemudian cabang diberikan ke lingkungan pilot dan setelah itu ke yang produktif. Tetapi, sebelum memulai tes regresi, butuh 2-3 hari untuk menstabilkan cabang master, menghilangkan konflik setelah bergabung dengan cabang perintah.
Apa keuntungan Kanban? Tim tidak menunggu akhir sprint, tetapi menggabungkan perubahan lokal mereka dengan cabang utama setelah menyelesaikan tugas, setiap kali memeriksa konflik tabrakan. Pada hari yang ditentukan, semua asosiasi dengan master diblokir dan tes regresi dimulai.
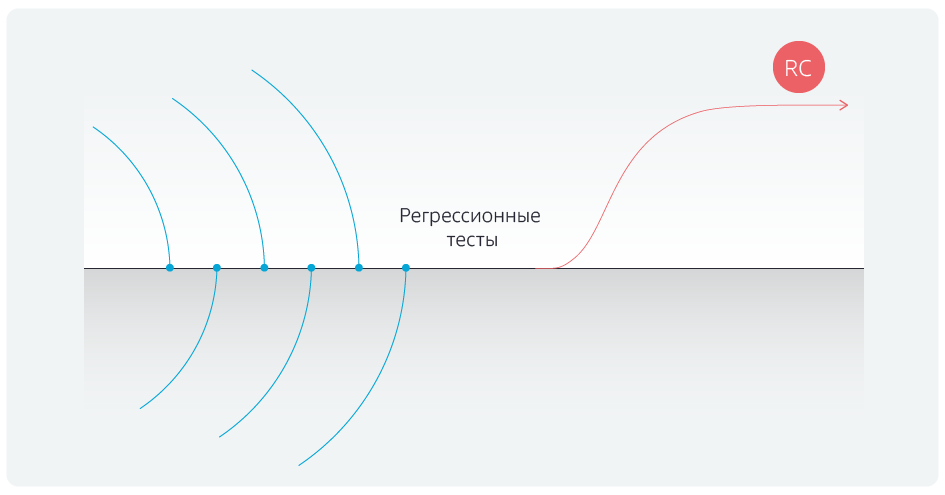
Sebagai hasilnya, kami berhasil menyingkirkan pergeseran istilah yang konstan ke kanan, regresi
tidak tertunda, kandidat rilis dikirimkan tepat waktu.
Otomasi di mana-mana
Tentu saja, mengubah metodologi saja tidak cukup. Langkah kedua, kami, bersama dengan pengecer, melakukan pengujian otomatis. Secara total, sekitar 900 skenario diuji, dibagi ke dalam kelompok berdasarkan prioritas.
Sekitar 100 skenario adalah yang disebut pemblokir. Mereka harus bekerja di situs - toko online M.Video - bahkan selama perang atom. Jika salah satu pemblokir tidak berfungsi, maka ada masalah besar di situs. Misalnya, pemblokir termasuk mekanisme untuk membeli barang, menerapkan diskon, otorisasi, mendaftarkan pengguna, menempatkan pesanan kredit, dll.
Sekitar 300 skenario lebih penting. Ini termasuk, misalnya, kemampuan untuk memilih produk menggunakan filter. Jika fitur ini rusak, maka tidak mungkin pengguna akan membeli barang, bahkan jika mekanisme pembelian dan pencarian langsung di katalog berfungsi.
Skenario lain besar dan kecil. Jika tidak berfungsi, orang akan mendapatkan pengalaman negatif menggunakan situs ini. Ini mencakup banyak masalah dengan kepentingan dan visibilitas yang beragam bagi pengguna. Misalnya, tata letak (utama) berjalan, deskripsi stok (minor) tidak ditampilkan, saran otomatis untuk kata sandi di akun pribadi (minor) tidak berfungsi, pemulihan (utama) tidak berfungsi.
Bersama dengan M.Video, kami mengotomatiskan pengujian blocker sebesar 95%, dari skenario yang tersisa - sekitar 50%. Mengapa sekitar setengahnya tidak otomatis? Ada banyak alasan, dan berbeda. Ada skenario yang apriori tidak setuju untuk otomatisasi. Ada kasus integrasi yang kompleks, persiapan yang membutuhkan pekerjaan manual, misalnya, menelepon bank dan membatalkan aplikasi pinjaman, menghubungi departemen penjualan dan membatalkan pesanan di lingkungan yang produktif.
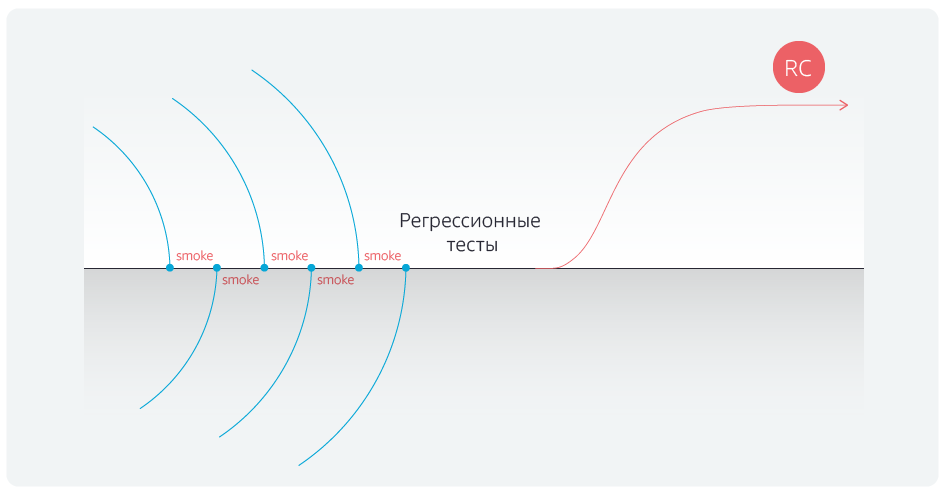
Otomatisasi tes regresi mengurangi durasinya. Tapi kami melangkah lebih jauh dan mengotomatiskan tes asap untuk blocker setelah masing-masing menggabungkan cabang perintah dengan cabang master.
Setelah mengotomatisasi tes, kami akhirnya menyingkirkan penundaan setelah menyelesaikan asosiasi dengan cabang utama.
Gherkin untuk menyelamatkan
Untuk mengkonsolidasikan kesuksesan, tim kami mengerjakan ulang tes itu sendiri. Sebelumnya, ini adalah tabel: action → hasil yang diharapkan → hasil aktual. Misalnya, saya masuk ke situs dengan nama pengguna dan kata sandi; hasil yang diharapkan: semuanya dalam urutan; hasil sebenarnya juga oke, saya akan ke halaman lain. Ini adalah skenario yang tidak praktis.
Kami menerjemahkannya ke dalam notasi Gherkin dan mengotomatiskan beberapa langkah. Mari kita ambil otorisasi yang sama di situs, skrip sekarang dirumuskan sebagai berikut: "
sebagai pengguna situs, saya login dengan data otorisasi, dan prosedurnya berhasil ." Selain itu, "
pengguna situs " dan "
masuk dengan data otorisasi " tercantum dalam tabel terpisah. Sekarang kita dapat dengan cepat menjalankan kasus uji terlepas dari data.
Apa nilai dari langkah ini? Katakanlah satu tester terlibat dalam pengujian suatu proyek. Dia tidak peduli bagaimana dia menulis tes, dia dapat melakukan pemeriksaan bahkan dalam bentuk daftar periksa: "otorisasi diperiksa, pendaftaran diverifikasi, pembelian diverifikasi dengan kartu, pembelian oleh Yandex.Money diverifikasi - saya tampan". Seseorang baru datang dan bertanya: apakah Anda masuk melalui email atau melalui Facebook? Akibatnya, daftar periksa berubah menjadi skrip.
Lima tim bekerja di proyek, dan masing-masing tim memiliki setidaknya dua penguji. Sebelumnya, masing-masing dari mereka menulis tes sesuka hatinya, dan sebagai hasilnya, tes hanya dapat didukung oleh penulis mereka. Dengan otomatisasi, semuanya membosankan: Anda harus merekrut insinyur otomatisasi terpisah yang menerjemahkan seluruh kebun binatang tes ke dalam bahasa scripting, atau melupakan otomatisasi sebagai sebuah fenomena. Gherkin membantu mengubah segalanya: dengan bantuan bahasa scripting ini kami menciptakan "kubus" - otorisasi, keranjang, pembayaran, dll. - yang darinya penguji sekarang mengumpulkan berbagai skrip. Ketika Anda perlu membuat skrip baru, seseorang tidak menulisnya dari awal, tetapi hanya menarik blok yang diperlukan dalam bentuk autotests. Notasi Gherkin telah melatih semua penguji fungsional, dan sekarang mereka dapat berinteraksi secara independen dengan otomatisasi, skrip dukungan, dan hasil parse.
Kami tidak berhenti di situ.
Blok fungsi
Katakanlah rilis 1 adalah fungsi yang sudah ada di situs. Dalam rilis 2, kami ingin membuat beberapa perubahan pada skenario pengguna dan bisnis, dan sebagai hasilnya, bagian dari tes berhenti bekerja karena fungsinya berubah.
Kami menyusun sistem penyimpanan pengujian: kami membaginya menjadi blok fungsional, misalnya, "akun pribadi", "pembelian", dll. Sekarang, ketika skrip pengguna baru diperkenalkan, blok fungsional yang diperlukan ditandai dengan tanda centang di dalamnya.
Berkat ini, setelah bergabung dengan cabang utama, pengembang dapat memeriksa pekerjaan tidak hanya pemblokir, tetapi juga skrip yang terkait dengan area subjek yang membuat perubahan tersebut mempengaruhi.
Konsekuensi kedua adalah menjadi lebih mudah untuk mempertahankan tes itu sendiri. Misalnya, jika ada sesuatu yang berubah di akun pribadi Anda, melakukan pemesanan dan pengiriman, kami tidak perlu mengguncang seluruh model regresi, karena blok fungsional yang diubah segera terlihat. Artinya, menjaga suite tes tetap terbaru menjadi lebih cepat, dan karenanya lebih murah.
Masalah dengan tribun
Tidak ada yang terbiasa menguji kinerja tribun sebelum pengujian penerimaan. Misalnya, mereka memberi kami beberapa bangku tes, kami menjalankan tes regresi selama beberapa jam. Mereka jatuh, mengerti, memperbaiki, menjalankan tes lagi. Artinya, kami kehilangan waktu untuk debugging dan menjalankan berulang.
Masalahnya diselesaikan dengan sederhana: mereka menulis total 15 tes API yang memeriksa konfigurasi tribun, yang sama sekali tidak terkait dengan fungsionalitas. Tes tidak tergantung pada versi build, mereka hanya memeriksa semua titik integrasi penting untuk melewati skrip.
Ini telah membantu menghemat banyak waktu. Memang, sebelum otomatisasi, kami memiliki 14 penguji, ceknya rumit dan panjang, ada skrip untuk hampir sepanjang hari kerja, yang terdiri dari 150 langkah. Dan di sini Anda menguji, dan di suatu tempat pada langkah 30-40-110 Anda menyadari bahwa dudukan tidak berfungsi. Kami melipatgandakan waktu kerja yang hilang dengan 14 orang dan merasa ngeri. Dan setelah pengenalan otomatisasi dan pengujian tribun, kami berhasil membagi dua jumlah penguji dan menyingkirkan waktu henti, yang membawa banyak kegembiraan kepada kepala akuntan.
Ceri pada kue
Ceri pertama adalah bugflow. Secara formal, ini adalah siklus hidup bug apa pun, tetapi sebenarnya entitas apa pun. Sebagai contoh, kami mengoperasikan konsep ini di Jira. Satu status tambahan memungkinkan kami untuk mempercepat rilis.
Secara umum, prosesnya terlihat seperti ini: mereka menemukan insiden, membawanya bekerja, menyelesaikannya, menyerahkannya untuk pengujian, mengujinya, dan menutupnya.

Kami memahami bahwa cacat telah ditutup, masalahnya telah diselesaikan. Dan mereka menambahkan status lain: "untuk pengujian regresi." Ini berarti bahwa setelah analisis, skenario yang mendeteksi bug kritis ditambahkan ke set regresi 900 skenario. Jika mereka tidak ada di sana, atau jika mereka memiliki detail yang tidak mencukupi, maka kami memiliki umpan balik instan tentang keadaan produktif atau pilot.

Artinya, kami memahami bahwa ada masalah, dan untuk beberapa alasan kami tidak memperhitungkannya. Dan sekarang menambahkan skrip pemeriksaan bug menghemat banyak waktu.
Kami juga memperkenalkan retrospektif di tingkat pengujian. Kelihatannya seperti ini: mereka menyusun tablet "nomor rilis, jumlah bug di dalamnya, jumlah blocker dan skrip lainnya, dan jumlah resolusi". Pada saat yang sama, kami memperkirakan jumlah resolusi yang tidak valid. Misalnya, jika Anda mendapatkan 15 bug tidak valid dari 40 bug, maka ini adalah indikator yang sangat buruk, penguji tidak hanya menghabiskan waktu mereka, tetapi juga waktu pengembang yang mengerjakan bug ini. Orang-orang mulai merefleksikan, menangani hal ini, memperkenalkan prosedur untuk merevisi bug oleh penguji yang lebih berpengalaman sebelum mengirim mereka ke pengembangan. Dan mereka melakukannya dengan sangat baik.
Dengan demikian, selalu ada refleksi dan upaya untuk meningkatkan kualitas. Semua bug dari produk dianalisis: tes dibuat untuk setiap bug, yang segera dimasukkan dalam set regresi. Jika memungkinkan, tes ini otomatis dan berjalan secara teratur.
Hasil
Awalnya, direncanakan untuk meningkatkan frekuensi rilis dan mengurangi jumlah kesalahan, tetapi hasilnya agak melebihi harapan. Proses otomasi yang dibangun secara wajar memungkinkan untuk meningkatkan jumlah pengujian otomatis dalam waktu singkat, dan analisis bug yang terlewat memungkinkan tim pengembangan dan pengujian untuk memprioritaskan skrip secara optimal dan fokus pada yang paling penting.
Hasil Otomatisasi:
- hingga 4 hari (bukan 10 hari sebelumnya) mengurangi durasi tes regresi;
- tim pengujian manual menurun sebesar 50%;
- dari 30–35 menjadi 25 hari, waktu ke durasi pasar berkurang - dari saat fitur masuk dalam tim penumpukan hingga memasuki pilot.
Tim Otomatisasi Uji, Jet Infosystems