Tahun lalu, ada gelombang artikel tentang pesta di Lembah Silikon di pers Rusia dan Ukraina, dengan suasana Hollywood, tetapi tanpa menyebutkan nama, foto, dan tanpa menjelaskan pengembangan perangkat keras dan teknologi penulisan perangkat lunak yang terkait dengan nama-nama ini. Artikel ini berbeda! Ini juga akan memiliki miliarder, genius dan perempuan, tetapi dengan foto, slide, diagram, dan fragmen kode program. Jadi:
Suatu hari, walikota Campbell, dengan nama Rusia Paul Resnikoff, memotong pita pada pembukaan kantor startup baru Wave Computing, yang, bersama dengan Broadcom, sedang mengembangkan chip 7-nanometer untuk mempercepat perhitungan jaringan saraf. Kantor ini terletak di gedung buah bersejarah dan pabrik pengalengan pada akhir abad ke-19 dan awal ke-20, ketika Lembah Silikon adalah kebun buah terbesar di dunia. Bahkan kemudian, kantor itu terlibat dalam inovasi, memperkenalkan yang pertama di motor listrik industri aprikot-plum untuk konveyor, yang sekitar 200 karyawan, terutama perempuan, bekerja.
Pada pesta yang mengikuti pemotongan pita, banyak orang terkenal di industri menjadi sorotan, termasuk kawan-kawan Kernigan-Richie dan penulis kompiler C paling populer pada akhir 70-an - awal 80-an, Stephen Johnson, salah satu penulis standar angka floating point Jerome Kunen, penemu konsep bus lokal dan pengembang chipset PC AT pertama Diosdado Banatao, mantan pengembang Sun, DEC, Cyrix, Intel, AMD dan prosesor Silicon Graphics, Qualcomm, Xilinx dan chip Cypress, analis industri, seorang gadis dengan rambut merah dan penduduk California lainnya mpany dari tipe ini.
Di akhir posting kita akan berbicara tentang buku apa yang harus dibaca dan latihan yang harus dilakukan untuk bergabung dengan komunitas ini.
Mari kita mulai dengan Jerome Kunen, inovator dalam aritmatika floating point dan manajer Apple sejak Macintosh pertama.
Kandidat disertasi tidak begitu umum yang mempengaruhi komputasi pada miliaran perangkat. Inilah yang Diser Jerome Kunen (kiri) adalah, Kontribusi terhadap Usulan Standar untuk Aritmatika Binary Floating Point, yang hasilnya dimasukkan dalam nomor poin mengambang IEEE Standard 754. Setelah lulus dari sekolah pascasarjana Berkeley pada tahun 1982, Jerome bekerja di Apple, di mana ia memperkenalkan perpustakaan floating point ke Macintosh pertama.
Setelah 10 tahun manajemen di Apple, Kunen menyarankan Hewlett-Packard dan Microsoft, dan pada tahun 2000 dioptimalkan aritmatika 128-bit untuk AMD 64-bit x86 versi baru. Jerome baru-baru ini mengalihkan perhatiannya ke penelitian tentang standar floating point untuk jaringan saraf, khususnya perselisihan tentang Unum dan Posit. Unum adalah standar yang diusulkan baru, dipromosikan oleh ilmuwan dari Caltech John Gustafson, penulis buku yang sekarang berisik The End of Error, "The End of Error". Posit adalah versi Unum yang dapat diimplementasikan lebih efisien (*) daripada Unum dalam perangkat keras.
(*) Lebih efisien dalam kombinasi parameter: frekuensi clock, jumlah siklus per operasi, throughput conveyor, area relatif pada chip dan konsumsi daya relatif.

Gambar dari artikel (bukan dari Jerome)
Membuat floating point matematika sangat efisien untuk perangkat keras dan
AIMengalahkan Floating Point di Game miliknya: Aritmatika Posit oleh John L. Gustafson dan Isaac Yonemoto :

Tetapi di pesta Stephen / Steve Johnson adalah orang yang kompilernya bahasa pemrograman C telah menjadi populer. Kompiler C pertama ditulis oleh Denis Ritchie, tetapi kompiler Richie terikat erat dengan arsitektur PDP-11. Steve Johnson, berdasarkan karya Alan Snyder, menulis pada pertengahan 1970-an Portable C Compiler (PCC), yang mudah dibuat ulang untuk menghasilkan kode untuk arsitektur yang berbeda. Pada saat yang sama, kompiler Johnson bekerja dengan cepat dan mengoptimalkan. Bagaimana dia mencapai ini?
Pada input PCC, Steve Johnson menggunakan parser LALR (1) yang dihasilkan oleh YACC (Yet Another Compiler Compiler), juga ditulis oleh Steve Johnson. Setelah itu, tugas kompilasi direduksi menjadi memanipulasi pohon dalam fungsi rekursif dan menghasilkan kode dari tabel templat. Beberapa fungsi rekursif ini adalah mesin-independen, bagian lain ditulis oleh orang yang mentransfer PCC ke komputer lain. Tabel templat terdiri dari entri aturan dari tipe "jika register tipe A dan dua register tipe B bebas, bangun kembali pohon menjadi simpul tipe C dan menghasilkan kode dengan string D". Tabel itu tergantung mesin.
Karena kombinasi keanggunan, fleksibilitas dan efisiensi, kompiler PCC dipindahkan ke lebih dari 200 arsitektur - dari PDP, VAX, IBM / 370, x86 ke Soviet BESM-6 dan Orbit 20-700 (komputer on-board dalam versi awal MiG-29). Menurut Denis Ritchie, hampir setiap kompiler C pada awal 1980-an didasarkan pada PCC. Dari dunia BSD Unix, PCC digantikan sebagai kompilator GNU GCC hanya-standar pada tahun 1994.
Selain PCC dan Yacc, Steve Johnson juga merupakan penulis program verifikasi program Lint yang asli (lihat, misalnya,
artikel 1978 ). Nama-nama program Yacc dan Lint telah menjadi kata benda umum. Pada 2000-an, Steve menulis ulang ujung depan MATLAB dan menulis MLint. Sekarang, Steve Johnson sibuk dengan tugas untuk memparalelkan algoritma untuk menghitung jaringan saraf pada perangkat seperti CGRA (Coarse-Grained Reconfigurable Architecture), dengan puluhan ribu elemen mirip prosesor yang membentang oleh tensor melalui jaringan puluhan ribu sakelar di dalam chip besar dengan miliaran transistor:

Tetapi dengan segelas anggur, miliarder Diosdado Banatao, pendiri Chips & Technologies, S3 Graphics dan investor di Marvell. Jika Anda memprogram PC IBM pada tahun 1985-1988, ketika mereka pertama kali muncul di USSR, maka Anda mungkin tahu bahwa di sebagian besar AT-sheks dengan grafis EGA dan VGA ada chipset dari Chips & Technologies, yang keluar bersamaan dengan IBM. Chipset C&T awal dirancang oleh Banatao, yang telah belajar menjadi insinyur elektronik di Stanford, dan sebelum Stanford bekerja sebagai insinyur di Boeing. Pada tahun 1987, Intel mengakuisisi Chips & Technologies.


Di sebelah kiri dalam gambar di bawah ini adalah John Bourgoin, presiden MIPS Technologies sejak puncaknya pada tahun 2000-an, ketika chip dengan core MIPS ada di dalam sebagian besar pemutar DVD, kamera digital dan TV, dengan chipset dari Zoran, Sigma Design, Realtek, Broadcom dan perusahaan lain. Sebelum ini, John adalah presiden MIPS Silicon Graphics sejak 1996, ketika prosesor MIPS berada di dalam workstation Silicon Graphics yang digunakan Hollywood untuk merekam film Jurassic Park 3D realistis pertama. Sebelum di Silicon Graphics, John adalah salah satu wakil presiden AMD sejak 1976.
Art Swift, benar, adalah wakil presiden pemasaran MIPS pada 2000-an, dan sebelum itu pada 1980-an ia bekerja sebagai insinyur di Fairchild Semiconductor (ya, yang itu), kemudian wakil presiden pemasaran di Sun, DEC, Cirrus Logic, dan Presiden Transmet. Baru-baru ini, Art telah menjadi wakil ketua komite pemasaran RISC-V dan telah akrab dengan Syntacore dan CloudBear di Rusia dalam posisi ini. Dan sekarang dia telah menjadi presiden IP MIPS Wave:

Slide dari
presentasi tentang sejarah MIPS terkait dengan periode ketika MIPS dikendalikan oleh John Bourgoin, pada gambar di atas ke kiri:

Perusahaan Transmet, yang presidennya adalah Art Swift untuk beberapa waktu, dalam gambar di atas di sebelah kanan, merilis prosesor Crusoe pada akhir 1990-an, yang dapat mengikuti instruksi x86 dan mencapai pasar di sub-laptop Toshiba Libretto L, laptop NEC dan Sharp. , thin client dari Compaq. Keunggulan kompetitif mereka atas Intel dan AMD diatur untuk mengendalikan konsumsi daya yang rendah.
Implementasi langsung dan verifikasi suite x86 penuh adalah pekerjaan yang sangat mahal, jadi Transmeta pergi ke arah lain, yang menyerupai jalur perusahaan MTsST Rusia dengan prosesor Elbrus (jalur yang dimulai dengan Elbrus 2000 dan sekarang disajikan sebagai Elbrus 8C). Transmeta dan Elbrus didasarkan pada prosesor yang sederhana secara struktural dengan mikroarsitektur VLIW, dan level emulasi x86 bekerja di atasnya menggunakan teknologi yang Transmeta disebut kode morphing.
Gagasan VLIW (Very Long Instruction Word) cukup sederhana - beberapa instruksi prosesor secara eksplisit dinyatakan sebagai satu instruksi super dan dieksekusi secara paralel. Tidak seperti prosesor superscalar, khususnya Intel dimulai dengan PentiumPro (1996), di mana prosesor memilih beberapa instruksi dari memori, dan kemudian memutuskan apa yang harus dieksekusi secara paralel dan apa yang berurutan, berdasarkan pada analisis otomatis dari dependensi antara instruksi.
Prosesor superscalar jauh lebih rumit daripada VLIW, karena seorang superscalar harus menghabiskan logika untuk mempertahankan ilusi seorang programmer bahwa semua instruksi yang dipilih dieksekusi satu demi satu, walaupun dalam kenyataannya dapat ada puluhan dari mereka di dalam prosesor, pada berbagai tahap pelaksanaan. Dalam kasus VLIW, beban mempertahankan ilusi seperti itu terletak pada kompiler dari bahasa tingkat tinggi. Pada akhirnya, sirkuit VLIW rusak ketika prosesor harus bekerja dengan cache multi-level, yang memiliki penundaan tak terduga yang menyulitkan kompiler untuk menjadwalkan instruksi jam. Tetapi untuk perhitungan matematis (misalnya, menempatkan Elbrus di radar dan menghitung pergerakan target) inilah masalahnya, terutama dalam kondisi kekurangan tenaga teknik yang berkualifikasi (lebih banyak orang perlu memverifikasi superscalar).
Ilustrasi ide VLIW, prosesor Crusoe dan sub-laptop Toshiba Libretto L1:

Dan di sini, di tengah dalam foto di bawah ini Derek Meyer, Derek Meyer, CEO Wave Computing saat ini. Sebelum Wave, Derek adalah CEO ARC, pengembang core prosesor ARC yang digunakan dalam chip audio. Core ini
dilisensikan pada suatu waktu oleh
perusahaan Rusia NIIMA Progress , yang kemudian melisensikan core MIPS dan
menunjukkan chip berdasarkan pada mereka di sebuah pameran di Kazan Innopolis . Derek Meyer telah berulang kali bepergian ke Rusia, ke St. Petersburg, di mana tim pengembangan Virage Logic berada. Pada 2009, ARC mengakuisisi Virage Logic, dan pada 2010, Synopsys, perusahaan desain chip terkemuka di dunia, mengakuisisi ARC.
Di sebelah kanan dalam foto -
Sergey Vakulenko , yang pada awal karirnya berdiri di asal-usul Runet, bekerja di Demo dan Institut Kurchatov, yang membawa Internet ke USSR. Sekarang Sergey sedang menulis model siklus-akurat dari elemen prosesor Wave untuk komputasi jaringan saraf, dan sebelumnya ia menulis model-model MIPS yang akurat untuk instruksi yang digunakan untuk memverifikasi core prosesor MIPS I6400 Samurai, I7200 Shaolin dan lainnya.

Inilah Vadim Antonov dan Sergey Vakulenko pada tahun 1990, dengan komputer pertama di Uni Soviet yang terhubung ke Internet:

Dan ini Larry Hudepohl di sebelah kanan (Hüdepol dieja dalam bahasa Rusia?). Larry memulai karirnya di Digital Equipment Corporation (DEC) sebagai perancang prosesor untuk MicroVAX. Kemudian Larry bekerja untuk perusahaan kecil Cyrix, yang pada akhir 1980-an menantang Intel dan membuat prosesor FPU yang kompatibel dengan Intel 80387 dan 50% lebih cepat. Kemudian Larry mendesain chip MIPS di Silicon Graphics. Ketika MIPS Technologies terpisah dari Silicon Graphics, Larry dan Ryan Quinter bersama-sama meluncurkan produk MIPS independen pertama, MIPS 4K, yang menjadi tulang punggung lini yang mendominasi elektronik rumah tahun 2000-an (pemutar DVD, kamera, TV digital). Kemudian MIPS 5K terbang ke angkasa - itu digunakan oleh badan antariksa Jepang JAXA. Kemudian Larry, sebagai VP Hardware Engineering, memimpin pengembangan baris-baris berikut, dan sekarang ia sedang mengerjakan arsitektur akselerator Wave yang baru.

Pesawat ruang angkasa Jepang, dengan bangga bernama Hayabusa-2 (Sapsan-2), yang
mendarat di permukaan asteroid Ryugu tahun lalu , dikendalikan oleh prosesor HR5000 berdasarkan pada inti prosesor MIPS 5Kf, yang telah dilisensikan untuk waktu yang lama oleh MIPS Technologies.
Berikut ini adalah saluran pipa sederhana dari inti prosesor MIPS 5Kf 64-bit dari
datasheet -nya:

Tepat di foto - Darren Jones, Darren Jones. Dia adalah direktur rekayasa perangkat keras di MIPS, yang memimpin pengembangan core kompleks, dengan multithreading perangkat keras, dan superscalars dengan pelaksanaan instruksi yang luar biasa. Kemudian Darren pergi ke Xilinx, di mana ia terlibat dalam Xilinx Zynq - chips, di mana berdiri kombinasi FPGA dan prosesor ARM. Darren sekarang adalah Wakil Presiden Teknik di Wave.
Di MIPS, Darren adalah pemimpin kelompok yang anggotanya kemudian bekerja untuk Apple dan Samsung. Desainer Monica, yang pergi ke Samsung, pernah mengatakan kepada saya sebuah frasa yang saya ingat dengan baik: "Desain RTL: beberapa prinsip sederhana dan sisanya curang" (desain perangkat keras tingkat register: beberapa prinsip sederhana, yang lainnya adalah muhlezh ") Contoh kanonik muhlezh adalah cache (program menulis data dan membacanya, tetapi hanya akan diingat kemudian), tetapi ini hanya kasus yang sangat istimewa dari apa yang dapat dilakukan Monica.

Multithreading perangkat keras dan superscalar yang luar biasa adalah dua pendekatan berbeda untuk meningkatkan kinerja prosesor. Hardware multithreading memungkinkan Anda untuk meningkatkan throughput tanpa banyak konsumsi energi, tetapi dengan pemrograman non-sepele. Superscalar memungkinkan Anda untuk menjalankan program single-threaded kira-kira dua kali lebih cepat, tetapi juga menghabiskan watt dua kali lebih banyak. Tetapi tanpa trik dalam pemrograman.
Akhirnya, multithreading perangkat keras dijelaskan dengan baik di Wikipedia bahasa Rusia, ini adalah
multithreading sementara (diimplementasikan dalam MIPS interAptiv dan MIPS I7200 Shaolin), tetapi
multithreading simultan (dibuat dalam prosesor DEC Alpha pada 1990-an, kemudian di SPARC, dan kemudian di MIPS I6400 Samurai / I6500 Daimyo).
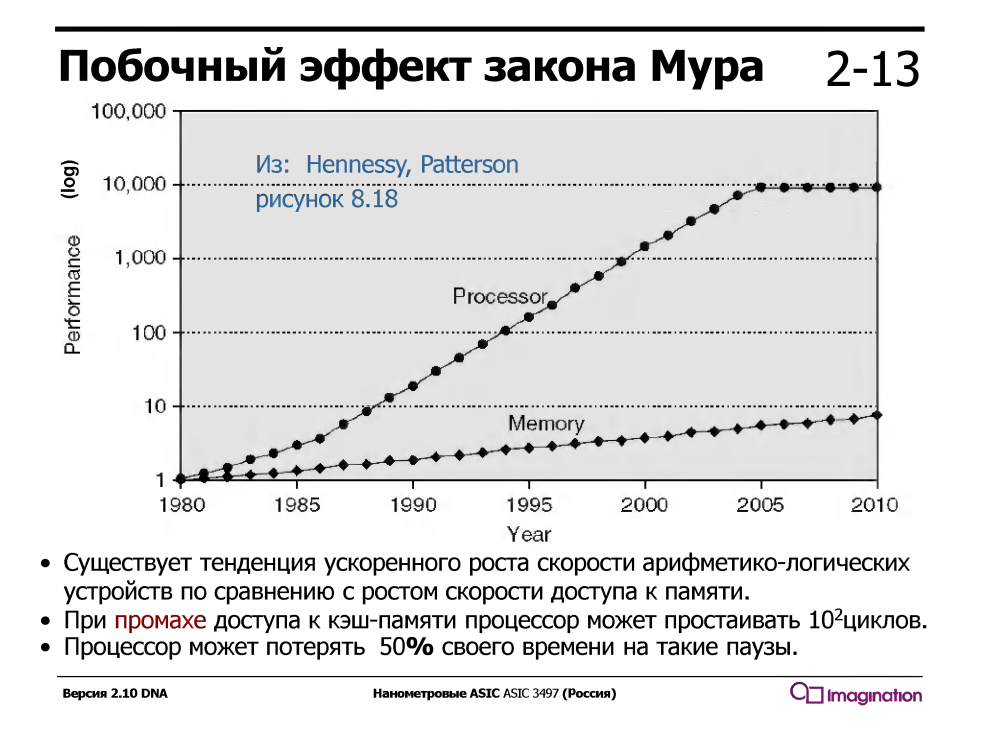
Multithreading sementara mengeksploitasi fakta bahwa prosesor dengan pipa serial konvensional idle / menunggu separuh waktu eksekusi. Apa yang dia tunggu? Data yang melewati cache dari memori. Dan itu menunggu lama - sambil menunggu satu cache miss, prosesor dapat mengeksekusi puluhan atau bahkan seratus atau dua instruksi aritmatika sederhana seperti penambahan.
Ini tidak selalu terjadi - pada tahun 1960-an perangkat aritmatika jauh lebih lambat daripada memori. Tetapi sejak sekitar 1980, kecepatan inti prosesor telah tumbuh jauh lebih cepat daripada kecepatan memori, dan bahkan munculnya cache multi-level dalam prosesor hanya menyelesaikan sebagian masalah.
Prosesor dengan multithreading sementara mendukung beberapa set register, satu untuk setiap utas, dan ketika utas saat ini sedang menunggu data dari memori selama cache hilang, prosesor beralih ke utas lainnya. Ini terjadi secara instan, dalam satu siklus, tanpa gangguan dan ribuan siklus pengendali interupsi, yang diaktifkan selama multithreading perangkat lunak (bukan perangkat keras).
Inilah gagasan multi-threading
pada slide dari bengkel Charles Danchek , seorang profesor di Universitas California Santa Cruz, Silicon Valley Extension. Kenapa di Rusia? Karena Charles Danchek memberi kuliah di MISiS Moskwa, dan kemudian di ITMO St. Petersburg dan Kiev KPI:


Menariknya, perangkat keras multi-ulir dapat diprogram hanya dalam C. Begini tampilannya:
#include "mips/m32c0.h" #include "mips/mt.h" #include "mips/mips34k.h"
Di sini, di sisi pesta adalah perangkat Wave untuk pusat data. Ini belum sepenuhnya berfungsi, meskipun chip tersedia untuk beberapa pelanggan sebagai bagian dari program beta:

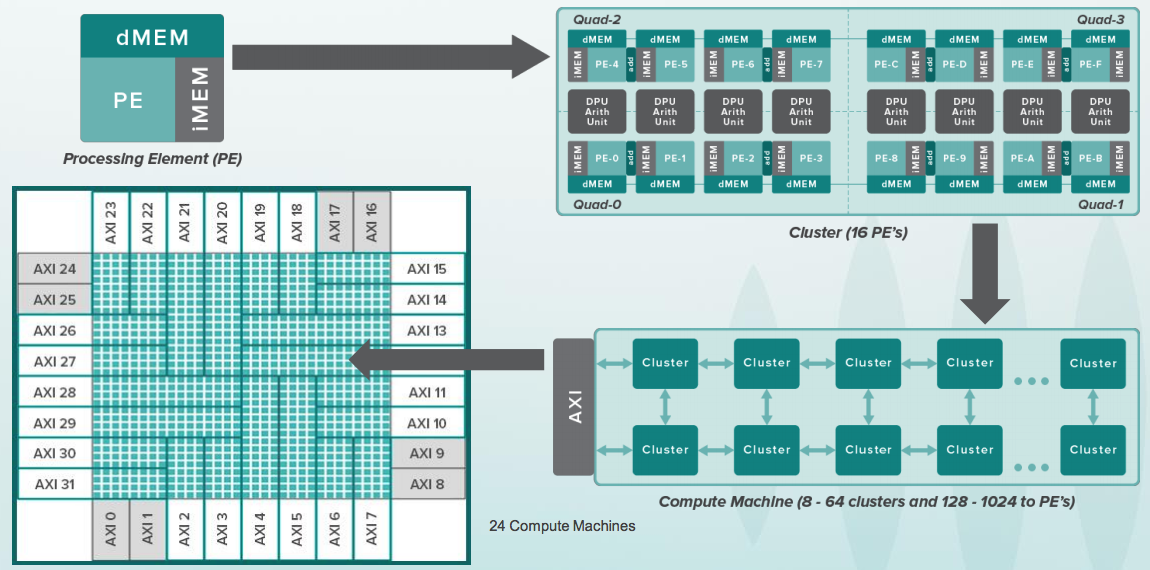
Apa yang dilakukan perangkat ini? Apakah Anda tahu cara memprogram dalam Python? Di sini, di Python, Anda bisa membangun menggunakan pustaka TensorFlow yang disebut Data Flow Graph (DFG). Jaringan saraf pada dasarnya adalah grafik khusus dengan operasi pada matriks. Dalam grup perangkat lunak Wave, yang sebagian dipimpin oleh Steve Johnson, ada kompiler dengan subset perwakilan Google TensorFlow dalam file konfigurasi untuk chip perangkat ini. Setelah konfigurasi, ia dapat melakukan perhitungan grafik tersebut dengan sangat cepat. Perangkat ini dirancang untuk pusat data, tetapi prinsip yang sama dapat diterapkan pada chip kecil, bahkan di dalam perangkat seluler, misalnya untuk pengenalan wajah:

Chijioke Anyanwu (kiri) - Selama bertahun-tahun ia telah menjadi pemelihara seluruh sistem pengujian inti prosesor MIPS. Baldwyn Chieh (tengah) adalah perancang generasi baru elemen mirip prosesor di Wave. Baldwin pernah menjadi desainer senior di Qualcomm. Berikut ini
slide tentang perangkat Wave dari konferensi HotChips :


Setiap inovasi digital nanometer setiap perusahaan Lembah Silikon, AI harus memiliki gadis dengan rambut cerah. Inilah gadis di Wave. Namanya Athena, ia adalah seorang sosiolog berdasarkan pendidikan, dan bergerak di kantor kantor:

Dan inilah tampilan kantornya dari luar, dan sejarahnya yang sudah lebih dari seabad sejak pabrik pengalengan inovatif:


Dan sekarang pertanyaannya adalah: bagaimana memahami arsitektur, arsitektur mikro, sirkuit digital, prinsip-prinsip desain chip AI dan berpartisipasi dalam pihak-pihak tersebut? Cara termudah adalah mempelajari buku teks "Sirkuit Digital dan Arsitektur Komputer" oleh David Harris dan Sarah Harris, dan pergi ke Wave Computing untuk magang musim panas (direncanakan untuk menyewa 15 magang untuk musim panas). Saya harap ini juga dapat dilakukan di perusahaan mikroelektronika Rusia yang terlibat dalam pengembangan serupa - ELVIS, Milander, Baikal Electronics, IVA Technologies dan beberapa lainnya. Di Kiev, ini secara teoritis dapat dilakukan di perusahaan Melexis, yang bekerja sama dengan KPI.
Beberapa hari yang lalu, versi buku teks yang baru dan akhirnya diperbaiki, Harris & Harris dirilis, yang seharusnya gratis di sini
www.mips.com/downloads/digital-design-and-computer-architecture-russian-edition-second-edition-ver3 , tetapi tautan ini tidak berfungsi untuk saya, dan ketika berhasil, saya akan menulis posting terpisah tentangnya. Dengan pertanyaan yang diajukan selama wawancara di Apple, Intel, AMD, dan di halaman mana dari buku pelajaran ini (dan sumber lainnya) Anda dapat melihat jawabannya.