Setelah bertemu pada tahun 2019 dan sedikit beristirahat dari pengembangan fitur baru untuk Smart IDReader, kami ingat bahwa kami tidak menulis apa pun tentang prosesor dalam negeri untuk waktu yang lama. Karena itu, kami memutuskan untuk segera memperbaiki dan menunjukkan sistem pengakuan lain pada Elbrus.
Sebagai sistem pengenalan, sistem pengenalan objek lukisan dianggap "dalam kondisi yang tidak terkendali oleh metode dengan pelatihan sesuai dengan satu contoh" [1]. Sistem ini membangun deskripsi gambar berdasarkan titik tunggal dan deskriptornya, yang dicari dalam basis data gambar yang diindeks. Kami menganalisis kinerja sistem ini dan mengidentifikasi bagian algoritma tingkat rendah yang paling memakan waktu, yang kemudian dioptimalkan menggunakan alat platform Elbrus.
Sistem pengenalan seperti apa yang sedang kita bicarakan?
Saat ini, sebagian besar museum dan galeri menggunakan berbagai alat untuk membiasakan diri dengan eksposisi. Seiring dengan panduan audio klasik, aplikasi seluler yang menggunakan pemrosesan gambar dan metode analisis telah menyebar luas. Beberapa aplikasi ini mengenali kode grafis untuk pameran (bar atau QR) [2], untuk yang lain [3-4] data inputnya adalah bingkai foto atau video dengan pameran diambil secara close-up (Smartify, Artbit). Tentu saja, "panduan seluler" dari kategori yang terakhir lebih nyaman bagi pengguna [5] daripada solusi dengan entri manual nomor pameran atau pengenalan QR: jumlah dan kode cukup kecil, dan pencarian dan entri mereka memerlukan tindakan tambahan yang tidak terkait dengan tinjauan paparan. Ini adalah sistem yang akan kita pertimbangkan.
Tugas mengenali lukisan dalam gambar dirumuskan sebagai berikut. Minta Gambar Q harus ditugaskan ke salah satu kelas C = \ {C_i \} _ {i \ dalam [0, N]}C = \ {C_i \} _ {i \ dalam [0, N]} dimana C i - kelas gambar saya pameran di i i n [ 1 , N ] , C 0 - kelas gambar lain yang sesuai dengan nilai "gambar tidak dikenal". Untuk masing-masing C i set gambar referensi T i .
Selain itu, kami dibimbing oleh asumsi berikut:
- Minta Gambar Q diperoleh dengan menggunakan kamera perangkat seluler oleh pengguna yang tidak siap selama tur, oleh karena itu:
a) mungkin mengandung cacat visual - silau, area tidak fokus, kebisingan;
b) sudut, pembingkaian, pencahayaan, dan keseimbangan warna tidak diketahui (Gbr. 1a);
c) benda asing, seperti pemandangan, bingkai foto, pengunjung, mungkin ada pada gambar (Gbr. 1b). - Gambar Referensi T Ini adalah gambar beresolusi tinggi dengan proyeksi frontal gambar atau reproduksi digitalnya. Standar tidak mengandung benda asing dan cacat visual. Standar dapat, misalnya, halaman yang dipindai secara kualitatif dari album seni (Gbr. 2).
- Gambar (baik atas permintaan dan standar) dapat berlaku untuk gaya apa pun - realisme,
impresionisme, abstraksionisme, grafik fraktal, dll. - Jumlah kelas N sesuai dengan ukuran koleksi dan untuk satu galeri dapat mencapai
ratusan ribu pameran [6].

Gambar 1 - Contoh permintaan gambar a) gambar difoto dari jauh dalam cahaya rendah, b) pengunjung ada dalam bingkai.

Gambar 2 - Contoh gambar referensi untuk lukisan a) Claude Monet "De Voorzaan en de Westerhem", b) Salvador Dali "La persistència de la memòria"
Gagasan utama solusi kami untuk masalah ini didasarkan pada pembuatan deskripsi khusus gambar dari gambar input, yang kemudian digunakan untuk mencari gambar ini dalam database deskripsi gambar referensi gambar resolusi tinggi yang tidak mengalami distorsi geometrik dan cacat foto lainnya. Koordinat titik tunggal yang ditemukan menggunakan algoritma YACIPE [7] dan deskriptor RFD mereka bertindak sebagai deskripsi.
Untuk setiap referensi T i membangun deskripsi, dan kemudian indeks itu - untuk setiap titik dalam deskripsi kita masukkan catatan formulir l a n g l e i , f i r a n g l e ke dalam pohon pencarian pengelompokan hierarki acak [8], yang memungkinkan Anda untuk melakukan pencarian perkiraan tetangga terdekat dengan peningkatan kecepatan yang signifikan dibandingkan dengan pencarian linear. Jarak Hamming digunakan sebagai metrik, karena kami menggunakan deskriptor biner.
Proses pengakuan adalah sebagai berikut:
Di gambar permintaan Q area lukisan Q L pre-localized menggunakan asumsi rectangularity dari frame. Pencarian zona dilakukan menggunakan algoritma pencarian quadrangle cepat [9] dengan pembatasan pada rasio aspek dihapus. Ini mencegah masalah berikut:
- deskripsi yang kurang dari area gambar karena benda asing dalam bingkai, yang mungkin memiliki poin khusus dengan peringkat terbaik;
- biaya komputasi untuk membandingkan deskriptor area yang terletak di luar gambar;
- ketidakcocokan yang signifikan dalam skala dan sudut antara standar dalam database dan gambar dari gambar, yang mengarah ke hasil yang salah dari deskriptor yang cocok.
Gambar di zona yang ditemukan secara normal dinormalisasi:
Q ∗ = H ( Q L ) ,
dimana H - transformasi proyektif.
Buat deskripsi yang ringkas w * :
a) gambar direduksi menjadi ukuran standar sambil mempertahankan proporsi agar algoritma lebih tangguh untuk penskalaan;
b) noise frekuensi tinggi ditekan oleh filter Gaussian;
c) titik tunggal dihitung pada gambar yang dihasilkan, jumlah mereka secara artifisial terbatas M. Yang terbaik dengan penilaian internal YACIPE;
d) warna deskriptor mirip-RFD dari lingkungan dari titik-titik tunggal yang ditemukan dihitung, karena dalam tugas kami, penting untuk menyimpan informasi tentang karakteristik warna gambar input. Misalnya, gambar pada Gbr. 3 akan sangat sulit untuk membedakan tanpanya;
d) demikian, deskripsi gambar Saya dapat direpresentasikan sebagai: w ^ * = \ {\ langle p_i, f_i) \ rangle \} _ {i \ dalam [1, M]} dimana pi= langlexi,yi rangle Apakah koordinat titik tunggal ke-i, dan fi Adalah pegangan ke lingkungan titik tunggal ke-i.
Untuk setiap entri langlep,f rangle inw∗ indeks melakukan pencarian perkiraan untuk tetangga terdekat dari deskriptor f . Prosedur pemungutan suara diterapkan pada deskriptor yang ditemukan - deskriptor fi menambahkan suara ke standar Ti . Kemudian, kandidat kandidat K dengan jumlah suara tertinggi dipilih.
Untuk masing-masing K opsi yang dipilih menggunakan algoritma RANSAC, pencarian untuk transformasi proyektif dilakukan H menerjemahkan, dalam kesalahan geometris yang diberikan delta poin permintaan Q∗ ke poin referensi T . Sepasang titik langlep,p′ rangle dengan deskriptor tertutup dianggap cocok jika:
k i r i | H ( p ) - p ′ r i g h t | < D e l t a , p i n w * , p ' i n w T
Sebagai hasil akhir, standar dipilih T b di mana jumlah perbandingan yang benar ternyata maksimum. Jika kurang dari nilai ambang tertentu R , hasilnya akan menjadi jawaban "gambar tidak dikenal" untuk menghindari kesalahan positif (misalnya, dalam gambar yang tidak ada deskripsi standar dalam database pencarian).


Gambar 3 - Claude Monet. Katedral Rouen, Facade Barat, Sunlight (kiri) dan Katedral Rouen, Portal dan Tower Saint-Romain in the Sun (kanan).
Salah satu bagian utama dari sistem adalah pencarian deskriptor dekat menggunakan jarak Hamming sebagai metrik. Karena dihitung berkali-kali, tahap ini menjadi memakan waktu secara komputasi dan memakan waktu 65% dari waktu sistem. Itu sebabnya kami mengoptimalkannya.
Deskripsi arsitektur Elbrus yang sangat kecil
Arsitektur prosesor Elbrus menggunakan prinsip kata perintah lebar (Very Long Instruction Word, VLIW). Ini berarti bahwa prosesor menjalankan instruksi dalam kelompok, dan dalam setiap kelompok tidak ada dependensi dan instruksi ini dieksekusi secara paralel. Setiap kelompok seperti itu disebut kata perintah yang luas. Kata-kata perintah yang luas dihasilkan oleh kompiler yang mengoptimalkan, yang memungkinkan analisis kode sumber yang lebih rinci, yang mengarah ke paralelisasi yang lebih efisien [10].
Fitur arsitektur Elbrus adalah metode bekerja dengan memori. Selain memiliki cache yang mengoptimalkan waktu akses memori, prosesor Elbrus mendukung metode perangkat keras-perangkat lunak untuk pra-paging data. Metode ini memungkinkan memprediksi akses memori dan memompa data ke dalam buffer data awal. Perangkat keras prosesor mencakup perangkat khusus untuk mengakses array (Array Access Unit, AAU), tetapi kebutuhan untuk bertukar ditentukan oleh kompiler, yang menghasilkan instruksi khusus untuk AAU. Menggunakan perangkat swap lebih efisien daripada menempatkan elemen array dalam cache, karena elemen array paling sering diproses secara berurutan dan jarang digunakan lebih dari sekali [11]. Namun, perlu dicatat bahwa penggunaan buffer pra-paging pada Elbrus hanya mungkin ketika bekerja dengan data yang selaras. Karena itu, membaca / menulis data yang selaras terjadi jauh lebih cepat daripada operasi yang sesuai untuk data yang tidak selaras.
Selain itu, prosesor Elbrus mendukung beberapa jenis paralelisme selain paralelisme pada tingkat perintah: paralelisme SIMD, paralelisme aliran kontrol, paralelisme tugas dalam kompleks multi-mesin. Yang menarik bagi kami adalah konkurensi SIMD.
Fitur menggunakan prosesor ekspansi-SIMD Elbrus
Penggunaan ekstensi SIMD dapat dilakukan dalam dua mode: otomatis dan langsung. Dalam kasus pertama, paralelisasi operasi sepenuhnya dilakukan oleh kompiler tanpa partisipasi pengembang. Mode ini terbatas, karena kode yang dioptimalkan harus sepenuhnya mengulangi perilaku kode sumber, termasuk perilaku ketika meluap, membulatkan, dll. Dalam hal ini, perilaku instruksi ekstensi SIMD mungkin berbeda dalam aspek ini dari instruksi prosesor. Selain itu, algoritma yang digunakan dalam kompiler tidak sempurna dan tidak selalu dapat melakukan paralelisasi yang efisien. Namun, pengembang juga dapat mengakses perintah ekstensi SIMD secara langsung menggunakan intrinsik. Intrinsik adalah fungsi yang panggilannya digantikan oleh kompiler dengan kode kinerja tinggi untuk platform tertentu, khususnya, dengan perintah ekstensi SIMD. Prosesor Elbrus-4C dan Elbrus-8C mendukung satu set intrinsik, yang ukuran registernya adalah 64 bit. Ini termasuk operasi untuk konversi data, inisialisasi elemen vektor, operasi aritmatika, operasi logis bitwise, permutasi elemen vektor, dll.
Saat menggunakan intrinsik pada platform Elbrus, perhatian khusus harus diberikan pada akses ke memori, karena tugas praktis, misalnya tugas pemrosesan gambar, seringkali memerlukan pembacaan data yang tidak seimbang ke dalam register 64-bit. Pembacaan seperti itu sendiri tidak efisien, karena membutuhkan sepasang perintah baca dan perintah berikutnya untuk membentuk blok data, tetapi, yang lebih penting, buffer swap array tidak dapat digunakan untuk meningkatkan kecepatan akses data. Namun, perlu dicatat bahwa masalah akses yang tidak efisien ke data yang tidak selaras relevan untuk prosesor Elbrus-4C dan Elbrus-8C, sedangkan untuk Elbrus-8CV yang lebih baru dengan versi 5 dari sistem perintah, sebagian diselesaikan. Diharapkan prosesor Elbrus dengan versi 6 dari sistem instruksi akan sepenuhnya diselesaikan.
Namun, pada prosesor Elbrus-4C dan Elbrus-8C, pemrosesan data tingkat rendah secara efisien dilakukan dengan mempertimbangkan penyelarasan akun. Sebagai contoh, untuk array numerik, dapat terdiri dari beberapa tahap: memproses bagian awal (hingga batas penyelarasan 64-bit dari salah satu array), memproses bagian utama menggunakan akses memori yang disejajarkan, dan memproses elemen-elemen array yang tersisa. Karena parsing pointer selama kompilasi bukan tugas yang sepele, Anda dapat menggunakan –faligned compiler yang –faligned , yang dengannya semua operasi akses memori dilakukan dengan cara yang selaras.
Fitur selanjutnya menggunakan intrinsik pada platform Elbrus secara langsung terkait dengan arsitektur VLIW-nya. Karena adanya beberapa perangkat logika aritmatika (ALU), yang bekerja secara paralel dan dimuat saat membentuk kata-kata perintah lebar, beberapa perintah dapat dieksekusi secara bersamaan. Secara total, prosesor Elbrus-4C dan Elbrus-8C memiliki enam ALU yang dapat digunakan sebagai bagian dari satu tim luas, tetapi setiap ALU mendukung perangkat intrinsiknya sendiri. Operasi sederhana, seperti menambahkan atau mengalikan elemen dalam register 64-bit, sebagai aturan mendukung dua ALU. Ini berarti bahwa prosesor Elbrus dapat menjalankan dua instruksi tersebut dalam satu siklus clock tunggal. Untuk melakukan ini, jalankan perulangan harus digunakan dalam kode yang dapat dieksekusi. Kompilator pengoptimal untuk platform Elbrus mendukung pragma #pragma unroll(n) , yang memungkinkan penyebaran iterasi n loop.
Contoh penerapan fungsi penambahan dengan mempertimbangkan fitur-fitur ini dapat ditemukan di artikel kami sebelumnya.
Eksperimennya
Hore, teks sudah selesai dan akhirnya kita akan meluncurkan sesuatu di Elbrus!
Pertama, kami mempertimbangkan secara terpisah jarak Hamming. Tanpa basa-basi lagi, kami membandingkan dua vektor bit data acak. Nilai-nilai biner dikemas ke dalam array bilangan bulat 8-bit, dan untuk kesederhanaan, kami percaya bahwa panjang vektor sumber adalah kelipatan 8. Seperti biasa, kode ditulis dalam C ++, dikompilasi oleh lcc 1.21.24 - kompiler Elbrus yang mengoptimalkan.
Kami menulis beberapa implementasi jarak Hamming, yang secara konsisten memperhitungkan fitur prosesor Elbrus. Mereka terlihat seperti ini:
- XOR bitwise antara bilangan bulat 8-bit dan tabel nilai yang dihitung sebelumnya digunakan. Ini adalah implementasi dasar tanpa trik dan trik lainnya.
- Ia menggunakan XOR antara bilangan bulat 32-bit dan intrinsik untuk menghitung jumlah unit dalam bilangan bulat 32-bit - popcnt32. Penjajaran batas 32-bit tidak dilakukan.
- Ia menggunakan XOR antara integer 64-bit dan intrinsik untuk menghitung jumlah unit dalam integer 64-bit - popcnt64. Penjajaran perbatasan 64-bit tidak dilakukan.
- Ia menggunakan XOR antara integer 64-bit dan intrinsik untuk menghitung jumlah unit dalam integer 64-bit - popcnt64. Akses ke memori dilakukan dengan cara yang selaras. Karena alamat awal array dapat memiliki keberpihakan yang berbeda, ketika membaca salah satu array, dua blok 64-bit tetangga dibaca dan blok 64-bit yang diperlukan terbentuk dari mereka.
- Ia menggunakan XOR antara integer 64-bit dan intrinsik untuk menghitung jumlah unit dalam integer 64-bit - popcnt64. Akses ke memori dilakukan dengan cara yang selaras. Karena alamat awal array dapat memiliki keberpihakan yang berbeda, ketika membaca salah satu array, dua blok 64-bit tetangga dibaca dan blok 64-bit yang diperlukan terbentuk dari mereka. Selain itu, flag compiler
-faligned . - Ia menggunakan XOR antara integer 64-bit dan intrinsik untuk menghitung jumlah unit dalam integer 64-bit - popcnt64. Akses ke memori dilakukan dengan cara yang selaras. Karena alamat awal array dapat memiliki keberpihakan yang berbeda, ketika membaca salah satu array, dua blok 64-bit tetangga dibaca dan blok 64-bit yang diperlukan terbentuk dari mereka. Selain itu, flag compiler
-faligned dan compiler pragmas #pragma unroll(2) (untuk menggunakan kedua ALU yang tersedia untuk menghitung popcnt64) dan #pragma loop count(1000) (untuk mengaktifkan optimisasi #pragma loop count(1000) tambahan) digunakan.
Hasil pengukuran waktu ditunjukkan pada tabel 1.
Tabel 1. Waktu untuk menghitung jarak Hamming antara dua array angka biner panjang 10 ^ 5 pada mesin dengan prosesor Elbrus-4C. Rata-rata waktu lebih dari 10 ^ 5 dimulai.
| Tidak. | Eksperimen | Waktu, ms |
|---|
| 1 | tabel nilai yang dihitung | 141.18 |
| 2 | popcnt32, tidak ada perataan | 125,54 |
| 3 | popcnt64, tidak ada perataan | 58.00 |
| 4 | perataan popcnt64 | 17.36 |
| 5 | perataan -faligned , -faligned | 17.15 |
| 6 | popcnt64, penjajaran, -faligned, pragma unroll | 12.23 |
Dapat dilihat bahwa semua optimasi dianggap menyebabkan penurunan runtime 11,5 kali lipat. Perlu dicatat bahwa penggunaan intrinsik dengan akses tidak seimbang ke memori menunjukkan akselerasi hanya 1,13 kali (untuk popcnt32) dan 2,4 kali (untuk popcnt64), sementara akuntansi untuk penyelarasan data menyebabkan penggunaan buffer swap array APB dengan bantuan yang memungkinkan untuk mencapai akselerasi dengan 3,4 kali (58 ms vs 17,15 ms). Terlepas dari kenyataan bahwa penggunaan flag -faligned tidak menunjukkan peningkatan kinerja yang signifikan dalam contoh di atas, dalam algoritma yang lebih kompleks adalah mungkin bahwa kompiler tidak dapat menganalisis kode sumber cukup dalam untuk menghasilkan perintah untuk APB. Dengan mempertimbangkan jumlah aktual ALU khusus memungkinkan kami untuk mempercepat perhitungan dengan 1,4 kali.
Tidak terlalu buruk! Karena kami membandingkan sebanyak 6 opsi untuk implementasi, kami memberikan pseudo-code final, tercepat:
: 8- A B, T, T[i] i : res, A B offset ← A 64- effective_len ← , 64- for i from 1 to offset: res ← res + T[xor(A[i] , B[i])] v_a ← 64- , A[offset+1] v_b1 ← 64- , B[offset] v_b2 ← 64- , v_b1 // 64- for i from offset to effective_len: v_b ← align(v_b1, v_b2) // 64- , v_a res ← res + popcnt64(xor(v_a, v_b)) v_a ← 64- v_b1 ← v_b2 v_b2 ← 64- //
Akan sangat bagus sekali dan untuk semua untuk mempercepat perhitungan jarak Hamming sebanyak 11,5 kali, tetapi dalam kehidupan semuanya sedikit lebih rumit: implementasi semacam itu akan memiliki keuntungan hanya dengan panjang array yang cukup besar. Dalam Fig. Gambar 4 menyajikan perbandingan waktu perhitungan menggunakan tabel nilai pra-perhitungan dan implementasi akhir kami. Anda dapat melihat bahwa ketika versi kami mulai menang hanya dimulai dengan panjang melebihi 400 byte, dan ini juga perlu diperhitungkan saat mengoptimalkan pada Elbrus.
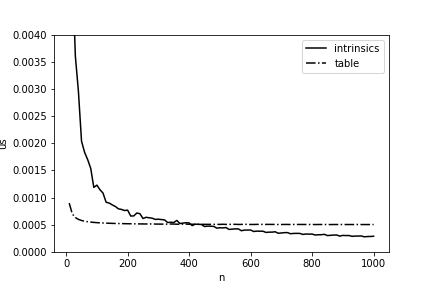
Gambar 4 - Rata-rata waktu (per 1 byte) untuk menghitung jarak Hamming antara dua array tergantung pada panjangnya di Elbrus-4C.
Itu saja, sekarang kami siap untuk mengukur waktu operasi seluruh sistem. Kami mengukur waktu pemrosesan permintaan rata-rata (tidak termasuk pemuatan gambar) untuk 933 permintaan. Saat menyusun deskripsi gambar yang ringkas, deskriptor biner mirip-RFD warna 5328-bit digunakan. Ini terdiri dari 3 deskriptor RFD abu-abu 1776-bit gabungan yang dihitung untuk setiap saluran pada bagian gambar input. Di satu sisi, deskriptor yang panjang seperti itu tidak menyenangkan dengan kecepatan perhitungan dan perbandingan yang tinggi, di sisi lain, deskriptor memberikan kualitas kerja yang cukup tinggi. Namun, ada kabar baik - kita bisa menggunakan implementasi cepat jarak Hamming untuk membandingkannya! Panjang array yang dibandingkan adalah 666 byte, yang lebih dari nilai ambang batas 400 byte untuk Elbrus-4C.
Hasil pengukuran ditunjukkan pada Tabel 2. Dapat dilihat bahwa hanya satu implementasi cepat dari jarak Hamming yang memberikan pemrosesan query 1,5 kali lebih cepat. Perlu juga dicatat bahwa optimasi ini tidak mengubah hasil perhitungan, dan karenanya kualitas pengakuan.
Tabel 2. Waktu pemrosesan rata-rata dari permintaan ke sistem pengenalan objek lukisan dalam kondisi yang tidak terkendali.
| Eksperimen | Minta waktu, s | Perhitungan jarak Hamming mengambil | Waktu akselerasi |
|---|
| Implementasi basis | 2.81 | 63% | - |
| Implementasi cepat | 1,87 | 40% | 1.5 |
Kesimpulan
Dalam artikel ini, kami berbicara sedikit tentang struktur sistem pengenalan untuk objek lukisan dalam kondisi yang tidak terkendali dan sekali lagi menunjukkan bagaimana manipulasi tingkat rendah dapat secara signifikan meningkatkan kecepatannya pada platform Elbrus. Jadi, implementasi yang diusulkan dari jarak Hamming bekerja dengan urutan besarnya (!) Lebih cepat daripada implementasi menggunakan tabel nilai yang telah dihitung dengan panjang yang cukup besar dari vektor input, dan seluruh sistem dipercepat satu setengah kali! Untuk mencapai hasil ini, ekstensi SIMD digunakan, dan fitur arsitektur dan akses memori dari prosesor Elbrus-4C dan Elbrus-8C diperhitungkan. Hasil ini menunjukkan bahwa prosesor Elbrus mengandung sumber daya yang signifikan untuk operasi yang efisien, yang tidak sepenuhnya digunakan tanpa adanya optimasi yang dilakukan secara khusus. Namun, diharapkan bahwa metode akses memori akan ditingkatkan pada prosesor Elbrus yang lebih baru, yang akan memungkinkan beberapa optimasi ini dilakukan secara otomatis dan akan sangat memudahkan kehidupan pengembang.
Sastra
[1] N.S. Skoryukina, A.N. Milovzorov, D.V. Field, V.V. Arlazarov. Metode pengenalan objek lukisan dalam kondisi yang tidak terkendali dengan pelatihan menurut satu contoh // Transaksi ISA RAS. - Masalah khusus, 2018 - hal. 5-15.
[2] Pérez-Sanagustín M. et al. Menggunakan kode QR untuk meningkatkan keterlibatan pengguna di ruang seperti museum // Komputer dalam Perilaku Manusia. - 2016. - T. 60. - S. 73-85. doi: 10.1016 / j.chb.2016.02.02.012
[3] Antoshchuk S. G., Godovichenko N. A. Analisis fitur titik gambar dalam sistem Panduan Virtual Seluler // Pratsi. - 2013. - No. 1 (40). - S. 67-72.
[4] Andreatta C., Leonardi F. Penampilan lukisan berbasis pengakuan untuk panduan museum seluler // Konferensi Internasional tentang Teori dan Aplikasi Visi Komputer, VISAPP. - 2006.
[5] Leonard Wein. 2014. Pengakuan visual dalam aplikasi panduan museum: apakah pengunjung menginginkannya? .. Dalam Prosiding Konferensi SIGCHI tentang Faktor Manusia dalam Sistem Komputasi (CHI '14). ACM, New York, NY, AS, 635-638.
doi: 10.1145 / 2556288.2557270
[6] Galeri Tretyakov, https://www.tretyakovgallery.ru/collection/
[7] Lukoyanov A. S., Nikolaev D. P., Konovalenko I. A. Modifikasi algoritma YAPE untuk gambar dengan penyebaran kontras lokal yang besar // Teknologi Informasi dan Teknologi Nanoteknologi. - 2018 .-- S. 1193-1204.
[8] Muja M., Lowe DG Pencocokan cepat fitur biner // Computer and Robot Vision (CRV), 2012 Ninth Conference on. - IEEE, 2012 .-- S. 404-410.
doi: 10.1109 / CRV.2012.60
[9] Skoryukina, N., Nikolaev, DP, Sheshkus, A., Polevoy, D. (2015, Februari). Deteksi dokumen persegi panjang waktu-nyata pada perangkat seluler. Dalam Konferensi Internasional Ketujuh tentang Visi Mesin (ICMV 2014) (Vol. 9445, hal. 94452A). Masyarakat Internasional untuk Optik dan Photonics.
doi: 10.1117 / 12.2181377
[10] Kim A.K., Bychkov I.N. dan teknologi Rusia lainnya "Elbrus" untuk komputer pribadi, server dan superkomputer // Teknologi Informasi Modern dan Pendidikan TI, M.: Yayasan Pengembangan Media Internet, Pendidikan TI, Potensi Manusia "Liga Media Internet", 2014, No 10, hlm. 39-50.
[11] Kim A.K., Perekatov V.I., Ermakov S.G. Mikroprosesor dan sistem komputasi
keluarga Elbrus. - St. Petersburg: Peter, 2013 .-- 272 S.